




调度
在调度相关的体系中有几个非常重要的组件。
调度器:SchedulerNG 及其子类、实现类。 调度策略:SchedulingStrategy 及其实现类。 调度模式:ScheduleMode 包含流和批的调度,有各自不同的调度模式。
1、调度器
作业调度器是作业的执行、异常处理的核心,具备如下基本能力。
作业的生命周期管理,如作业开始调度、挂起、取消。 作业执行资源的申请、分配、释放。 作业的状态管理,作业发布过程中的状态变化和作业异常时的容错等。 作业的信息提供,对外提供作业的详细信息。
在 Flink 中有两个调度器的实现。
DefaultScheduler
该调度器是当前版本的默认调度器,是 Flink 新的调度设计,使用 SchedulerStrategy 来实现调度。 LegacyScheduler
该调度器是遗留的调度器,实际上使用了原来的 ExecutionGraph 的调度逻辑,在后文中不再阐述该调度器的调度过程。
2、调度行为
SchedulerStrategy 接口定义了调度行为,其中定义了四种行为。
startScheduling:调度入口,触发调度器的调度行为。 restartTasks:重启执行失败的 Task,一般是 Task 执行异常导致的。 onExcutionStateChange:当 Execution 的状态发生改变时。 onPartitionConsumable:当 IntermediateResultPartition 中的数据可以消费时。
3、调度模式
Eager 调度
该模式适用于流计算。一次性申请所有需要的资源,如果资源不足,则作业启动失败。 分阶段调度
分阶段调度(Lazy_From_Sources)适用于批处理。从 Source Task 开始分阶段调度,申请资源的时候,一次性申请本阶段所需要的所有资源。上游 Task 执行完毕后开始调度执行下游的 Task,读取上游的数据,执行本阶段的计算任务,执行完毕之后,调度后一个阶段的 Task,依次进行调度,直到作业执行完成。 分阶段 Slot 重用调度
分阶段 Slot 重用调度(Lazy_From_Sources_With_Batch_Slot_Request)适用于批处理,与分阶段调度基本一样,区别在于该模式下使用批处理资源申请模式,可以在资源不足的情况下执行作业,但是需要确保在本阶段的作业执行中没有 Shuffle 行为。
4、调度策略
调度策略目前有两种实现。
EagerSchedulerStrategy :该调度策略用来执行流计算作业的调度。 LazyFromSourceSchedulingStrategy:该调度策略用来执行批处理作业的调度。
作业生命周期
关键组件
1.JobMaster
现在提到 JobManager 的时候,其实是说 Flink 的 JobManager 角色,是一个独立运行的进程,该进程中包含了一系列的服务,如 Dispatcher、ResourManager 等。
1、调度执行和管理
InputSplit 分配
在批处理中使用,为批处理计算任务分配待计算的数据分片。
结果分区跟踪
结果分区跟踪器 (PartitionTracker) 跟踪非 Pipelined 模式的分区,其实就是跟踪批处理中的结果分区,当结果分区消费完之后,具备结果分区释放条件时,向 TaskExeculor 和 ShuffleMaster 发出释放请求。 作业执行异常
根据作业的执行异常,选择重启作业或者停止作业。
2、作业 Slot 资源管理
