




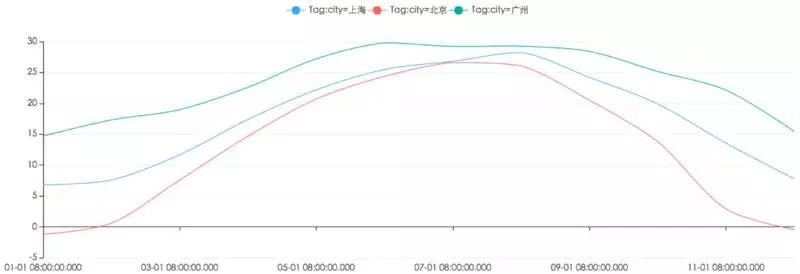
在大数据的应用场景中,如果要连续检测某地点某一时间环境的温度湿度和污染物含量指标,我们就会用到时序数据库。那什么是时序数据库,为什么要用时序数据库,下面将会做一个简单的介绍。
1. 什么是时间序列数据:
时序数据库依赖一种衡量事物随着时间的变化的数据形式,这就是时间序列数据,概括起来就是统一表示系统、过程或行为随时间变化的数据,它有一些特点:
数据总是作为新的记录往数据库插入;
数据总是按时间顺序抵达;
时间是一个主要的坐标轴。
整个时序数据库的改动主要体现在不断的插入新数据,而不是更新当前的数据。时间序列数据将系统的每个变化都记录为新的一行,从而更好的去衡量变化:分析过去变化,监测现在变化以及预测未来的变化。
2.为什么要用时间序列数据:
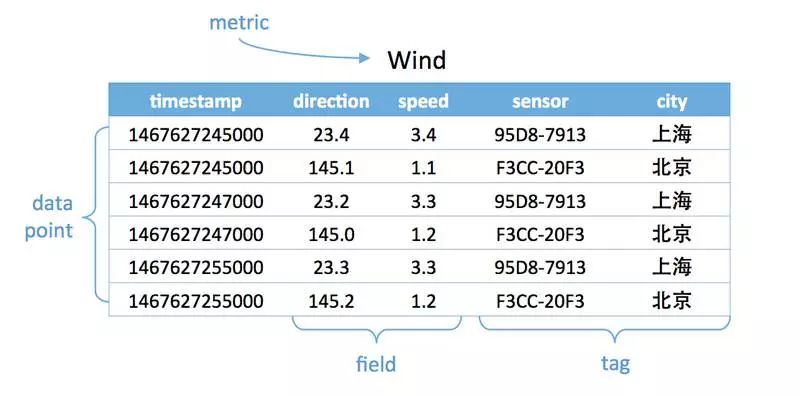
为什么对于监测类的数据不用常规数据库呢?因为传统的常规数据库在处理这种大数据集的效率非常差,监测类的数据特点是写多读少,写入数据吞吐量大,存在连续查询,响应要求高,数据结构简单,存在少量的删除和更新。而时序数据库的设计则集成了这些功能:数据保留策略,连续查询,时间聚合计算。传统数据库存储采用的都是B树,这是由于其在查询和顺序插入时有利于减少寻道次数的组织形式。B树示意图如下:
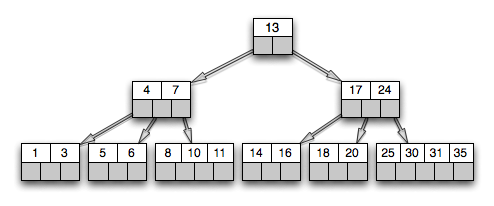
我们知道磁盘寻道时间是非常慢的,一般在10ms左右。磁盘的随机读写慢就慢在寻道上面。对于随机写入B树会消耗大量的时间在磁盘寻道上,导致速度很慢。然而对于时序数据库的设计,业界主流都采用了LSM树来代替,例如HBase。LSM树操作流程如下:
