




千言介绍
千言是由百度联合中国计算机学会、中国中文信息学会共同发起的面向自然语言处理的开源数据集项目,携手高校和企业的数据资源研发者共同建设中文开源数据集,旨在推动中文信息处理技术的进步。
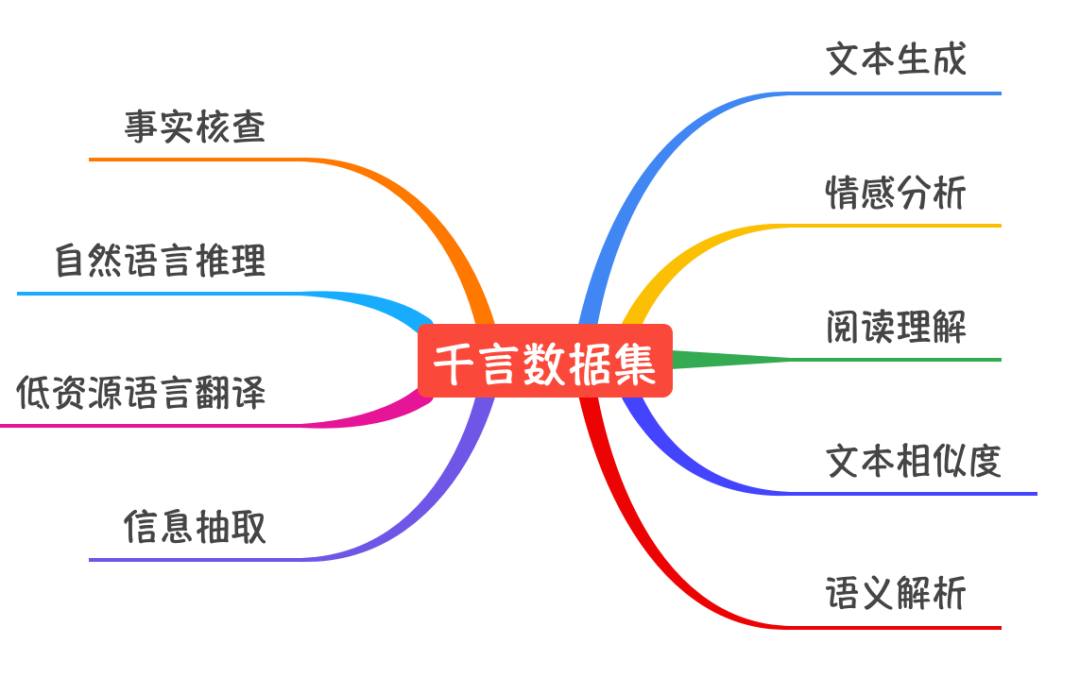
千言开源数据集项目自 2020 年 8 月发布以来,吸引来自清华、哈工大、中科院、美团、腾讯、OPPO 等近20家企业和高校的数据集作者加入共同建设。目前,千言已经针对十余个任务,汇集了近50个开源数据集。
千言评测任务
目前,千言平台已经针对10个任务,汇集了来自14所高校和企业的36个开源数据集。
文本生成
自然语言生成旨在让机器能够像人一样使用自然语言进行表达和交互,它是人工智能领域重要的前沿课题,近年来受到学术界和工业界广泛关注。
AdvertiseGen广告文案生成数据集
https://www.luge.ai/#/luge/dataDetail?id=9
AdvertiseGen以商品网页的标签与文案的信息对应关系为基础构造,是典型的开放式生成任务,在模型基于key-value输入生成开放式文案时,与输入信息的事实一致性需要得到重点关注。
任务描述:给定商品信息的关键词和属性列表kv-list,生成适合该商品的广告文案adv; 数据规模:训练集114k,验证集1k,测试集3k;
LCSTS_new中文短摘要生成数据集
https://www.luge.ai/#/luge/dataDetail?id=10
LCSTS_new是中文短摘要最常用的LCSTS短摘要数据集的升级版本,在数据量、质量方面均有显著提升,在信息摘要与提炼的过程中,与原文的事实一致性需要得到重点关注。
任务描述:给定文章正文doc,生成符合文章信息的摘要sum; 数据规模:训练集1500k,验证集 1k,测试集5k;
DuReader_QG问题生成数据集
https://www.luge.ai/#/luge/dataDetail?id=8
DuReader robust旨在利用真实应用中的数据样本来衡量阅读理解模型的鲁棒性,评测模型的过敏感性、过稳定性以及泛化能力,是首个中文阅读理解鲁棒性数据集。
任务描述:给定段落p和答案a,生成自然语言表述的问题q,且该问题符合段落和上下文的限制; 数据规模:训练集约14.5k,开发集约1k,测试集约1k;
情感分析
情感分析旨在自动识别和提取文本中的倾向、立场、评价、观点等主观信息。传统的情感分析包含各式各样的任务,比如句子级情感分类、评价对象级情感分类、评论观点抽取、情绪分类等。
情感分析是人工智能的重要研究方向,具有很高的学术价值。同时,情感分析在消费决策、舆情分析、个性化推荐等领域均有重要的应用,具有很高的商业价值。
ChnSentiCorp句子级情感分类数据集
https://www.luge.ai/#/luge/dataDetail?id=25
本数据集任务类型为句子级情感分类。对于给定的文本d,系统需要根据文本的内容,给出其对应的情感类别或者情感得分s,类别s取值可以是“积极”、“消极”的离散值,表示情感类别。也可以是1-5的连续实数,表示情感得分(详见ASAP_SENTI数据集)。
SE-ABSA16观点级情感分类数据集
https://www.luge.ai/#/luge/dataDetail?id=18
观点级情感分类是一种细粒度的情感分类任务,旨在评论分本中针对不同评价对象或者评论维度的情感分类。该数据集包含积极、消极两个类别。共覆盖手机、相机两个领域的数据。
COTE中文观点抽取数据集
