






异常情况
hive中创建一个表
create external table test_table
(
s1 string,
s2 CHAR(10),
s3 VARCHAR(10)
)
row format delimited fields terminated by '#'
stored as textfile location '/fayson/fayson_test_table';
插入中文字符
insert into test_table values ('1','我你我你我','我你我你我');
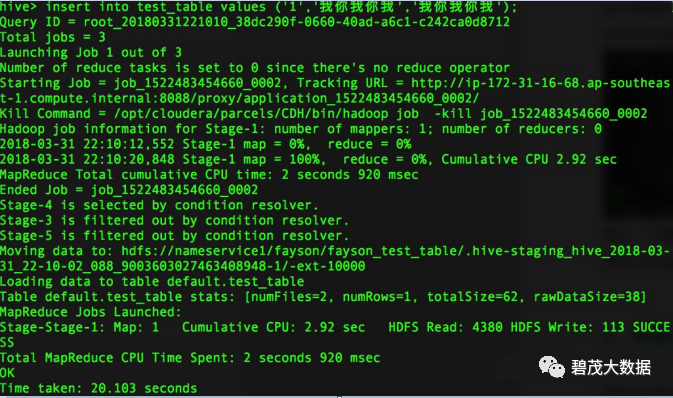
Hive使用正常
select * from test_table;
Impala查询
select * from test_table;
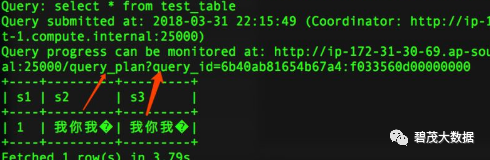
数据生成的hdfs文件的编码
hadoop fs -get fayson/fayson_test_table/000000_0_copy_1 .
cat 000000_0_copy_1
file -bi 000000_0_copy_1
解决方法
扩大CHAR/VARCHAR的长度定义
create external table test_table1
(
s1 string,
s2 CHAR(15),
s3 VARCHAR(15),
s4 string
)
row format delimited fields terminated by '#'
stored as textfile location '/fayson/fayson_test_table1';
插入数据
insert into test_table1 values ('1','我你我你我','我你我你我','我你我你我');
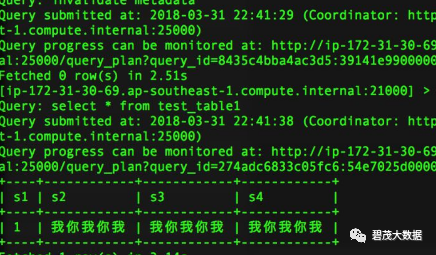
Hive查询正常
select * from test_table1;

Impala查询正常
select * from test_table1;
总结
Hive和Impala在处理字符时是不一样的
Hive的实现与Java保持一致,但Impala并没有
Hive中的CHAR/VARCHAR字符串的长度是根据实际的代码页确定的
Impala处理CHAR/VARCHAR类型的字段使用的是UTF-8编码, 内部使用字节数组
中文字符的UTF-8编码是3个字节,CHAR(10)只能容纳最多3个完整的中文字符
定义的CHAR(10)只能容纳3个半个中文字符导致的问题
解决方法是使用CHAR(15), 这样最多可以容纳5个中文字符,如事先无法估计中文串长度, 则建议使用STRING类型

文章转载自碧茂大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
