




赛事背景
2014年11月,亚马逊推出了一款全新概念的智能音箱Echo,通过语音指令交互控制硬件设备。截止2016年4月,Echo的累计销量已经突破300万台。2017年12月累计数千万台。亚马逊Echo音箱的推出标志着以语音交互为实用化的落地方案。
以智能音箱为代表的声控智能硬件在我国已经得到了商业化的大规模推广。2020年我国占有全球智能音箱销售量的51%,位居全球第一,而同期美国的份额从44%下降到了24%。
比赛链接:http://challenge.xfyun.cn/topic/info?type=time-frequency-2022&ch=ds22-dw-zmt05
赛事任务
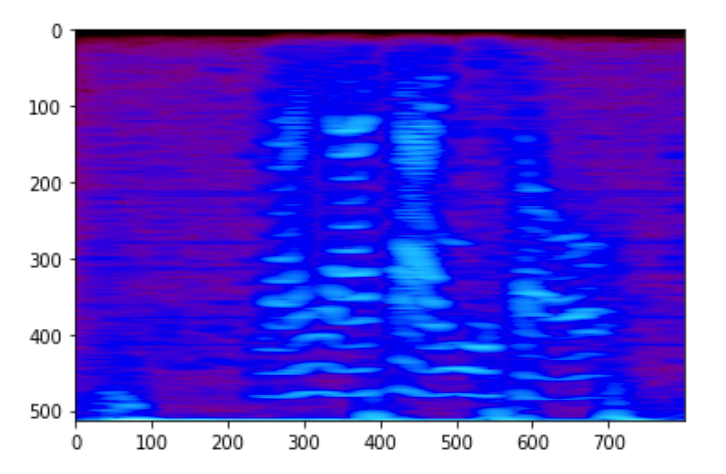
赛题提供具有24句语音交互指令的语音时频谱数据集(spectrogram dataset),选手需要完成搭建网络模型,基于密集多层网络、卷积网络和循环网络等基本结构的组合,进行有效预测。
评审规则
1.数据说明
本次比赛为参赛选手提供了语音信号及其对应的语句标签。出于数据安全保证的考虑,所有数据均为脱敏处理后的数据。
2.评估指标
本模型依据提交的结果文件,采用Macro-F1进行评价。
解题思路
赛题给出的是提取好的频谱图,因此我们只需要完成分类操作即可。在分析的过程中我们发现:
数据整体非常规整,尺寸相同; 类别数据分布不算非常不均衡;
步骤1:读取图片路径
train_df = pd.read_csv('./train.csv')
train_df['path'] = './train/' + train_df['image']
test_df = pd.read_csv('./提交示例.csv')
test_df['path'] = './test/' + test_df['image']
定义数据集,读取方法:
class XunFeiDataset(Dataset):
def __init__(self, img_path, label, transform=None):
# 定义成员变量
def __getitem__(self, index):
# 读取文件
def __len__(self):
return len(self.img_path)
步骤2:定义模型
使用ResNet预训练模型权重,修改最终的全连接节点数为类别数:
class XunFeiNet(nn.Module):
def __init__(self):
super(XunFeiNet, self).__init__()
model = models.resnet18(True)
model.avgpool = nn.AdaptiveAvgPool2d(1)
model.fc = nn.Linear(512, 24)
self.resnet = model
def forward(self, img):
out = self.resnet(img)
return out
步骤3:定义训练代码
def train(train_loader, model, criterion, optimizer):
model.train()
train_loss = 0.0
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
return train_loss/len(train_loader)
步骤4:训练与调参
本次赛题建议对数据进行处理的过程中,多去调节数据扩增方法,此步骤对模型的精度影响较大。
A.Compose([
A.RandomCrop(450, 750),
A.RandomContrast(p=0.5),
])
对于优化器和学习率也可以更具需要进行调整,整体的代码可以在1080ti上迭代完成。
完整代码:https://gitee.com/coggle/competition-baseline/tree/master/competition/%E7%A7%91%E5%A4%A7%E8%AE%AF%E9%A3%9EAI%E5%BC%80%E5%8F%91%E8%80%85%E5%A4%A7%E8%B5%9B2022
# 竞赛交流群 邀请函 #

每天Kaggle算法竞赛、干货资讯汇总
与 22000+来自竞赛爱好者一起交流~

