




Apache Doris
Doris概述篇
前言
Doris由百度大数据部研发,之前叫百度Palo,于2017年开源,2018年贡献到 Apache 社区后,更名为Doris。
Doris简介
Apache Doris是一个现代化的基于MPP(大规模并行处理)技术的分析型数据库产品。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。
Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。令您的数据分析工作更加简单高效!
MPP ( Massively Parallel Processing ),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。简单来说,MPP 是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果 ( 与 Hadoop 相似 )。
核心特性
- 基于MPP(大规模并行处理)架构的分析型数据库
- 性能卓越,PB级别数据毫秒/秒级响应
- 支持标准SQL语言,兼容MySQL协议
- 向量化执行器
- 高效的聚合表技术
- 新型预聚合技术Rollup
- 高性能、高可用、高可靠
- 极简运维,弹性伸缩
Doris特点
- 性能卓越
TPC-H、TPC-DS性能领先,性价比高,高并发查询,100台集群可达10w QPS,流式导入单节点50MB/s,小批量导入毫秒延迟
- 简单易用
高度兼容MySql协议;支持在线表结构变更高度集成,不依赖于外部存储系统
- 扩展性强
架构优雅,单集群可以水平扩展至200台以上
- 高可用性
多副本,元数据高可用
Doris发展历程

对比其他的数据分析框架
开源OLAP引擎对比
- OLTP 与 OLAP
OLTP是 Online Transaction Processing 的简称;OLAP 是 OnLine Analytical Processing 的简称
OLTP的查询一般只会访问少量的记录,且大多时候都会利用索引。比如最常见的基于主键的 CRUD 操作
OLAP 的查询一般需要 Scan 大量数据,大多时候只访问部分列,聚合的需求(Sum,Count,Max,Min 等)会多于明细的需求(查询原始的明细数据)
- HTAP
HTAP 是 Hybrid Transactional(混合事务)/Analytical Processing(分析处理)的简称。
基于创新的计算存储框架,HTAP 数据库能够在一份数据上同时支撑业务系统运行和 OLAP 场景,避免在传统架构中,在线与离线数据库之间大量的数据交互。此外,HTAP 基于分布式架构,支持弹性扩容,可按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
目前,实现 HTAP 的数据库不多,主要有 PingCAP 的 TiDB、阿里云的 HybridDB for MySQL、百度的 BaikalDB 等。其中,TiDB 是国内首家开源的 HTAP 分布式数据库。
- OLAP分类
MOLAP:通过预计算,提供稳定的切片数据,实现多次查询一次计算,减轻了查询时的计算压力,保证了查询的稳定性,是“空间换时间”的最佳路径。实现了基于Bitmap的去重算法,支持在不同维度下去重指标的实时统计,效率较高。
ROLAP:基于实时的大规模并行计算,对集群的要求较高。MPP引擎的核心是通过将数据分散,以实现CPU、IO、内存资源的分布,来提升并行计算能力。在当前数据存储以磁盘为主的情况下,数据Scan需要的较大的磁盘IO,以及并行导致的高CPU,仍然是资源的短板。因此,高频的大规模汇总统计,并发能力将面临较大挑战,这取决于集群硬件方面的并行计算能力。传统去重算法需要大量计算资源,实时的大规模去重指标对CPU、内存都是一个巨大挑战。目前Doris最新版本已经支持Bitmap算法,配合预计算可以很好地解决去重应用场景。
doris是一个ROLAP引擎, 可以满足以下需求
- 灵活多维分析
- 明细+聚合
- 主键更新
对比其他的OLAP系统

- MOLAP模式的劣势(以Kylin为例)
- 应用层模型复杂,根据业务需要以及Kylin生产需要,还要做较多模型预处理。这样在不同的业务场景中,模型的利用率也比较低。
- 由于MOLAP不支持明细数据的查询,在“汇总+明细”的应用场景中,明细数据需要同步到DBMS引擎来响应交互,增加了生产的运维成本。
- 较多的预处理伴随着较高的生产成本。
- ROLAP模式的优势
- 应用层模型设计简化,将数据固定在一个稳定的数据粒度即可。比如商家粒度的星形模型,同时复用率也比较高。
- App层的业务表达可以通过视图进行封装,减少了数据冗余,同时提高了应用的灵活性,降低了运维成本。
- 同时支持“汇总+明细”。
- 模型轻量标准化,极大的降低了生产成本。
综上所述,在变化维、非预设维、细粒度统计的应用场景下,使用MPP引擎驱动的ROLAP模式,可以简化模型设计,减少预计算的代价,并通过强大的实时计算能力,可以支撑良好的实时交互体验。
总结:
- 数据压缩率Clickhouse好
- ClickHouse单表查询性能优势巨大
- Join查询两者各有优劣,数据量小情况下Clickhouse好,数据量大Doris好
- Doris对SQL支持情况要好
使用场景
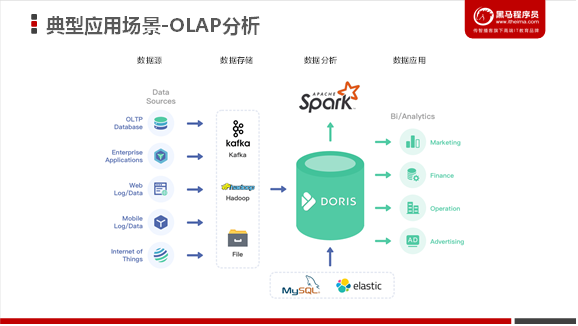
上图是整个Doris的具体使用场景,主要是它的接收数据源,以及它的一个整体的模块,还有最后它的一个可视化的呈现。后面会有一张更详细的图去介绍它整个的来源,以及最后可以输出的数据流向。
一般情况下,用户的原始数据,比如日志或者在事务型数据库中的数据,经过流式系统或离线处理后,导入到Doris中以供上层的报表工具或者数据分析师查询使用。
使用用户

Doris原理篇
名称解释

整体架构
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩) 的技术。

为什么要将这三种技术整合?
- Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。
- Impala是一个非常好的MPP SQL查询引擎,但是缺少完美的分布式存储引擎。
- 自研列式存储:存储层对存储数据的管理通过storage_root_path路径进行配置,路径可以是多个。存储目录下一层按照分桶进行组织,分桶目录下存放具体的tablet,按照tablet_id命名子目录。
因此选择了这三种技术的组合。
Doris的系统架构如下,Doris主要分为FE和BE两个组件:

- Doris的架构很简洁,使用MySQL协议,用户可以使用任何MySQL ODBC/JDBC和MySQL客户端直接访问Doris,只设**FE(Frontend)、BE(Backend)**两种角色、两个进程,不依赖于外部组件,方便部署和运维。
- FE:Frontend,即 Doris 的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作
- BE:Backend,即 Doris 的后端节点。主要负责数据存储与管理、查询计划执行等工作。
- FE,BE都可线性扩展
- FE主要有两个角色,一个是follower,另一个是observer。多个follower组成选举组,会选出一个master,master是follower的一个特例,Master跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
- Observer节点仅从 leader 节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
- 数据的可靠性由BE保证,BE会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
元数据结构
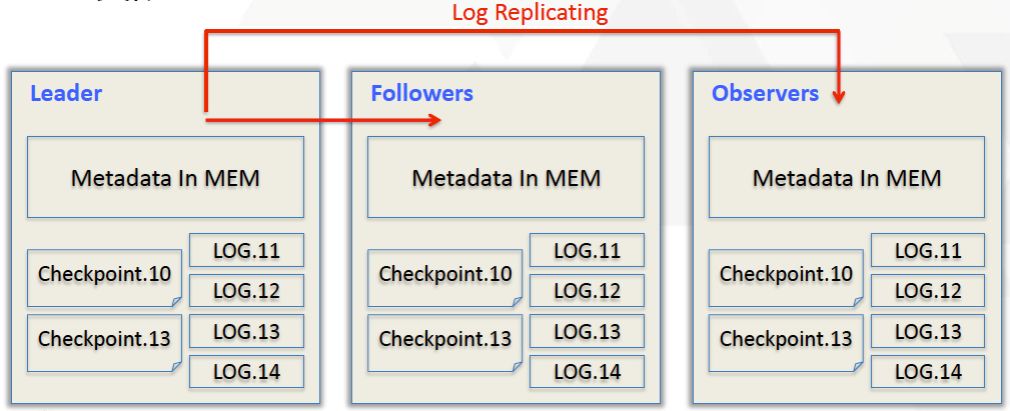
Doris采用Paxos协议以及Memory+ Checkpoint + Journal的机制来确保元数据的高性能及高可靠。元数据的每次更新,都会遵照以下几步:
- 首先写入到磁盘的日志文件中
- 然后再写到内存中
- 最后定期checkpoint到本地磁盘上
相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证FE在宕机后能够快速恢复元数据,而且不丢失元数据。
Leader、follower和 observer它们三个构成一个可靠的服务,如果发生节点宕机的情况,一般是部署一个leader两个follower,目前来说基本上也是这么部署的。就是说三个节点去达到一个高可用服务。单机的节点故障的时候其实基本上三个就够了,因为FE节点毕竟它只存了一份元数据,它的压力不大,所以如果FE太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
数据分发

- 数据主要都是存储在BE里面,BE节点上物理数据的可靠性通过多副本来实现,默认是3副本,副本数可配置且可随时动态调整,满足不同可用性级别的业务需求。FE调度BE上副本的分布与补齐。
- 如果说用户对可用性要求不高,而对资源的消耗比较敏感的话,我们可以在建表的时候选择建两副本或者一副本。比如在百度云上我们给用户建表的时候,有些用户对它的整个资源消耗比较敏感,因为他要付费,所以他可能会建两副本。但是我们一般不太建议用户建一副本,因为一副本的情况下可能一旦机器出问题了,数据直接就丢了,很难再恢复。一般是默认建三副本,这样基本可以保证一台机器单机节点宕机的情况下不会影响整个服务的正常运作。
Doris编译部署篇
该章节主要介绍了部署 Doris 所需软硬件环境、建议的部署方式、集群扩容缩容,以及集群搭建到运行过程中的常见问题。
Doris编译
Apache Doris提供直接可以部署的版本压缩包:https://cloud.baidu.com/doc/PALO/s/Ikivhcwb5
也可以自行编译压缩包后使用(推荐)
使用 Docker 开发镜像编译(推荐)
这个是官方文档推荐的,可以非常方便顺利的编译源码,如果需要快速部署的,可以使用这种方式。这种方式的优点就是不用配置环境变量,也不用考虑各种版本问题,进入开发镜像系统后直接下载 doris 源码编译即可。
首先需要安装 Docker,Docker 在 Linux 下安装比较简单,可以参考以下附件:

如果已经启动了 Docker 服务(systemctl status docker),我们直接拉取镜像,开始编译 Doris。
操作步骤
说明
1
拉取Doris官方提供的Docker镜像,目前可用版本有:build-env、build-env-1.1、build-env-1.2
docker pull apachedoris/doris-dev:build-env-1.2
2
查看 Docker 镜像
docker images

3
运行镜像
将容器中的 maven 下载的包保存到宿主机本地指定的文件中,避免重复下载,同时会将编译的 Doris 文件保存到宿主机本地指定的文件,方便部署
docker run -it \
-v /u01/.m2:/root/.m2 \
-v /u01/incubator-doris-DORIS-0.13-release/:/root/incubator-doris-DORIS-0.13-release/ \
apachedoris/doris-dev:build-env-1.2
开启之后, 就在容器内了
4
下载Doris的安装包
cd /opt
5
解压安装
tar -zxvf apache-doris-0.13.0.0-incubating-src.tar.gz
cd apache-doris-0.13.0.0-incubating-src
6
开始编译(此过程需要等待很久,根据网速来定)
sh build.sh
7
编译完成
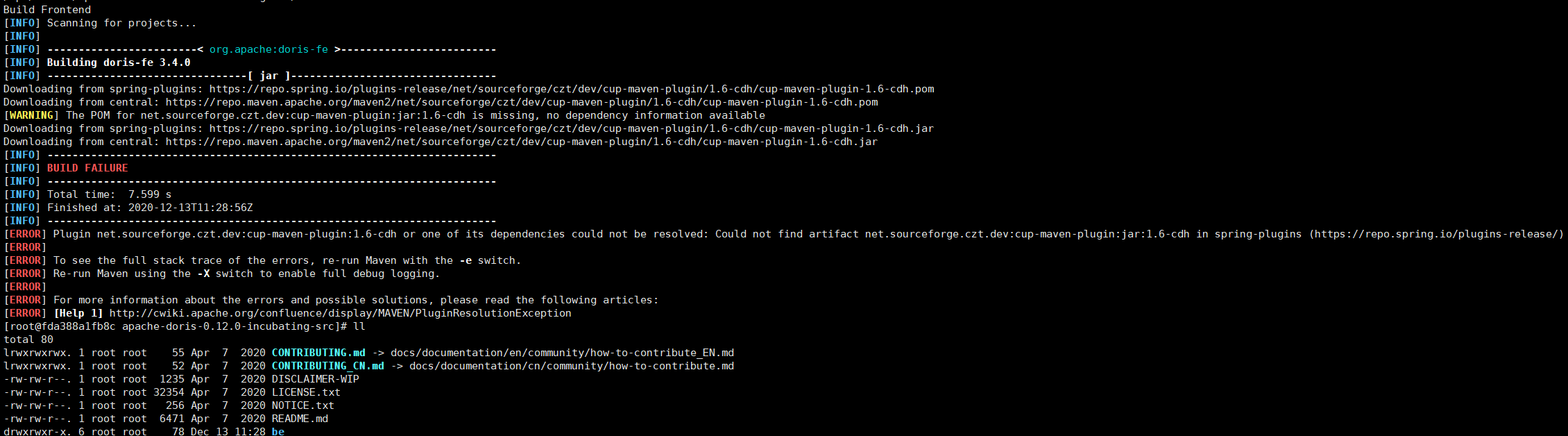
遇到的问题
- 其中错误重点:
Plugin net.sourceforge.czt.dev:cup-maven-plugin:1.6-cdh or one of its dependencies could not be resolved: Could not find artifact net.sourceforge.czt.dev:cup-maven-plugin:jar:1.6-cdh in spring-plugins (https://repo.spring.io/plugins-release/)
- 解决方式:
vi fe/pom.xml change
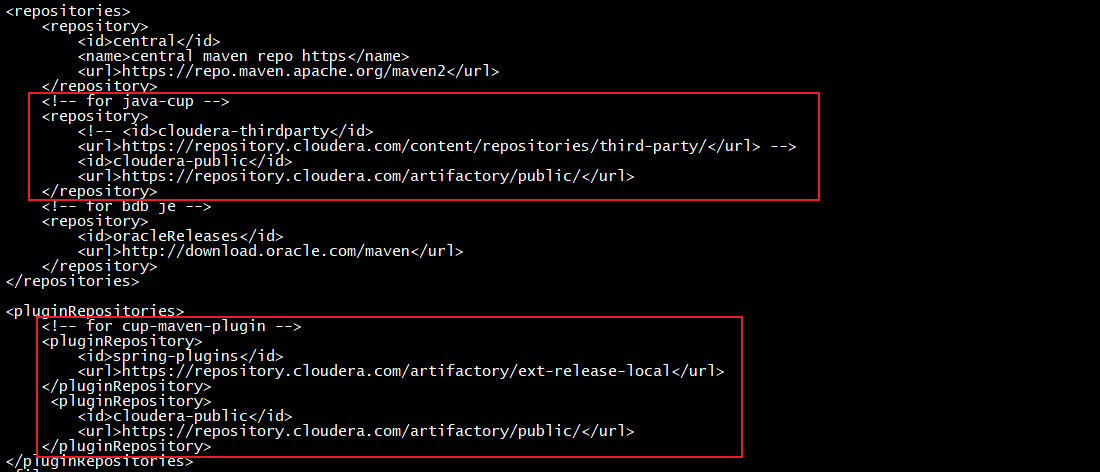
然后再次重新执行编译
直接编译(CentOS/Ubuntu)
使用直接编译方式需要注意第三方包的下载一定要下载指定连接的包且务必完整。
环境准备
- Centos Linux release 7.7.1908
- GCC 7.3+
- Oracle JDK 1.8+
- Python 2.7+
- Apache Maven 3.5+
- CMake 3.11+
- Bison 3.0+
系统依赖(一次性安装)
如果一次性安装所需软件,可以直接使用官方的如下命令:
sudo yum groupinstall ‘Development Tools’ && sudo yum install maven cmake byacc flex automake libtool bison binutils-devel zip unzip ncurses-devel curl git wget python2 glibc-static libstdc+±static java-1.8.0-openjdk
手动安装系统依赖
如果单独安装可以参考如下步骤
CMake 3.11+
# 0 基本的务必安装
yum install **-**y zip unzip curl git wget python2
# 1 下载并解压
# 访问 https://cmake.org/files,比如以 linux x86_64 系统为例,安装 3.11.4,可以下载如下
wget https**😕/cmake.org/files/v3.11/**cmake-3.11.4-Linux-x86_64.tar.gz
tar **-**zxf cmake-3.11.4-Linux-x86_64.tar.gz
# 2 编译或创建软连
#cd cmake-3.11.4-Linux-x86_64
#./bootstrap --prefix=/usr/local/cmake
mv cmake-3.11.4-Linux-x86_64 **/usr/local/**cmake
ln -s **/usr/local/cmake/bin/**cmake **/usr/bin/**cmake
# 3 添加到环境变量
export PATH**=$PATH:/usr/local/cmake/**bin
# 查看版本验证
cmake **–**version
GCC 7.3+
这一步非常重要,最好下载满足条件的版本,耐心的编译,否则因为 GCC 版本或者包的问题容易在编译 Doris 出现一系列莫名的错误,因为 Doris 中依赖了较多的三方库(可以查看thirdparty/vars.sh),其中有些三方库会一般都需要对应的版本对 GCC 有一些要求。
# 1 查看环境中的 gcc 是否满足条件
gcc **-**v
# 2 环境(必须)
yum groupinstall “Development Tools”
yum install **-**y glibc-static libstdc+±static
yum install **-**y byacc flex automake libtool binutils-devel ncurses-devel
# 3 下载 GCC
# 例如这里下载 gcc 7.3.0 版本
# 官网下载页:https://gcc.gnu.org/releases.html
# 3.1 方式一【推荐】:编译方式(以 华中科技大源 为例)
wget http**😕/mirror.hust.edu.cn/gnu/gcc/gcc-7.3.0/**gcc-7.3.0.tar.xz
tar **-**xf gcc-7.3.0.tar.xz
cd gcc-7.3.0
# 下载需要的包
# 需方访问 ftp://gcc.gnu.org/pub/gcc/infrastructure/,
# 如果失败可以将 mpc-1.0.3.tar.gz、mpfr-3.1.4.tar.bz2、isl-0.16.1.tar.bz2、gmp-6.1.0.tar.bz2 包下载放到项目根目录下
**./contrib/**download_prerequisites
# 编译
mkdir build
cd build
**…/**configure **–prefix=/usr/local/**gcc-7.3.0 **–enable-checking=**release **–enable-languages=c,**c++ **–**disable-multilib
# 若给的资源不够,会导致编译时间较长
make -j\[(nproc)/4+1]
make install
# 3.2 方式二:解压后创建软连直接使用
wget https**😕/gfortran.meteodat.ch/download/x86_64/releases/**gcc-7.5.0.tar.xz
tar **-**xf gcc-7.5.0.tar.xz
mv gcc-7.5.0 /usr/local/
# 4【可选】卸载或备份
rpm **-**q gcc
rpm -e gcc-4.8.5-39.el7.x86_64
rpm **-**q libmpc
rpm **-**q mpfr
# 【推荐】备份
mv **/usr/bin/**gcc **/usr/bin/**gcc_old
mv **/usr/bin/**g++ **/usr/bin/**g++_old
mv **/usr/lib64/**libstdc++.so.6 **/usr/lib64/**libstdc++.so.6_old
# 5 创建软连
ln -s **/usr/local/gcc-7.3.0/bin/**gcc **/usr/bin/**gcc
ln -s **/usr/local/gcc-7.3.0/bin/**g++ **/usr/bin/**g++
cp **/usr/local/gcc-7.3.0/lib64/**libstdc++.so.6.0.24 /usr/lib64/
ln -s **/usr/lib64/**libstdc++.so.6.0.24 **/usr/lib64/**libstdc++.so.6
ln -s **/usr/local/gcc-7.3.0/lib64/**libatomic.so.1 **/usr/lib64/**libatomic.so.1
# 5 查看版本以验证
gcc **-**v
g++ **-**v
strings **/usr/lib64/**libstdc++.so.6 | grep GLIBC
Bison 3.0+
# 1 查看当前系统的 Bsion 版本
bison **-**V
# 2 如果没有,则需要安装
wget http**😕/ftp.gnu.org/gnu/bison/**bison-3.0.5.tar.xz
tar **-**xf bison-3.0.5.tar.xz
cd bison-3.0.5
mkdir build
cd build
**…/**configure **–prefix=/usr/local/**bison-3.0.5
make && make install
# 3 替换为新版本
mv **/usr/bin/**bison **/usr/bin/**bison_old
ln -s **/usr/local/bison-3.0.5/bin/**bison **/usr/bin/**bison
其它
Apache Maven 需要 3.5+ 、Oracle JDK 1.8+ 、Python 2.7+ 这些可自行查找相关资料进行安装。
开始编译 Doris
操作步骤
说明
1
下载Doris的安装包
wget https**😕/mirrors.tuna.tsinghua.edu.cn/apache/incubator/doris/0.13.0-incubating/** apache-doris-0.13.0.0-incubating-src.tar.gz
2
解压缩
tar **-**zxf apache-doris-0.13.0.0-incubating-src.tar.gz
3
上传“doris编译修改的配置文件\\thirdparty\vars.sh”脚本文件覆盖到“/export/softwares/ apache-doris-0.13.0.0-incubating-src/thirdparty”目录

