在时序数据库的排行榜上,InfluxDB一直排行榜首,因为其高度定制的TSM引擎实现的时序数据库能够支持高性能的处理时序数据,influxDB的专业表现排行第一也是实至名归,本篇文章会从基本概念和架构原理来深入分析influxDB的实现。
一、influxDB的数据模型
下面是InfluxDB的一张示意图表:
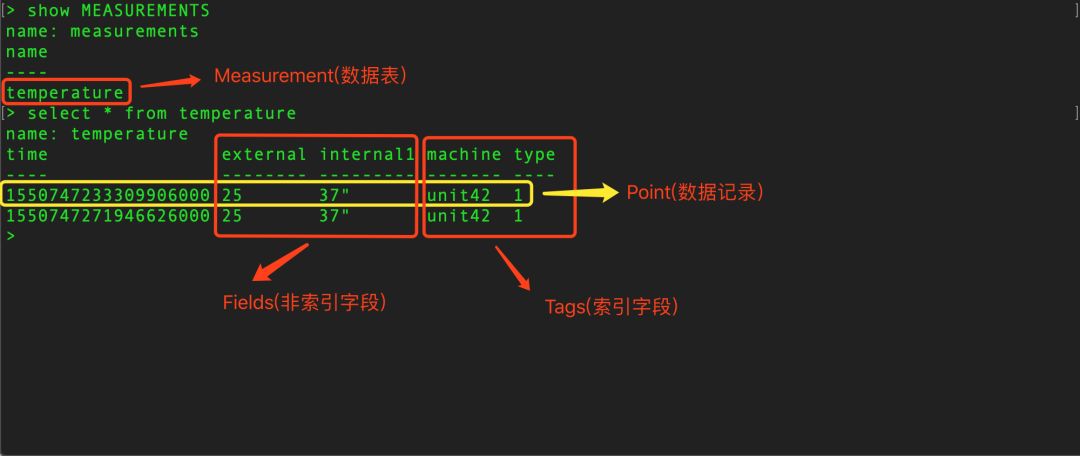
Measurement:从原理上讲更像SQL中表的概念。
Tags:维度列上图中machine和type分别是表中的两个Tag Key,其中machine对应的维度值Tag Values为{unit42},type对应的维度值Tag Values为{1},一般来说,表中的Tags组合会作为记录Point的主键的,因此主键并不唯一,比如第一行和第二行的主键完全一样,但是所有时序的查询最终都会基于主键查询后再经过时间戳过滤完成。
Fields:数值列。数值列存放用户的时序数据。
Point:类似SQL中一行记录,而并不是一个点。
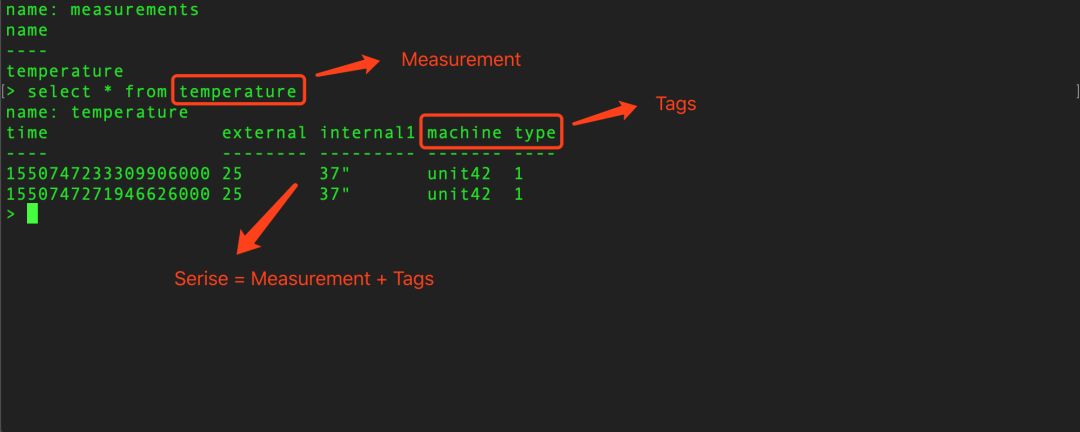
二、InfluxDB的核心概念 - Series
时序数据是随着时间的变化而生成的数据,这样的一条数据线就是时间线。InfluxDB中使用Series表示数据源,它由Measurement和Tags组合而成,Tags组合可以用来唯一标识Measurement。Series是InfluxDB中最重要的概念。下面请看示意图:
三、InfluxDB系统架构图
InfluxDB对时序数据的组织和管理有自己非常独特的设计,为了清晰的说明,下面展示一张笔者手绘的InfluxDB系统架构图:

1. DataBase:InfluxDB中数据库的概念。
2. Retention Policy(RP):数据保留策略,这是一个非常关键的概念,RP是Retention Policy的简写,翻译为数据保护策略,它有3个核心点,指定数据的过期时间,指定数据副本的数据以及指定ShardGroup的过期时间,下面举个简单的例子:
