




Spark的计算比map-reduce job更快。如果我们没有为重复计算而设计job,那么对于数十亿和数万亿的数据来说,性能会下降。因此,需要在计算阶段使用优化技术,作为提高性能的方法之一。
cache() 和persist() 方法提供了一种优化机制来存储spark Dataframe的中间结果。以便在后续action中利用。
Spark persist()
当我们持久化一个Dataset时,每个节点在内存中存储它的分区数据,并在该数据集的其他action中重复使用它们。Spark的节点上的持久化数据是容错的。如果我们丢失了Dataset的任何分区,将自动通过使用最初转换来重新计算。
Dataframe persist格式和例子
Spark persist()方法将DataFrame或Dataset存储到一个StorageLevel中。
格式
- persist():Dataset.this.type — 将存在
MEMORY_AND_DISK。 - persist(newLevel : org.apache.spark.storage.StorageLevel)
例子


cache()
Spark cache() 在Dataset类中内部调用persist()。
cache的格式和例子
格式
cache() : Dataset.this.type
例子
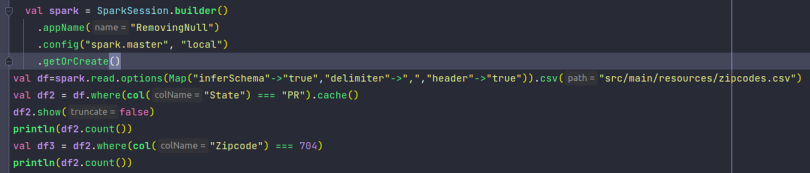
结论
这篇博客讲了spark中的cache()和persist()方法,它们是种优化技术,用来保存dataset和dataframe中间计算结果。
原文标题:Cache and Persist in Apache Spark Dataframe
原文作者:RakhiPareek
原文地址:https://blog.knoldus.com/cache-and-persist-in-apache-spark-dataframe/
最后修改时间:2022-09-19 21:03:52
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