4
【为加速编译可以使用提供的第三方包】
上传“doris直接编译需要下载的第三方包”目录下所有文件上传到“/export/softwares/ apache-doris-0.13.0.0-incubating-src/thirdparty/src”目录
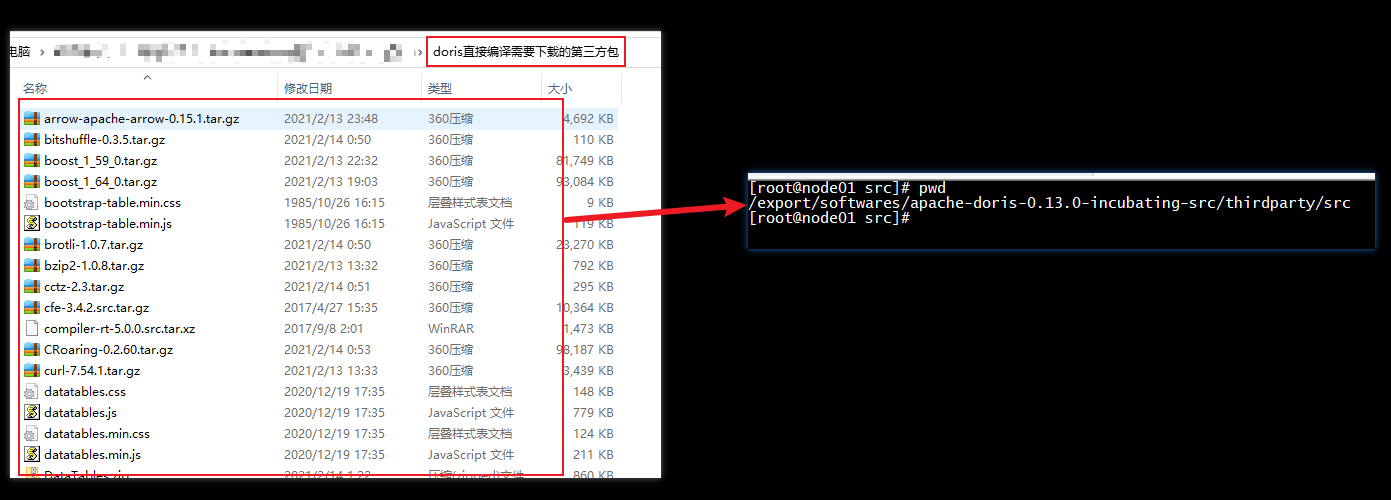
5
开始编译
cd apache-doris-0.13.0.0-incubating-src
# 从 0.13 版本开始,因为协议的不兼容,移除了 mysql-5.7.18 和 lzo-2.10 库
# 如果需要访问 mysql 外部表,可以编译时手动添加 WITH_MYSQL=1
# 如果需要继续使用 LZO 压缩算法(例如访问早期写入数据时),添加 WITH_LZO=1
# 如果编译的机器网速很慢,可以后台执行
#WITH_MYSQL=1 sh build.sh >log.txt 2>&1 &
# --clean
WITH_MYSQL=1 sh build.sh
遇到的问题
js_generator.cc:(.text+0xfc3c): undefined reference to `well_known_types_js’
查找 Doris 源码中的 js_embed,一般在三方库的 protobuf 下,直接移除掉,重新编译即可
find ./ **-**name js_embed
mv **./thirdparty/src/protobuf-3.5.1/src/**js_embed ./
/lib64/libstdc++.so.6: version `GLIBCXX_3.4.21’ not found
问题的原因就是在使用 gcc 编译时,使用本地环境的库 libstdc++.so.6 中的方法时找不到需要的信息,一般是在安装或升级是没有把环境变量的这个库文件升级,解决方法如下:
find / **-**name “libstdc++.so*”
cd **/usr/**lib64
strings **/usr/lib64/**libstdc++.so.6 | grep GLIBC
# 查看 /usr/lib64 目录下的 libstdc 开头的文件
[root@node1 lib64]# ll libstdc*****
lrwxrwxrwx 1 root root 19 Nov 19 09**😗*07 libstdc++.so.6 -> libstdc++.so.6.0.19
**-rwxr-xr-x 1 root root 995840 Sep 30 10😗*17 libstdc++.so.6.0.19
# 把高版本的拷贝到 /usr/lib64 下
cp **/usr/local/gcc-7.3.0/lib64/**libstdc++.so.6.0.24 ./
# 创建软连接
rm libstdc++.so.6
ln -s libstdc++.so.6.0.24 libstdc++.so.6
libatomic.so.1: cannot open shared object file: No such file or directory
编译三方包时如果报如下的错误
./comp_err: error while loading shared libraries**😗* libatomic.so.1**😗* cannot open shared object file**😗* No such file or directory
make**[3]😗* *** [include/mysqld_error.h] Error 127
make**[2]😗* *** [extra/CMakeFiles/GenError.dir/all] Error 2
make**[1]😗* *** [libmysql/CMakeFiles/mysqlclient.dir/rule] Error 2
make**😗* *** [mysqlclient] Error 2
原因是安装 gcc 或升级之后,其中的 libatomic.so.1 包没有在环境变量中生效,我们直接将新版本 gcc 的安装目录下的 libatomic.so.1 软连到 /usr/lib64 下即可。
ln -s **/usr/local/gcc-7.3.0/lib64/**libatomic.so.1 **/usr/lib64/**libatomic.so.1
Could NOT find Curses (missing: CURSES_LIBRARY CURSES_INCLUDE_PATH)
在编译安装 GCC 7.3 时,其中我们安装了 ncurses-devel,如果忽略了这个,系统环境又没有安装,则在编译 Doris 时就会报这个错误,解决方法就是 yum 安装这个依赖。
yum install ncurses-devel
configure: error: Building GCC requires GMP 4.2+, MPFR 2.4.0+ and MPC 0.8.0+.
环境中缺少依赖,解决方法如下:
yum install gmp gmp-devel mpfr mpfr-devel libmpc libmpc-devel
error while loading shared libraries: libisl.so.15: cannot open shared object file: No such file or directory
这个问题比较隐蔽,通过访问 http://rpm.pbone.net/搜索 libisl.so.15 库。
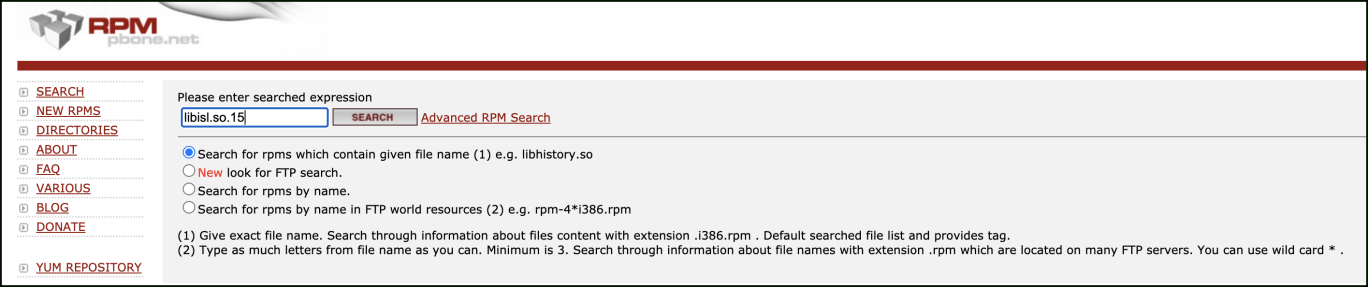
在查询出的结果中,我们查找 CentOS7 的条目,可以发下这个库为 libisl15-0.18-9.94.el7.x86_64.rpm,到这里问题就好解决了,我们直接下载这个包安装即可
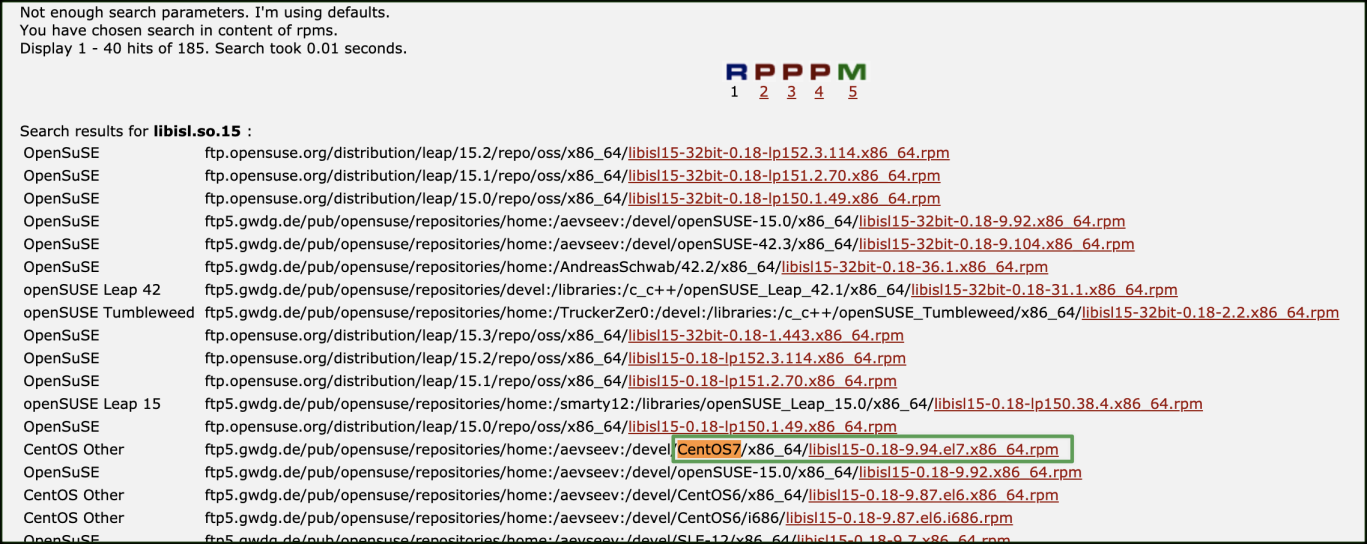
wget ftp**😕/ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home😕aevseev😕devel/CentOS7/x86_64/**libisl15-0.18-9.94.el7.x86_64.rpm
rpm **-**ivh libisl15-0.18-9.94.el7.x86_64.rpm
Could not resolve dependencies for project org.apache:fe-core:jar:3.4.0: Failure to find com.sleepycat:je:jar:7.3.7
原因就是通过 https://repo.spring.io/libs-milestone/com/sleepycat/je/7.3.7/je-7.3.7.jar 下载包时需要用户认证,所以会下载失败,可以在 Maven 配置文件 setting.xml 中新增如下的仓库镜像,重新编译即可。
A required class was missing while executing net.sourceforge.czt.dev:cup-maven-plugin:1.6-cdh:generate: org/sonatype/plexus/build/incremental/BuildContext
清除 Maven 本地仓库的 cup-maven-plugin(Maven 配置的仓库路径下的 net/sourceforge/czt/dev/cup-maven-plugin/1.6-cdh),为了防止其他镜像资源的影响,可以先将本地 Maven 配置文件中添加的其它镜像注释掉,可以只保留下面的一个镜像,用来可以正常下载 je-7.3.7.jar 依赖包。
Doris 源码下的 fe/pom.xml 中的
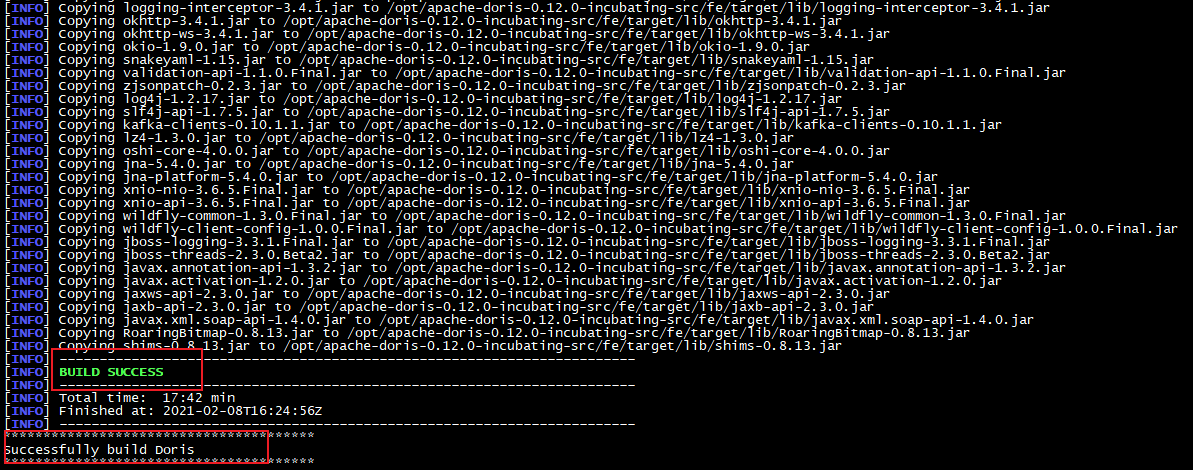
编译成功
Doris 编译成功后控制台显示如下 Successfully build Doris
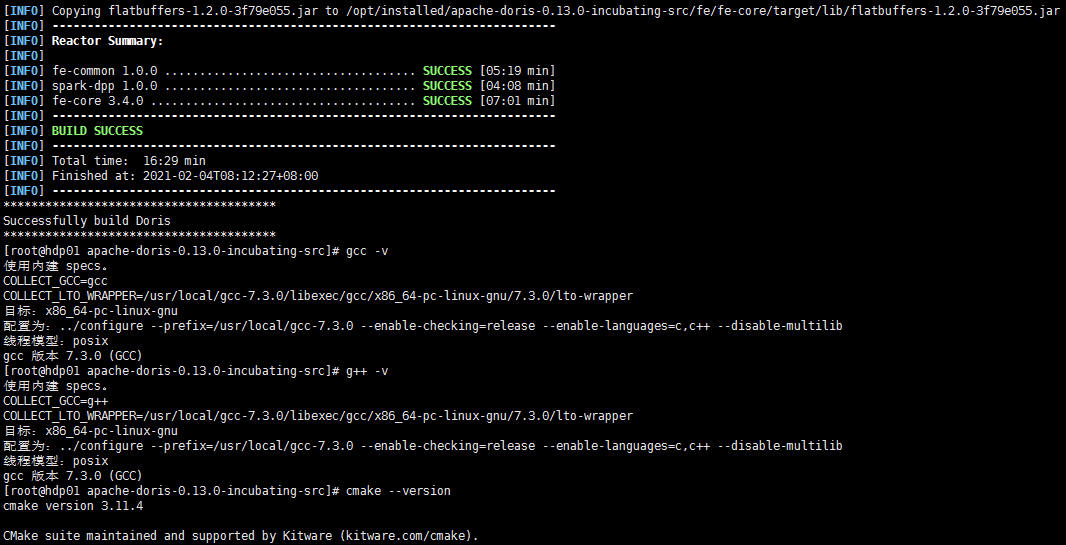
同时编译成功后会在项目根目录下生成 output/,其中为编译之后可以直接部署的二进制包,大概有 1.2GB。
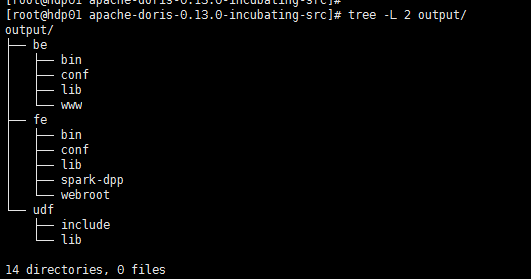
安装与部署
该章节主要介绍了部署 Doris 所需软硬件环境、建议的部署方式、集群扩容缩容,以及集群搭建到运行过程中的常见问题
软硬件需求
Doris 作为一款开源的 MPP 架构 OLAP 数据库,能够运行在绝大多数主流的商用服务器上。为了能够充分运用 MPP 架构的并发优势,以及 Doris 的高可用特性,我们建议 Doris 的部署遵循以下需求:
- Linux 操作系统版本需求
Linux系统
版本
Centos
7.1及以上
Ubuntu
16.04及以上
- 软件需求
软件
版本
Java
1.8及以上
GCC
7.3及以上
- 开发测试环境
模块
CPU
内存
磁盘
网络
实例数量
Frontend
8核+
8GB+
SSD 或 SATA,10GB+ *
千兆网卡
1
Backend
8核+
16GB+
SSD 或 SATA,50GB+ *
千兆网卡
1-3 *
- 生产环境
模块
CPU
内存
磁盘
网络
实例数量
Frontend
16核+
64GB+
SSD 或 RAID,100GB+ *
万兆网卡
1-5 *
Backend
16核+
64GB+
SSD 或 SATA,100GB+ *
万兆网卡
10-100 *
注意点一:
- FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个 GB 不等。
- BE 的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量 * 3(3副本)计算,然后再预留额外 40% 的空间用作后台 compaction 以及一些中间数据的存放。
- 一台机器上可以部署多个 BE 实例,但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个 BE 实例(而不是1台机器部署3个BE实例)。多个FE所在服务器的时钟必须保持一致(允许最多5秒的时钟偏差)
- 测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定了整体查询延迟。
- 所有部署节点关闭 Swap。
注意点二:FE 节点的数量
-
FE 角色分为 Follower 和 Observer,(Leader 为 Follower 组中选举出来的一种角色,以下统称 Follower,具体含义见 元数据设计文档)。
-
FE 节点数据至少为1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时,可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
-
Follower 的数量必须为奇数,Observer 数量随意。
-
根据以往经验,当集群可用性要求很高是(比如提供在线业务),可以部署 3 个 Follower 和 1-3 个 Observer。如果是离线业务,建议部署 1 个 Follower 和 1-3 个 Observer。
-
- 通常我们建议 10 ~ 100 台左右的机器,来充分发挥 Doris 的性能(其中 3 台部署 FE(HA),剩余的部署 BE)
- 当然,Doris的性能与节点数量及配置正相关。在最少4台机器(一台 FE,三台 BE,其中一台 BE 混部一个 Observer FE 提供元数据备份),以及较低配置的情况下,依然可以平稳的运行 Doris。
- 如果 FE 和 BE 混部,需注意资源竞争问题,并保证元数据目录和数据目录分属不同磁盘。
-
Broker 部署
- Broker 是用于访问外部数据源(如 hdfs)的进程。通常,在每台机器上部署一个 broker 实例即可。
-
网络需求
Doris 各个实例直接通过网络进行通讯。以下表格展示了所有需要的端口

