




简单介绍
MySQL全文索引是在基于文本的列(char、varchar或text列)上创建的,以提升对这些列中包含的数据的查询和DML操作效率。全文索引被定义为create table语句的一部分,或者使用alter table或create index追加到现有表中。搜索语法为:match(field1,field2,…) against(’keyword‘),更多使用方法及详细信息参考MySQL全文索引官方文档
版本说明
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引
只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引
创建全文索引
说明:搜索时,默认对中文类分词支持不友好,如果有中日韩文分词需求,在创建索引时,需要声明该分词插件ngram,语法可选【with parser ngram】
DROP TABLE IF EXISTS `t_stu`;CREATE TABLE `t_stu` (`id` int(10) UNSIGNED NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`kecheng` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`fenshu` int(11) NULL DEFAULT NULL,`keyword` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE,FULLTEXT INDEX `ft_index`(`keyword`) WITH PARSER `ngram`) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;-- ------------------------------ Records of t_stu-- ----------------------------INSERT INTO `t_stu` VALUES (1, '张三', '语文', 81, '张三语文');INSERT INTO `t_stu` VALUES (2, '张三', '数学', 75, '张三数学');INSERT INTO `t_stu` VALUES (3, '李四', '语文', 76, '李四语文');INSERT INTO `t_stu` VALUES (4, '李四', '数学', 90, '李四数学');INSERT INTO `t_stu` VALUES (5, '王五', '语文', 81, '王五语文');INSERT INTO `t_stu` VALUES (6, '王五', '数学', 100, '王五数学');INSERT INTO `t_stu` VALUES (7, '王五', '英语', 90, '王五英语');
create index方式创建
DROP TABLE IF EXISTS `t_stu`;CREATE TABLE `t_stu` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,`kecheng` varchar(255) DEFAULT NULL,`fenshu` int(11) DEFAULT NULL,`keyword` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC;INSERT INTO `t_stu` VALUES (1, '张三', '语文', 81, '张三语文');INSERT INTO `t_stu` VALUES (2, '张三', '数学', 75, '张三数学');INSERT INTO `t_stu` VALUES (3, '李四', '语文', 76, '李四语文');INSERT INTO `t_stu` VALUES (4, '李四', '数学', 90, '李四数学');INSERT INTO `t_stu` VALUES (5, '王五', '语文', 81, '王五语文');INSERT INTO `t_stu` VALUES (6, '王五', '数学', 100, '王五数学');INSERT INTO `t_stu` VALUES (7, '王五', '英语', 90, '王五英语');-- create index方式创建CREATE FULLTEXT INDEX ft_index ON t_stu (keyword) WITH PARSER ngram;
alter table方式创建
alter table t_stu add fulltext index ft_index(keyword) with parser ngram;
alter table方式创建
alter table t_stu add fulltext index ft_index(keyword) with parser ngram;
删除全文索引
drop index方式删除
drop index ft_index on t_stu ;
alter table方式删除
alter table t_stu drop index ft_index ;
完整使用语法
select * from t_stu where match(keyword) against('张三') ;
提示:match() 函数中指定的列务必与索引中指定的列完全一致,否则将无法使用全文索引,全文索引不会记录关键字来自于哪一列。
发现问题
select * from t_stu where match(keyword) against('张') ;
找不到数据,或者数据不全
