




Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算,本教程将指导如何用苹果macOS系统安装Hadoop。
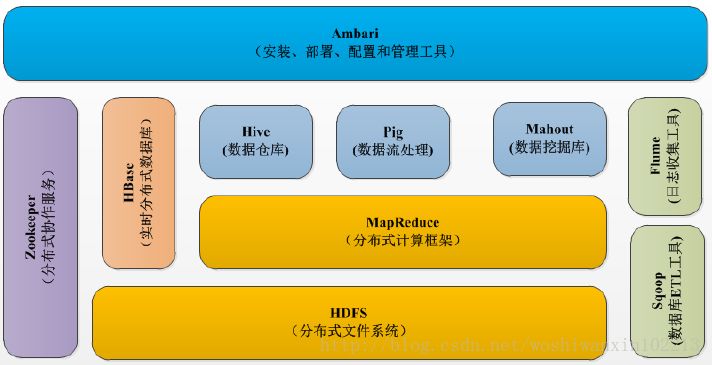
附Hadoop架构图:
环境说明
macOS Mojave 10.14.3
JDK 1.8.0_144
hadoop 3.1.1
homebrew
Homebrew安装
HomeBrew 是OSX中的方便的套件管理工具。采用Homebrew安装Hadoop非常简洁方便(中文官网:http://brew.sh/index_zh-cn.html)
复制如下代码安装:
/usr/bin/ruby -e "$(curl-fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
配置 ssh localhost(免密登录)
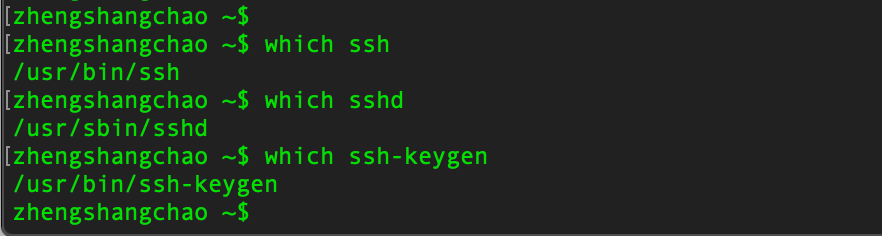
因为安装hadoop需要远程登入的功能,所以需要安装ssh工具,但Mac下自带ssh,所以不需要安装ssh。可以通过如下命令验证:
$ which ssh /usr/bin/ssh $ which sshd /usr/sbin/sshd $ which ssh-keygen /usr/bin/ssh-keygen
运行如图:
Mac OS X只需在 系统偏好设置-->共享-->远程登录 勾选就可以使用ssh了。
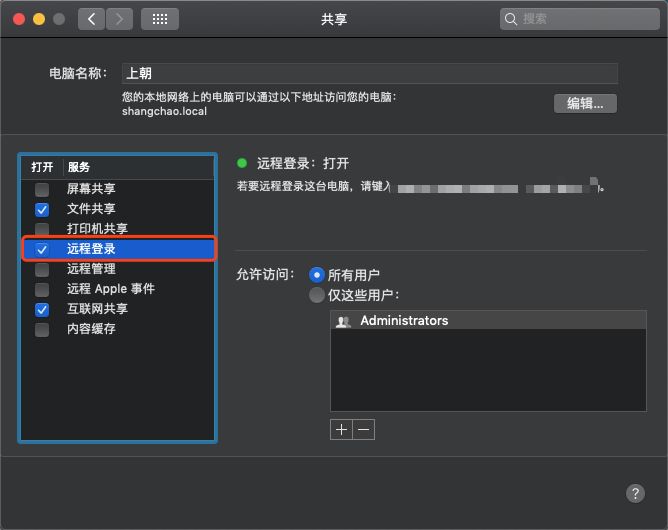
注意:如果没有执行远程登陆勾选操作,在运行ssh localhost的时候会出现:mac ssh: connect to host localhost port 22: Connection refused。
ssh免密设置:终端输入
ssh-keygen -t rsa -P ""cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
确认能否不输入口令就用ssh登录localhost:
$ ssh localhost