- 当部署多个 FE 实例时,要保证 FE 的 http_port 配置相同。
- 部署前请确保各个端口在应有方向上的访问权限。
资源规划
node1
node2
node3
FE(Leader)
FE(Follower)
FE(Follower)
BE
BE
BE
BROKER
BROKER
BROKER
注意点:
- 因测试环境资源有限,FE和BE节点部署在相同服务器,生产环境建议分开
启动FE
配置环境变量
- 拷贝 FE 部署文件到指定节点(node1)
将源码编译生成的 output 下的 fe 文件夹拷贝到 FE 的节点/export/server/apache-doris-0.13.0路径下
- 配置环境变量
vim /etc/profile
#DORIS_HOME
export DORIS_HOME**=/export/server/apache-doris-0.13.0**
export PATH**=:PATH**

重新加载环境变量:source /etc/profile
创建doris-mate
- 配置文件为 fe/conf/fe.conf。其中注意:meta_dir:元数据存放位置。默认在 fe/doris-meta/ 下。需手动创建该目录
mkdir -p /export/server/apache-doris-0.13.0/fe/doris-meta

- 配置fe/conf/fe.conf配置文件
vim conf/fe.conf
meta_dir = /export/server/apache-doris-0.13.0/fe/doris-meta

修改fe.conf中的JAVA_OPTS
- fe.conf 中 JAVA_OPTS 默认 java 最大堆内存为 4GB,建议生产环境调整至 8G 以上。

修改ip绑定(可选)
如果机器有多个ip, 比如内网外网, 虚拟机docker等, 需要进行ip绑定, 以便在配置集群时可以正确识别
修改fe服务的配置文件(ip地址根据环境实际ip进行修改)
vim /export/server/apache-doris-0.13.0/fe/conf/fe.conf
priority_networks = 192.168.10.0/24

将安装目录分发到另外两台节点
scp -r /export/server/apache-doris-0.13.0/ node2:/export/server/
scp -r /export/server/apache-doris-0.13.0/ node3:/export/server/
启动FE
三台机器分别启动
sh /export/server/apache-doris-0.13.0/fe/bin/start_fe.sh --daemon
日志默认存放在 fe/log/ 目录下
配置BE
配置be节点
- 拷贝 BE 部署文件到指定节点(node1)
将源码编译生成的 output 下的 be 文件夹拷贝到 BE 的节点/export/server/apache-doris-0.13.0路径下
创建storage_root_path, 并配置be.conf
配置文件为 be/conf/be.conf。主要是配置 storage_root_path:数据存放目录。默认在be/storage下,需要手动创建该目录。多个路径之间使用 ; 分隔(最后一个目录后不要加 ;)
mkdir -p /export/server/apache-doris-0.13.0/be/storage1 /export/server/apache-doris-0.13.0/be/storage2

vim conf/be.conf
storage_root_path = /export/server/apache-doris-0.13.0/be/storage1,10;/export/server/apache-doris-0.13.0/be/storage2

添加BE
使用mysql连接
操作步骤
说明
1
删除操作系统自带的mysql库文件(node1)
rpm -qa | grep mariadb
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64

2
安装mysql-client
上传”资料\软件\mysql-client”目录下的rpm到服务器节点/export/server/mysql-client

3
进行安装

rpm -ivh *

4
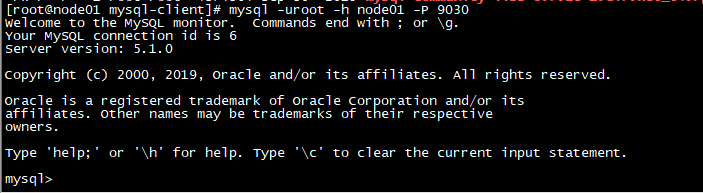
连接node1服务器上的mysql实例(默认端口9030,默认没有密码)
mysql -uroot -h node1 -P 9030
5
登陆后,可以通过以下命令修改 root 密码
SET PASSWORD FOR ‘root’ = PASSWORD**(‘123456’);**

6
使用Navicat客户端登录
添加be
操作步骤
说明
1
BE 节点需要先在 FE 中添加,才可加入集群(node1)
mysql -uroot -h node1 -P 9030 -p
输入密码:123456
2
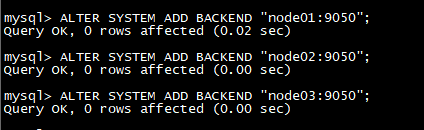
登录后添加BE节点port为be上的heartbeat_service_port端口,默认9050
ALTER SYSTEM ADD BACKEND “node1:9050”;
ALTER SYSTEM ADD BACKEND “node2:9050”;
ALTER SYSTEM ADD BACKEND “node3:9050”;
3
查看BE状态,alive必须为true
SHOW PROC ‘/backends’;

查看 BE 运行情况。如一切正常,isAlive 列应为 true
修改可打开文件数
ulimit -n 65535
上述方式在重启系统后失效
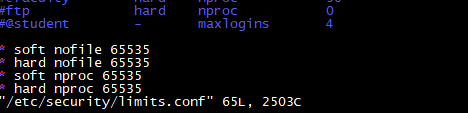
或者修改配置文件: /etc/security/limits.conf, 添加
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535
这种方法需要重启机器才能生效(所有BE节点都需要进行配置)
否则启动不成功, 日志报错

修改ip绑定
如果机器有多个ip, 比如内网外网, 虚拟机docker等, 需要进行ip绑定, 以便在配置集群时可以正确识别
修改fe服务的配置文件(ip地址根据环境实际ip进行修改)
vim /export/server/apache-doris-0.13.0/be/conf/be.conf
priority_networks = 192.168.10.0/24

将安装目录分发到另外两台节点
scp -r /export/server/apache-doris-0.13.0/be node2:/export/server/apache-doris-0.13.0
scp -r /export/server/apache-doris-0.13.0/be node3:/export/server/apache-doris-0.13.0
启动BE
三台机器分别启动
sh /export/server/apache-doris-0.13.0/be/bin/start_be.sh --daemon
日志默认存放在 fe/log/ 目录下
查看FE 和 BE
- 在mysql终端中
show proc ‘/frontends’;

show proc ‘/backends’;

查看 BE 运行情况。如一切正常,isAlive 列应为 true
- 通过前端界面访问FE:
http://192.168.52.150:8030/frontend
http://192.168.52.150:8030/system?path=//frontends
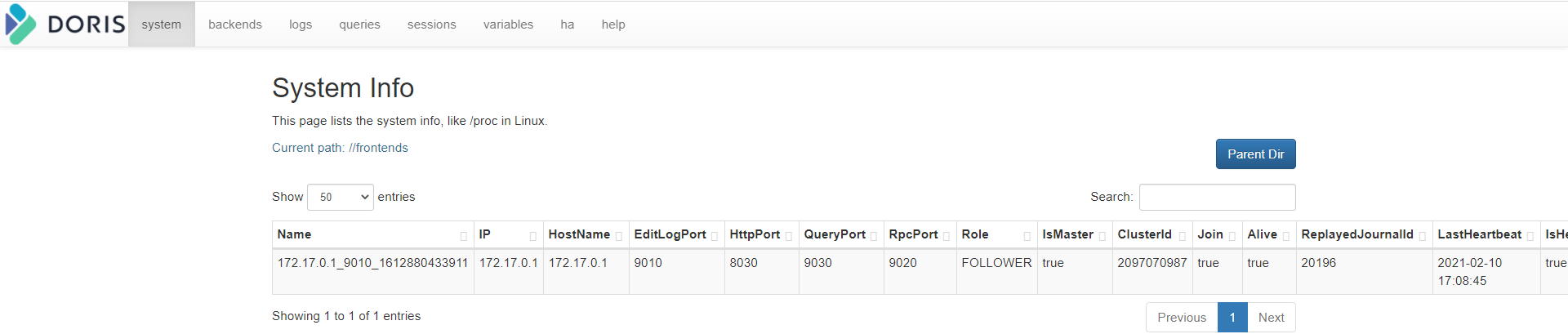
- 通过前端界面访问BE:
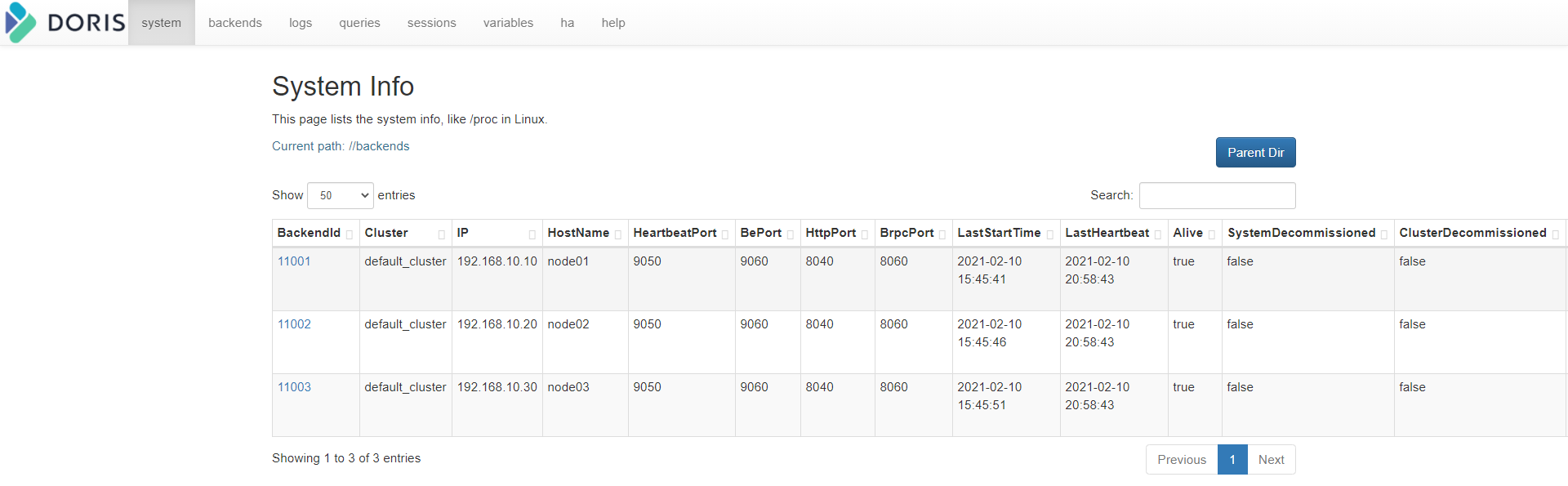
http://192.168.52.150:8030/backend
http://192.168.52.150:8030/system?path=//backends
用户名为root, 密码为空
添加FS_BROKER(可选)
BROKER以插件的形式,独立于Doris的部署,建议每个PE和BE节点都部署一个Broker,Broker是用于访问外部数据源的进程,默认是HDFS,上传编译好的hdfs_broker
配置broker节点
拷贝源码 fs_broker 的 output 目录下的相应 Broker 目录到需要部署的所有节点上。建议和 BE 或者 FE 目录保持同级。
编译fs_broker


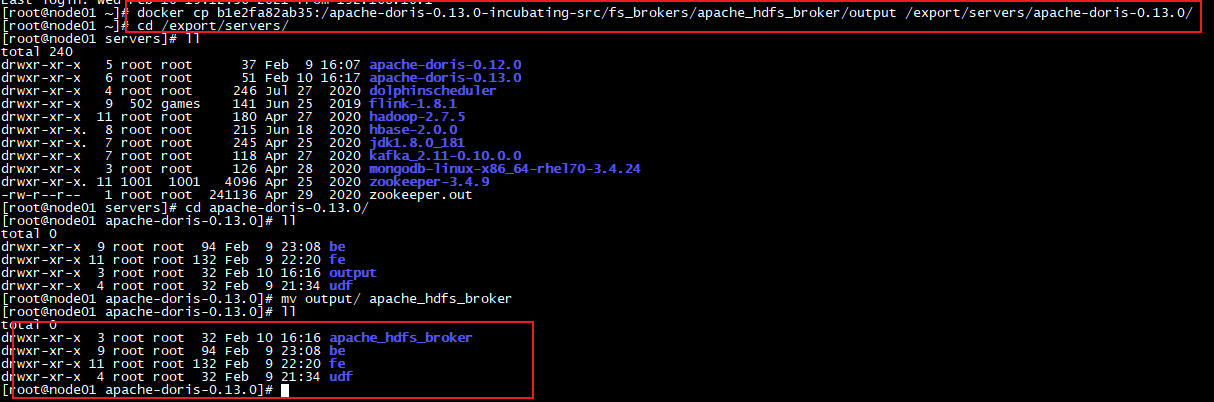
拷贝output目录的部署到node1节点
docker cp b1e2fa82ab35:/ apache-doris-0.13.0-incubating-src/fs_brokers/apache_hdfs_broker/output /export/server/apache-doris-0.13.0/
将安装目录分发到另外两台节点
进入/export/server/apache-doris-0.13.0目录
scp -r apache_hdfs_broker/ node2:/export/server/apache-doris-0.13.0/
scp -r apache_hdfs_broker/ node3:/export/server/apache-doris-0.13.0/
启动 Broker
三台机器分别启动
sh /export/server/apache-doris-0.13.0/apache_hdfs_broker/bin/start_broker.sh --daemon

添加broker节点
使用mysql客户端访问pe,添加broker节点
mysql -uroot -h node1 -P 9030 -p
输入密码:123456
要让 Doris 的 FE 和 BE 知道 Broker 在哪些节点上,通过 sql 命令添加 Broker 节点列表
ALTER SYSTEM ADD BROKER broker_name “node1:8000”,“node2:8000”,“node3:8000”;
其中 host 为 Broker 所在节点 ip;port 为 Broker 配置文件中的 broker_ipc_port。
查看 Broker 状态
SHOW PROC “/brokers”;

注:在生产环境中,所有实例都应使用守护进程启动,以保证进程退出后,会被自动拉起,如 Supervisor (opens new window)。如需使用守护进程启动,在 0.9.0 及之前版本中,需要修改各个 start_xx.sh 脚本,去掉最后的 & 符号。从 0.10.0 版本开始,直接调用 sh start_xx.sh 启动即可。也可参考 这里
扩容缩容
Doris 可以很方便的扩容和缩容 FE、BE、Broker 实例。
FE 扩容和缩容
可以通过将 FE 扩容至 3 个以上节点来实现 FE 的高可用。
FE 节点的扩容和缩容过程,不影响当前系统运行
- 增加 FE 节点
FE 分为 Leader,Follower 和 Observer 三种角色。 默认一个集群,只能有一个 Leader,可以有多个 Follower 和 Observer。其中 Leader 和 Follower 组成一个 Paxos 选择组,如果 Leader 宕机,则剩下的 Follower 会自动选出新的 Leader,保证写入高可用。Observer 同步 Leader 的数据,但是不参加选举。如果只部署一个 FE,则 FE 默认就是 Leader。
第一个启动的 FE 自动成为 Leader。在此基础上,可以添加若干 Follower 和 Observer。
添加 Follower 或 Observer。使用 mysql-client 连接到已启动的 FE,并执行:
ALTER SYSTEM ADD FOLLOWER “ip:port”;
或
ALTER SYSTEM ADD OBSERVER “ip:port”;
其中host为Follower或Observer所在节点 ip,port 为其配置文件 fe.conf 中的 edit_log_port。
配置及启动 Follower或Observer。Follower 和 Observer 的配置同 Leader 的配置。
第一次启动时,需执行以下命令:
./bin/start_fe.sh --helper host:port --daemon
其中 host 为 Leader 所在节点 ip, port 为 Leader 的配置文件 fe.conf 中的 edit_log_port。–helper 参数仅在 follower 和 observer 第一次启动时才需要。
查看 Follower 或 Observer 运行状态。使用 mysql-client 连接到任一已启动的 FE,并执行:SHOW PROC ‘/frontends’; 可以查看当前已加入集群的 FE 及其对应角色。
FE 扩容注意事项:
-
Follower FE(包括 Leader)的数量必须为奇数,建议最多部署 3 个组成高可用(HA)模式即可
-
当 FE 处于高可用部署时(1个 Leader,2个 Follower),我们建议通过增加 Observer FE 来扩展 FE 的读服务能力。当然也可以继续增加 Follower FE,但几乎是不必要的
-
通常一个 FE 节点可以应对 10-20 台 BE 节点。建议总的 FE 节点数量在 10 个以下。而通常 3 个即可满足绝大部分需求
-
helper 不能指向 FE 自身,必须指向一个或多个已存在并且正常运行中的 Master/Follower FE
-
删除 FE 节点
使用以下命令删除对应的 FE 节点:
ALTER SYSTEM DROP FOLLOWER**[OBSERVER]** “fe_host:edit_log_port”;
FE 缩容注意事项:
-
删除 Follower FE 时,确保最终剩余的 Follower(包括 Leader)节点为奇数
-
操作演示
操作步骤
说明
1
使用mysql客户端访问pe,添加broker节点
mysql -uroot -h node1 -P 9030 -p
输入密码:123456
2
将node2节点添加为FOLLOWER
ALTER SYSTEM ADD FOLLOWER “node2:9010”;

