




大家好,我是小寒。
今天我们来分享第二个深度学习案例:手写数字识别。
1.加载数据集
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.MNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.MNIST(root="../data", train=False, transform=trans, download=True)
len(mnist_train), len(mnist_test)
60000,10000
可视化数据集
我们来看一下数据集中的图像样本是什么样的。
通过如下方式,我们来可视化的展示训练集中前几个样本。
# 显示数据集
mnist_show = torchvision.datasets.MNIST(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
images, label = next(iter(data.DataLoader(mnist_show, 20, shuffle=True)))
#多张图合并成一张图片
images_example = torchvision.utils.make_grid(images,nrow=5)
images_example = images_example.numpy().transpose(1,2,0) # 将图像的通道值置换到最后的维度,符合图像的格式
plt.imshow(images_example )
plt.show()

2.模型架构
模型架构如下图所示。
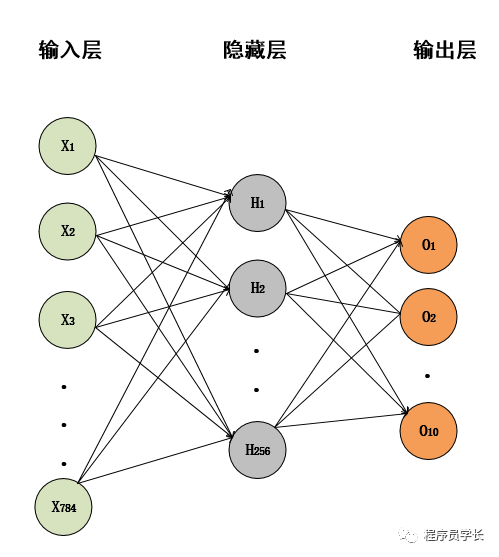
#这里使用多层感知机来进行手写数字的识别
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
3.初始化模型参数
以均值为 0 和标准差为 0.1的高斯分布来随机初始化权重。
# PyTorch 不会隐式地调整输⼊的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整⽹络输⼊的形状
def init_weights(m):
if type(m) == nn.Linear:
#以均值为 0 和标准差为 0.1 随机初始化权重。
nn.init.normal_(m.weight, std=0.1)
4.定义损失函数
由于是分类问题,所以损失函数使用交叉熵损失。
loss = nn.CrossEntropyLoss(reduction='none')
5.定义优化器
使用 SGD(批量梯度下降算法)来进行优化,这里设置学习率为0.01
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
6.训练和预测
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
print("随机初始化后,测试集的准确率为")
print(evaluate_accuracy(net, test_iter))
#训练
def train_epoch_ch3(net, train_iter, loss, updater):
"""训练模型⼀个迭代周期(定义⻅第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
#进行预测
y_hat = net(X)
#计算损失
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使⽤PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else: # 使⽤定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
train_losss=[]
train_accs=[]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型"""
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
train_loss, train_acc = train_metrics
print(f'epoch {epoch + 1}, loss {float(train_loss):f}')
train_losss.append(train_loss)
train_accs.append(train_acc)
num_epochs = 15
print("开始训练:")
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
输出:
随机初始化后,测试集的准确率为
0.0997
开始训练:
epoch 1, loss 1.719787
epoch 2, loss 1.028229
epoch 3, loss 0.708345
epoch 4, loss 0.633207
epoch 5, loss 0.545152
epoch 6, loss 0.517245
epoch 7, loss 0.435589
epoch 8, loss 0.378610
epoch 9, loss 0.398382
epoch 10, loss 0.355470
epoch 11, loss 0.292634
epoch 12, loss 0.303913
epoch 13, loss 0.297712
epoch 14, loss 0.316524
epoch 15, loss 0.227925
7.评估及测试
def show_image(num_epochs,train_ls,train_acc):
plt.plot(np.arange(1, num_epochs + 1), train_ls,label='train_loss')
plt.plot(np.arange(1, num_epochs + 1), train_acc,label='train_accuracy')
plt.xlabel('epoch')
plt.legend()
plt.show()
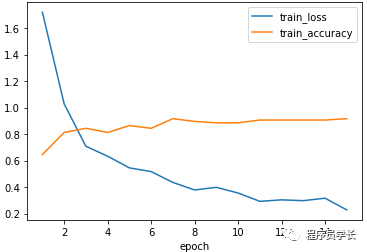
show_image(num_epochs,train_losss,train_accs)
test_acc = evaluate_accuracy(net, test_iter)
print(f'test_acc {float(test_acc):f}')
输出:
test_acc 0.910300
损失变化和准确率变化如下图所示。
最后
今天简单介绍了一个如何用 Pytorch 来实现手写数字识别。
如果需要完整代码+数据集,可以加我微信: algo_code
接下来我们会分享更多的 深度学习案例以及python相关的技术,欢迎大家关注。
最后,最近新建了一个 python 学习交流群,会时不时的分享 python相关学习资料,也可以问问题,非常棒的一个群。
进群方式:加我微信,备注 “python”
最后
—

往期回顾

如果对本文有疑问可以加作者微信直接交流。进技术交流群的可以拉你进群。

文章转载自程序员学长,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
