





相信有开发或DBA小伙伴,对于mysql处理多表关联方式或者说性能方面一直不太满意,对于开发提交的join查询,一般都是比较抗拒的,从而建议将join进行拆分,避免join带来的性能问题,同时也避免了程序与数据库带来网络开销的问题
Mysql常见的几种算法
嵌套循环连接算法(Nested-Loop Join(NLJ))
基于索引的嵌套循环连接算法(Index Nested-Loop Join(INLJ))
基于块的嵌套循环连接算法(Block Nested-Loop Join(BNL)
CREATE TABLE `t1` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_a` (`a`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;create table t2 like t1;-- 插入一些示例数据-- 往t1表插入1万行记录drop procedure if exists insert_t1;delimiter ;;create procedure insert_t1()begindeclare i int;set i=1;while(i<=10000)doinsert into t1(a,b) values(i,i);set i=i+1;end while;end;;delimiter ;call insert_t1();-- 往t2表插入100行记录drop procedure if exists insert_t2;delimiter ;;create procedure insert_t2()begindeclare i int;set i=1;while(i<=100)doinsert into t2(a,b) values(i,i);set i=i+1;end while;end;;delimiter ;call insert_t2();
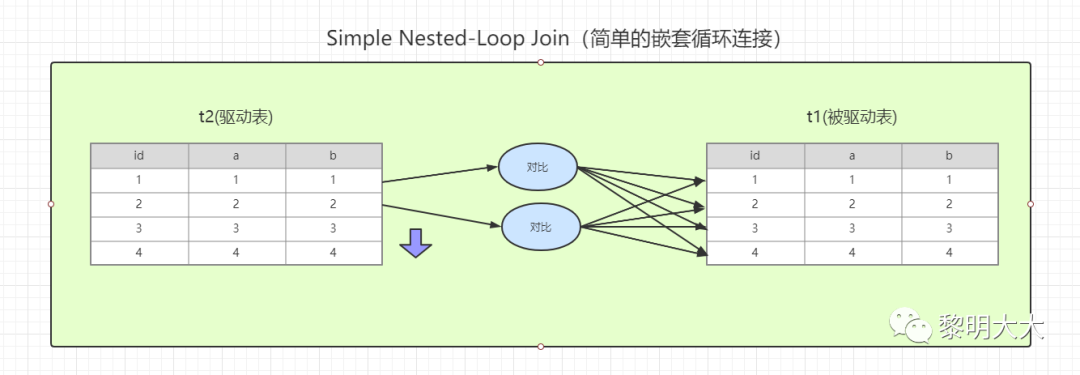
嵌套循环连接算法
(Simple Nested-Loop Join(NLJ))
适用于关联的两个字段都是索引的情况下,首先会查询驱动表的全部数据,然后一次一行循环的去和被驱动表进行关联,直至全部关联完成
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;