3
将node3节点添加为OBSERVER
ALTER SYSTEM ADD OBSERVER “node3:9010”;

4
分别停止三台节点的fe服务(三台节点依次停止)
**/export/server/apache-doris-0.13.0/fe/bin/**stop_fe.sh



5
启动node1节点
sh **/export/server/apache-doris-0.13.0/fe/bin/**start_fe.sh **–**daemon
6
启动node2节点(指定leader节点的位置)
sh **/export/server/apache-doris-0.13.0/fe/bin/**start_fe.sh **–helper node1😗*9010 **–**daemon
7
启动node3节点(指定leader节点的位置)
sh **/export/server/apache-doris-0.13.0/fe/bin/**start_fe.sh **–helper node1😗*9010 **–**daemon
8
查看fe节点列表
SHOW PROC ‘/frontends’;

BE 扩容和缩容
用户可以通过 mysql 客户端登陆 Master FE。
BE 节点的扩容和缩容过程,不影响当前系统运行以及正在执行的任务,并且不会影响当前系统的性能。数据均衡会自动进行。根据集群现有数据量的大小,集群会在几个小时到1天不等的时间内,恢复到负载均衡的状态。集群负载情况,可以参见 Tablet 负载均衡文档。
- 增加 BE 节点
BE 节点的增加方式同 BE 部署 一节中的方式,通过 ALTER SYSTEM ADD BACKEND 命令增加 BE 节点。
BE 扩容注意事项:
-
BE 扩容后,Doris 会自动根据负载情况,进行数据均衡,期间不影响使用
-
删除 BE 节点
删除 BE 节点有两种方式:DROP 和 DECOMMISSION
DROP 语句如下:
ALTER SYSTEM DROP BACKEND “be_host:be_heartbeat_service_port”;
注意事项:
- DROP BACKEND 会直接删除该 BE,并且其上的数据将不能再恢复!!!所以我们强烈不推荐使用 DROP BACKEND 这种方式删除 BE 节点。当你使用这个语句时,会有对应的防误操作提示。
DECOMMISSION 语句如下:
ALTER SYSTEM DECOMMISSION BACKEND “be_host:be_heartbeat_service_port”;
DECOMMISSION 命令说明:
- 该命令用于安全删除 BE 节点。命令下发后,Doris 会尝试将该 BE 上的数据向其他 BE 节点迁移,当所有数据都迁移完成后,Doris 会自动删除该节点。
- 该命令是一个异步操作。执行后,可以通过 SHOW PROC ‘/backends’; 看到该 BE 节点的 isDecommission 状态为 true。表示该节点正在进行下线。
- 该命令不一定执行成功。比如剩余 BE 存储空间不足以容纳下线 BE 上的数据,或者剩余机器数量不满足最小副本数时,该命令都无法完成,并且 BE 会一直处于 isDecommission 为 true 的状态。
- DECOMMISSION 的进度,可以通过 SHOW PROC ‘/backends’; 中的 TabletNum 查看,如果正在进行,TabletNum 将不断减少。
- 该操作可以通过:
CANCEL DECOMMISSION BACKEND “be_host:be_heartbeat_service_port”;
命令取消。取消后,该 BE 上的数据将维持当前剩余的数据量。后续 Doris 重新进行负载均衡
Broker 扩容缩容
Broker 实例的数量没有硬性要求。通常每台物理机部署一个即可。Broker 的添加和删除可以通过以下命令完成:
ALTER SYSTEM ADD BROKER broker_name “broker_host:broker_ipc_port”;
ALTER SYSTEM DROP BROKER broker_name “broker_host:broker_ipc_port”;
ALTER SYSTEM DROP ALL BROKER broker_name**;**
Broker 是无状态的进程,可以随意启停。当然,停止后,正在其上运行的作业会失败,重试即可。
Doris实践篇
Doris 采用 MySQL 协议进行通信,用户可通过 MySQL client 或者 MySQL JDBC连接到 Doris 集群。选择 MySQL client 版本时建议采用5.1 之后的版本,因为 5.1 之前不能支持长度超过 16 个字符的用户名。
创建用户
- Root 用户登录与密码修改
Doris 内置 root 和 admin 用户,密码默认都为空。启动完 Doris 程序之后,可以通过 root 或 admin 用户连接到 Doris 集群。 使用下面命令即可登录 Doris:
mysql -h node1 -P9030 -uroot
登陆后,可以通过以下命令修改 root 密码
SET PASSWORD FOR ‘root’ = PASSWORD**(‘your_password’);**
- 创建新用户
通过下面的命令创建一个普通用户
CREATE USER ‘test’ IDENTIFIED BY ‘test_passwd’;
后续登录时就可以通过下列连接命令登录。
mysql -h node1 -P9030 -utest -ptest_passwd
注意:
- 新创建的普通用户默认没有任何权限。权限授予可以参考后面的权限授予。
创建数据库并赋予权限
- 创建数据库
初始可以通过 root 或 admin 用户创建数据库:
CREATE DATABASE test_db**;**
注意:
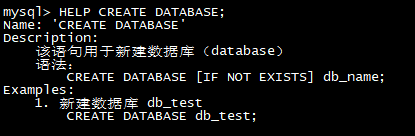
- 所有命令都可以使用 ‘HELP command;’ 查看到详细的语法帮助。如:HELP CREATE DATABASE;
- 如果不清楚命令的全名,可以使用 “help 命令某一字段” 进行模糊查询。如键入 ‘HELP CREATE’,可以匹配到 CREATE DATABASE, CREATE TABLE, CREATE USER 等命令。
数据库创建完成之后,可以通过 SHOW DATABASES; 查看数据库信息。
show databases;
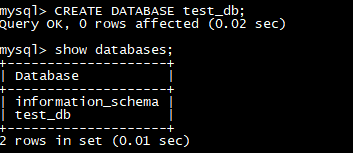
information_schema是为了兼容MySQL协议而存在,实际中信息可能不是很准确,所以关于具体数据库的信息建议通过直接查询相应数据库而获得。
- 权限赋予
test_db 创建完成之后,可以通过 root/admin 账户将 test_db 读写权限授权给普通账户,如 test。授权之后采用 test 账户登录就可以操作 test_db 数据库了。
GRANT ALL ON test_db TO test**;**
[Doris 建表、数据导入与删除](http://www.mianshigee.com/tutorial/Doris/4.md#Doris %E5%BB%BA%E8%A1%A8%E3%80%81%E6%95%B0%E6%8D%AE%E5%AF%BC%E5%85%A5%E4%B8%8E%E5%88%A0%E9%99%A4)
可以通过在 mysql-client 中执行以下 help 命令获得更多帮助:
- help create table
- help load
- help mini load
- help delete
- help alter table
基本概念
在 Doris 中,数据都以**表(Table)**的形式进行逻辑上的描述。
Row & Column
一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key 列相同的行,会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。关于更多聚合模型的介绍,可以参阅 Doris 数据模型
Tablet & Partition
在 Doris 的存储引擎中,用户数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
多个 Tablet 在逻辑上归属于不同的分区(Partition)。一个 Tablet 只属于一个 Partition。而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立。Tablet 是数据移动、复制等操作的最小物理存储单元。
若干个 Partition 组成一个 Table。Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
建表(Create Table)
使用 CREATE TABLE 命令建立一个表(Table)。更多详细参数可以查看:
HELP CREATE TABLE;
首先切换数据库:
USE test_db**;**
Doris 的建表是一个同步命令,命令返回成功,即表示建表成功。
可以通过 HELP CREATE TABLE; 查看更多帮助。
CREATE TABLE IF NOT EXISTS test_db**.table0**
(
`user_id` LARGEINT NOT NULL COMMENT “用户id”,
`date` DATE NOT NULL COMMENT “数据灌入日期时间”,
`timestamp` DATETIME NOT NULL COMMENT “数据灌入的时间戳”,
`city` VARCHAR(20) COMMENT “用户所在城市”,
`age` SMALLINT COMMENT “用户年龄”,
`sex` TINYINT COMMENT “用户性别”,
`last_visit_date` DATETIME REPLACE DEFAULT “1970-01-01 00:00:00” COMMENT “用户最后一次访问时间”,
`cost` BIGINT SUM DEFAULT “0” COMMENT “用户总消费”,
`max_dwell_time` INT MAX DEFAULT “0” COMMENT “用户最大停留时间”,
`min_dwell_time` INT MIN DEFAULT “99999” COMMENT “用户最小停留时间”
)
ENGINE**=**olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p202001` VALUES LESS THAN (“2020-02-01”),
PARTITION `p202002` VALUES LESS THAN (“2020-03-01”),
PARTITION `p202003` VALUES LESS THAN (“2020-04-01”)
)
DISTRIBUTED BY HASH**(`user_id`)** BUCKETS 16
PROPERTIES
(
“replication_num” = “3”,
“storage_medium” = “SSD”,
“storage_cooldown_time” = “2021-05-01 12:00:00”
);
字段类型

- TINYINT数据类型
长度: 长度为1个字节的有符号整型。
范围: [-128, 127]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成CHAR。
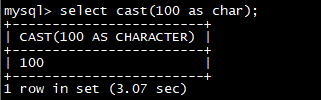
举例:
select **cast(**100 as char);
- SMALLINT数据类型
长度: 长度为2个字节的有符号整型。
范围: [-32768, 32767]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成TINYINT,CHAR。
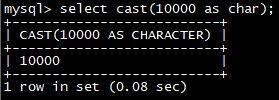
举例:
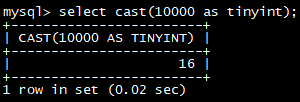
select **cast(**10000 as char);
select **cast(**10000 as tinyint);
- INT数据类型
长度: 长度为4个字节的有符号整型。
范围: [-2147483648, 2147483647]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成TINYINT,SMALLINT,CHAR
举例:
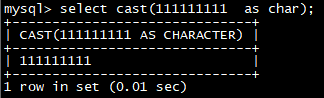
select **cast(**111111111 as char);
- BIGINT数据类型
长度: 长度为8个字节的有符号整型。
范围: [-9223372036854775808, 9223372036854775807]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成TINYINT,SMALLINT,INT,CHAR
举例:
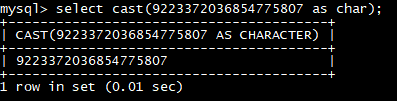
select **cast(**9223372036854775807 as char);
- LARGEINT数据类型
长度: 长度为16个字节的有符号整型。
范围: [-2^127, 2^127-1]
转换: Doris可以自动将该类型转换成浮点类型。使用CAST()函数可以将其转换成TINYINT,SMALLINT,INT,BIGINT,CHAR
举例:
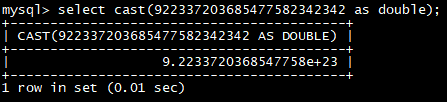
select **cast(**922337203685477582342342 as double);
- FLOAT数据类型
长度: 长度为4字节的浮点类型。
范围: -3.40E+38 ~ +3.40E+38。
转换: Doris会自动将FLOAT类型转换成DOUBLE类型。用户可以使用CAST()将其转换成TINYINT, SMALLINT, INT, BIGINT, STRING, TIMESTAMP。
- DOUBLE数据类型
长度: 长度为8字节的浮点类型。
范围: -1.79E+308 ~ +1.79E+308。
转换: Doris不会自动将DOUBLE类型转换成其他类型。用户可以使用CAST()将其转换成TINYINT, SMALLINT, INT, BIGINT, STRING, TIMESTAMP。用户可以使用指数符号来描述DOUBLE 类型,或通过STRING转换获得。
- DECIMAL数据类型
DECIMAL[M, D]
保证精度的小数类型。M代表一共有多少个有效数字,D代表小数点后最多有多少数字。M的范围是[1,27],D的范围是[1,9],另外,M必须要大于等于D的取值。默认取值为decimal[10,0]。
precision: 1 ~ 27
scale: 0 ~ 9
- DATE数据类型
范围: [0000-01-01~9999-12-31]。默认的打印形式是’YYYY-MM-DD’。
- DATETIME数据类型
范围: [0000-01-01 00:00:00~9999-12-31 23:59:59]。默认的打印形式是’YYYY-MM-DD HH:MM:SS’。
- CHAR数据类型
范围: char[(length)],定长字符串,长度length范围1~255,默认为1。
转换:用户可以通过CAST函数将CHAR类型转换成TINYINT,,SMALLINT,INT,BIGINT,LARGEINT,DOUBLE,DATE或者DATETIME类型。
示例:
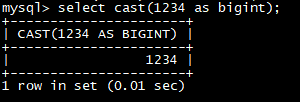
select **cast(**1234 as bigint);
- VARCHAR数据类型
范围: char(length),变长字符串,长度length范围1~65535。
转换:用户可以通过CAST函数将CHAR类型转换成TINYINT,,SMALLINT,INT,BIGINT,LARGEINT,DOUBLE,DATE或者DATETIME类型。
示例:
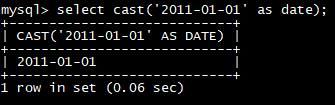
select cast(‘2011-01-01’ as date);
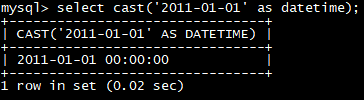
select cast(‘2011-01-01’ as datetime);
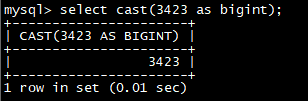
select **cast(**3423 as bigint);
- HLL数据类型
范围:char(length),长度length范围1~16385。用户不需要指定长度和默认值、长度根据数据的聚合程度系统内控制,并且HLL列只能通过配套的hll_union_agg、hll_cardinality、hll_hash进行查询或使用
数据划分
Doris支持单分区和复合分区两种建表方式。
在复合分区中:
- 第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
以下场景推荐使用复合分区
- 有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不使用复合分区,即使用单分区。则数据只做 HASH 分布。
下面以聚合模型为例,分别演示两种分区的建表语句。
- Partition

- Bucket

- PROPERTIES

- ENGINE

关于 Partition 和 Bucket 的数量和数据量的建议
- 一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
- 一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
- 单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
- 当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
- 在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
- 一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
- 举一些例子:假设在有10台BE,每台BE一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑4-8个分片。5GB:8-16个。50GB:32个。500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。
注:表的数据量可以通过 show data 命令查看,结果除以副本数,即表的数据量。
演示单分区和复合分区
单分区
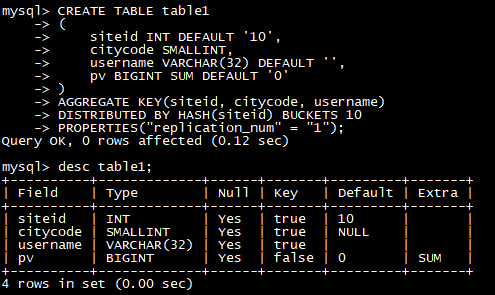
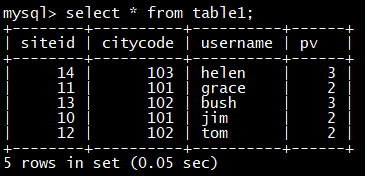
建立一个名字为 table1 的逻辑表。分桶列为 siteid,桶数为 10。
这个表的 schema 如下:
- siteid:类型是INT(4字节), 默认值为10
- citycode:类型是SMALLINT(2字节)
- username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
- pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
建表语句如下:
CREATE TABLE table1
(
siteid INT DEFAULT ‘10’,
citycode SMALLINT,
username VARCHAR(32) DEFAULT ‘’,
pv BIGINT SUM DEFAULT ‘0’
)
AGGREGATE KEY(siteid, citycode**,** username**)**
DISTRIBUTED BY HASH**(siteid)** BUCKETS 10
PROPERTIES**(“replication_num” = “1”);**
将 table1_data 导入 table1 中:vim table1_data
10,101,jim,2
11,101,grace,2
12,102,tom,2
13,102,bush,3
14,103,helen,3
curl --location-trusted -u root:123456 -H “label:table1_20210210” -H “column_separator:,” -T table1_data http://node1:8030/api/test_db/table1/_stream_load