https://www.luge.ai/#/luge/dataDetail?id=19
评价对象抽取任务旨在对于给定的评论文本,自动抽取其中包含的评价对象。该任务是情感分析中的基础任务之一,该数据集覆盖百度、点评和马蜂窝上抓取的数据。
NLPCC14-SC情感分类评测数据集
https://www.luge.ai/#/luge/dataDetail?id=20
本数据集任务类型为句子级情感分类。任务定义如下:对于给定的文本d,系统需要根据文本的内容,给出其对应的情感类别或者情感得分s,类别s取值可以是“积极”、“消极”的离散值,表示情感类别。
ASAP中文评论分析数据集
https://www.luge.ai/#/luge/dataDetail?id=17
本数据集任务类型包含句子级情感分类和观点级情感分类。
句子级情感分类数据集ASAP_SENT 任务定义如下:对于给定的文本d,系统需要根据文本的内容,给出其对应的情感类别或者情感得分s,类别s取值可以是“积极”、“消极”的离散值,表示情感类别。也可以是1-5的连续实数,表示情感得分(详见ASAP_SENTI数据集)。
SENTI_RATIONAL情感可解释性数据集
https://www.luge.ai/#/luge/dataDetail?id=22
对于输入的文本t及其对应的情感极性s,人工标注预测极性s所依赖的证据。证据来自输入文本,且每一条证据均满足充分、简洁及可读可理解3个特性。参赛系统需要给出输入文本对应的预测依赖证据,也就是输入文本中对预测影响较大的若干部分。
SENTI_ROBUST中文情感鲁棒性数据集
https://www.luge.ai/#/luge/dataDetail?id=23
对于给定的输入文本t,及其对应的情感极性s,根据人工定义的扰动类型(例如针对情感分析任务,我们预先定义扰动类型包括:“新词/冷门词替换”、“改为否定表达”、“不重要的term增删改”等),标注对应的扰动文本t’,并且标注扰动后样本所对应的情感极性s’。系统需要分别预测原始输入文本t以及扰动文本t’的情感分类结果,最终通过统计模型在全部预测数据(包括所有的预测文本以及扰动文本)上的准确率,作为模型鲁棒性的评价指标。
DuVideoSenti多模态情感标签数据集
https://www.luge.ai/#/luge/dataDetail?id=21
本数据集为多模情感分析数据集,包含视频情感泛标签抽取任务(Video Tagging),旨在验证模型在文本、视觉多模态数据上的效果。
阅读理解
机器阅读理解 (Machine Reading Comprehension) 是指让机器阅读文本,然后回答和阅读内容相关的问题。机器阅读理解是自然语言处理和人工智能领域的重要前沿课题,对于提升机器的智能水平、使机器具有持续知识获取的能力等具有重要价值,近年来受到学术界和工业界的广泛关注。
阅读理解鲁棒性数据集
https://www.luge.ai/#/luge/dataDetail?id=1
数据集是单篇章、抽取式阅读理解数据集,具体的任务定义为:对于一个给定的问题q和一个篇章p,参赛系统需要根据篇章内容,给出该问题的答案a。
阅读理解细粒度评估数据集
https://www.luge.ai/#/luge/dataDetail?id=3
数据集是单篇章、抽取式阅读理解数据集,具体任务定义为:给定一个问题q,一段篇章p及其标题t,参赛系统需要根据篇章内容,判断该篇章p中是否包含给定问题的答案,如果是,则给出该问题的答案a;否则输出“无答案”。