CREATE RETENTION POLICY "effective_thirty_day" ON "temperature" DURATION 30d REPLICATION 1 SHARD DURATION 12h DEFAULT
其中effective_thirty_day代表RP的名称,temperature代表数据库名,30d代表30天存活时间,1代表1个副本,12h代表Shard分片的数据存活时间。
3. Shard Group:它是多个Shard分片的集合,Shard Group是按时间来划分的,每个Shard Group会存储指定时间段的数据,而且不会互相重合,比如2018-01的数据会落在Shard Group0上,2018-02的数据会落在Shard Group1上。每个Shard Group保留数据的时长由创建Retention Policy的时候进行指定,也可以通过Retention Duration(数据过期时间)计算出来,两者的对应关系为:

将时序数据按照时间分成一个个Shard Group的好处有:
(1). 按时间分割成小粒度的数据可以优化数据过期实现的性能,当InfluxDB真正的去执行删除操作的时候,就不需要去逐条判断来删除,而可以按Shard Group为维度来判断删除,删除的性能将会大大提高。
(2).在做时间段查询的时候,比如查询最近一小时或者一天,数据分区可以根据时间维度直接选择符合筛选条件的Shard Group,而不是逐条是筛选记录是否符合查询条件,查询性能也会大大的提高。
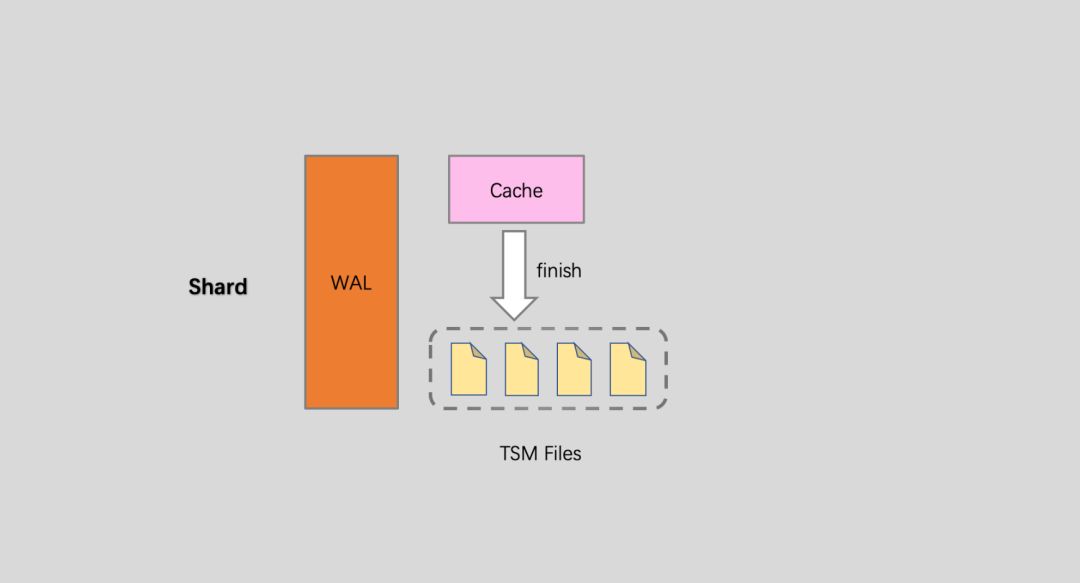
4. Shard:Shard Group实现了按时间数据分区,里面会包含大量的Shard,Shard才是InfluxDB真正存储数据以及提供读写服务的地方:
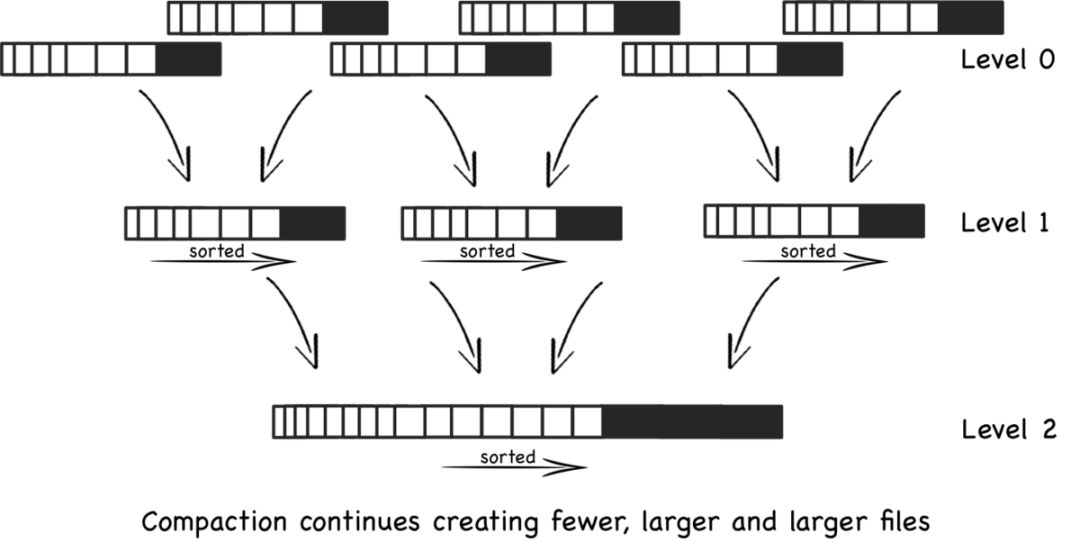
(1). Shard是InfluxDB的存储引擎实现,具体称之为TSM(Time Sort Merge Tree) Engine,负责数据的编码存储、读写服务等。TSM类似于LSM树的实现方式。LSM树是按记录来做归并,TSM则改进为按Time来做排序和归并,然后再flush和compaction等数据操作。
