




短文本自动生成技术属于自然语言生成(NLG)的研究范畴,是指计算机能够根据知识库或逻辑形式的机器表述自动生成一段符合语法和逻辑的自然语言 文本。
相对于长文本,短文本内容特征稀疏、噪声大、上下文依赖性强,同时受网络传播的影响,短文本还具有海量性、实时性、内容多样性等特点。
短文本生成方法
传统的短文本生成方法多是采用基于模板或规则、基于统计语言模型的方法。随着人工智能技术和神经网络的变革与发展,现基于神经网络模型的生成方法成为短文本生成领域的主流方法。
传统文本生成方法
基于模板或规则的方法是文本生成任务中早期的使用方法。其原理是通过抽取语义相似句子的共同特征,形成由变量和固定词组成的系列模板,再通过检索语义相似的模板。
统计语言模型是用来计算一个词语、句子甚至是文档概率分布的模型,能够使计算机从概率角度预测下一个词语或句子出现的可能性及语义合法性。
常见的统计语言模型包括 :N 元文法模型、马尔可夫模型、最大熵模型、决策树模型等。基于统计语言模型的生成方法最初多应用在机器翻译中,其后基于统计翻译的思想也被广泛应用在诗歌创作等短文本生成任务。
基于神经网络的生成模型
短文本生成领域常用的神经网络模型主要包括Seq2Seq 模型、VAE 模型、GAN 模型、Transformer模型等四类。
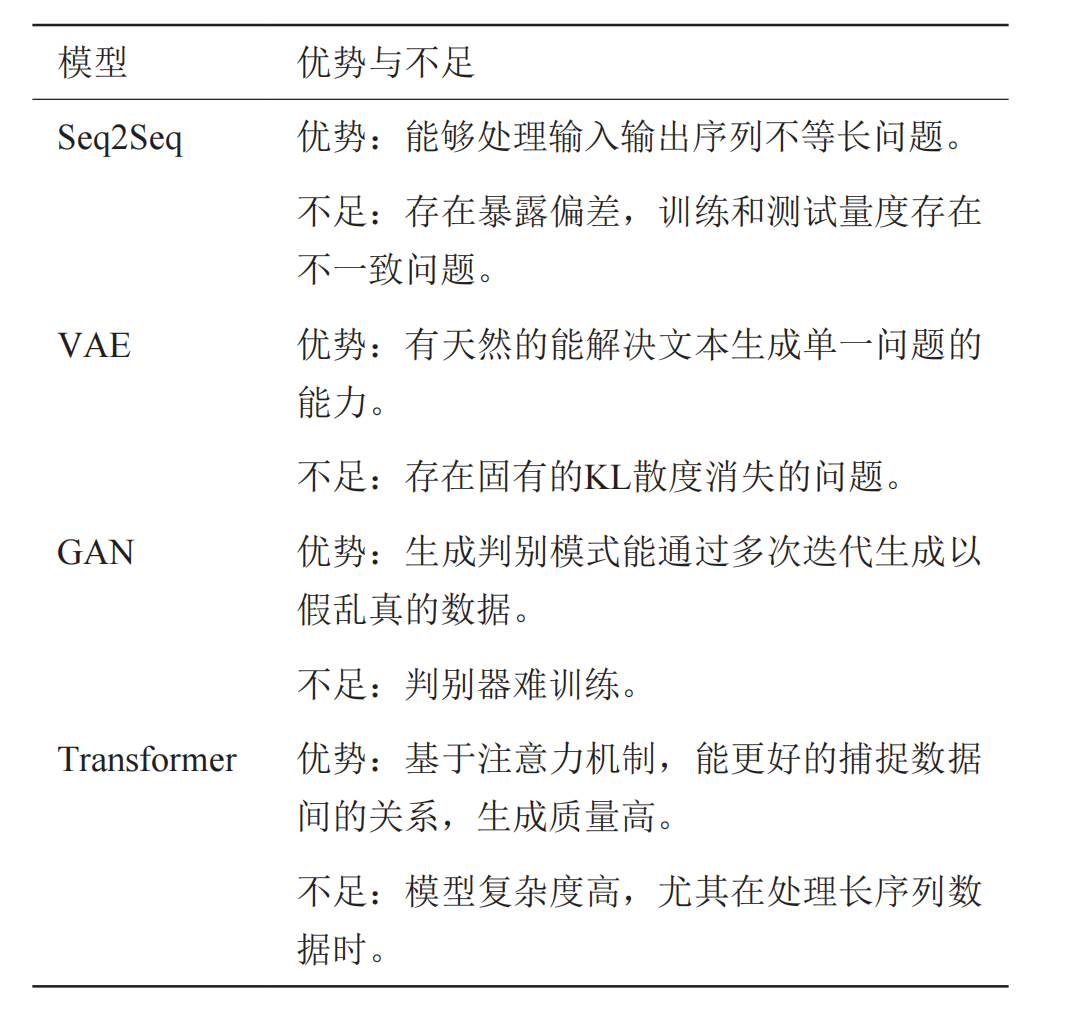
Seq2Seq模型
Seq2Seq 采用基础的编码器 - 解码器(Encoder-Decoder)结构。编码器可以将句子编码成一个能映射其大致内容的固定长度的潜在向量,然后通过解码器将其还原为目标序列。
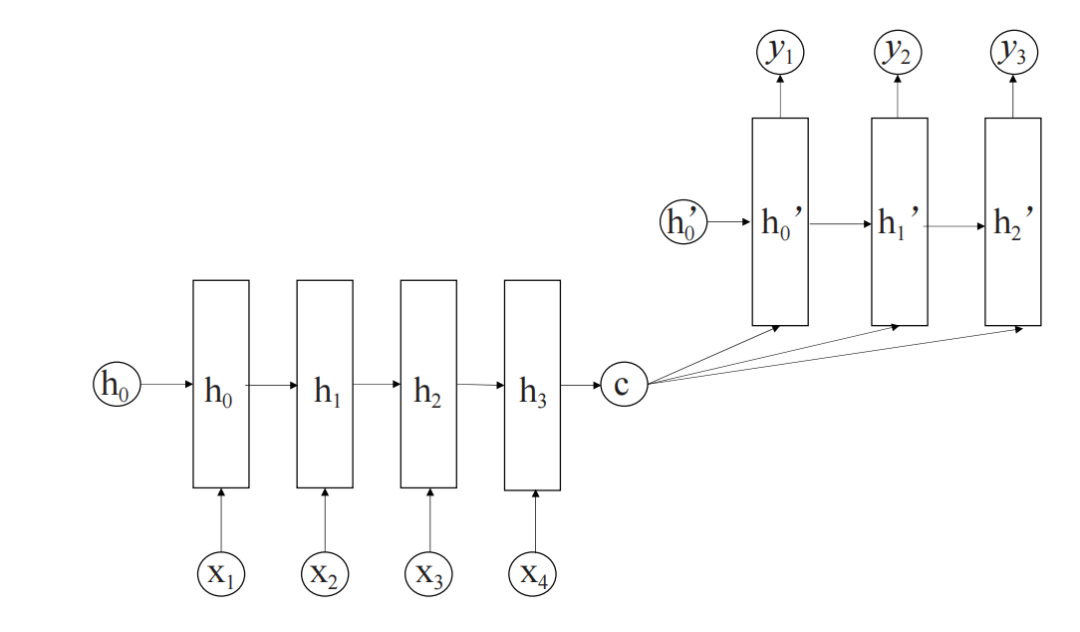
VAE 模型