JDK安装
查看java版本
$ java -version
终端输出如下

brew 安装 hadoop
安装命令
$ brew install hadoop
安装结果

查看安装目录
$ brew list hadoop
配置Hadoop相关文件(此处伪分布式,还有单机模式和完全分布式模式)
改
/usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/hadoop-env.sh
,添加内容如下:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home
改
/usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/core-site.xml
,添加如下内容:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/Cellar/hadoop/hdfs/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property>
</configuration>
注: fs.default.name 保存了NameNode的位置,HDFS和MapReduce组件都需要用到它,这就是它出现在core-site.xml 文件中而不是 hdfs-site.xml文件中的原因。在该处配置HDFS的地址和端口号。
改
/usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/mapred-site.xml
,添加内容如下:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9010</value> </property>
</configuration>
变量mapred.job.tracker 保存了JobTracker的位置,因为只有MapReduce组件需要知道这个位置,所以它出现在mapred-site.xml文件中。
改
/usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/hdfs-site.xml
,添加内容如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property>
</configuration>
变量dfs.replication指定了每个HDFS默认备份方式通常为3, 由于我们只有一台主机和一个伪分布式模式的DataNode,将此值修改为1。
配置完毕,运行hadoop
跳转目录
cd usr/local/Cellar/hadoop/3.1.1/bin/
启动hadoop之前需要格式化hadoop系统的HDFS文件系统
$ hadoop namenode -format
接着进入
cd usr/local/Cellar/hadoop/3.1.1/sbin/
执行$ ./start-all.sh
或者分开启动:
$ ./start-dfs.sh
$ ./start-yarn.sh
警告:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 这对Hadoop的运行没有影响
jps命令查看java进程

通过访问以下网址查看hadoop是否启动成功
Resource Manager: http://localhost:9870
JobTracker: http://localhost:8088
Specific Node Information: http://localhost:8042
退出hadoop
进入目录
cd /usr/local/Cellar/hadoop/3.1.1/sbin/执行命令
$ ./stop-all.sh
运行界面截图
1. Resource Manager:
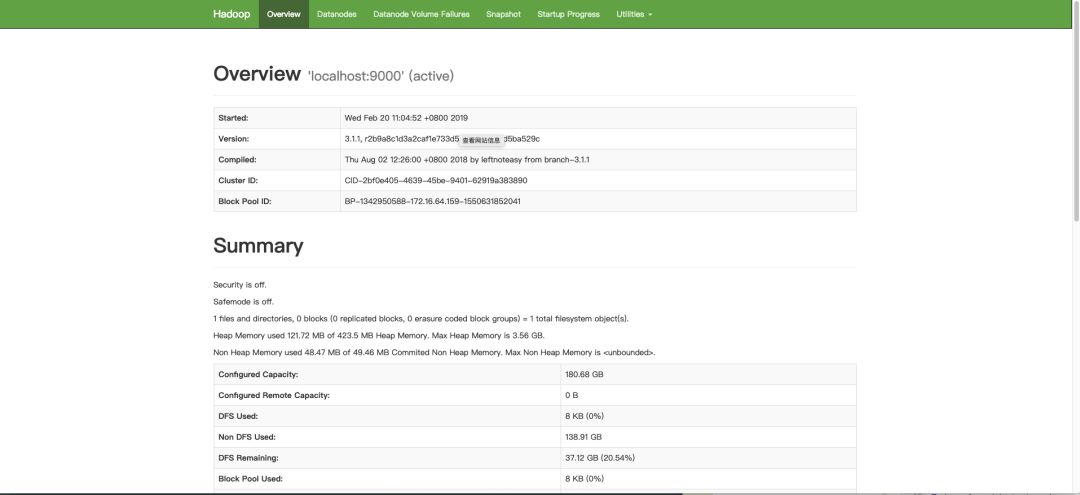
2.JobTracker:

3.Specific Node Information:
注:本文是参考https://www.jianshu.com/p/3859f57aa545博客搭建的,感谢初版作者的博客分享。
