




PyCaret
是一个低代码库,可以提高您的工作效率。由于花费更少的时间进行编码,您和您的团队现在可以专注于业务问题。PyCaret
是一个简单易用的机器学习库,可帮助您用更少的代码行执行端到端 ML 实验。
安装方法
pip install pycaret
使用PyCaret进行分类
读取数据集:
train = pd.read_csv('../input/titanic/train.csv')
test = pd.read_csv('../input/titanic/test.csv')
sub = pd.read_csv('../input/titanic/gender_submission.csv')
导入分类模型:
from pycaret.classification import *
查看数据类型:
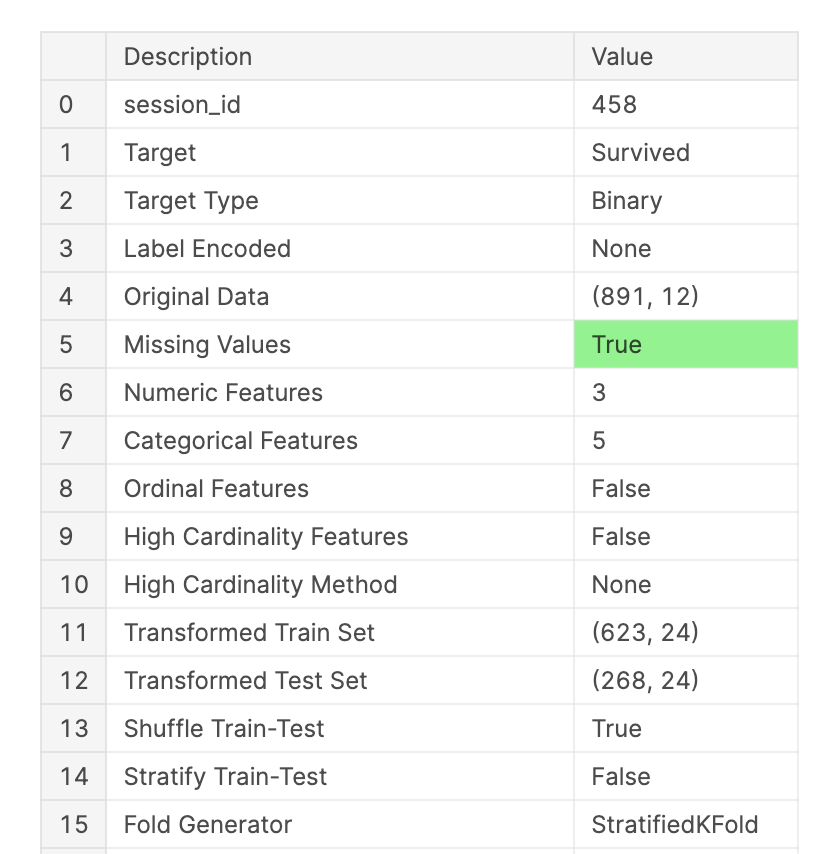
clf1 = setup(data = train,
target = 'Survived',
numeric_imputation = 'mean',
categorical_features = ['Sex','Embarked'],