select * from table1**;**
复合分区
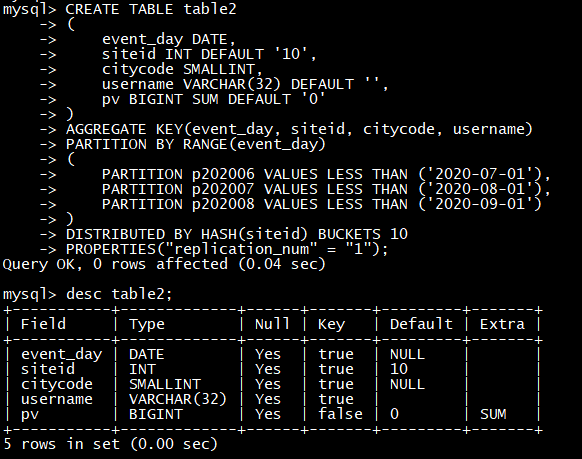
建立一个名字为 table2 的逻辑表。
这个表的 schema 如下:
- event_day:类型是DATE,无默认值
- siteid:类型是INT(4字节), 默认值为10
- citycode:类型是SMALLINT(2字节)
- username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
- pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris 内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
我们使用 event_day 列作为分区列,建立3个分区: p202006, p202007, p202008
-
p202006:范围为 [最小值, 2020-07-01)
-
p202007:范围为 [2020-07-01, 2020-08-01)
-
p202008:范围为 [2020-08-01, 2020-09-01)
-
注意区间为左闭右开。
每个分区使用 siteid 进行哈希分桶,桶数为10
建表语句如下:
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT ‘10’,
citycode SMALLINT,
username VARCHAR(32) DEFAULT ‘’,
pv BIGINT SUM DEFAULT ‘0’
)
AGGREGATE KEY(event_day, siteid**,** citycode**,** username**)**
PARTITION BY RANGE(event_day)
(
PARTITION p202006 VALUES LESS THAN (‘2020-07-01’),
PARTITION p202007 VALUES LESS THAN (‘2020-08-01’),
PARTITION p202008 VALUES LESS THAN (‘2020-09-01’)
)
DISTRIBUTED BY HASH**(siteid)** BUCKETS 10
PROPERTIES**(“replication_num” = “1”);**
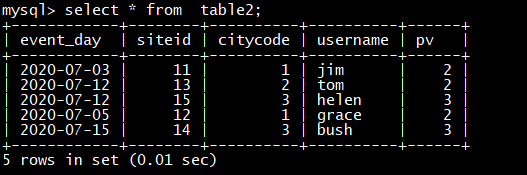
将 table2_data 导入 table2 中:vim table2_data
2020-07-03|11|1|jim|2
2020-07-05|12|1|grace|2
2020-07-12|13|2|tom|2
2020-07-15|14|3|bush|3
2020-07-12|15|3|helen|3
curl --location-trusted -u root:123456 -H “label:table2_20200707” -H “column_separator:|” -T table2_data http://node1:8030/api/test_db/table2/_stream_load

select * from table2**;**
注意事项:
- 上述表通过设置 replication_num 建的都是单副本的表,Doris建议用户采用默认的 3 副本设置,以保证高可用。
- 可以对复合分区表动态的增删分区。详见 HELP ALTER TABLE 中 Partition 相关部分。
- 数据导入可以导入指定的 Partition。详见 HELP LOAD。
- 可以动态修改表的 Schema。
- 可以对 Table 增加上卷表(Rollup)以提高查询性能,这部分可以参见高级使用指南关于 Rollup 的描述。
- 表的列的Null属性默认为true,会对查询性能有一定的影响。
数据导入(Load)
为适配不同的数据导入需求,Doris系统提供了五种不同的数据导入方式,每种数据导入方式支持不同的数据源,存在不同的方式(异步,同步)
- Broker load
通过Broker进程访问并读取外部数据源(HDFS)导入Doris,用户通过Mysql提交导入作业,异步执行,通过show load命令查看导入结果
- Stream load
用户通过HTTP协议提交请求并携带原始数据创建导入,主要用于快速将本地文件或者数据流中的数据导入到Doris,导入命令同步返回结果
- Insert
类似Mysql中的insert语句,Doris提供insert into table select …的方式从Doris的表中读取数据并导入到另一张表中,或者通过insert into table values(…)的方式插入单条数据
- Multi load
用户可以通过HTTP协议提交多个导入作业,Multi load可以保证多个导入作业的原子生效
- Routine load
用户通过Mysql协议提交例行导入作业,生成一个常驻线程,不间断的从数据源(如Kafka)中读取数据并导入到Doris中
Broker Load
Broker load是一个导入的异步方式,不同的数据源需要部署不同的 broker 进程。可以通过 show broker 命令查看已经部署的 broker。
适用场景
- 源数据在Broker可以访问的存储系统中,如HDFS
- 数据量在几十到几百GB级别
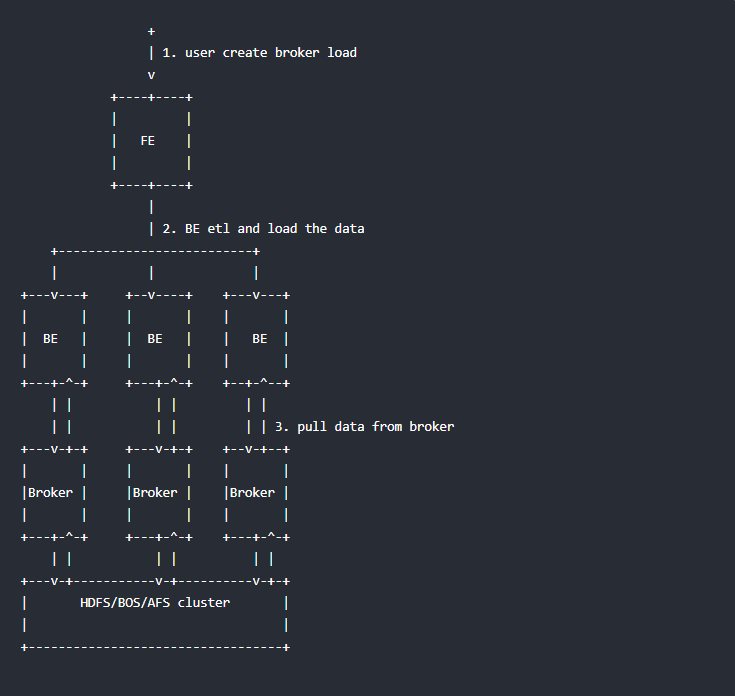
基本原理
用户在递交导入任务后,FE(Doris系统的元数据和调度节点)会生成相应的PLAN(导入执行计划,BE会导入计划将输入导入Doris中)并根据BE(Doris系统的计算和存储节点)的个数和文件的大小,将PLAN分给多个BE执行,每个BE导入一部分数据。BE在执行过程中会从Broker拉取数据,在对数据转换之后导入系统,所有BE均完成导入,由FE最终决定导入是否成功
前置操作
- 启动zookeeper集群(三台节点都启动):zkServer.sh start
- 启动hdfs集群:start-dfs.sh
语法
LOAD LABEL load_label
(
data_desc1**[,** data_desc2**,** …]
)
WITH BROKER broker_name
[broker_properties]
[opt_properties];
load_label
当前导入批次的标签,在一个 database 内唯一。
语法:
[database_name.]your_label
data_desc
用于描述一批导入数据。
语法:
DATA INFILE
(
“file_path1”[, file_path2**,** …]
)
[NEGATIVE]
INTO TABLE `table_name`
[PARTITION (p1, p2**)]**
[COLUMNS TERMINATED BY “column_separator”]
[(column_list)]
[SET (k1 = func(k2))]
**file_path:**文件路径,可以指定到一个文件,也可以用 * 通配符指定某个目录下的所有文件。通配符必须匹配到文件,而不能是目录。
**PARTITION:**如果指定此参数,则只会导入指定的分区,导入分区以外的数据会被过滤掉。如果不指定,默认导入table的所有分区。
**NEGATIVE:**如果指定此参数,则相当于导入一批“负”数据。用于抵消之前导入的同一批数据。该参数仅适用于存在 value 列,并且 value 列的聚合类型仅为 SUM 的情况。
**column_separator:**用于指定导入文件中的列分隔符。默认为 \t如果是不可见字符,则需要加\\x作为前缀,使用十六进制来表示分隔符。如hive文件的分隔符\x01,指定为"\\x01"
**column_list:**用于指定导入文件中的列和 table 中的列的对应关系。当需要跳过导入文件中的某一列时,将该列指定为 table 中不存在的列名即可。
语法:(col_name1, col_name2, …)
**SET:**如果指定此参数,可以将源文件某一列按照函数进行转化,然后将转化后的结果导入到table中。
目前支持的函数有:
- strftime(fmt, column) 日期转换函数
- fmt: 日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
- column: column_list中的列,即输入文件中的列。存储内容应为数字型的时间戳。
- 如果没有column_list,则按照palo表的列顺序默认输入文件的列。
- time_format(output_fmt, input_fmt, column) 日期格式转化
- output_fmt: 转化后的日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
- input_fmt: 转化前column列的日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
- column: column_list中的列,即输入文件中的列。存储内容应为input_fmt格式的日期字符串。
- 如果没有column_list,则按照palo表的列顺序默认输入文件的列。
- alignment_timestamp(precision, column) 将时间戳对齐到指定精度
- precision: year|month|day|hour
- column: column_list中的列,即输入文件中的列。存储内容应为数字型的时间戳。
- 如果没有column_list,则按照palo表的列顺序默认输入文件的列。
- 注意:对齐精度为year、month的时候,只支持20050101~20191231范围内的时间戳。
- default_value(value) 设置某一列导入的默认值
- 不指定则使用建表时列的默认值
- md5sum(column1, column2, …) 将指定的导入列的值求md5sum,返回32位16进制字符串
- replace_value(old_value[, new_value]) 将导入文件中指定的old_value替换为new_value
- new_value如不指定则使用建表时列的默认值
- hll_hash(column) 用于将表或数据里面的某一列转化成HLL列的数据结构
- now() 设置某一列导入的数据为导入执行的时间点。该列必须为 DATE/DATETIME 类型
broker_name
所使用的 broker 名称,可以通过 show broker 命令查看。不同的数据源需使用对应的 broker。
broker_properties
用于提供通过 broker 访问数据源的信息。不同的 broker,以及不同的访问方式,需要提供的信息不同。
Apache HDFS:
社区版本的 hdfs,支持简单认证、kerberos 认证。以及支持 HA 配置。
- 简单认证:
- hadoop.security.authentication = simple (默认)
- username:hdfs 用户名
- password:hdfs 密码
- kerberos 认证:
- hadoop.security.authentication = kerberos
- kerberos_principal:指定 kerberos 的 principal
- kerberos_keytab:指定 kerberos 的 keytab 文件路径。该文件必须为 broker 进程所在服务器上的文件。
- kerberos_keytab_content:指定 kerberos 中 keytab 文件内容经过 base64 编码之后的内容。这个跟 kerberos_keytab 配置二选一就可以。
- namenode HA:
通过配置 namenode HA,可以在 namenode 切换时,自动识别到新的 namenode- dfs.nameservices: 指定 hdfs 服务的名字,自定义,如:“dfs.nameservices” = “my_ha”
- dfs.ha.namenodes.xxx:自定义 namenode 的名字,多个名字以逗号分隔。其中 xxx 为 dfs.nameservices 中自定义的名字,如 “dfs.ha.namenodes.my_ha” = “my_nn”
- dfs.namenode.rpc-address.xxx.nn:指定 namenode 的rpc地址信息。其中 nn 表示 dfs.ha.namenodes.xxx 中配置的 namenode 的名字,如:“dfs.namenode.rpc-address.my_ha.my_nn” = “host:port”
- dfs.client.failover.proxy.provider:指定 client 连接 namenode 的 provider,默认为:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
opt_properties
用于指定一些特殊参数。
语法:
[PROPERTIES (“key”=“value”, …)]
可以指定如下参数:
- timeout:指定导入操作的超时时间。默认超时为4小时。单位秒。
- max_filter_ratio:最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。
- exec_mem_limit:设置导入使用的内存上限。默认为2G,单位字节。这里是指单个 BE 节点的内存上限。一个导入可能分布于多个BE。我们假设 1GB 数据在单个节点处理需要最大5GB内存。那么假设1GB文件分布在2个节点处理,那么理论上每个节点需要内存为2.5GB。则该参数可以设置为 2684354560,即2.5GB
数据导入演示
操作步骤
说明
1
启动zookeeper集群(三台节点都启动)
zkServer.sh start
2
启动hdfs集群
start-dfs.sh
3
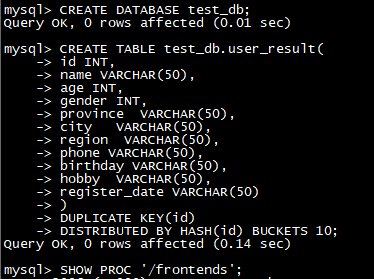
进入mysqlclient,创建表
CREATE TABLE test_db**.user_result(**
id INT,
name VARCHAR(50),
age INT,
gender INT,
province VARCHAR(50),
city VARCHAR(50),
region VARCHAR(50),
phone VARCHAR(50),
birthday VARCHAR(50),
hobby VARCHAR(50),
register_date VARCHAR(50)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH**(id)** BUCKETS 10**;**
4
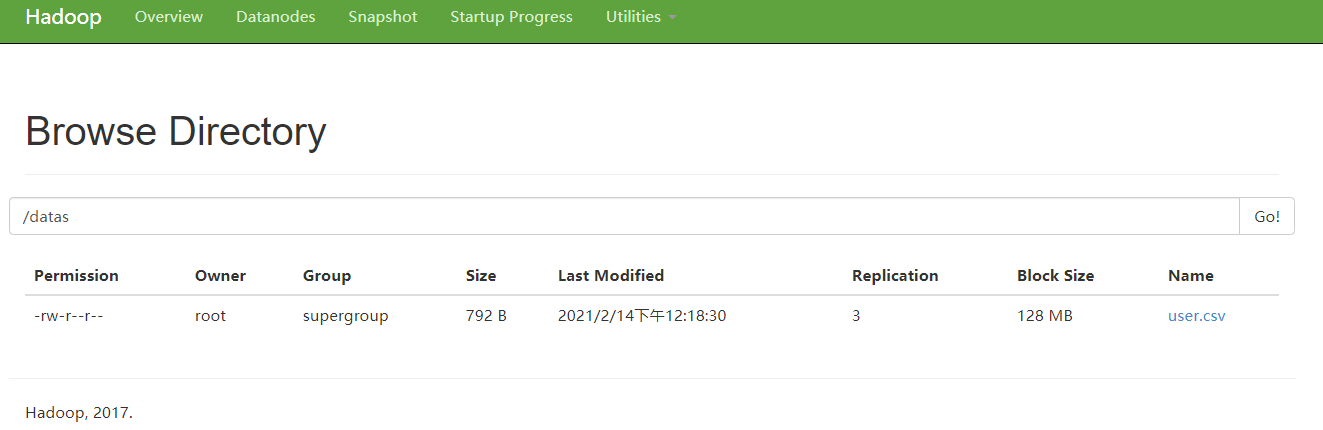
上传数据,将“资料\测试数据\user.csv”上传到hdfs

5
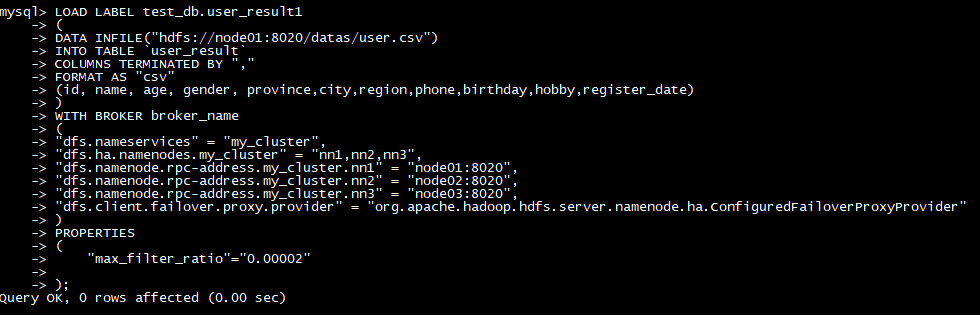
导入数据
LOAD LABEL test_db**.**user_result
(
DATA INFILE**(“hdfs://node1:8020/datas/user.csv”)**
INTO TABLE `user_result`
COLUMNS TERMINATED BY “,”
FORMAT AS “csv”
(id, name**,** age**,** gender**,** province**,city,region,phone,birthday,hobby,register_date)**
)
WITH BROKER broker_name
(
“dfs.nameservices” = “my_cluster”,
“dfs.ha.namenodes.my_cluster” = “nn1,nn2,nn3”,
“dfs.namenode.rpc-address.my_cluster.nn1” = “node1:8020”,
“dfs.namenode.rpc-address.my_cluster.nn2” = “node2:8020”,
“dfs.namenode.rpc-address.my_cluster.nn3” = “node3:8020”,
“dfs.client.failover.proxy.provider” = “org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider”
)
PROPERTIES
(
“max_filter_ratio”=“0.00002”
);
6
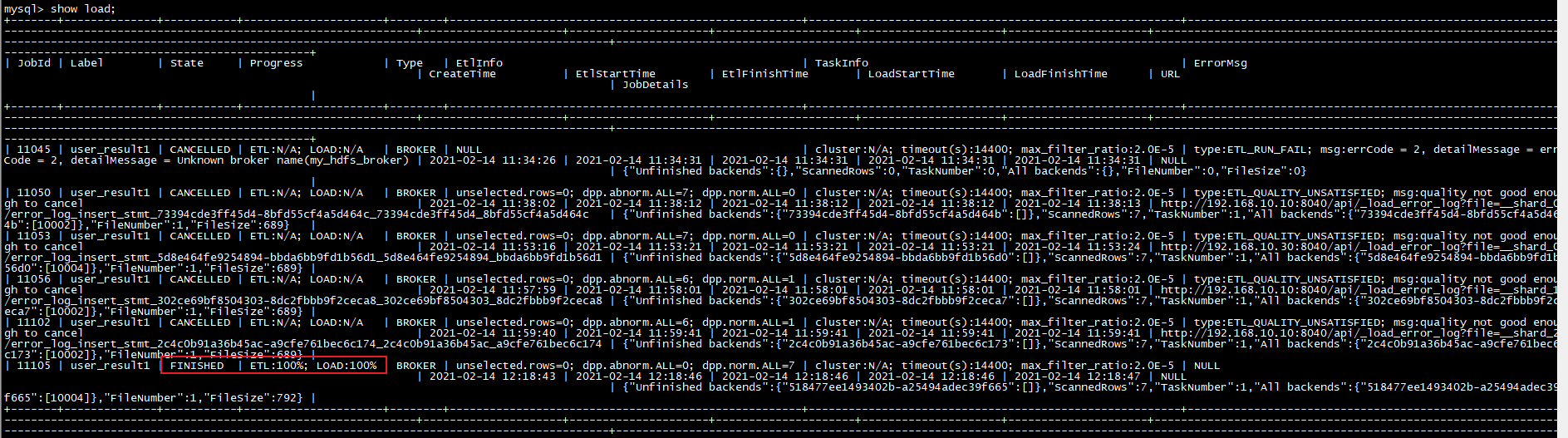
查看load作业
7
查询表数据
select * from user_result;

查看导入
Broker load 导入方式由于是异步的,所以用户必须将创建导入的 Label 记录,并且在查看导入命令中使用 Label 来查看导入结果。查看导入命令在所有导入方式中是通用的,具体语法可执行 HELP SHOW LOAD 查看。
show load order by createtime desc limit 1\G