观点型阅读理解数据集
对于一个给定的问题q、一系列相关文档D=d1, d2, …, dn,以及人工抽取答案段落摘要a,要求参评系统自动对问题q、候选文档D以及答案段落摘要a进行分析,输出每个答案段落摘要所表述的是非观点极性。
文本相似度
文本相似度旨在识别两段文本在语义上是否相似。文本相似度在自然语言处理领域是一个重要研究方向,同时在信息检索、新闻推荐、智能客服等领域都发挥重要作用,具有很高的商业价值。
LCQMC通用领域问题匹配数据集
https://www.luge.ai/#/luge/dataDetail?id=14
该数据集的任务定义如下:给定两个问题Q,判定该问题对语义是否匹配。
BQ金融领域问题匹配数据集
https://www.luge.ai/#/luge/dataDetail?id=15
银行金融领域的问题匹配数据,包括了从一年的线上银行系统日志里抽取的问题pair对,是目前最大的银行领域问题匹配数据。该数据集的任务定义如下:给定两个问题Q,判定该问题对语义是否匹配。
PAWS语序对抗问题匹配数据集
https://www.luge.ai/#/luge/dataDetail?id=16
数据集里包含了释义对和非释义对,即识别一对句子是否具有相同的释义(含义),特点是具有高度重叠词汇,重点考察模型对句法结构的理解能力。
OPPO小布对话文本语义匹配数据集
https://www.luge.ai/#/luge/dataDetail?id=28
通过对闲聊、智能客服、影音娱乐、信息查询等多领域真实用户交互语料进行用户信息脱敏、相似度筛选处理得到,数据集主要特点是文本较短、非常口语化、存在文本高度相似而语义不同的难例。该数据集所有标签都有经过人工精标确认。
DuQM细粒度鲁棒性问题匹配数据集
https://www.luge.ai/#/luge/dataDetail?id=27
DuQM评测集关注问题匹配模型在真实应用场景中的鲁棒性,从词汇理解、句法结构、错别字、口语化四个维度检测模型的能力,从而发现模型的不足之处,推动语义匹配技术的发展。
语义解析
语义解析(本比赛特指Text-to-SQL任务)旨在将用户输入的自然语言问题转成可与数据库操作的SQL查询语句,其实现了通过自然语言完成与数据库的交互及获得数据库中的信息。
语义解析属于人工智能中的语言理解方向,具有很高的学术研究价值。该技术可以帮助非技术用户通过自然语言与数据库进行交互,降低数据库使用门槛及提升数据库使用效率,同时具有很高的实用价值,在工业界受到了广泛关注。
DuSQL-中文多表SQL解析数据集
https://www.luge.ai/#/luge/dataDetail?id=13
DuSQL是一个面向实际应用的数据集,包含200个数据库,覆盖了164个领域,问题覆盖了匹配、计算、推理等实际应用中常见形式。该数据集更贴近真实应用场景,要求模型领域无关、问题无关,且具备计算推理等能力。
Text-to-SQL任务的输入为数据库D和自然语言问题Q,输出为对应的SQL查询语句Y。在DuSQL数据集中,每一条样本是由数据库D、自然语言问题Q、SQL查询语句Y构成的一个三元组 (D, Q, Y ),其中,数据库由若干张表格构成,表格之间通过外键连接。
NL2SQL-中文单表SQL解析数据集
https://www.luge.ai/#/luge/dataDetail?id=12
NL2SQL是一个多领域的简单数据集,其主要包含匹配类型问题。该数据集主要验证模型的泛化能力,其要求模型具有较强的领域泛化能力、问题泛化能力。
