





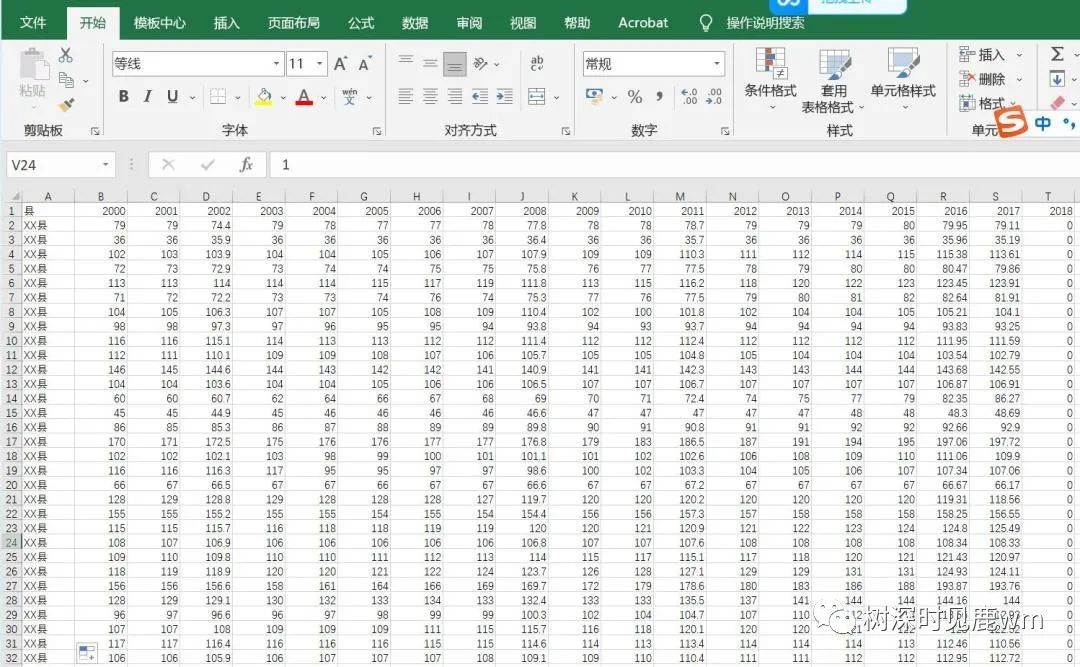
【前言】从县域统计年鉴获取1000余县2000-2018年年末人口数据,发现200余县2017、2018年末总人口数据缺失,故需要利用2000-2016或2000-2017年时间序列数据预测2017、2018年数据,转化为时间序列预测问题,综合考虑后选择灰色预测模型进行预测计算,并实现参数输入后让电脑自己跑代码,实现批量化作业。(距离上次更新,好久好久了,哈哈哈,偷了个大懒)

【数据预处理】接下来步入正题,本次用到的数据为200余县2000-2016、2000-2017年年末总人口数据,先按所要预测的情况分为缺失2017、2018年与缺失2018年两类,利用线性插值补全部分中间缺失值,并将2017、2018年缺失值用0替代。(实际过程还有缺失4、5年以上的,由于本文仅仅讨论灰色预测模型的应用,故将过程简化,方法、数据以及模型、代码仅供学习参考)

