




在我们比较Apache Beam和Apache Spark之前,我们必须看看两者是什么。
- Apache Beam指的是一个综合规划模型(integrated planning model)。
- 它使用了很多流式数据处理函数,可以在任何输出引擎上工作。也在很多使用的地方使用管道。
- Apache Spark是一个大规模的快速和通用数据处理引擎。
- Spark是一个快速和标准的处理引擎,并与Hadoop数据兼容。
Apache Beam

-
Apache Beam(Collection + strEAM)集成了批量和处理数据,而其他的通常用不同的API来实现。
-
非常容易将流式处理变成集合处理,反之亦然。
-
使用Beam的主要原因之一是能够在多个运行器之间切换,如-Apache Spark、Apache Flink、Samza和Google Cloud Dataflow。
-
除了Beam这个综合规划模型外,不同的运行器有不同的能力,因此很难提供一个可移植的API。
-
Apache Beam提出了灵活性。
-
Apache Beam是基于称之为抽象管道,可以被不同的管理器使用。
-
这个管道包括了从数据下载、转换到最后输出的所有处理阶段。
-
Beam 使用这些管道隐藏了低级项目,例如推送、拆分等工程师。
Apache Spark
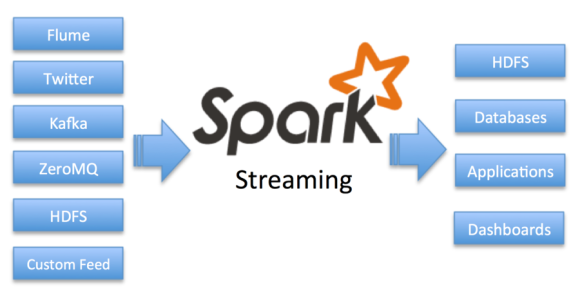
-
Spark是一个开源的分布式处理系统,用于大型数据负载。
-
它使用内存,通过对任意规模的数据进行快速分析来提高查询性能。
-
它提供Java、Scala、Python和R的开发API,并支持所有多种任务的代码重用——批量处理、交互式问答、实时分析、机器阅读和图形处理。
-
基于Hadoop MapReduce的MapReduce内存模型。
-
Hadoop MapReduce是一种用一致的分布式算法处理大型数据集的编程模型。
-
工程师可以编写一致的运算符,而不必担心作业分布,以及容错。
-
有了Spark,只需一个步骤,即把数据读到内存中然后执行操作,并把结果写回来——这就导致了更快的性能。
-
Spark包含了各种机器学习算法(ML)和图形算法的库。
Apache Beam 特性
- 统一 — 在批处理和流处理中使用单一的编程模型。
- 可移植 — 在多个执行环境中执行管道。执行环境意味着不同的Runner。例如。Spark Runner、Dataflow Runner等。
- 可扩展性 — 编写自定义SDK、IO连接器和transformation库。
Apache Spark 特性
-
Spark的处理速度很快。相比在Hadoop集群,Spark应用程序在内存中的运行速度快100倍,在磁盘上的运行速度快10倍。
-
易于使用 。Spark允许你用Java、Scala、Python和R编写可扩展的应用程序。
-
开发人员可以用他们喜欢的编程语言创建和运行Spark应用程序。
-
Spark不仅支持简单的"map "和"reduce "操作。还支持SQL查询、流处理和高级分析,包括机器学习算法和图算法。
-
在Spark的帮助下,我们可以处理实时数据流。
-
Spark可以在集群模式下独立运行,它也可以在-Hadoop YARN、Apache Mesos、Kubernetes上运行,甚至在云中运行。
Apache Beam优势
-
对于Beam,收集和分发两点是关于延迟连续性、完整性和成本的权衡。
-
不存在从收集到流的读取或重写的地方。
-
因此,如果你今天建立了一个批量管道,但你的延迟要求明天发生了变化,你可以很容易地在同一个API中把它转换成流。
-
同一条管道可以有多种使用方式。因为数据形式和处理时间是分开的。
-
这意味着当你从一个资产转移到更高级的资产时,你不必重写代码。
-
可以快速比较选项,以找到适合当前需求的环境和性能的正确组合。
Apache Spark优势
-
Apache Spark最好的一点是背后有个庞大的开源社区。
-
它开辟了各种大数据的机会。
-
它拥有处理多种任务负载的能力,包括互操作性问题、实时分析、机器学习和图形处理。
-
一个应用程序可以无缝地组合多种函数。
-
由于其处理低内存数据的能力,它可以处理许多数学上的挑战。
-
包含精心设计的图和数学算法库。
结论
我们可以说两者(Apache beam和Apache spark)都是用来解决同样的问题的,但也有一个小区别。
从表面看,Apache beam看起来像一个框架,它隐藏了处理的复杂性和技术细节,而Spark是一种技术,需要深入研究一下。
Spark有助于简化具有挑战性和计算密集型的任务,即大量处理实时或归档数据(包括结构化和非结构化数据),并且整合了对应复杂功能,如机器学习和图算法。
参考
- https://beam.apache.org/
- https://www.youtube.com/watch?v=znBa13Earms
原文标题:Apache Beam Vs Apache Spark: A Quick Guide
原文作者:Udit Raj
原文地址:https://blog.knoldus.com/apache-beam-vs-apache-spark-a-quick-guide/