VAE 生成模型也是编码器 - 解码器的框架,VAE 变分自编码器,是在自编码器(Auto encoder)的基础上添加了隐变量,并将训练数据指定为一个联合概率分布,即编码器端将输入的高维数据先映射成符合某种概率分布的低维隐变量,解码器端按照条件概率由隐变量还原为目标数据。
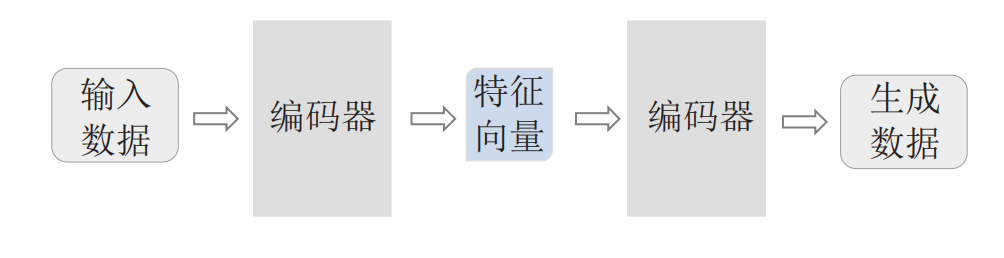
GAN 模型
GAN(生成对抗网络)由生成器和判别器构成,其基本原理是将生成器生成的样本和真实数据输入到判别器中进行真假判断,通过迭代训练,直至生成器的生成样本不能被判别器识别,即可达到理想的生成效果。
Transformer 模型
Transformer由 Google 团队在 2017 年提出,模型也是采用 Encoder-Decoder架构,是完全采用注意力机制来实现加速深度学习算法的生成模型。
Transformer 模型能并行化处理,模型生成效率高,但相对时间复杂度也较大,同时Transformer 需要事先设定输入长度,对长序列关系的捕捉也有一定限制。
短文本生成需求演化方向
短文本自动生成技术的应用主要可分为创作型生成和辅助型生成两大类。创作型生成包括诗歌生成、评论文本生成和对话生成等。辅助型生成任务包括标题生成、注释(描述)生成和短文本摘要等。
语句连贯表达
语句连贯表达是指在生成语句时句子是准确、流畅且符合逻辑的。语句连贯表达是短文本生成任务的基础目标。当前多是采用融合模型或检索的方式、加强输入数据约束、增加预处理模型等三个方面进行。
语句多样表达
语句的多样表达在短文本任务中,是解决生成回复较单一或者存在较多“安全性”回复(如“我不知道”、“我明白了”等意义低且简单的通用性回复)问题。语句多样性的实现主要通过改变目标函数、搜索算法或增加生成内容控制单元。
语境关联表达