JobId
导入任务的唯一ID,每个导入任务的 JobId 都不同,由系统自动生成。与 Label 不同的是,JobId永远不会相同,而 Label 则可以在导入任务失败后被复用。
Label
导入任务的标识。
State
导入任务当前所处的阶段。在 Broker load 导入过程中主要会出现 PENDING 和 LOADING 这两个导入中的状态。如果 Broker load 处于 PENDING 状态,则说明当前导入任务正在等待被执行;LOADING 状态则表示正在执行中。
导入任务的最终阶段有两个:CANCELLED 和 FINISHED,当 Load job 处于这两个阶段时,导入完成。其中 CANCELLED 为导入失败,FINISHED 为导入成功。
Progress
导入任务的进度描述。分为两种进度:ETL 和 LOAD,对应了导入流程的两个阶段 ETL 和 LOADING。目前 Broker load 由于只有 LOADING 阶段,所以 ETL 则会永远显示为 N/A
LOAD 的进度范围为:0~100%。
LOAD 进度 = 当前完成导入的表个数 / 本次导入任务设计的总表个数 * 100%
如果所有导入表均完成导入,此时 LOAD 的进度为 99% 导入进入到最后生效阶段,整个导入完成后,LOAD 的进度才会改为 100%。
导入进度并不是线性的。所以如果一段时间内进度没有变化,并不代表导入没有在执行。
Type
导入任务的类型。Broker load 的 type 取值只有 BROKER。
EtlInfo
主要显示了导入的数据量指标 unselected.rows , dpp.norm.ALL 和 dpp.abnorm.ALL。用户可以根据第一个数值判断 where 条件过滤了多少行,后两个指标验证当前导入任务的错误率是否超过 max_filter_ratio。
三个指标之和就是原始数据量的总行数。
TaskInfo
主要显示了当前导入任务参数,也就是创建 Broker load 导入任务时用户指定的导入任务参数,包括:cluster,timeout 和max_filter_ratio。
ErrorMsg
在导入任务状态为CANCELLED,会显示失败的原因,显示分两部分:type 和 msg,如果导入任务成功则显示 N/A。
type的取值意义:
USER_CANCEL: 用户取消的任务
ETL_RUN_FAIL:在ETL阶段失败的导入任务
ETL_QUALITY_UNSATISFIED:数据质量不合格,也就是错误数据率超过了 max_filter_ratio
LOAD_RUN_FAIL:在LOADING阶段失败的导入任务
TIMEOUT:导入任务没在超时时间内完成
UNKNOWN:未知的导入错误
CreateTime/EtlStartTime/EtlFinishTime/LoadStartTime/LoadFinishTime
这几个值分别代表导入创建的时间,ETL阶段开始的时间,ETL阶段完成的时间,Loading阶段开始的时间和整个导入任务完成的时间。
Broker load 导入由于没有 ETL 阶段,所以其 EtlStartTime, EtlFinishTime, LoadStartTime 被设置为同一个值。
导入任务长时间停留在 CreateTime,而 LoadStartTime 为 N/A 则说明目前导入任务堆积严重。用户可减少导入提交的频率。
LoadFinishTime - CreateTime = 整个导入任务所消耗时间
LoadFinishTime - LoadStartTime = 整个 Broker load 导入任务执行时间 = 整个导入任务所消耗时间 - 导入任务等待的时间
URL
导入任务的错误数据样例,访问 URL 地址既可获取本次导入的错误数据样例。当本次导入不存在错误数据时,URL 字段则为 N/A。
JobDetails
显示一些作业的详细运行状态。包括导入文件的个数、总大小(字节)、子任务个数、已处理的原始行数,运行子任务的 BE 节点 Id,未完成的 BE 节点 Id。
{“Unfinished backends”:{“9c3441027ff948a0-8287923329a2b6a7”:[10002]},“ScannedRows”:2390016,“TaskNumber”:1,“All backends”:{“9c3441027ff948a0-8287923329a2b6a7”:[10002]},“FileNumber”:1,“FileSize”:1073741824}
其中已处理的原始行数,每 5 秒更新一次。该行数仅用于展示当前的进度,不代表最终实际的处理行数。实际处理行数以 EtlInfo 中显示的为准。
取消导入
当 Broker load 作业状态不为 CANCELLED 或 FINISHED 时,可以被用户手动取消。取消时需要指定待取消导入任务的 Label 。取消导入命令语法可执行 HELP CANCEL LOAD查看。

其他导入案例参考
- 从 HDFS 导入一批数据,数据格式为CSV,同时使用 kerberos 认证方式,同时配置 namenode HA
设置最大容忍可过滤(数据不规范等原因)的数据比例。
LOAD LABEL test_db**.**user_result2
(
DATA INFILE**(“hdfs://node1:8020/datas/user.csv”)**
INTO TABLE `user_result`
COLUMNS TERMINATED BY “,”
FORMAT AS “csv”
(id, name**,** age**,** gender**,** province**,city,region,phone,birthday,hobby,register_date)**
)
WITH BROKER broker_name
(
“hadoop.security.authentication”=“kerberos”,
“kerberos_principal”=“doris@YOUR.COM”,
“kerberos_keytab_content”=“BQIAAABEAAEACUJBSURVLkNPTQAEcGFsbw”,
“dfs.nameservices” = “my_ha”,
“dfs.ha.namenodes.my_ha” = “my_namenode1, my_namenode2”,
“dfs.namenode.rpc-address.my_ha.my_namenode1” = “node1:8020”,
“dfs.namenode.rpc-address.my_ha.my_namenode2” = “node2:8020”,
“dfs.client.failover.proxy.provider” = “org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider”
)
PROPERTIES
(
“max_filter_ratio”=“0.00002”
);
- 从 HDFS 导入一批数据,指定超时时间和过滤比例。使用铭文 my_hdfs_broker 的 broker。简单认证。
LOAD LABEL test_db**.**user_result3
(
DATA INFILE**(“hdfs://node1:8020/datas/user.csv”)**
INTO TABLE `user_result`
)
WITH BROKER broker_name
(
“username” = “hdfs_user”,
“password” = “hdfs_passwd”
)
PROPERTIES
(
“timeout” = “3600”,
“max_filter_ratio” = “0.1”
);
其中 hdfs_host 为 namenode 的 host,hdfs_port 为 fs.defaultFS 端口(默认9000)
- 从 HDFS 导入一批数据,指定hive的默认分隔符\x01,并使用通配符*指定目录下的所有文件
使用简单认证,同时配置 namenode HA。
LOAD LABEL test_db**.**user_result4
(
DATA INFILE**(“hdfs://node1:8020/datas/input/*”)**
INTO TABLE `user_result`
COLUMNS TERMINATED BY “\\x01”
)
WITH BROKER broker_name
(
“username” = “hdfs_user”,
“password” = “hdfs_passwd”,
“dfs.nameservices” = “my_ha”,
“dfs.ha.namenodes.my_ha” = “my_namenode1, my_namenode2”,
“dfs.namenode.rpc-address.my_ha.my_namenode1” = “node1:8020”,
“dfs.namenode.rpc-address.my_ha.my_namenode2” = “node2:8020”,
“dfs.client.failover.proxy.provider” = “org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider”
)
- 从 HDFS 导入一批“负”数据。同时使用 kerberos 认证方式。提供 keytab 文件路径
LOAD LABEL test_db**.**user_result5
(
DATA INFILE**(**"hdfs://node1:8020/datas/input/old_file)
NEGATIVE
INTO TABLE `user_result`
COLUMNS TERMINATED BY “\t”
)
WITH BROKER broker_name
(
“hadoop**.security.**authentication” = “kerberos”,
“kerberos_principal”=“doris@YOUR**.**COM”,
“kerberos_keytab”="**/home/palo/palo.**keytab"
)
- 从 HDFS 导入一批数据,指定分区。同时使用 kerberos 认证方式。提供 base64 编码后的 keytab 文件内容
LOAD LABEL test_db.user_result6
(
DATA INFILE(“hdfs**😕/node1:8020/datas/input/file**”)
INTO TABLE `user_result`
PARTITION (p1, p2)
COLUMNS TERMINATED BY “,”
(k1, k3, k2, v1, v2)
)
WITH BROKER broker_name
(
“hadoop**.security.**authentication”=“kerberos”,
“kerberos_principal”=“doris@YOUR**.**COM”,
“kerberos_keytab_content”=“BQIAAABEAAEACUJBSURVLkNPTQAEcGFsbw”
)
Stream Load
Broker load是一个同步的导入方式,用户通过发送HTTP协议将本地文件或者数据流导入到Doris中,Stream Load同步执行导入并返回结果,用户可以通过返回判断导入是否成功。
适用场景
Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
基本原理
下图展示了 Stream load 的主要流程,省略了一些导入细节。
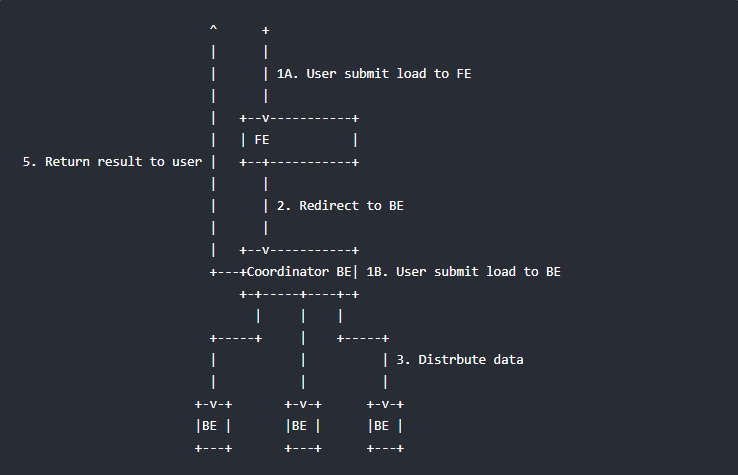
Stream load 中,Doris 会选定一个节点作为 Coordinator 节点。该节点负责接数据并分发数据到其他数据节点。
用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。
导入的最终结果由 Coordinator BE 返回给用户。
语法
具体帮助使用help stream load查看
数据导入演示
操作步骤
说明
1
进入mysqlclient,清空上次导入到user_result表的数据
truncate table user_result;

2
通过命令将csv将数据导入到doris,-H指定参数,column_seqarator指定分割符,-T指定数据源文件(在csv文件目录下执行)
curl --location-trusted -u root -H “label:123” -H “column_separator:,” -T user.csv -X PUT http://node1:8030/api/test_db/user_result/_stream_load

3
查询导入表的数据

其他导入案例参考
- 将本地文件’testData’中的数据导入到数据库’testDb’中’testTbl’的表,使用Label用于去重
curl **–**location-trusted -u root -H “label:123” -T testData http😕/host:port/api/testDb/testTbl/_stream_load
- 将本地文件’testData’中的数据导入到数据库’testDb’中’testTbl’的表,使用Label用于去重, 并且只导入k1等于20180601的数据
curl **–**location-trusted -u root **-**H “label:123” -H “where: k1=20180601” -T testData http😕/host:port/api/testDb/testTbl/_stream_load
- 将本地文件’testData’中的数据导入到数据库’testDb’中’testTbl’的表, 允许20%的错误率(用户是defalut_cluster中的)
curl **–**location-trusted -u root **-**H “label:123” -H “max_filter_ratio:0.2” -T testData http😕/host:port/api/testDb/testTbl/_stream_load
- 将本地文件’testData’中的数据导入到数据库’testDb’中’testTbl’的表, 允许20%的错误率,并且指定文件的列名(用户是defalut_cluster中的)
curl **–**location-trusted -u root **-**H “label:123” **-**H “max_filter_ratio:0.2” -H “columns: k2, k1, v1” -T testData http😕/host:port/api/testDb/testTbl/_stream_load
- 将本地文件’testData’中的数据导入到数据库’testDb’中’testTbl’的表中的p1, p2分区, 允许20%的错误率。
curl **–**location-trusted -u root **-**H “label:123” **-**H “max_filter_ratio:0.2” -H “partitions: p1, p2” -T testData http😕/host:port/api/testDb/testTbl/_stream_load
- 使用streaming方式导入(用户是defalut_cluster中的)
seq 1 10 | awk ‘{OFS="\t"}{print $1, $1 * 10}’ | curl –location-trusted -u root -T - http😕/host:port/api/testDb/testTbl/_stream_load
- 导入含有HLL列的表,可以是表中的列或者数据中的列用于生成HLL列
curl **–**location-trusted -u root -H “columns: k1, k2, v1=hll_hash(k1)” -T testData http😕/host:port/api/testDb/testTbl/_stream_load
Routine Load
例行导入功能为用户提供了义中自动从指定数据源进行数据导入的功能
适用场景
当前仅支持kafka系统进行例行导入。
使用限制
- 支持无认证的 Kafka 访问,以及通过 SSL 方式认证的 Kafka 集群。
- 支持的消息格式为 csv 文本格式。每一个 message 为一行,且行尾不包含换行符。
- 仅支持 Kafka 0.10.0.0(含) 以上版本。
基本原理
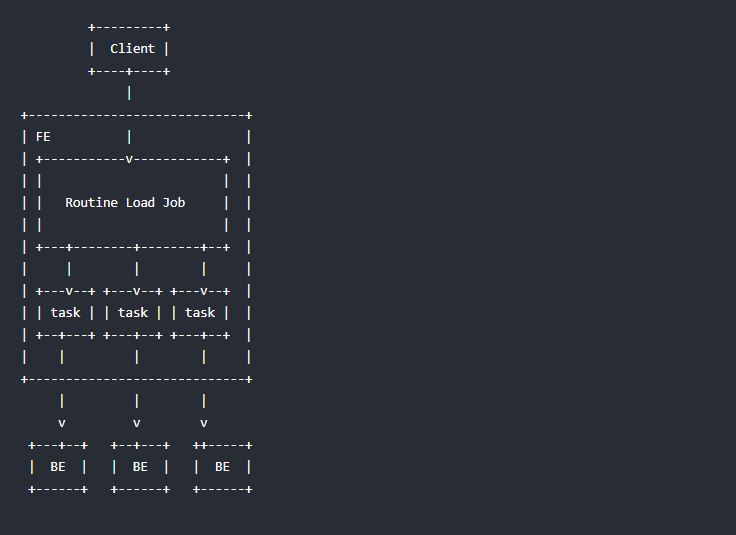
如上图,Client 向 FE 提交一个例行导入作业。
FE 通过 JobScheduler 将一个导入作业拆分成若干个 Task。每个 Task 负责导入指定的一部分数据。Task 被 TaskScheduler 分配到指定的 BE 上执行。
在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。导入完成后,向 FE 汇报。
FE 中的 JobScheduler 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
整个例行导入作业通过不断的产生新的 Task,来完成数据不间断的导入。
前置操作
- 启动zookeeper集群(三台节点都启动):zkServer.sh start
- 启动kafka集群,创建topic,并向topic写入一批数据
创建例行导入任务
创建例行导入任务的的详细语法可以连接到 Doris 后,执行 HELP ROUTINE LOAD; 查看语法帮助。这里主要详细介绍,创建作业时的注意事项。
语法:
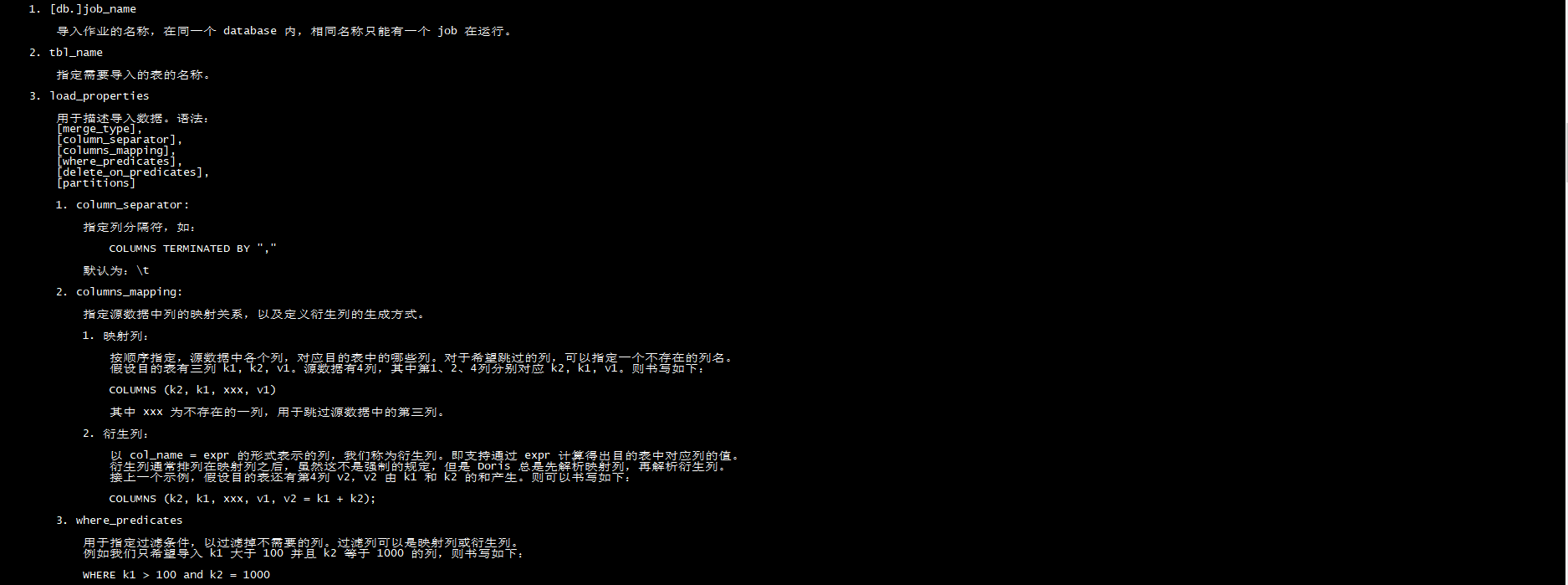
CREATE ROUTINE LOAD **[db.]**job_name ON tbl_name
[load_properties]
[job_properties]
FROM data_source
[data_source_properties]
数据导入演示
操作步骤
说明
1
启动kafka集群(三台节点都启动)
cd /export/server/kafka_2.11-0.10.0.0
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
2
创建topic
bin/kafka-topics.sh --create \
–zookeeper node1:2181,node2:2181,node3:2181 \
–replication-factor 1 \
–partitions 1 \
–topic test

3
往test topic中插入一批测试数据
启动kafka生产者命令行工具
bin/kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic test

每个字段以\t分割
4
在doris中创建对应表
create table student_kafka
(
id int,
name varchar(50),
age int
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH**(id)** BUCKETS 10**;**
5
创建导入作业,desired_concurrent_number指定并行度
CREATE ROUTINE LOAD test_db**.**kafka_job1 on student_kafka
PROPERTIES
(
“desired_concurrent_number”=“1”,
“strict_mode”=“false”,
“format” = “json”
)
FROM KAFKA
(
“kafka_broker_list”= “node1:9092,node2:9092,node3:9092”,
“kafka_topic” = “test”,
“property.group.id” = “test_group_1”,
“property.kafka_default_offsets” = “OFFSET_BEGINNING”,
“property.enable.auto.commit” = “false”
);
6
查询表的数据(有一定延迟时间)
select * from student_kafka;
查看导入作业状态
- 查看作业状态的具体命令和示例可以通过 HELP SHOW ROUTINE LOAD; 命令查看。
- 只能查看当前正在运行中的任务,已结束和未开始的任务无法查看。
HELP SHOW ROUTINE LOAD;