从结果看出,只有输入“张三”才匹配到了一条记录,有了解过ElasticSearch、Lucene、Solr、MeiliSearch等搜索中间件的大佬,对这样的结果属实是不满意的,预期的结果应该查出3条记录才正常,导致这种情况其中非常关键的一个原因是MySQL对应执行引擎下全文索引的**【最小搜索长度】**,MySQL 中的全文索引,有两个关键的变量,分别是最小搜索长度和最大搜索长度,对于长度小于最小搜索长度和大于最大搜索长度的词,都不会被索引。换言之,这个词的长度必须在以上两个变量的区间内。
通过命令可以查看
show variables like '%ft%';
----------------------------
// InnoDB
innodb_ft_min_token_size = 3;
innodb_ft_max_token_size = 84;
// MyISAM
ft_min_word_len = 4;
ft_max_word_len = 84;
可以看到最小搜索长度InnoDB 引擎下默认是3,MyISAM引擎下默认是4,因此MySQL 的全文索引只会对长度大于等于3或者4的词建立索引,而前面基于InnoDB,搜索的只有“jav”和“java”的长度大于等于 3,而基于MyISAM,搜索也只有“java”的长度大于等于4。
解决问题
既然最小搜索长度不满足要求,就需要修改配置,在/etc/my.cnf下的mysqlId中追加内容如下,当然也可以修改最大搜索长度,但没必要
innodb_ft_min_token_size = 1ft_min_word_len = 1
完事儿后重启 MySQL 服务器,并修复全文索引,修复全文索语句如下,不过一般建议删除索引,并重建索引
repair table t_stu quick;
到这里为止,也依然没有达到最终的效果,搜索关键字“张”时,并没有出现结果集中,因为MySQL的全文索引有自然语言的全文索引和布尔全文索引两种选择:
1、自然语言全文索引默认情况下,或者使用 in natural language mode修饰符时,match() 函数对文本集合执行自然语言搜索,上面的例子都是基于自然语言的全文索引。自然语言搜索引擎将计算每一个文档对象和查询的相关度。这里,相关度是基于匹配的关键词的个数,以及关键词在文档中出现的次数。在整个索引中出现次数越少的词语,匹配时的相关度就越高。相反,非常常见的单词将不会被搜索,如果一个词语的在超过 50% 的记录中都出现了,那么自然语言的搜索将不会搜索这类词语。这个机制也比较好理解,比如,一个数据表存储的是一篇篇的文章,文章中的常见词、语气词等等,出现的频率非常多,搜索这些词语是没有意义的,搜索具有文章特性的词,这样才能把文章区分开来。2、布尔全文索引在布尔搜索中,可以在查询中自定义某个被搜索的词语的相关性,当编写一个布尔搜索查询时,可以通过一些前缀修饰符来定制搜索。MySQL内置的修饰符,上面查询最小搜索长度时,搜索结果ft_boolean_syntax变量的值就是内置的修饰符,相关修饰符具体的作用可以看看手册。
上面的情况,可以通过布尔满足
select * from t_stu where match(keyword) against('*张*' IN BOOLEAN MODE);
select * from t_stu where match(keyword) against('张*' IN BOOLEAN MODE);
数据是可以查出来的。完全实现like效果
按自然语言搜索模式查询
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('关键词' IN NATURAL LANGUAGE MODE);
按布尔全文搜索模式查询
2.1 匹配既有管理又有数据库的记录
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+数据库 +管理' IN BOOLEAN MODE);
2.2匹配有数据库,但是没有管理的记录
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+数据库 -管理' IN BOOLEAN MODE);
2.3匹配MySQL,但是把数据库的相关性降低
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('>数据库 +MySQL' INBOOLEAN MODE);
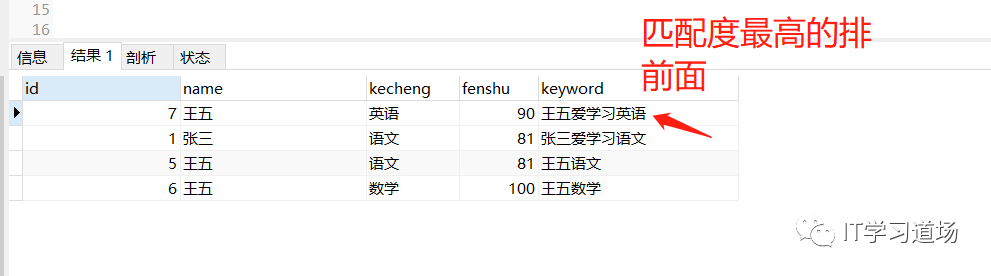
select * from t_stu where match(keyword) against('*王五*爱学习*英语*' IN BOOLEAN MODE);
匹配度越高的排在最前面
总结
MySQL全文索引起初仅支持英文,因为英文的词与词之间有空格,使用空格作为分词的分隔符是很方便的。亚洲文字,比如汉语、日语、汉语等,是没有空格的,这就造成了一定的限制。不过 MySQL 5.7.6 开始,引入了一个 ngram 全文分析器来解决这个问题,并且对 MyISAM 和 InnoDB 引擎都有效。
事实上,MyISAM 存储引擎对全文索引的支持有很多的限制,例如表级别锁对性能的影响、数据文件的崩溃、崩溃后的恢复等,这使得 MyISAM 的全文索引对于很多的应用场景并不适合。所以,多数情况下的建议是使用别的解决方案,例如MeiliSearch、ElasticSearch等等第三方的插件,亦或是使用InnoDB存储引擎的全文索引。
注意
1、使用全文索引前,明确版本支持情况
2、全文索引比like + %快N倍,但是可能存在精度问题
3、如果需要全文索引的是大量数据,建议先添加数据,再创建索引
4、对于中文,可以使用 MySQL 5.7.6之后的版本,或者第三方插件
下篇讲解java中使用ik分词器对文本进行分词,敬请期待