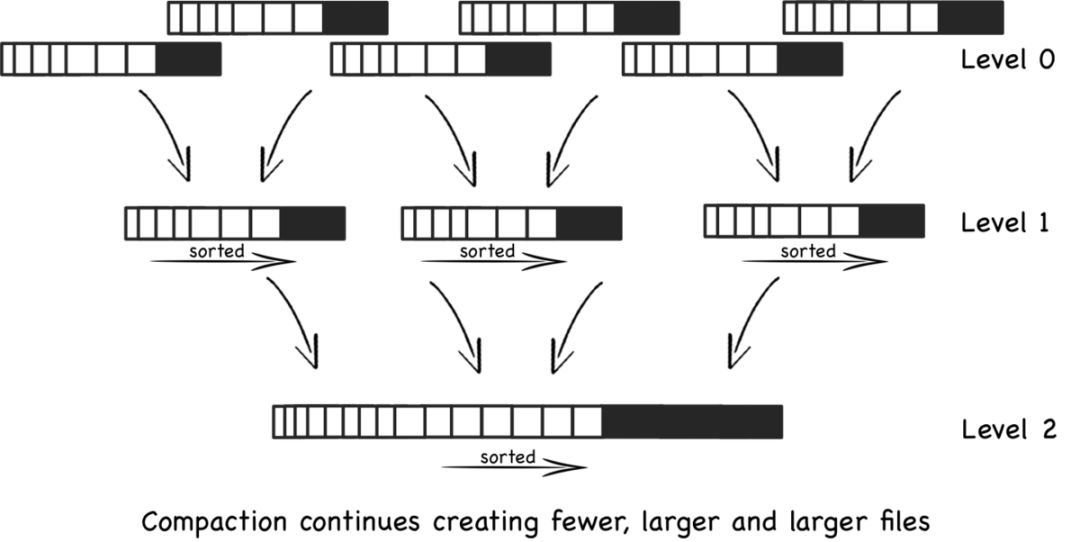
1. 数据写入和更新时首先写入位于内存里的数据结构。为了避免数据丢失也会先写到WAL文件中。
2. 内存里的数据结构会定时或者达到固定大小会刷到磁盘。这些磁盘上的文件不会被修改。
3. 随着磁盘上积累的文件越来越多,会定时的进行合并操作,消除冗余数据,减少文件数量。
LSM树的核心思想就是通过内存写和后续磁盘的顺序写入获得更高的写入性能,避免了随机写入。但同时也牺牲了读取性能,因为同一个key的值可能存在于多个HFile中。为了获取更好的读取性能,可以通过布隆过滤器进行优化。如果是海量数据的写入、存储和读取,则单机无法胜任,这时候就会采用分布式存储,分布式存储首先要考虑的是如何将数据分布在多台机器上,即如何分片的问题。时序数据库的分片方法和其他分布式数据库的分片方法基本上相通的,有如下的方案:
1. 哈希分片:这种方案实现简单,均衡性比较好,但不容易对集群进行扩展。
2.一致性哈希:这种方案均衡性和扩展性都比较好,但是实现比较复杂。
3. 范围划分:通常全局有序,但是复杂度在与map和reduce,代表有HBase。
时序数据库的分片设计,根据metric+tags分片是比较好的一种方式,因为往往会按照一个时间范围查询,这样相同metric和tags的数据会分配到一台机器上连续存放,顺序的磁盘读取是很快的。再结合上面讲到的单机存储内容,可以做到快速查询。进一步我们考虑时序数据时间范围很长的情况,需要根据时间范围再将分成几段,分别存储到不同的机器上,这样对于大范围时序数据就可以支持并发查询,优化查询速度。
在时序数据库的排行榜上,InfluxDB遥遥领先,InfluxDB是一款专业的时序数据库,只存储时序数据,因此在数据模型的存储上可以针对时序数据做非常多的优化工作。