ignore_features = ['Name','Ticket','Cabin'],
silent = True)
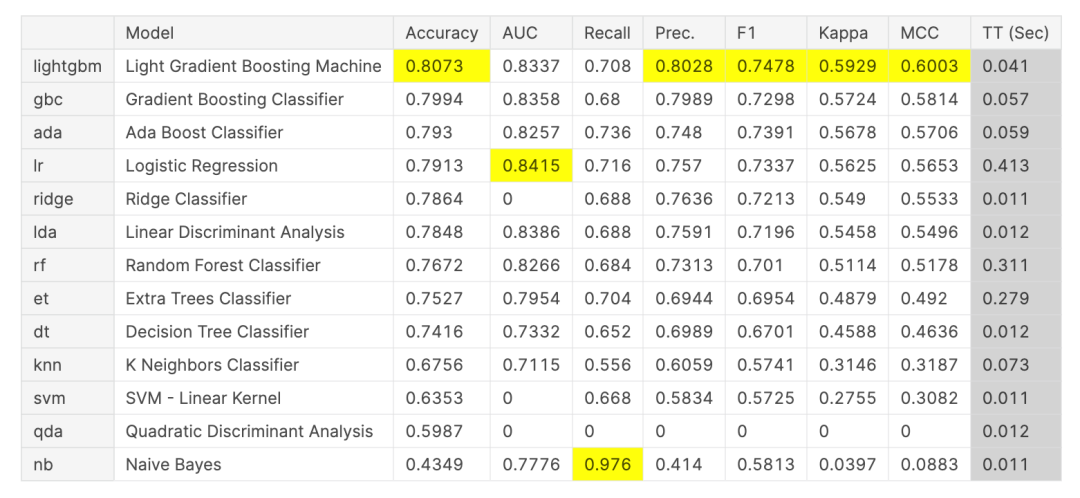
运行 & 对比精度:
compare_models()
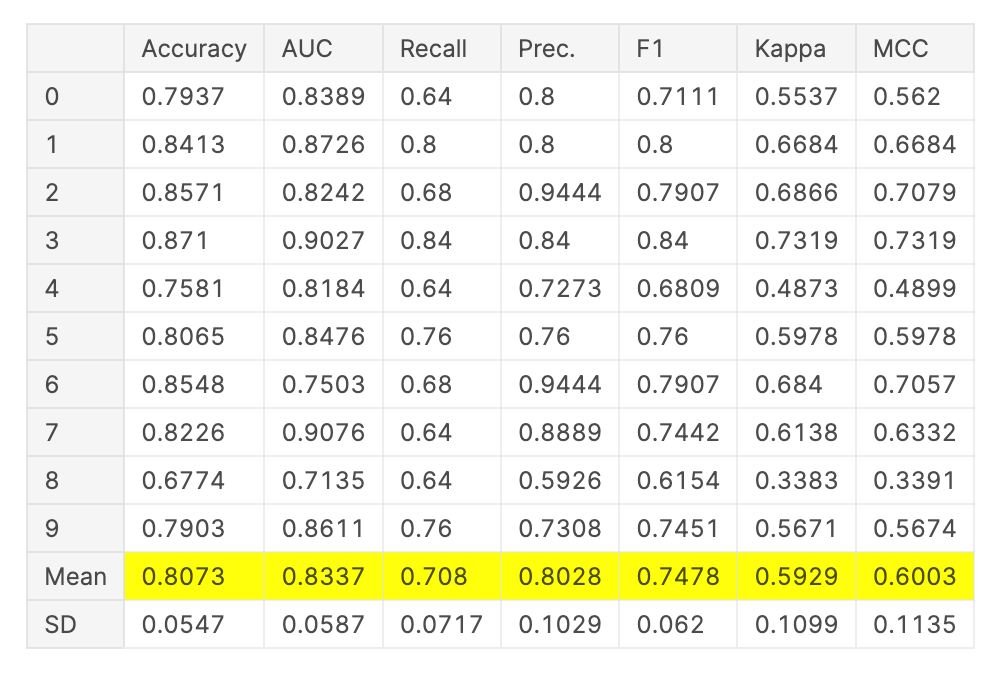
创建单个模型:
lgbm = create_model('lightgbm')
对单个模型进行调参:
tuned_lightgbm = tune_model(lgbm)
plot_model(estimator = tuned_lightgbm, plot = 'learning')
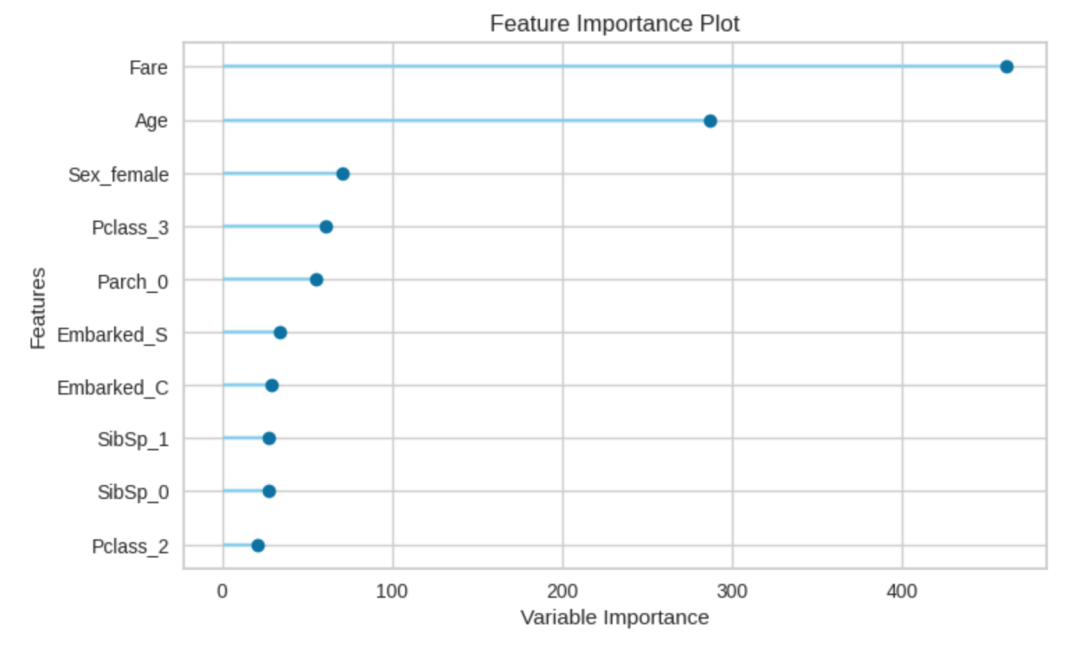
打印重要性:
plot_model(estimator = tuned_lightgbm, plot = 'feature')
对测试集进行预测:
predict_model(tuned_lightgbm, data=test)
使用PyCaret进行回归
读取数据集:
train = pd.read_csv('../input/house-prices-advanced-regression-techniques/train.csv')