释放 TaskManager 的情况:作业停止、闲置 TM、TM 心跳超时。
3、检查点与保存点
4、监控运维相关
反压跟踪、作业状态、作业各算子的吞吐量等监控指标。
5、心跳管理
2.TaskManager
Task
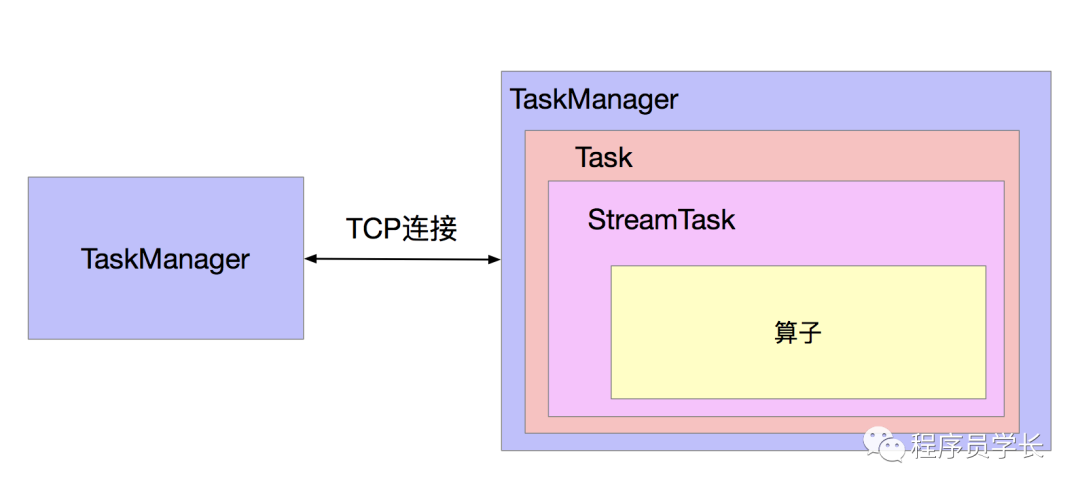
TaskManager、Task、StreamTask 和 算子的关系如下图所示。
Task 执行所需要的核心组件如下。
TaskStateManager:负责 State 的整体协调。其中封装了 CheckpointResponder,在 StreamTask 中用来跟 JobMaster 交互,汇报检查点的状态。 MemoryManager:Task 通过该组件申请和释放内存。 LibraryCacheManager:开发者开发的 Flink 作业打包成 jar 提交给 Flink 集群,在 Task 启动的时候,需要从此组件远程下载所需要的 Jar 文件等,在 Task 的类加载器中加载,然后才能够执行业务逻辑。 InputSplitProvider:在数据源算子中,用来向 JobMaster 请求分配数据集的分片,然后读取该分片的数据。 ResultPartitionConsumableNotifier:结果分区可消费通知器,用于通知消费者,生产者生产的结果分区可消费。 PartitionProducerStateChecker:分区状态检查器,用于检查生产端分区状态。 TaskLocalStaleStore:在 TaskManager 本地提供 State 的存储,恢复作业的时候,优先从本地恢复,提高恢复速度。但是本地 State 存储的方式可能因为硬件问题丢失,所以如果不能从本地恢复,需要再从可靠分布式存储中恢复。 IOManager:IO 管理器,在批处理计算中(如排序、Join等场景),经常会遇到内存中无法放下所有数据的情况,IOManager 就负责将数据溢写到磁盘,并在需要的时候将其读取回来。 ShuflleEnvironment:数据交换的管理环境,其中包含了数据写出、数据分区的管理等组件。 BroadcastVariableManager:广播变量管理器,Task 可以共享该管理器,通过引用数跟踪广播变量的使用,没有使用的时候则清除。 TaskEventDispatcher:任务事件分发器,从消费者任务分发事件给生产者任务。
StreamTask
StreamTask 的类型与算子的类型一一对应。
StreamTask 的实现分为几类。
TwolnpulStreamTask
两个输入的 StreamTask,对应于 TwoInputStreamOperator
OnelnpulStreamTask
单个输入的 StreamTask,对应于 OneInputStreamOperator
SourceStreamTask
SourceStreamTask 是用在流模式的执行数据读取的 StreamTask
BoundedStreamTask
该 StreamTask 是用在模拟批处理的数据读取行为
SourceReaderStreamTask
SourceReaderStreamTask 用来执行 SourceReaderStreamOperator。用来重构Soruce接口,目前还未实现。
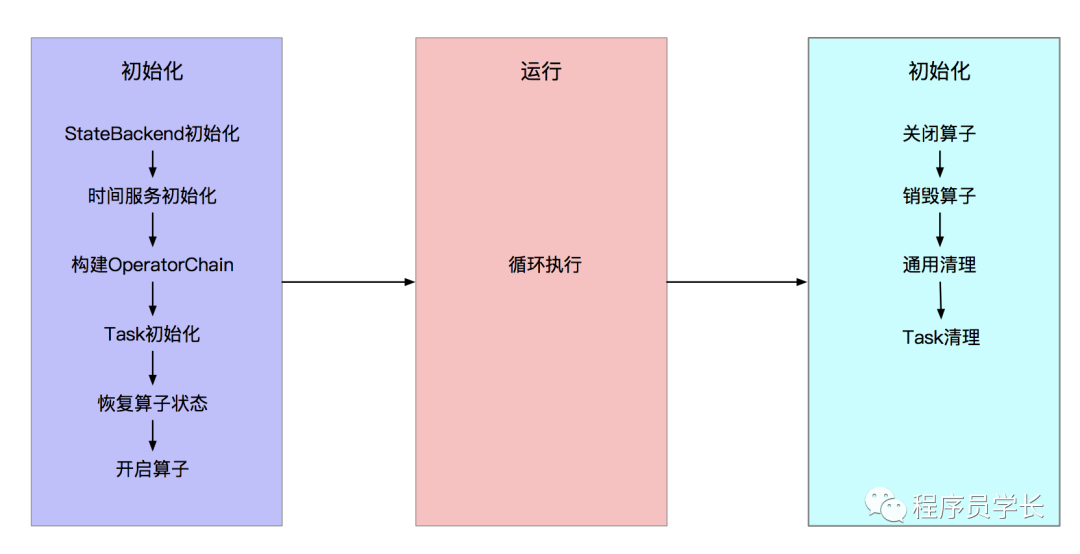
1、初始化阶段