(2). Shard Group对数据按时间进行分区,对于Shard如何落到Shard Group分区上,这里注意,InfluxDB按Series将时序数据映射到不同的Shard上面,而不是根据Measurement进行hash映射,这样使得相同的Series的数据肯定会存在同一个Shard中,而同一个Shard中可能会包含多个Measurement的数据。
四、InfluxDB Sharding策略
分布式数据库一般有两种Sharding策略:Range Sharding和Hash Sharding,前者对于基于主键的范围扫描比较高效;后者对于离散大规模写入以及随即读取相对比较友好。通常最简单的Hash策略是采用取模法,但取模法有个很大的弊端就是取模基础N需要固定,一旦N变化就需要数据重分布,当然可以采用更加复杂的一致性Hash策略来缓解数据重分布影响。
InfluxDB的Sharding策略是典型的两层Sharding,上层使用Range Sharding,下层使用Hash Sharding。对于时序数据库来说,基于时间的Range Sharding是最合理的考虑,但如果仅仅使用Time Range Sharding,会存在一个很严重的问题,即写入会存在热点,基于Time Range Sharding的时序数据库写入必然会落到最新的Shard上,其他老Shard不会接收写入请求。对写入性能要求很高的时序数据库来说,热点写入肯定不是最优的方案。解决这个问题最自然的思路就是再使用Hash进行一次分区,我们知道基于Key的Hash分区方案可以通过散列很好地解决热点写入的问题,但同时会引入两个新问题:
1. 导致Key Range Scan性能比较差。InfluxDB很优雅的解决了这个问题,上文笔者提到时序数据库基本上所有查询都是基于Series(数据源)来完成的,因此只要Hash分区是按照Series进行Hash就可以将相同Series的时序数据放在一起,这样Range Scan性能就可以得到保证。事实上InfluxDB正是这样实现的。
2. Hash分区的个数必须固定,如果要改变Hash分区数N会导致大量数据重分布。除非使用更好的一致性Hash算法。