【用到的知识】
灰色预测模型、pandas模块、numpy模块、openpyxl模块
(一)灰色预测模型简介
先来简单介绍一下灰色预测模型,1979年,邓聚龙老师发表了“参数不完全大系统的最小信息镇定”论文,在1981年于上海召开的中一美控制系统学术会议上,又作了《含未知参数系统的控制问题》的学术报告,并在发言中首次使用“灰色系统”。简单来说,知道系统的信息已知成为表征其特质的是白色参数,系统信息未知无法表征其特质称为黑色参数,系统中既有白色参数又有黑色参数,被称为灰色系统,是用于研究数据量少、信息贫瘠的不确定性问题的理论方法。
基本原理与主要建模步骤:
(1) 对原始时间序列数据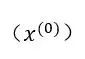 进行累加,得到新的时间序列数据
进行累加,得到新的时间序列数据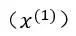 。
。
(2) 一般形式为GM(1,1),表示一个变量的一阶线性微分方程:
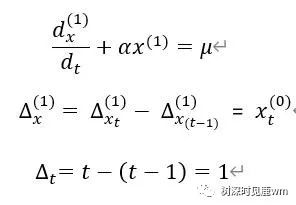
进一步化简得到:
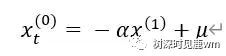
(3) 为了使得模型效果更好,需要对累加模型进行加权平均处理生成新数据,一般取0.5:
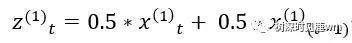
写为数列形式:
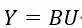
即:

(4) 利用最小二乘法估计计算系数
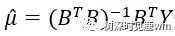
(5)代入原微分方程求解
(公式还是我一张张从word里截屏搞过来的,呜呜呜)

【计算过程】
(一)模块导入与数据读取(分别用pandas和openpyxl导入,前用于数据处理,后者用于改写excel中的数据)

(二)计算有效数据长度
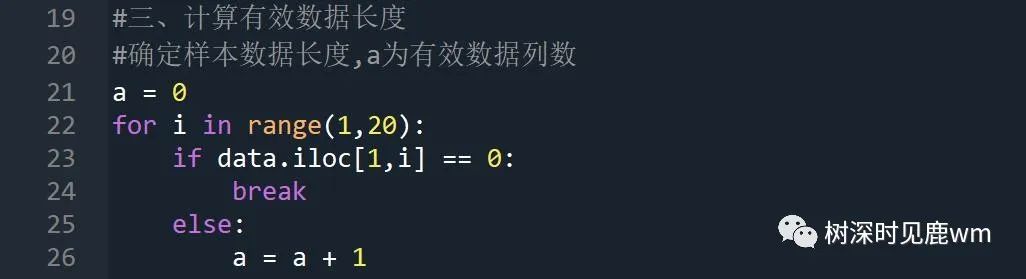
(三)对数据进行级比检验,主要目的是验证数据是否可用灰色模型进行预测,判断t和t-1项数据是否在限定范围内。(iloc用于读取excel行列数据;cell用于定位单元格;value为给单元格赋值)
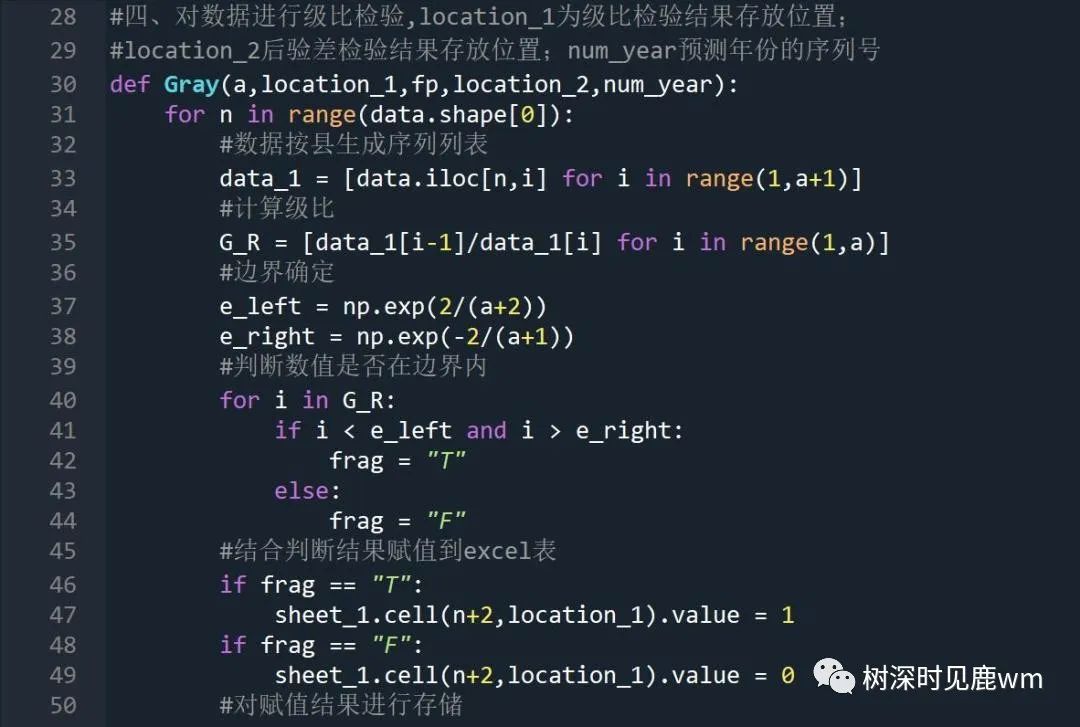
(四)灰色预测模型构建(累加列表生成、计算紧临均值列表,利用nump构造数列,利用numpy进行数列运算,估计参数)