StateBackend 初始化,这是实现有状态计算和 Exactly-Once 的关键组件。
时间服务初始化,此处的时间服务即最终管理定时器的服务。
构建 OperatorChain,实例化各个算子。
算子构建完毕,然后开始 Task 的初始化。根据 Task 的类型的不同,其初始化略有不同。
然后初始化 StreamInputProcessor ,将输入(StreamTaskNetWorkInput)、算子处理数据、输出(StreamTaskNetWorkOutput)关联起来,形成 StreamTask 的数据处理完整通道。 之后设置监控指标,使之在运行时能够将各种监控数据与监控模块打通。
对于 SourceStreamTask 而言,主要是启动 SourceFunction 开始读取数据,如果支持检查点,则开启检查点。
对于 OneInputStreamTask 和 TwoInputStreamTask,构建 InputGate,包装到 StreamTask 的输入组件 StreamTaskNetWorkInput。此处需要注意,StreamTask 之间的数据传递关系由下游的 StreamTask 负责建立数据传输通道,上游的 StreamTask 只负责写入内存。
对 OperatorChain 中的所有算子恢复状态,如果作业是从快照恢复的,就把算子恢复到上一次保存的快照状态。如果是无状态算子或者作业第一次执行,则无需恢复。 算子状态恢复之后,开启算子,将 UDF 函数加载、初始化进入执行状态。不同的算子也有一些特殊的初始化行为。
2、运行阶段
3、关闭与清理阶段
管理 OperatorChain 中的所有算子,同时不再接收新的 Timer 定时器,处理完剩余的数据 ,将算子的数据强制清理。 销毁算子,销毁算子的时候,关闭 StateBackend 和 UDF。 通用清理,停止相关的执行线程。 Task 清理,关闭 StreamInputProcessor ,本质上是关闭了 StreamTaskInput,清理 InputGate,释放序列化器。
作业启动
1、JobMaster 启动作业
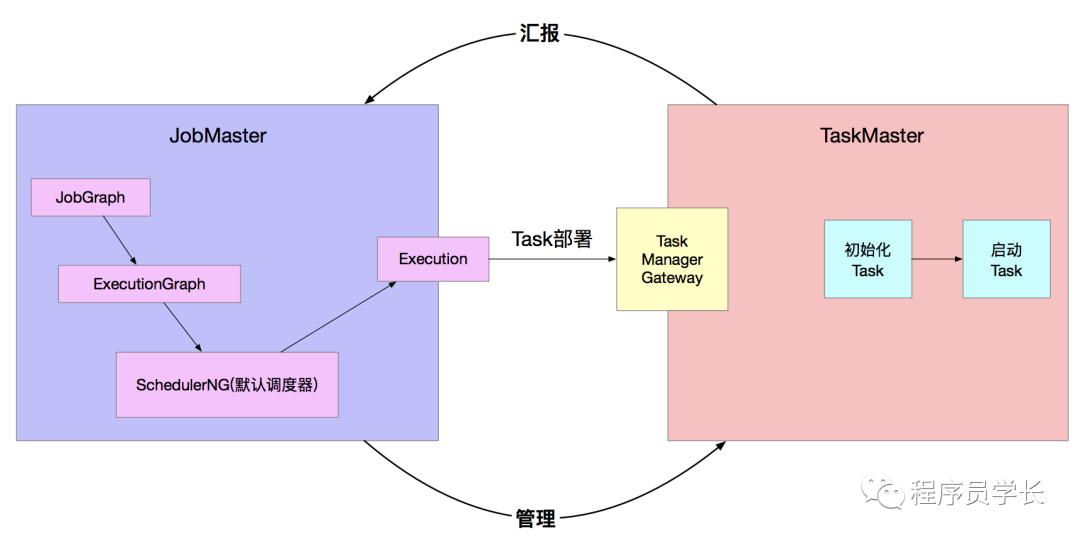
作业调度的入口在 JobMaster 中,由 JobMaster 发起调度。
2、TaskManger 启动 Task
Task 启动
Task 部署
该方法的核心逻辑是初始化 Task。
启动 Task
StreamTask 启动
作业停止
作业失败调度
Flink 对作业失败的原因做了归纳定义,有如下 4 种类型。
NonRecoverableError 不可恢复的错误。 PartitionDataMissError 分区数据不可访问错误。下游 Task 无法读取上游 Task 产生的数据,需要重启上游的 Task。
EnvironmentError 环境的错误。 RecoverableError 可恢复的错误。
默认作业失败调度
RestartAllStrategy:若 Task 发生异常,则重启所有的 Task,恢复成本高,但其是恢复作业一致性的最安全策略。
RestartPipelinedRegionStrategy:分区恢复策略,若 Task 发生异常,则重启该分区的所有 Task,恢复成本低,实现逻辑复杂。
最后
—
这期文章就分享到这里,如果觉得不错,转发、在看、点赞安排起来吧。
你知道的越多,你的思维越开阔。我们下期再见。

往期回顾

如果对本文有疑问可以加作者微信直接交流。进技术交流群的可以拉你进群。