SHOW ALL ROUTINE LOAD;
显示 test_db 下,所有的例行导入作业(包括已停止或取消的作业)。结果为一行或多行。
修改作业属性
用户可以修改已经创建的作业。具体说明可以通过 HELP ALTER ROUTINE LOAD; 命令查看。
作业控制
用户可以通过一下 三个命令来控制作业:
- STOP:停止
- PAUSE:暂停
- RESUME:重启
可以通过以下三个命令查看帮助和示例。
- HELP STOP ROUTINE LOAD;
- HELP PAUSE ROUTINE LOAD;
- HELP RESUME ROUTINE LOAD;
Insert Into
Insert Into 语句的使用方式和 MySQL 等数据库中 Insert Into 语句的使用方式类似。但在 Doris 中,所有的数据写入都是一个独立的导入作业。所以这里将 Insert Into 也作为一种导入方式介绍。
主要的 Insert Into 命令包含以下两种;
- INSERT INTO tbl SELECT …
- INSERT INTO tbl (col1, col2, …) VALUES (1, 2, …), (1,3, …);
其中第二种命令仅用于 Demo,不要使用在测试或生产环境中。
创建导入
Insert Into 命令需要通过 MySQL 协议提交,创建导入请求会同步返回导入结果。
语法:
INSERT INTO table_name [partition_info] [WITH LABEL label**]** [col_list] [query_stmt] [VALUES];
示例:
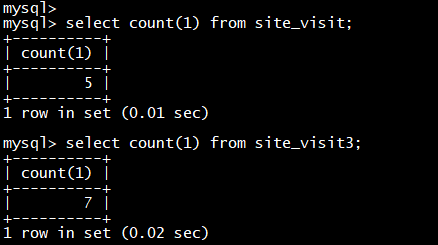
INSERT INTO site_visit WITH LABEL label1 SELECT * FROM site_visit3**;**

注意:
当需要使用 CTE(Common Table Expressions) 作为 insert 操作中的查询部分时,必须指定 WITH LABEL 和 column list 部分。示例
INSERT INTO site_visit WITH LABEL label1 SELECT * FROM site_visit3**;**
导入结果
Insert Into 本身就是一个 SQL 命令,其返回结果会根据执行结果的不同,分为以下几种:
- 结果集为空
如果 insert 对应 select 语句的结果集为空,则返回如下:
mysql**>** insert into tbl1 select * from empty_tbl**;**
Query OK**,** 0 rows affected (0.02 sec)
Query OK 表示执行成功。0 rows affected 表示没有数据被导入。
- 结果集不为空
在结果集不为空的情况下。返回结果分为如下几种情况:
-
- Insert 执行成功并可见:
mysql**>** insert into tbl1 select * from tbl2**;**
Query OK**,** 4 rows affected (0.38 sec)
{‘label’:‘insert_8510c568-9eda-4173-9e36-6adc7d35291c’, ‘status’:‘visible’, ‘txnId’:‘4005’}
mysql**>** insert into tbl1 with label my_label1 select * from tbl2**;**
Query OK**,** 4 rows affected (0.38 sec)
{‘label’:‘my_label1’, ‘status’:‘visible’, ‘txnId’:‘4005’}
mysql**>** insert into tbl1 select * from tbl2**;**
Query OK**,** 2 rows affected**,** 2 warnings (0.31 sec)
{‘label’:‘insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:‘visible’, ‘txnId’:‘4005’}
mysql**>** insert into tbl1 select * from tbl2**;**
Query OK**,** 2 rows affected**,** 2 warnings (0.31 sec)
{‘label’:‘insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:‘committed’, ‘txnId’:‘4005’}
Query OK 表示执行成功。4 rows affected 表示总共有4行数据被导入。2 warnings 表示被过滤的行数。
同时会返回一个 json 串:
{‘label’:‘my_label1’, ‘status’:‘visible’, ‘txnId’:‘4005’}
{‘label’:‘insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:‘committed’, ‘txnId’:‘4005’}
{‘label’:‘my_label1’, ‘status’:‘visible’, ‘txnId’:‘4005’, ‘err’:‘some other error’}
label 为用户指定的 label 或自动生成的 label。Label 是该 Insert Into 导入作业的标识。每个导入作业,都有一个在单 database 内部唯一的 Label。
status 表示导入数据是否可见。如果可见,显示 visible,如果不可见,显示 committed。
txnId 为这个 insert 对应的导入事务的 id。
err 字段会显示一些其他非预期错误。
当需要查看被过滤的行时,用户可以通过如下语句
show load where label**=“xxx”;**
返回结果中的 URL 可以用于查询错误的数据,具体见后面 查看错误行 小结。
数据不可见是一个临时状态,这批数据最终是一定可见的
可以通过如下语句查看这批数据的可见状态:
show transaction where id**=4005;**
返回结果中的 TransactionStatus 列如果为 visible,则表述数据可见。
-
- Insert 执行失败
执行失败表示没有任何数据被成功导入,并返回如下:
mysql**>** insert into tbl1 select * from tbl2 where k1 = “a”;
ERROR 1064 (HY000): all partitions have no load data. url**😗* http**😕/10.74.167.16:8042/api/_load_error_log?file=__shard_2/error_log_insert_stmt_ba8bb9e158e4879-**ae8de8507c0bf8a2_ba8bb9e158e4879_ae8de8507c0bf8a2
其中 ERROR 1064 (HY000): all partitions have no load data 显示失败原因。后面的 url 可以用于查询错误的数据,具体见后面 查看错误行 小结。
综上,对于 insert 操作返回结果的正确处理逻辑应为:
- 如果返回结果为 ERROR 1064 (HY000),则表示导入失败。
- 如果返回结果为 Query OK,则表示执行成功。
- 如果 rows affected 为 0,表示结果集为空,没有数据被导入。
- 如果 rows affected 大于 0:
- 如果 status 为 committed,表示数据还不可见。需要通过 show transaction 语句查看状态直到 visible
- 如果 status 为 visible,表示数据导入成功。
- 如果 warnings 大于 0,表示有数据被过滤,可以通过 show load 语句获取 url 查看被过滤的行
删除数据(Delete)
Doris 目前可以通过两种方式删除数据:DELETE FROM 语句和 ALTER TABLE DROP PARTITION 语句。
语法:
DELETE FROM table_name [PARTITION partition_name**]**
WHERE
column_name1 op { value | value_list } [ AND column_name2 op { value | value_list } …];
DELETE FROM Statement(条件删除)
delete from 语句类似标准 delete 语法,具体使用可以查看 help delete; 帮助。这里主要说明一些注意事项。
- 该语句只能针对 Partition 级别进行删除。如果一个表有多个 partition 含有需要删除的数据,则需要执行多次针对不同 Partition 的 delete 语句。而如果是没有使用 Partition 的表,partition 的名称即表名。
- where 后面的条件谓词只能针对 Key 列,并且谓词之间,只能通过 AND 连接。如果想实现 OR 的语义,需要执行多条 delete。
- delete 是一个同步命令,命令返回即表示执行成功。
- 从代码实现角度,delete 是一种特殊的导入操作。该命令所导入的内容,也是一个新的数据版本,只是该版本中只包含命令中指定的删除条件。在实际执行查询时,会根据这些条件进行查询时过滤。所以,不建议大量频繁使用 delete 命令,因为这可能导致查询效率降低。
- 数据的真正删除是在 BE 进行数据 Compaction 时进行的。所以执行完 delete 命令后,并不会立即释放磁盘空间。
- delete 命令一个较强的限制条件是,在执行该命令时,对应的表,不能有正在进行的导入任务(包括 PENDING、ETL、LOADING)。而如果有 QUORUM_FINISHED 状态的导入任务,则可能可以执行。
- delete 也有一个隐含的类似 QUORUM_FINISHED 的状态。即如果 delete 只在多数副本上完成了,也会返回用户成功。但是会在后台生成一个异步的 delete job(Async Delete Job),来继续完成对剩余副本的删除操作。如果此时通过 show delete 命令,可以看到这种任务在 state 一栏会显示 QUORUM_FINISHED。
如:
delete from student_kafka where id**=1;**

DROP PARTITION Statement(删除分区)
该命令可以直接删除指定的分区。因为 Partition 是逻辑上最小的数据管理单元,所以使用 DROP PARTITION 命令可以很轻量的完成数据删除工作。并且该命令不受 load 以及任何其他操作的限制,同时不会影响查询效率。是比较推荐的一种数据删除方式。
该命令是同步命令,执行成功即生效。而后台数据真正删除的时间可能会延迟10分钟左右。
简单查询
简单查询
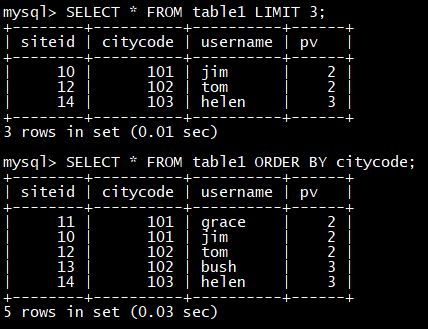
SELECT * FROM table1 LIMIT 3**;**
SELECT * FROM table1 ORDER BY citycode**;**
Join
SELECT SUM(table1.pv) FROM table1 JOIN table2 WHERE table1**.siteid = table2.siteid;**
select table1**.siteid,** sum(table1.pv) from table1 join table2 where table1**.siteid = table2.siteid group by table1.siteid;**

子查询
SELECT SUM(pv) FROM table2 WHERE siteid IN (SELECT siteid FROM table1 WHERE siteid > 1**);**

高级功能
表结构变更
使用alter table 命令, 可进行
- 增加列
- 删除列
- 修改列类型
- 改变列顺序
对上面的table1 添加一列
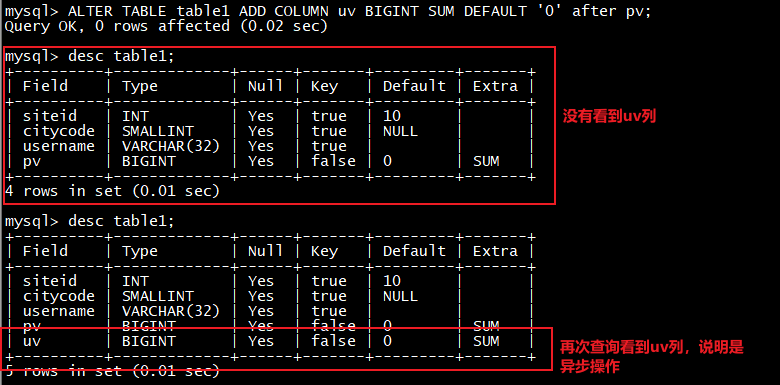
ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT ‘0’ after pv**;**
查看执行进度
show alter table column;

如果想取消掉正在执行的alter, 则使用
show alter table column;

更多帮助,可以参阅: HELP ALTER TABLE
Rollup
Rollup 可以理解为 Table 的一个物化索引结构。物化是因为其数据在物理上独立存储,而 索引 的意思是,Rollup可以调整列顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
对于 table1 明细数据是 siteid, citycode, username 三者构成一组 key,从而对 pv 字段进行聚合;如果业务方经常有看城市 pv 总量的需求,可以建立一个只有 citycode, pv 的rollup。
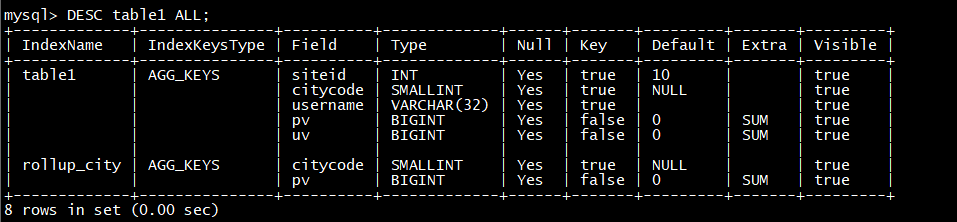
ALTER TABLE table1 ADD ROLLUP rollup_city**(citycode,** pv**);**
通过命令查看完成状态
SHOW ALTER TABLE ROLLUP;

之后可以查看完成情况
DESC table1 ALL;
可以使用以下命令取消当前正在执行的作业:
CANCEL ALTER TABLE ROLLUP FROM table1**;**
Rollup 建立之后,查询不需要指定 Rollup 进行查询。还是指定原有表进行查询即可。程序会自动判断是否应该使用 Rollup。是否命中 Rollup可以通过 EXPLAIN your_sql; 命令进行查看。
更多帮助,可以参阅 HELP ALTER TABLE。
高级设置
增大内存
内存不够时, 查询可能会出现‘Memory limit exceeded’, 这是因为doris对每个用户默认设置内存限制为 2g
SHOW VARIABLES LIKE “%mem_limit%”;
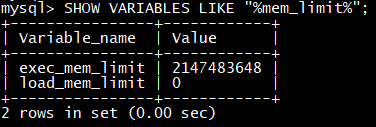
exec_mem_limit 的单位是 byte,可以通过 SET 命令改变 exec_mem_limit 的值。如改为 8GB。
SET exec_mem_limit = 8589934592**;**

上述设置仅仅在当前session有效, 如果想永久有效, 需要添加 global 参数
SET GLOBAL exec_mem_limit = 8589934592**;**

修改超时时间
doris默认最长查询时间为300s, 如果仍然未完成, 会被cancel掉
SHOW VARIABLES LIKE “%query_timeout%”;
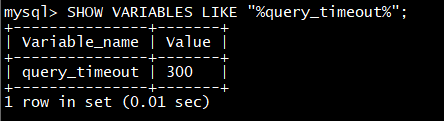
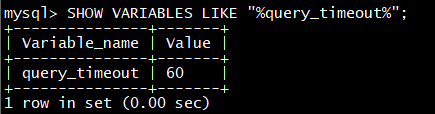
可以修改为60s
SET query_timeout = 60**;**

同样, 如果需要全局生效需要添加参数 global
set global query_timeout = 60**;**

Broadcast/Shuffle Join
doris在join操作的时候时候, 默认使用broadcast的方式进行join, 即将小表通过广播的方式广播到大表所在的节点, 形成内存hash, 然后流式读出大表数据进行hashjoin
但如果小表的数据量也很大的时候, 就会造成内存溢出, 此时需要通过shuffle join的方式进行, 也被称为partition join. 即将大表小表都按照join的key进行hash, 然后进行分布式join
- 使用 Broadcast Join(默认)
select sum(table1.pv) from table1 join table2 where table1**.siteid = 12;**

- 显示指定braodcast
select sum(table1.pv) from table1 join [broadcast] table2 where table1**.siteid = 12;**

- 使用suffle join
select sum(table1.pv) from table1 join [shuffle] table2 where table1**.siteid = 12;**

doris的高可用方案
当部署多个 FE 节点时,用户可以在多个fe上部署负载均衡实现或者通过mysql connect 自动重连
jdbc**:mysql😕/[host:port],[host:port]…/[database][?propertyName1][=propertyValue1][&propertyName2][=propertyValue2]…**
或者应用可以连接到和应用部署到同一机器上的 MySQL Proxy,通过配置 MySQL Proxy 的 Failover 和 Load Balance 功能来达到目的。
数据模型
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。一张表包括行(Row)和列(Column)。Row即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column可以分为两大类:Key(维度列)和Value(指标列)
Doris 的数据模型主要分为3类:
- Aggregate
- Uniq
- Duplicate
Aggregate模型(聚合模型)

这是一个典型的用户信息和访问行为的事实表。 在一般星型模型中,用户信息和访问行为一般分别存放在维度表和事实表中。这里我们为了更加方便的解释 Doris 的数据模型,将两部分信息统一存放在一张表中。
表中的列按照是否设置了 AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置 AggregationType 的,如 user_id、date、age … 等称为 Key,而设置了 AggregationType 的称为 Value。
当我们导入数据时,对于 Key 列相同的行和聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。 AggregationType 目前有以下四种聚合方式:
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
假设我们有以下导入数据(原始数据):

AGGREGATEKEY模型可以提前聚合数据,适合报表和多维度业务
- 演示一:导入数据聚合
操作步骤
说明
1
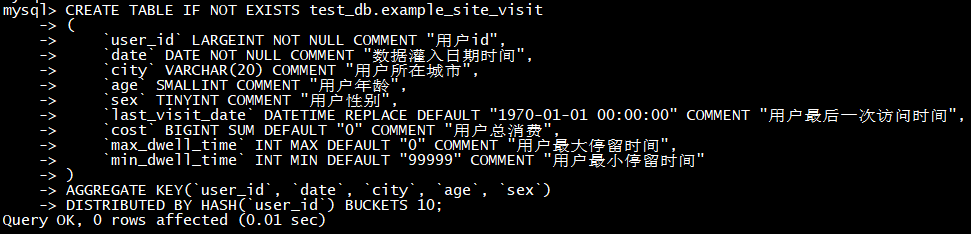
创建doris表
CREATE TABLE IF NOT EXISTS test_db**.**example_site_visit
(
`user_id` LARGEINT NOT NULL COMMENT “用户id”,
`date` DATE NOT NULL COMMENT “数据灌入日期时间”,
`city` VARCHAR(20) COMMENT “用户所在城市”,
`age` SMALLINT COMMENT “用户年龄”,
`sex` TINYINT COMMENT “用户性别”,
`last_visit_date` DATETIME REPLACE DEFAULT “1970-01-01 00:00:00” COMMENT “用户最后一次访问时间”,
`cost` BIGINT SUM DEFAULT “0” COMMENT “用户总消费”,
`max_dwell_time` INT MAX DEFAULT “0” COMMENT “用户最大停留时间”,
`min_dwell_time` INT MIN DEFAULT “99999” COMMENT “用户最小停留时间”
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH**(`user_id`)** BUCKETS 10**;**
2
插入数据
insert into test_db**.example_site_visit values(10000,‘2020-10-01’,‘北京’,20,0,‘2020-10-01 06:00:00’,20,10,10);**
insert into test_db**.example_site_visit values(10000,‘2020-10-01’,‘北京’,20,0,‘2020-10-01 07:00:00’,15,2,2);**
insert into test_db**.example_site_visit values(10001,‘2020-10-01’,‘北京’,30,1,‘2020-10-01 17:05:45’,2,22,22);**
insert into test_db**.example_site_visit values(10002,‘2020-10-02’,‘上海’,20,1,‘2020-10-02 12:59:12’,200,5,5);**
insert into test_db**.example_site_visit values(10003,‘2020-10-02’,‘广州’,32,0,‘2020-10-02 11:20:00’,30,11,11);**
insert into test_db**.example_site_visit values(10004,‘2020-10-01’,‘深圳’,35,0,‘2020-10-01 10:00:15’,100,3,3);**
insert into test_db**.example_site_visit values(10004,‘2020-10-03’,‘深圳’,35,0,‘2020-10-03 10:20:22’,11,6,6);**
3
select * from test_db**.example_site_visit;**