t2是为驱动表,t1是为被驱动表,先执行驱动表(执行计划结果id列值为一样的话,是从上往下进行执行的),mysql底层优化器会优先选择小表作为驱动表,用where条件过滤完驱动表,再和被驱动表进行关联查询。所以使用Inner join 时,排在前面的表并一定就是驱动表
当使用了left join,那么左表就是驱动表,右表作为被驱动表
当使用了right join,那么右表就是驱动表,左表为被驱动表
当使用了join,那么mysql优化器会以小表作为驱动表,大表为被驱动表
一般使用了join语句中,如果执行计划中的 Extra列中没有出现 Using join buffer 则表示该join使用算法是NLJ
从t2表中读取一行记录(如果t2表有查询过滤条件,会先执行完过滤条件,再从过滤后结果中取一行记录)
从第1步记录中,取出关联字段 a 到 t1表查找
取出 t1表满足条件的记录与t2中获取到的结果进行合并,将结果放入结果集
循环上3个步骤,直到无法满足条件,将结果集返回给客户端
List<结果集> lists = new ArrayList<>();for(t2 t2 : t2){ 外存循环for(t1 t1 : t1){ 内存循环if(t2.a().equals(t1.a())){ 条件匹配存放结果到结果集结果集 = t1的结果 + t2的结果lists.add(结果集);}}}
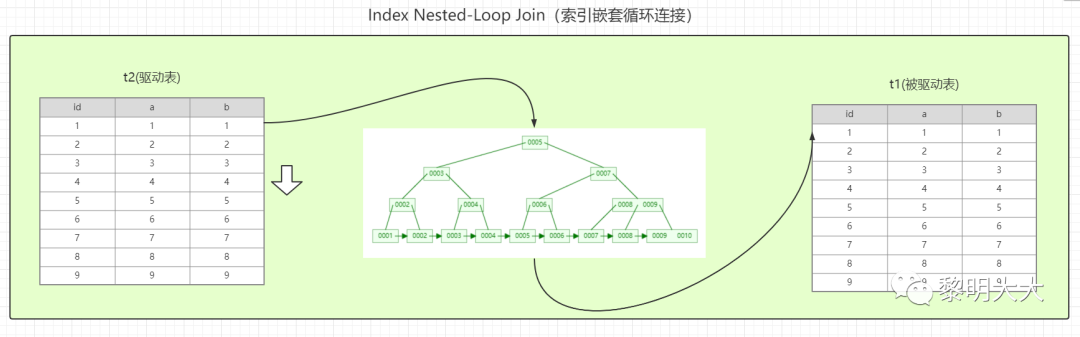
基于索引的嵌套循环连接算法
(Index Nested-Loop Join (INLJ)
索引嵌套循环连接算法是基于嵌套循环算法的改进版,其优化的思路,主要是为了减少了内层循环匹配次数,就是通过外层数据循环与内存索引数据进行匹配,这样就避免了内层循环数据逐个与外层循环的数据进行对比,从原来的匹配次数 = 外层所有行数据 * 内层所有行数据 优化成 外层所有行数据 * 索引树的高度,极大的提高的查询效率
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
从t2表中读取一行记录
从第1步记录中,取出关联字段 a 到 t1表的辅助索引树中进行查找
从t1表中取出辅助索引树中满足条件的记录拿出主键ID到主键索引中根据主键ID将剩下字段的数据取出与t2中获取到的结果进行合并,将结果放入结果集
循环上三个步骤,直到无法满足条件,将结果集返回给客户端
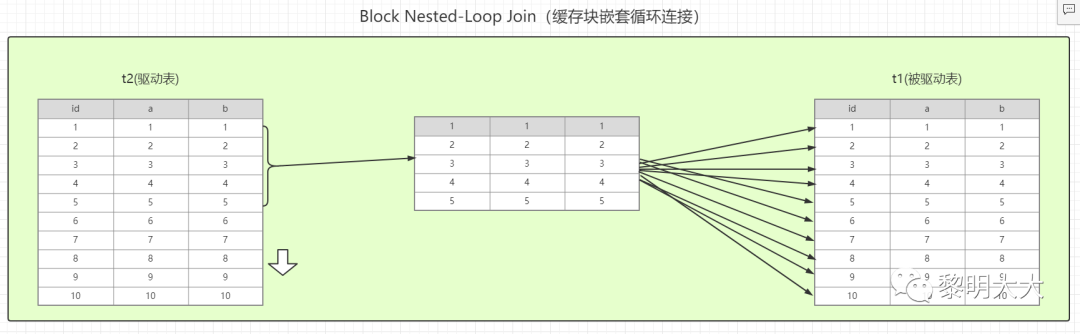
基于块的嵌套循环连接算法
(Block Nested-Loop Join(BNL)
如果关联字段不是索引或者有一个字段不是索引,MySQL则会采用此算法,和NLJ不同的是,BNL算法会多加一个join_buffer缓存块,关联时会把驱动表的数据读入到缓存块中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据批量做对比。
EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;

Extra列中的 Using join buffer (Block Nested Loop) 说明该关联查询使用了BNL算法
将t2(驱动表)的所有数据读入到join_buffer中(默认内存大小为256k,如果数据量多,会进行分段存放,然后进行比较)
把表t1的每一行数据,跟join_buffer中的数据批量进行对比
循环上两个步骤,直到无法满足条件,将结果集返回给客户端
什么是Join Buffer
什么是Join Buffer
Join Buffer会缓存所有参与查询的列而不是只有Join的列。
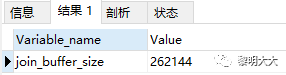
可以通过调整join_buffer_size缓存大小
join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
注意:
通过指令:Show variables like 'optimizer_switc%'; 查看配置

指令:Show variables like 'join_buffer_size%';
Join 算法总结
Join 算法总结
当用到BNLJ时,字段越少,join buffer 所缓存的数据就越多,外层表的循环次数就越少;
当用到INLJ时,如果可以不回表查询,即利用到覆盖索引,则可能可以提示速度。
我是黎明大大,我知道我没有惊世的才华,也没有超于凡人的能力,但毕竟我还有一个不屈服,敢于选择向命运冲锋的灵魂,和一个就是伤痕累累也要义无反顾走下去的心。
如果您觉得本文对您有帮助,还请关注点赞一波,后期将不间断更新更多技术文章