(五)计算后验差,并将计算结构分类,存储到Excel表格中指定位置

(六)数据预测(由于求得结果是累积结果,需要作差求得原始值)

【计算结果】
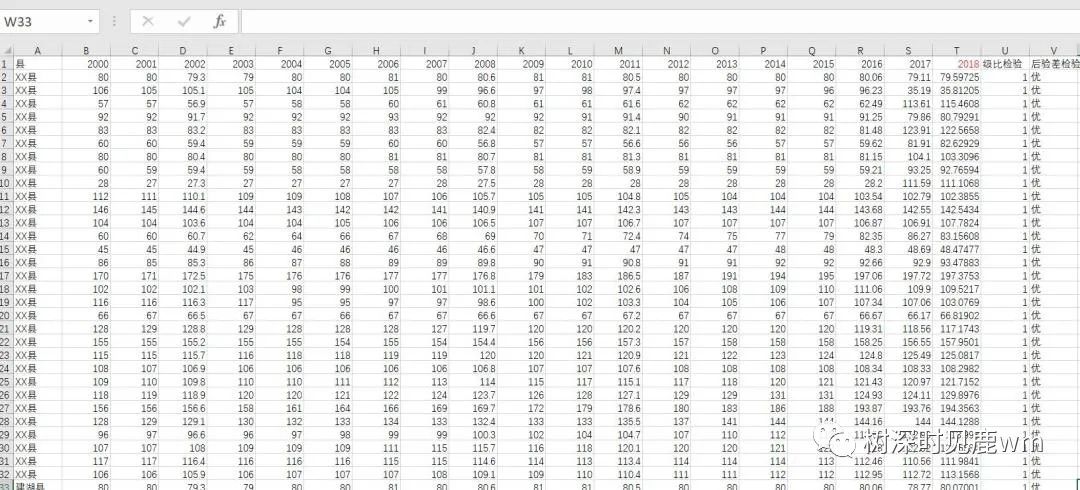
以上是本次分享的经验贴,可以参考一下,觉得不错的话,欢迎点赞、收藏、关注,后期会不断更新python相关知识和技巧,大家相互学习共同进步。
参考文献:
[1]邓聚龙.灰色系统综述[J].世界科学,1983(07):1-5.
[2]邓聚龙.灰色预测模型GM(1,1)的三种性质——灰色预测控制的优化结构与优化信息量问题[J].华中工学院学报,1987(05):1-6.DOI:10.13245/j.hust.1987.05.001.
[3]刘思峰,杨英杰.灰色系统研究进展(2004—2014)[J].南京航空航天大学学报,2015,47(01):1-18.DOI:10.16356/j.1005-2615.2015.01.001.
(表情包来自网络,如有侵权,联系删除,谢谢)