Cspider-中英文多表SQL解析数据集
https://www.luge.ai/#/luge/dataDetail?id=11
CSpider是一个多语言数据集,其问题以中文表达,数据库以英文存储,这种双语模式在实际应用中也非常常见,尤其是数据库引擎对中文支持不好的情况下。该数据集要求模型领域无关、问题无关,且能够实现多语言匹配。
机器同传
同声传译能够实时地翻译讲话的内容,因而广泛应用于国际会议、谈判、新闻发布、法律诉讼和医学等不同场景。机器同传结合了机器翻译(Machine Translation),语音识别(Automatic Speech Recognition)和语音合成(Text-To-Speech)等人工智能技术,已经成为重要的前沿研究领域。
BSTC中译英语音翻译数据集
BSTC数据集是一个大规模中译英语音翻译数据集,它包括一系列授权了的中文演讲视频(68小时)及其对应的转录文本和翻译文本(英语),弥补了已有语音翻译数据集在中文视频上的缺陷。
信息抽取
信息抽取旨在从非结构化自然语言文本中提取结构化知识,如实体、关系、事件等。目前,大多数研究工作仅关注单一类型信息的抽取效果,缺乏在不同类型信息抽取任务上的统一评价。
DuIE2.0中文关系抽取数据集
https://www.luge.ai/#/luge/dataDetail?id=5
DuIE2.0是业界规模最大的中文关系抽取数据集,其schema在传统简单关系类型基础上添加了多元复杂关系类型,此外其构建语料来自百度百科、百度信息流及百度贴吧文本,全面覆盖书面化表达及口语化表达语料,能充分考察真实业务场景下的关系抽取能力。该任务的目标是对于给定的自然语言句子,根据预先定义的schema集合,抽取出所有满足schema约束的SPO三元组。
DuEE-fin金融领域篇章级事件抽取数据集
https://www.luge.ai/#/luge/dataDetail?id=7
DuEE-fin是百度最新发布的金融领域篇章级事件抽取数据集,包含13个事件类型的1.17万个篇章,同时存在部分非目标篇章作为负样例。事件类型来源于常见的金融事件,数据集中的篇章来自金融领域的新闻和公告,覆盖了真实应用场景中诸多难以解决的问题。
该任务的目标是对于给定的自然语言篇章,根据预先指定的事件类型和论元角色,识别篇章中所有目标事件类型的事件,并根据相应的论元角色集合抽取事件所对应的论元。其中待抽取的事件类型限定为金融领域。
DuEE1.0中文事件抽取数据集
https://www.luge.ai/#/luge/dataDetail?id=6
DuEE1.0是百度发布的中文事件抽取数据集,包含65个事件类型的1.7万个具有事件信息的句子(2万个事件)。事件类型根据百度风云榜的热点榜单选取确定,具有较强的代表性。65个事件类型中不仅包含「结婚」、「辞职」、「地震」等传统事件抽取评测中常见的事件类型,还包含了「点赞」等极具时代特征的事件类型。数据集中的句子来自百度信息流资讯文本,相比传统的新闻资讯,文本表达自由度更高,事件抽取的难度也更大。
该任务的目标是对于给定的自然语言句子,根据预先指定的事件类型和论元角色,识别句子中所有目标事件类型的事件,并根据相应的论元角色集合抽取事件所对应的论元。其中目标事件类型 (event_type) 和论元角色 (role) 限定了抽取的范围,例如 (event_type:胜负,role:时间,胜者,败者,赛事名称)、(event_type:夺冠,role:夺冠事件,夺冠赛事,冠军)。
CNERTA中文多模态命名实体识别数据集