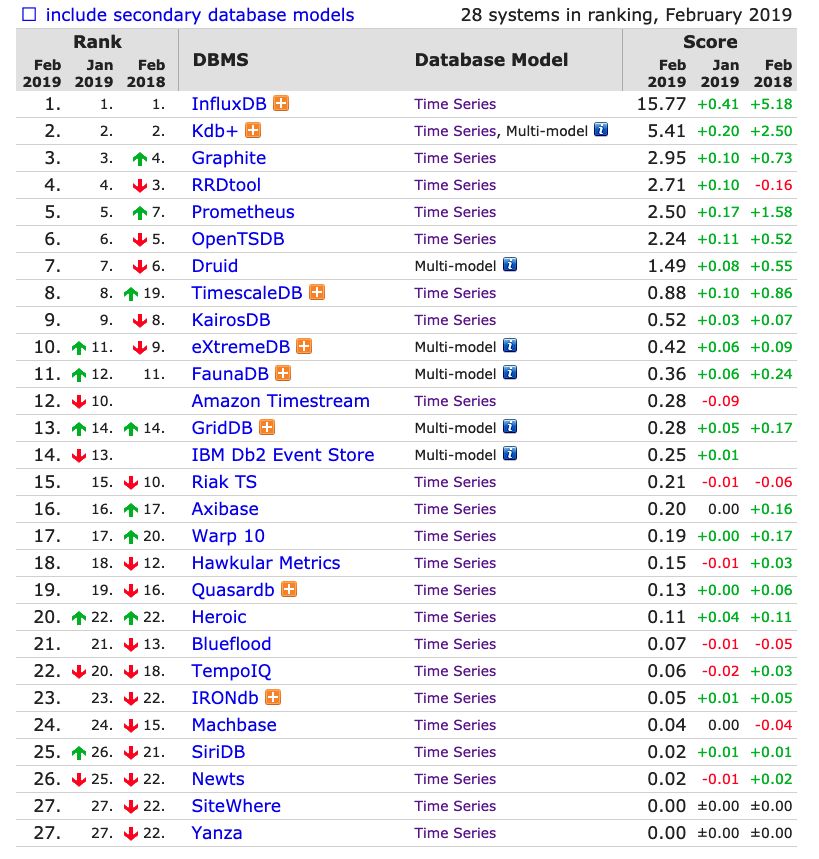
InfluxDB采用LSM树来存储,首先数据往内存写入数据,当内存容量达到一定的阈值之后就刷到磁盘里,InfluxDB也采用了metric+tags分片的方式(即seriesKey)。
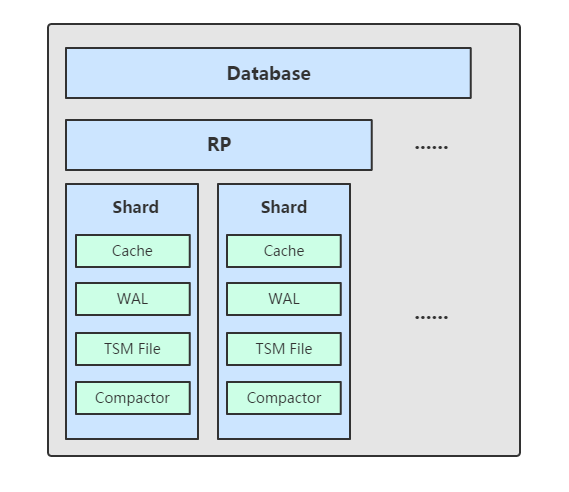
时序数据库写入内存之后的数据按seriesKey进行组织,内存中实际上就是一个Map:<SeriesKey, List<Timestamp|Value>>,Map中一个SeriesKey对应一个List,List中存储时间线数据。数据进来之后根tags+metric拼成SeriesKey,再将Timestamp|Value组合值写入时间线数据List中。内存中的数据刷到的磁盘后,同样会将同一个SeriesKey中的时间线数据写入同一个Block块内,即一个Block块内的数据都属于同一个数据源下的一个metric。这样设计的好处:
1. 同一数据源的tags将不再冗余,一个Block内会共用一个SeriesKey,大大降低了时序数据库的存储量。
2. 时间序列和value可以在同一个Block内分开独立存储,独立存储就可以对时间列以及数值列分别进行压缩。InfluxDB对时间列的存储借鉴了Beringei的压缩方式,使用delta-delta压缩方式极大的提高了压缩效率。而对Value的压缩可以针对不同的数据类型采用相同的压缩效率。
3. 对于给定数据源以及时间范围的数据查找,可以非常高效的进行查找。InfluxDB内部实现了倒排索引机制,即实现了tag到SeriesKey的映射关系,如果用户想根据某个tag查找的话,首先根据tag在倒排索引中找到对应的SeriesKey,再根据SeriesKey定位具体的时间线数据。

