




命名实体识别是指从文本中提取出专有名词或特定命名实体任务,是信息抽取中将非 结构化数据转化为结构化数据的关键步骤。

命名实体识别(Name Entity Recognition,NER)是知识库问答系统、机器翻译、信息检索、情感 分析、知识图谱等多项自然语言处理应用的基础任务。
传统方法
基于词典和规则
基于词典的实体识别方法是指词典中的每个词与被处理文档之间逐一匹配的过程。
基于规则的实体识别方法是根据文本特点与定制规则特点匹配的方式完成实体识别。
基于词典和规则的实体识别方法使用简单,结果准确率较高,特别是对于数字和时间日期实体利用规则匹配的方式能获得较好的识别效果。
基于统计机器学习
基于统计机器学习的方法是从给定的、已标注好的训练集出发,通过人工构建特征,并根据特定的模型对文本中每个词进行标签标注,实现命名实体识别。
在基于机器学习的命名实体识别方法中,标注的词语通常使用 IOBES 标注集表示,即每个词可以用5类标签进行分类标注。因此基于机器学习的方法也称为序列标注法。
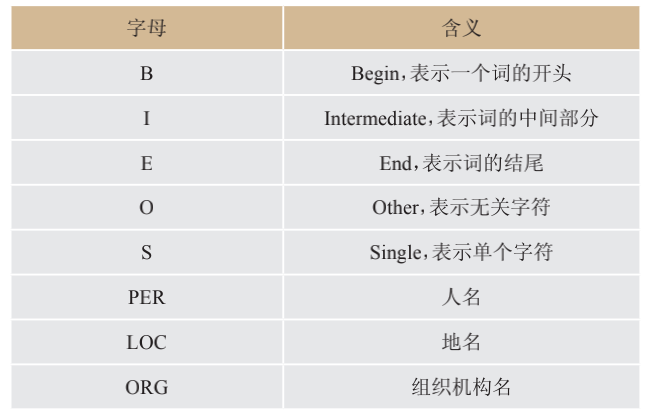
典型的基于统计机器学习的实体识别技术:
隐马尔可夫模型(Hidden Markov Model,HMM) 最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM) 支持向量机(Support Vector Machine,SVM)模型 条件随机场(Conditional Random Fields,CRF)模型
基于统计机器学习算法的命名实体识别模型对特征选取的要求较高,并且需要丰富的语料库。适用于专业性比较强的领域,可在一定程度上提高分词的准确性。
深度学习方法
基础的深度学习模型为:
循环神经网络(Recurrent Neural Network,RNN) 长短期记忆网络(Long Short-Term Memory,LSTM) 门控循环单元(Gated Recurrent Unit,GRU)
RNN
RNN 有一条数据通路指向自身,使得在同一个层面的神经单元之间有了关联。RNN 含有记忆功能,在上下文联系的自然语言处理或时间序列的文本特征问题的处理中具有一定的优势。