https://www.luge.ai/#/luge/dataDetail?id=42
CNERTA数据集是一个语音文本双模态中文命名实体识别数据集,数据集包含了4万多个自然语言句子,是目前最大的多模态命名实体识别数据集以及中文嵌套命名实体识别数据集。数据集中的句子覆盖了体育、时事政治、新闻、金融等多个领域。
模型输入:自然语言句子[华商报记者对几个圈内知名的宝鸡跑团进行调查发现]及其对应的语音片段 [BAC009S0706W0401.wav]。 模型输出:自然语言句子中提及的命名实体[[0, 3, '华商报', 'ORG'], [13, 17, '宝鸡跑团', 'ORG'], [13, 15, '宝鸡', 'LOC']]。
实体链指
面向中文短文本的实体链指,简称 EL(Entity Linking),是自然语言处理和知识图谱领域的基础任务之一,即对于给定的一个中文短文本(如搜索查询、微博、对话内容、文章/视频/图片的标题等),EL将其中的实体与给定知识库中对应的实体进行关联。传统的实体链指任务主要是针对长文本,长文本拥有丰富的上下文信息能辅助实体的歧义消解并完成链指。相比之下,中文短文本的实体链指存在很大的挑战。
DuEL 2.0中文短文本实体链指数据集
https://www.luge.ai/#/luge/dataDetail?id=24
DuEL 2.0 是一个以中文短文本实体链接为目标任务的数据集。该数据集中的样本主要来自于搜索Query、微博、对话内容、标题等,样本的口语化严重,上下文语境不丰富,难度较大。
该任务知识库来自百度百科知识库。知识库中的每个实体都包含一个subject_id(知识库id),一个subject名称,实体的别名,对应的概念类型,以及与此实体相关的一系列二元组<predicate,object>(<属性,属性值>)信息形式。
低资源语言翻译
低资源语言机器翻译是国际公认难题和前沿领域。大部分的小语种通常缺乏大规模的双语训练数据,其中小语种和中文之间的双语数据的稀疏问题更为突出。
百度低资源语言翻译数据集
https://www.luge.ai/#/luge/dataDetail?id=29
低资源语言翻译问题是目前机器翻译领域的重要研究热点,也是机器翻译面临的重大挑战。除了中英等大的语种具有大规模的训练数据外,大部分的小语种通常缺乏大规模的训练数据,其中小语种和中文之间的双语数据的稀疏问题更为突出。研究低资源语言翻译关键技术,对于促进翻译技术发展、提升翻译质量具有重要的研究意义和实用价值。
自然语言推理
自然语言推理任务目的是推断两个句子之间的语义逻辑关系,是自然语言处理领域的一个基础且重要的任务,反映了模型的语义理解能力和推理能力。近年来随着大型数据集的出现,自然语言推理模型由根据文本表层特征推理发展到应用深度学习方法推理,推理效果获得巨大提升。
中文成语语义推理数据集(CINLID)
https://www.luge.ai/#/luge/dataDetail?id=39
计算词/词组、句子、段落和文档之间的语义相似性(STS,Semantic similarity of text)在自然语言处理和计算语言学中起着重要作用,是一个非常重要的任务。
为了得到良好的语句表示,我们需要一个能编码基础语义关系的语料,而且字面重叠的情况要少,让机器学习的难度更大些,以便学到更多有用的语义信息。因此,我们基于同一关系、包含关系、重叠关系、分离关系这4种基本的语义类别构建了中文成语语义推理数据集(Chinese Idioms Natural Language Inference Dataset)。
