




一直以来,我们在写业务sql的时候,一般操作都是利用常用的查询函数和join操作就可以完成80%以上的查询操作,但是有时候也会碰到一些经典的问题,我们常常看到用寻常的写法写出sql的查询效率总是差强人意,可能很难避免用的子查询等非常耗性能的查询手段,虽然能获取查询结果,但sql性能堪忧,那有没有好的解决方案呢,当然是有的,本篇文章将带你一阅mysql自变量的风采。
首先简单介绍下自定义变量,我们一般在sql中所用到的自定义变量形如@xxx,它是一个用来存储内容的临时容器,在mysql整个过程中都会存在,初始化的时候可以用SET指令:如SET @xxx:=1,也可以用SELECT指令,形如SELECT @xxx:=1,当然这里要注意自定义变量赋值的时候一定要用:=而不是=,因为=符号对于自变量来说是判断相等的操作,这点非常重要。其实从本质上来看的话,自定义变量是sql查询期间的一个缓存,用来存储临时计算的迭代变量,这点很有用,比如计算连续值的时候,前一条记录和后一条记录就可以用自定义变量存放,而无需关联表来查询,可以节省一大笔的性能。后面列举的两大经典问题会讲到如何进行使用。
当然自定义变量也有局限性,如以下场景:
不能使用自定义变量的地方使用limt子句。
自定义变量的生命周期是一个sql查询连接,不能用来做连接间的传值。
如果使用了连接池,自定义变量可能会互串,如两个毫无相关的sql用到了同一个自定义变量的命名就会出现相互干扰。
mysql优化器在某些场景下会将自定义变量优化掉,从而导致代码不按预想的方式运行。
自定义变量的赋值顺序的时间点可能不固定,会依赖优化器。
赋值符号:=的优先级比较低,赋值表达式最好加明确的括号。
使用未定义的变量也不会产生语法错误,忽视这点将非常容易犯错。
上面讲完了大概的注意事项,下面就要开始实战了。
一、解决Top N问题
题1:编写一个SQL查询,获取employee表中的第n高的薪水(salary)。
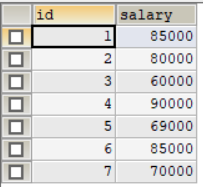
如果N=1的话获取的结果应该是
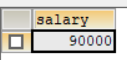
我看在Top N问题上,有很多种解法,比如关联多表来查询,如
这种解法是用2张表做笛卡尔乘积然后再利用group by和having count进行计算,这种方案sql不怎么好理解,而且由于表关联用了笛卡尔乘积,sql的查询效率不是很理想。
下面看下我自己总结出来的一种通用解法,其实Top N问题的本质是先排序然后再取第N行记录的值,在排序后可以用limt子句进行取值。形如
如果利用自变量求解的话,思路就是利用自变量为排序后的表生成一个虚拟的自增id,然后按虚拟id的条件来取值Top N的问题。
其实在解法3中我们可以看到自定义变量的价值在于它能够为表虚拟出自增id,这一特性还可以为按特殊条件排序提供非常多的便利。
二、连续值问题
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
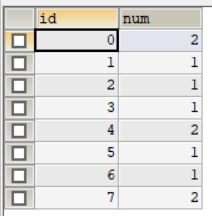
例如,给定上面的 LOGS 表, 1 是唯一连续出现至少三次的数字。
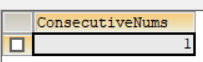
传统解法:
从以上解法可以看出为了记录连续数字,传统解法采取了利用3张表做笛卡尔积,然后再用查询条件进行筛选,这样查询虽然可行,但是性能非常不理想,如果表数据一多的话,单个查询的性能也是非常惊人的。
自定义变量解法:
我们再看看自定义变量的解法,利用自定义变量的特性将多表关联查询变成单表查询,自定义变量的解题思路是定义两个变量,一个是记录前1条记录的数字@pre,一个是计数器@cnt,如果当前记录和上条记录的num相等,则计数器+1,如果和上条的记录的num不相等,则计数器重置为1,在外面的where的句中只要筛选计数器@cnt>=3则表示相同的数字连续出现3次以上,本例子很好的体现了如何利用自定义变量来提升SQL的查询性能。
我们再看一道题目来加强下自定义变量的用法。
给定一个
给定一个 weather 表,编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id。
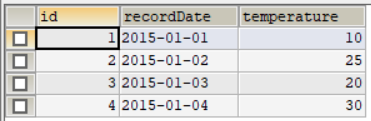
例如,根据上面给定的weather数据,返回如下id
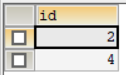
传统解法:
我们看到传统的解法里面,还是利用了join连接两张表进行筛选相邻2天的差值问题,同样的,这样查询的效率比较低,特别是在表数据量大的时候。
自定义变量解法:
而在自定义变量的解法中我们可以看到,我们定义了2个临时变量记录当前记录的的日期值@curd和记录前一天的日期值@pred,又定义了2个临时变量记录当前记录温度的@curt和前一天温度值的@pret,这样我们只要保持让datediff(@curd, @pred)=1就可以保证表记录当中2条记录的天数是连续的,只要让@curt>@pret就可以保证当前记录的温度大于上条记录的温度,然后就可以在单表中完成查询操作,自定义变量有一次在性能优化的查询中发挥了很重要的作用。
下面我们再看一个有点难度的SQL查询,看题:
X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)。
请编写一个查询语句,找出人流量的高峰期。高峰期时,至少连续三行记录中的人流量不少于100。例如表stadium:
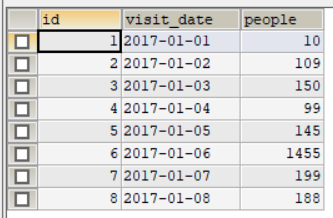
对于上述的示例数据,输出为:
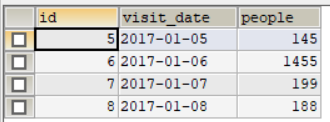
传统解法:
我们从传统解法中可以看到当求解类似于连续3行以上值的经典问题的时候,通常需要3张表做笛卡尔积才能完成查询,每一张表查询的价值在于记录某一行的数据,如果数据量大的话性能是非常低下的。
自定义变量解法:
从自定义变量的解法我们可以看到,遇到这类连续值问题的时候,自定义变量可以很好的通过临时存储迭代变量来完成查询,效率非常的高。以上的解法首先是通过定义3个变量来表示上条记录的id值@preid和当前记录的id值@curid,通过@curid - 1= @preid就可以保证记录的id是连续的,然后再定义一个计数器来记录,如果符合id连续条件的则计数器+1,如果不符合id连续条件的则计数器重置为1,最后只需要判断下计数器为3就可以了。当然在最后的的筛选条件里要注意加上
这个重要条件,否则会出现查询数据不全的情况。
mysql自定义变量这种数据特性确实也有点偏门,以前写了很多sql的时候都没用到过,但是当性能调优或者需要解决一些棘手问题的时候,这种偏门还是可以一试的,某个周末喝着咖啡坐在阳台下望着魔都的窗外阴沉的天做着LeetCode的编程挑战题有感而发写下此文,微微总结,以示敬意!
