




这是关于Spark结构化API Dataframe & Datasets系列博客的第二部分。在第一部分中,我们介绍了Dataframe,如果你是Spark的新手,我建议你先看看那篇博客。在这篇博客中,我们将介绍Spark DatasetsAPI,让我们开始吧。
Dataset API
数据集是两个特性的结合:typed和untyped的API,如图所示:
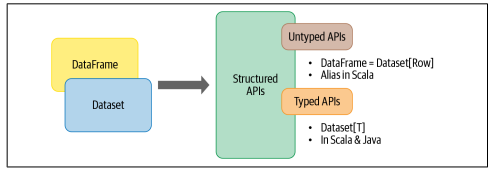
通过比较Dataframe来更好地理解Datasets,Scala中的Dataframe是一个通用对象集合的别名,即Datasets[Row],其中Row是泛型,可以容纳不同类型的字段;另一方面,Datasets文档是这样说的:
一个拥有强类型的领域特定对象集合,可以使用函数式或关系操作进行并行转换。每个Dataset [在Scala中]有一个untyped 的视图,称为Dataframe。
如何创建Dataset?
由于Dataset是强类型,首先需要了解的是schema。也就是数据类型。在Scala中创建Dataset的最简单方法是使用case类来推断schema。例子如下:
String,cca2: String, cca3: String, cn: String, latitude: Double,longitude: Double, scale: String, temp: Long, humidity: Long, c02_level: Long, lcd: String, timestamp: Long) val ds = spark.read .json("dbfs:/FileStore/iot_device.json") .as[IoTDeviceData] ds.show(5, false) (Image2)
https://i0.wp.com/blog.knoldus.com/wp-content/uploads/2022/06/Image_2-1.png?ssl=1
Dataset操作
我们可以在Dataframe上执行的相同的转换和操作。让我们看几个例子:
从一个过滤器的转换开始
val filteredDS = ds.filter(col => col.temp > 30 && col.humidity > 70) filteredDS.show() (Image3)
上述实现为我们提供了Dataframe和Dataset api之间的另一个区别,因为 Dataset api中的过滤器转换是一个重载方法的过滤器 (func: (T) >Boolean): Dataset[T],接受lambda函数,func: (T) > Boolean 作为它的参数。
而在Dataframe API中,filter()的条件表示为类似sql的DSL操作。
Dataframe和Dataset在b/w的区别
如果你读过我之前关于Dataframe的博客,在这篇博客中你一定想知道使用场景,一起看看:
- 想要严格的编译类型安全,那么就使用Dataset。
- 项目需要高级表达式,如过滤器、映射、聚合或SQL查询,那么你可以选择同时使用Dataframe和Dataset。
- 想利用并受益于Tungsten的高效序列化编码器,使用Dataset。
- 想高效利用空间和速度,使用Dataframe。
- 想在编译时而不是在运行时捕获错误,那么在下图的基础上你可以选择你的API。
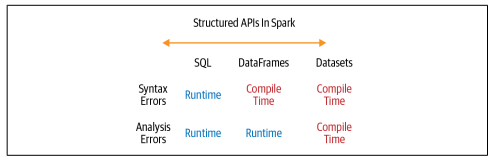
结论
以上是Spark结构化API的第一部分,我们已经涵盖了Dataset的所有基础知识。如果你正在阅读这个总结,感谢你能坚持到博客的最后,如果你喜欢我的文章,点击这里查看我更多的博客。
参考
https://docs.databricks.com/getting-started/spark/datasets.html
原文标题:Apache Spark’s Developers Friendly Structured APIs: Dataframe and Datasets
原文作者: Raviyanshu
原文地址:https://blog.knoldus.com/apache-sparks-structured-apis-dataframe-and-datasets/