ChineseBiomedicalQA
https://www.luge.ai/#/luge/dataDetail?id=40
ChineseBiomedicalQA旨在利用执业药师和医师的真题或者模拟题来衡量模型的推理能力,评测模型的可解释性以及泛化能力,是首个基于推理的中文医疗问答数据集。
数据集包含药师和医师数据集,药师数据集的训练集和验证集大小分别为46990条和660条,医师数据集的训练集和验证集大小分别为40796条和600条。
事实核查
事实核查是指针对非虚构作品中声称是事实的内容,为了确认真实性及正确性而进行确认。事实核查可能是在作品发布或是以其他方式公开之前进行核查,也可能是在作品发布后进行查核。作品发布之前的事实核查,目的是为了避免错误,使作品得以发布。近年来,随着社交媒体发展,事实核查任务的必要性得到了更大程度的关注。
CHEF中文事实核查数据集
https://www.luge.ai/#/luge/dataDetail?id=44
CHEF数据集使用真实世界的中文声明,填补了中文事实核查数据集的空白。CHEF使用搜索引擎返回的文档作为原始证据,更加贴近真实场景,并且使用人类标注返回文档的相关句子作为细粒度的证据,可以用于训练核查系统学会如何搜集证据。
CHEF包含了10000条数据,来自中国互联网辟谣平台、腾讯求真等多个企事业平台,涵盖了政治、公卫、社会、科学、文化等领域。
可解释评测
可解释评测(interpretability evaluation)旨在通过评估模型预测依赖证据来评估预测的可解释性。随着AI的发展及AI落地于行业应用的迫切需求,模型的可解释性、鲁棒性等问题受到业界广泛关注。为了更好地推动可解释研究工作发展,可解释评测任务提供了人工标注的细粒度评测数据集和相关评测指标。
DuExplain相似度计算可解释评测数据集
https://www.luge.ai/#/luge/dataDetail?id=47
DuExplain - 相似度计算可解释评测数据集旨在评估模型预测依赖证据的可解释性,提供了人工标注的细粒度证据和扰动数据,利用证据匹配F1 Score、扰动下证据一致性、证据充分性等指标评估证据的合理性和忠诚性;同时,该数据集提供了中英文标注数据。
本数据集任务为阅读理解可解释评测任务,其要求模型根据问题从文本中找出预测的答案以及预测依赖的证据。
DuExplain情感分析可解释评测数据集
https://www.luge.ai/#/luge/dataDetail?id=46
DuExplain - 情感分析可解释评测数据集旨在评估模型预测依赖证据的可解释性,提供了人工标注的细粒度证据和扰动数据,利用证据匹配F1 Score、扰动下证据一致性、证据充分性等指标评估证据的合理性和忠诚性;同时,该数据集提供了中英文标注数据。
本数据集任务为句子级情感分析可解释评测任务,其要求模型给出预测的情感标签以及预测依赖的证据。
DuExplain阅读理解可解释评测数据集
https://www.luge.ai/#/luge/dataDetail?id=48
DuExplain阅读理解可解释评测数据集旨在评估模型预测依赖证据的可解释性,提供了人工标注的细粒度证据和扰动数据,利用证据匹配F1 Score、扰动下证据一致性、证据充分性等指标评估证据的合理性和忠诚性;同时,该数据集提供了中英文标注数据。
本数据集任务为阅读理解可解释评测任务,其要求模型根据问题从文本中找出预测的答案以及预测依赖的证据。
中文对话