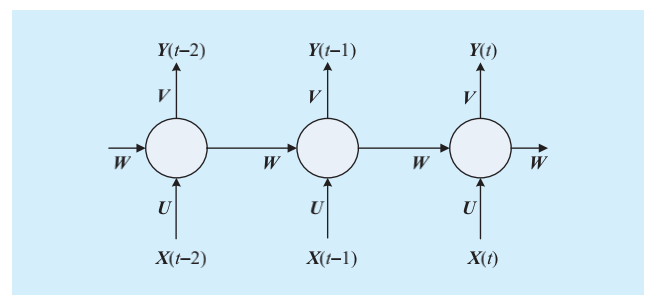
随着序列长度的不断增加,RNN 会逐步丧失学习能力,这种现象被称为“梯度消失”。
LSTM
LSTM结构包含更新门(输入门)、忘记门、输出门。每个门的计算过程都有当前输入信息和上一时刻的神经单元状态参与,并经过激活函数 tanh 的非线性映射计算。
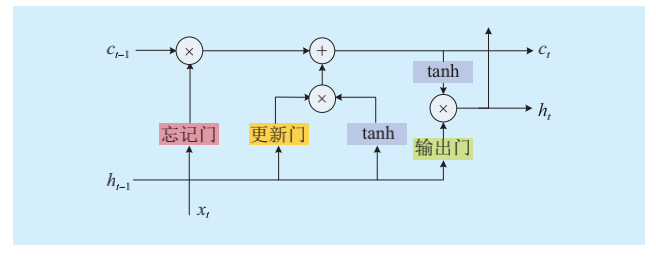
通过以上 3 个门结构的设计,LSTM 在一定程度上解决了梯度消失和梯度爆炸问题。
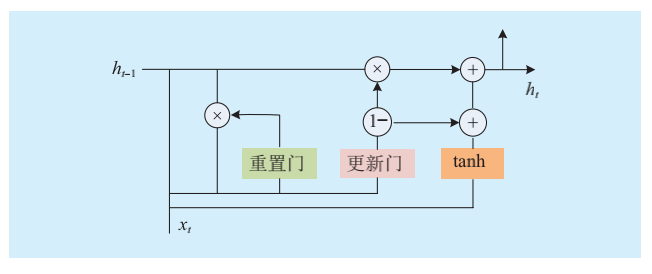
GRU
门控循环单元(GRU)是为了解决 LSTM 神经网络结构复杂、训练时间过长而提出的。GRU网络结构将LSTM的3个门进行整合后分为重置门和更新门。
Transformer
Transformer模型摒弃了递归和卷积操作,完全依赖于注意力(attention)机制,通过多头自注意力(Multi-headed self-attention)机制来构建编码层和解码层。
其编码器(encoder)由 6 个编码块(block)组成,每个块由自注意力机制和前馈神经网络组成,解码器(decoder)由 6 个解码块组成。
常见NER模型
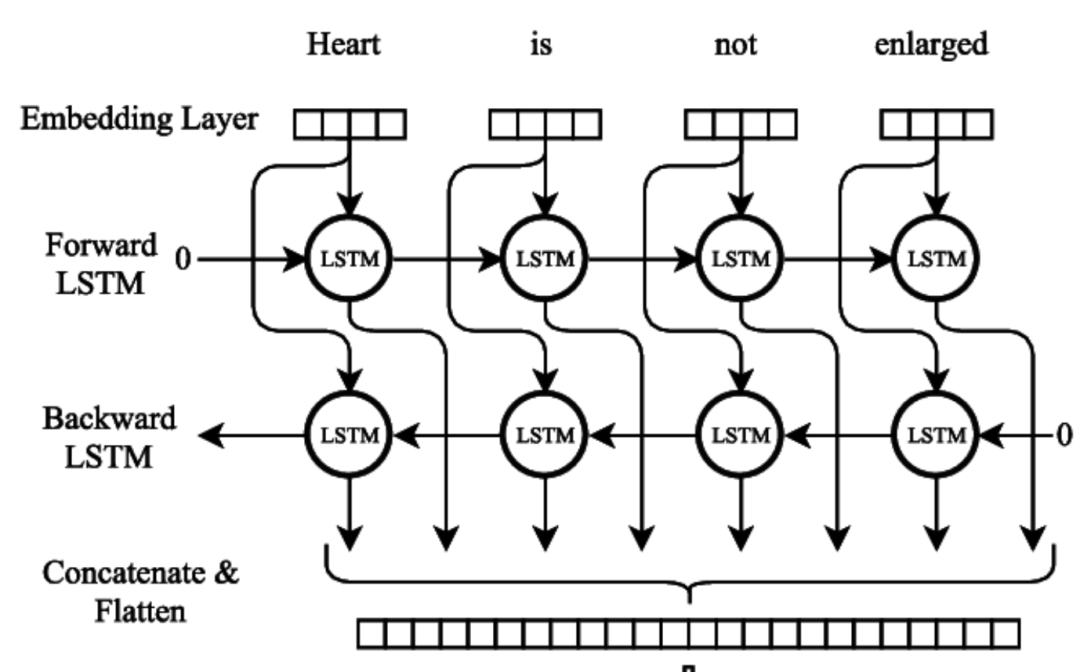
BILSTM
将一个句子作为输入,两个LSTM在句子的相反方向上移动,构造每个单词的上下文相关表示。模型基于两个上下文方向学习特征,使用softmax预测每一个标签。
BERT-BIGRU-CRF
通过 BERT 预训练语言模型获得输入的语义表示,得到句子中每个字的向量表示后,再将字向量序列输入 BiGRU 之中进行进一步语义编码,最后通过 CRF 层输出概率最大标签序列。

BERT-CRF
结合 BERT 与 CRF,对 BERT 进行微调,将 BERT 的输出序列输入到 CRF层,进行标签预测。
评价指标
衡量实体识别效果有 3 种常用的指标:召回率(recall)(用 R 表 示)、准 确 率(precision)(用 P 表示)、F1 值。

# 竞赛交流群 邀请函 #

每天Kaggle算法竞赛、干货资讯汇总
与 22000+来自竞赛爱好者一起交流~