语境关联表达主要针对短文本摘要、对话生成、评论生成等短文本生成应用中输入与响应不一致或关联性不强的情况。为解决这类问题,近年的研究多是基于主题词 ( 话题词 ) 约束、情感约束、引入外部知识约束的方法。
个性化生成
个性化表达是指在评论、对话短文本生成任务中,模型可以模仿和生成更贴近人类表达和行为特性的内容。个性化表达常用的方法可概况为增加风格和人格特性、基于用户个性化信息两方面。
短文本生成评价方法
为了评价生成文本质量的好坏,短文本生成领域目前常用的评价方式主要包括自动评价指标、人工评估指标和利用训练神经网络来模拟人打分流程的模拟人工评估方式。
常用指标可概括为三类 :
基于词重叠率的评价指标 基于语言模型优劣的评价指标 基于场景需求的多样性评价指标
短文本任务中常用的基于词重叠率的指标主要为 BLEU 和 ROUGE。
BLEU的本质是对两个句子中重复词频率的计算,在短文本生成任务中,通过 BLEU 可获得参考文本和生成文本的重合程度,重合程度越高代表生成文本的质量越高,句子流畅性和一致性越好。
BP 为长度惩罚因子,c 为参考句子长度。BLEU 包括 BLEU-1、BLEU-2、BLEU-3、BLEU-4,分别表示一元组至四元组的重合程度。但 BLEU 只从词的角度评估内容,缺乏对语义和句子结构的评估,在短文本生成任务中,通常和其他评价指标共同衡量生成效果。
ROUGE是基于 n元词组、序列和词对的重复率的评估方式。ROUGE 分 为四种:ROUGE-N(N通常取1-4)。
困惑度 Perplexity是将词重复出现概率用句子长度归一化表示的指标。困惑度在短文本任务中可以衡量生成评论或对话的质量,是对句子通顺,没有词序颠倒的衡量。
# 竞赛交流群 邀请函 #

每天Kaggle算法竞赛、干货资讯汇总
与 22000+来自竞赛爱好者一起交流~