test = pd.read_csv('../input/house-prices-advanced-regression-techniques/test.csv')
sample= pd.read_csv('../input/house-prices-advanced-regression-techniques/sample_submission.csv')
导入回归模型:
from pycaret.regression import *
运行 & 对比精度:
compare_models()
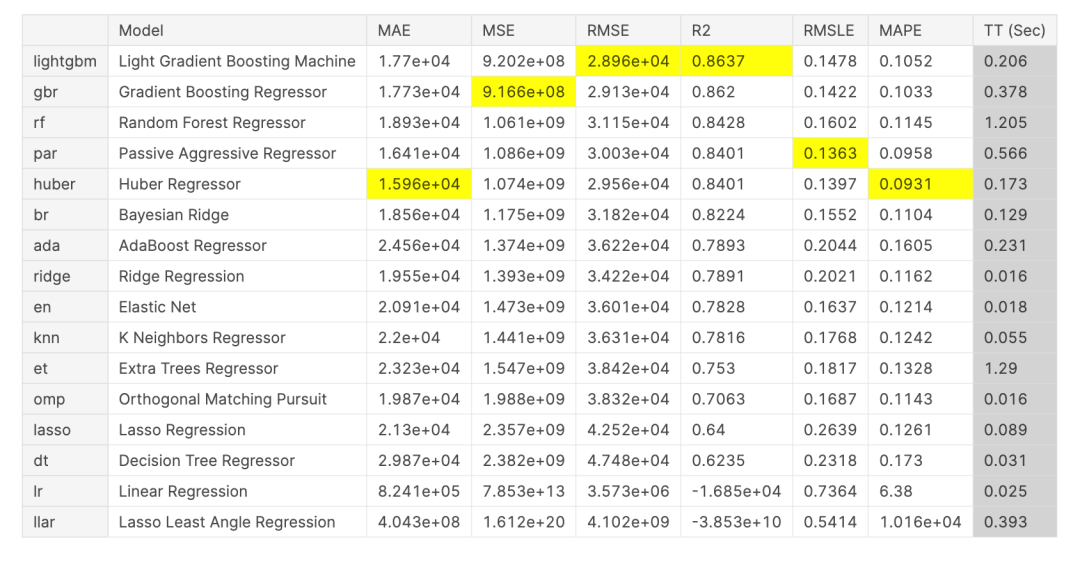
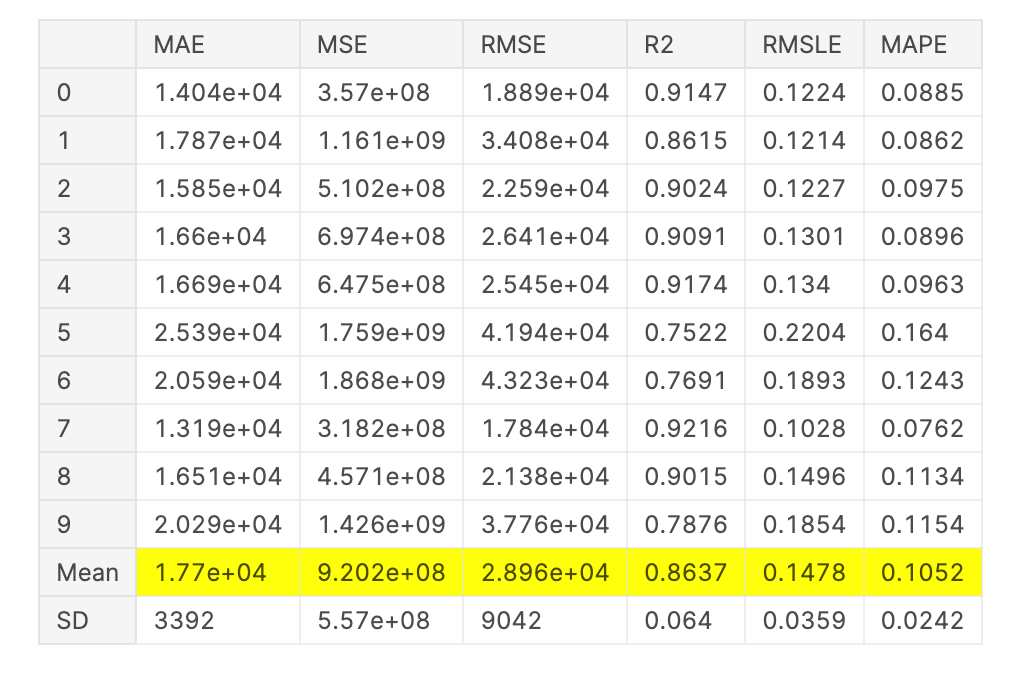
创建单个模型:
lgbm = create_model('lightgbm')
在线运行代码:https://www.kaggle.com/code/frtgnn/pycaret-introduction-classification-regression
学习交流群已成立


文章转载自Coggle数据科学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