对话是人类最自然,最重要的交流方式。随着人工智能技术的发展,对话式人机交互逐渐成为重要的人机交互形式,它显著降低了用户与机器交互的门槛,带来了极大的便利性。
开放域对话技术旨在建立一个开放域的多轮对话系统,使得机器可以流畅自然地与人进行语言交互,既可以进行日常问候类的闲聊,又可以完成特定功能,以使得开放域对话技术具有实际应用价值,例如进行对话式推荐,或围绕一个主题进行深入的知识对话,或进行情感陪护。
豆瓣中文开放域对话数据集
https://www.luge.ai/#/luge/dataDetail?id=33
Douban是一个大规模中文开放域对话数据集,旨在考察模型在闲聊场景中,是否可以生成流畅的、与上下文相关的对话回复。
DuConv知识对话数据集
https://www.luge.ai/#/luge/dataDetail?id=30
DuConv旨在考察模型是否可以在对话过程中充分利用外部知识(既包括结构化知识,也包括非结构化知识),并且在生成对话回复的过程中引入外部知识,是首个bot主动的中文知识对话数据集。
DuRecDial对话推荐数据集
https://www.luge.ai/#/luge/dataDetail?id=31
DuRecDial是首个融合多种对话类型的对话推荐数据集,它包含多种对话类型、多领域和丰富对话逻辑(考虑用户实时反馈)。在每个对话中,推荐者(bot)使用丰富的交互行为主动引导一个多类型对话不断接近推荐目标。DuRecDial旨在考察模型是否可以在对话过程中基于用户兴趣以及用户的实时反馈,主动给用户做出合理的推荐。
Tencent中文开放域对话数据集
https://www.luge.ai/#/luge/dataDetail?id=36
Tencent是一个大规模的检索辅助生成的中文开放域对话数据集,旨在考察模型在闲聊场景中,是否可以生成流畅的、与上下文相关的对话回复。
CPED中文个性情感对话数据集
https://www.luge.ai/#/luge/dataDetail?id=41
CPED是首个多模态中文个性情感对话数据集,包括超过1.2万个对话,超过13.3万个语句。该数据集来源于40部中文电视剧,其中包括与情感、个性特质相关的多源知识,包含13类情绪、性别、大五人格、19类对话动作以及其他知识。
微博开放域短文本对话数据集
https://www.luge.ai/#/luge/dataDetail?id=32
Weibo是一个大规模中文开放域短文本对话数据集,旨在考察模型在闲聊场景中,是否可以生成流畅的、与上下文相关的对话回复。
DuRecDial 2.0中英双语平行对话推荐数据集
https://www.luge.ai/#/luge/dataDetail?id=45
DuRecDial 2.0是第一个大规模中英双语平行的对话推荐数据集,包含5种对话类型(闲聊、对话推荐、知识对话、任务对话、QA)、6个领域(明星、电影、音乐、美食、POI、天气)、16.5k个对话和255k个utterance,采用Wizard-of-Oz方式人工构建。
在每个对话中,推荐者(bot)使用丰富的交互行为,主动引导一个多类型对话不断接近推荐目标。DuRecDial 2.0旨在考察模型是否可以在对话过程中基于用户兴趣以及用户的实时反馈,主动给用户做出合理的推荐。DuRecDial 2.0可支持单语言对话推荐、多语言对话推荐和跨语言对话推荐任务。
# 竞赛交流群 邀请函 #

添加Coggle小助手微信(ID : coggle666)
每天Kaggle算法竞赛、干货资讯汇总
与 24000+来自竞赛爱好者一起交流~