可以看到,用户 10000 只剩下了一行聚合后的数据。而其余用户的数据和原始数据保持一致。这里先解释下用户 10000 聚合后的数据:
前5列没有变化,从第6列 last_visit_date 开始:
2020-10-01 07:00:00:因为 last_visit_date 列的聚合方式为 REPLACE,所以 2020-10-01 07:00:00 替换了 2020-10-01 06:00:00 保存了下来。
注:在同一个导入批次中的数据,对于 REPLACE 这种聚合方式,替换顺序不做保证。如在这个例子中,最终保存下来的,也有可能是 2020-10-01 06:00:00。而对于不同导入批次中的数据,可以保证,后一批次的数据会替换前一批次。
35:因为 cost 列的聚合类型为 SUM,所以由 20 + 15 累加获得 35。
10:因为 max_dwell_time 列的聚合类型为 MAX,所以 10 和 2 取最大值,获得 10。
2:因为 min_dwell_time 列的聚合类型为 MIN,所以 10 和 2 取最小值,获得 2。
经过聚合,Doris 中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
- 演示二:保留明细数据
操作步骤
说明
1
创建doris表
CREATE TABLE IF NOT EXISTS test_db**.**example_site_visit2
(
`user_id` LARGEINT NOT NULL COMMENT “用户id”,
`date` DATE NOT NULL COMMENT “数据灌入日期时间”,
`timestamp` DATETIME COMMENT “数据灌入时间,精确到秒”,
`city` VARCHAR(20) COMMENT “用户所在城市”,
`age` SMALLINT COMMENT “用户年龄”,
`sex` TINYINT COMMENT “用户性别”,
`last_visit_date` DATETIME REPLACE DEFAULT “1970-01-01 00:00:00” COMMENT “用户最后一次访问时间”,
`cost` BIGINT SUM DEFAULT “0” COMMENT “用户总消费”,
`max_dwell_time` INT MAX DEFAULT “0” COMMENT “用户最大停留时间”,
`min_dwell_time` INT MIN DEFAULT “99999” COMMENT “用户最小停留时间”
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH**(`user_id`)** BUCKETS 10**;**
2
插入数据
insert into test_db**.example_site_visit2 values(10000,‘2017-10-01’,‘2017-10-01 08:00:05’,‘北京’,20,0,‘2017-10-01 06:00:00’,20,10,10);**
insert into test_db**.example_site_visit2 values(10000,‘2017-10-01’,‘2017-10-01 09:00:05’,‘北京’,20,0,‘2017-10-01 07:00:00’,15,2,2);**
insert into test_db**.example_site_visit2 values(10001,‘2017-10-01’,‘2017-10-01 18:12:10’,‘北京’,30,1,‘2017-10-01 17:05:45’,2,22,22);**
insert into test_db**.example_site_visit2 values(10002,‘2017-10-02’,‘2017-10-02 13:10:00’,‘上海’,20,1,‘2017-10-02 12:59:12’,200,5,5);**
insert into test_db**.example_site_visit2 values(10003,‘2017-10-02’,‘2017-10-02 13:15:00’,‘广州’,32,0,‘2017-10-02 11:20:00’,30,11,11);**
insert into test_db**.example_site_visit2 values(10004,‘2017-10-01’,‘2017-10-01 12:12:48’,‘深圳’,35,0,‘2017-10-01 10:00:15’,100,3,3);**
insert into test_db**.example_site_visit2 values(10004,‘2017-10-03’,‘2017-10-03 12:38:20’,‘深圳’,35,0,‘2017-10-03 10:20:22’,11,6,6);**
3
select * from test_db**.**example_site_visit2 ;

我们可以看到,存储的数据,和导入数据完全一样,没有发生任何聚合。这是因为,这批数据中,因为加入了 timestamp 列,所有行的 Key 都不完全相同。
也就是说,只要保证导入的数据中,每一行的 Key 都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。
- 演示三:导入数据与已有数据聚合
刚才讲了数据在导入的时候会有一次合并,因为要聚合。还有一种情况是如果我先导入了一批数据,然后又导入了一批数据,这两批的数据之间有相同的时候,也需要进行一个合并。
操作步骤
说明
1
创建doris表
CREATE TABLE IF NOT EXISTS test_db**.**example_site_visit3
(
`user_id` LARGEINT NOT NULL COMMENT “用户id”,
`date` DATE NOT NULL COMMENT “数据灌入日期时间”,
`city` VARCHAR(20) COMMENT “用户所在城市”,
`age` SMALLINT COMMENT “用户年龄”,
`sex` TINYINT COMMENT “用户性别”,
`last_visit_date` DATETIME REPLACE DEFAULT “1970-01-01 00:00:00” COMMENT “用户最后一次访问时间”,
`cost` BIGINT SUM DEFAULT “0” COMMENT “用户总消费”,
`max_dwell_time` INT MAX DEFAULT “0” COMMENT “用户最大停留时间”,
`min_dwell_time` INT MIN DEFAULT “99999” COMMENT “用户最小停留时间”
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH**(`user_id`)** BUCKETS 10**;**
2
插入数据
insert into test_db**.example_site_visit3 values(10000,‘2020-10-01’,‘北京’,20,0,‘2020-10-01 06:00:00’,20,10,10);**
insert into test_db**.example_site_visit3 values(10000,‘2020-10-01’,‘北京’,20,0,‘2020-10-01 07:00:00’,15,2,2);**
insert into test_db**.example_site_visit3 values(10001,‘2020-10-01’,‘北京’,30,1,‘2020-10-01 17:05:45’,2,22,22);**
insert into test_db**.example_site_visit3 values(10002,‘2020-10-02’,‘上海’,20,1,‘2020-10-02 12:59:12’,200,5,5);**
insert into test_db**.example_site_visit3 values(10003,‘2020-10-02’,‘广州’,32,0,‘2020-10-02 11:20:00’,30,11,11);**
insert into test_db**.example_site_visit3 values(10004,‘2020-10-01’,‘深圳’,35,0,‘2020-10-01 10:00:15’,100,3,3);**
insert into test_db**.example_site_visit3 values(10004,‘2020-10-03’,‘深圳’,35,0,‘2020-10-03 10:20:22’,11,6,6);**
3
select * from test_db**.**example_site_visit3 ;

4
再导入一批新的数据:
insert into test_db**.example_site_visit3 values(10004,‘2020-10-03’,‘深圳’,35,0,‘2020-10-03 11:22:00’,44,19,19);**
insert into test_db**.example_site_visit3 values(10005,‘2020-10-03’,‘长沙’,29,1,‘2020-10-03 18:11:02’,3,1,1);**
5
select * from test_db**.**example_site_visit3 ;

可以看到,用户 10004 的已有数据和新导入的数据发生了聚合。同时新增了 10005 用户的数据。
数据的聚合,在 Doris 中有如下三个阶段发生:
- 每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
- 底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
- 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。(可参阅聚合模型的局限性一节获得更多详情。)
Uniq模型(唯一主键)
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
Unique Key 的模型主要面向留存分析或者订单分析的场景,他们需要一个 Unique Key 的约束去保证整个数据不丢不重。然后 Duplicate Key 的模型,就是这个数据可能重复,
- 演示
操作步骤
说明
1
创建doris表
CREATE TABLE IF NOT EXISTS test_db**.user**
(
`user_id` LARGEINT NOT NULL COMMENT “用户id”,
`username` VARCHAR(50) NOT NULL COMMENT “用户昵称”,
`city` VARCHAR(20) COMMENT “用户所在城市”,
`age` SMALLINT COMMENT “用户年龄”,
`sex` TINYINT COMMENT “用户性别”,
`phone` LARGEINT COMMENT “用户电话”,
`address` VARCHAR(500) COMMENT “用户地址”,
`register_time` DATETIME COMMENT “用户注册时间”
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH**(`user_id`)** BUCKETS 10**;**
3
插入数据
insert into test_db**.user** values(10000,‘zhangsan’,‘北京’,20,0,13112345312,‘北京西城区’,‘2020-10-01 07:00:00’);
insert into test_db**.user** values(10000,‘zhangsan’,‘北京’,20,0,13112345312,‘北京xx区’,‘2020-11-15 06:10:20’);

4
查询数据
select * from test_db**.user;**

即 Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样
Duplicate 模型(冗余模型)
Duplicate Key 的模型,就是说支持一个用户导入之后把这个数据全部放在数据库里面,我们不再做提前的聚合,也不单独保证唯一性,只做一个排序。因此,我们引入 Duplicate 数据模型来满足这类需求。
如:对于有些日志分析它不太在意数据多几条或者少几条,可能只关心排序,这个时候可能重复 Key 的模型会更加有效果。
- 演示
操作步骤
说明
1
创建doris表
CREATE TABLE IF NOT EXISTS test_db.example_log
(
`timestamp` DATETIME NOT NULL COMMENT “日志时间”,
`type` INT NOT NULL COMMENT “日志类型”,
`error_code` INT COMMENT “错误码”,
`error_msg` VARCHAR(1024) COMMENT “错误详细信息”,
`op_id` BIGINT COMMENT “负责人id”,
`op_time` DATETIME COMMENT “处理时间”
)
DUPLICATE KEY(`timestamp`, `type`)
DISTRIBUTED BY HASH**(`timestamp`)** BUCKETS 10**;**
2
插入数据
insert into test_db**.example_log values(‘2020-10-01 08:00:05’,1,404,‘not found page’,** 101**,** ‘2020-10-01 08:00:05’);
insert into test_db**.example_log values(‘2020-10-01 08:00:05’,1,404,‘not found page’,** 101**,** ‘2020-10-01 08:00:05’);
insert into test_db**.example_log values(‘2020-10-01 08:00:05’,2,404,‘not found page’,** 101**,** ‘2020-10-01 08:00:06’);
insert into test_db**.example_log values(‘2020-10-01 08:00:06’,2,404,‘not found page’,** 101**,** ‘2020-10-01 08:00:07’);
3
查询数据
select * from test_db.example_log**;**

这种数据模型区别于 Aggregate 和 Uniq 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序
数据模型的总结

索引和Rollup
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
Rollup可以理解为表的一个物化索引结构,Rollup可以调整列的顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
基本概念
在 Doris 中,我们将用户通过建表语句创建出来的表成为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。
在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据。
- 在聚合表的基础上,按照其他维度再进一步聚合,提升查询效率。
- Doris索引是固定的前缀索引,用rollup改变索引顺序
下面我们用示例详细说明在不同数据模型中的 ROLLUP 表及其作用。
案例演示
- 在聚合表的基础上,按照其他维度再进一步聚合,提升查询效率。
以site_visit表为例
操作步骤
说明
1
创建表
CREATE TABLE IF NOT EXISTS test_db**.**site_visit
(
`user_id` LARGEINT NOT NULL COMMENT “用户id”,
`date` DATE NOT NULL COMMENT “数据灌入日期时间”,
`city` VARCHAR(20) COMMENT “用户所在城市”,
`age` SMALLINT COMMENT “用户年龄”,
`sex` TINYINT COMMENT “用户性别”,
`last_visit_date` DATETIME REPLACE DEFAULT “1970-01-01 00:00:00” COMMENT “用户最后一次访问时间”,
`cost` BIGINT SUM DEFAULT “0” COMMENT “用户总消费”,
`max_dwell_time` INT MAX DEFAULT “0” COMMENT “用户最大停留时间”,
`min_dwell_time` INT MIN DEFAULT “99999” COMMENT “用户最小停留时间”
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH**(`user_id`)** BUCKETS 10**;**
2
查看表的结构信息
desc site_visit all;
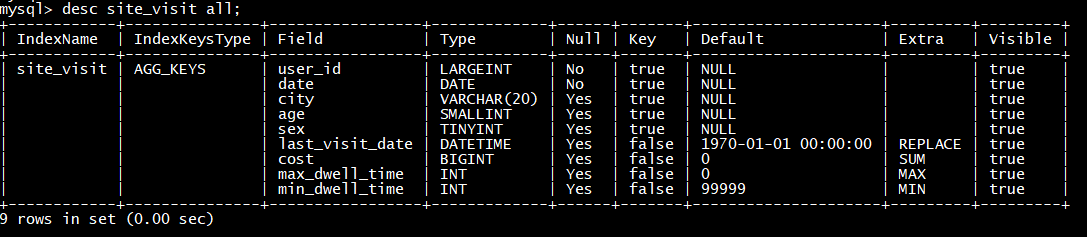
3
比如需要查看某个城市的user_id数,那么可以建立一个只有user_id和city的rollup
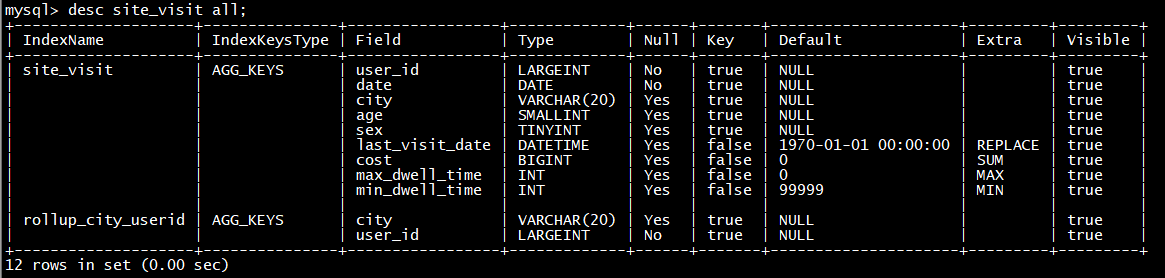
alter table site_visit add rollup rollup_city_userid**(city,user_id);**

4
查看表的结构信息
desc site_visit all;
5
然后可以通过explain查看执行计划,是否使用到了rollup
explain select date from site_visit where city=‘北京’;
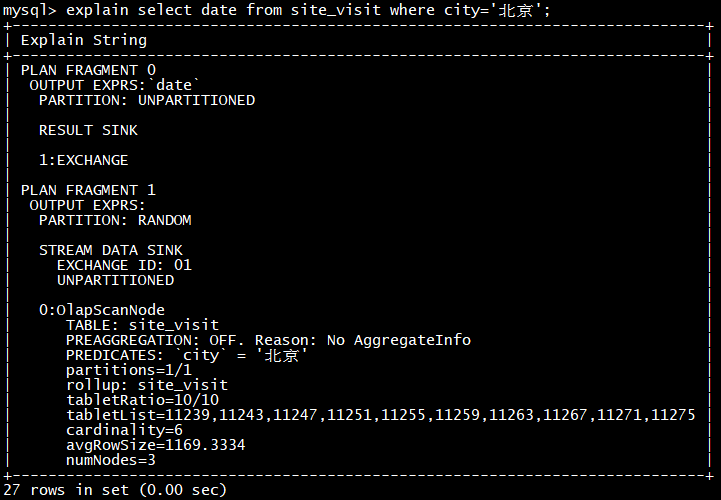
Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
6
通过命令查看完成状态
SHOW ALTER TABLE ROLLUP;

- Doris索引是固定的前缀索引,用rollup改变索引顺序
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。
Base 表结构如下:
列名
类型
user_id
BIGINT
age
INT
message
VARCHAR(100)
max_dwell_time
DATETIME
min_dwell_time
DATETIME
我们可以在此基础上创建一个 ROLLUP 表:
列名
类型
age
INT
user_id
BIGINT
message
VARCHAR(100)
max_dwell_time
DATETIME
min_dwell_time
DATETIME
可以看到,ROLLUP 和 Base 表的列完全一样,只是将 user_id 和 age 的顺序调换了。那么当我们进行如下查询时:
SELECT * FROM table where age**=20 and message LIKE “%error%”;**
会优先选择 ROLLUP 表,因为 ROLLUP 的前缀索引匹配度更高。
Aggregate 和 Uniq 模型中的 ROLLUP
因为 Uniq 只是 Aggregate 模型的一个特例,所以这里我们不加以区别。
- 示例1:获得每个用户的总消费
接Aggregate 模型小节的示例2,Base 表结构如下:

可以看到,ROLLUP 中仅保留了每个 user_id,在 cost 列上的 SUM 的结果。那么当我们进行如下查询时:
SELECT user_id**,** sum(cost) FROM table GROUP BY user_id**;**
Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
- 示例2:获得不同城市,不同年龄段用户的总消费、最长和最短页面驻留时间
紧接示例1。我们在 Base 表基础之上,再创建一个 ROLLUP:

当我们进行如下这些查询时:
SELECT city**,** age**,** sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city**,** age**;**
SELECT city**,** sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city**;**
SELECT city**,** age**,** sum(cost), min(min_dwell_time) FROM table GROUP BY city**,** age**;**
Doris 会自动命中这个 ROLLUP 表。
Duplicate 模型中的 ROLLUP
前缀索引
不同于传统的数据库设计,Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。
本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。‘’
在 Aggregate、Uniq 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。
而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
我们将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。我们举例说明:

当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id**=1829239 and age=**20;
该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age**=**20;
所以在建表时,正确的选择列顺序,能够极大地提高查询效率。
ROLLUP 调整前缀索引
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。举例说明。

可以看到,ROLLUP 和 Base 表的列完全一样,只是将 user_id 和 age 的顺序调换了。那么当我们进行如下查询时:
SELECT * FROM table where age**=20 and message LIKE “%error%”;**
会优先选择 ROLLUP 表,因为 ROLLUP 的前缀索引匹配度更高。
聚合模型的局限性
这里我们针对 Aggregate 模型(包括 Uniq 模型),来介绍下聚合模型的局限性。
在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。

我们在查询引擎中加入了聚合算子,来保证数据对外的一致性。
另外,在聚合列(Value)上,执行与聚合类型不一致的聚合类查询时,要注意语意。比如我们在如上示例中执行如下查询:
SELECT MIN(cost) FROM table;
得到的结果是 5,而不是 1。
同时,这种一致性保证,在某些查询中,会极大的降低查询效率。
我们以最基本的 count(*) 查询为例:
SELECT COUNT(*) FROM table;
在其他数据库中,这类查询都会很快的返回结果。因为在实现上,我们可以通过如“导入时对行进行计数,保存count的统计信息”,或者在查询时“仅扫描某一列数据,获得count值”的方式,只需很小的开销,即可获得查询结果。但是在 Doris 的聚合模型中,这种查询的开销非常大。
我们以刚才的数据为例:
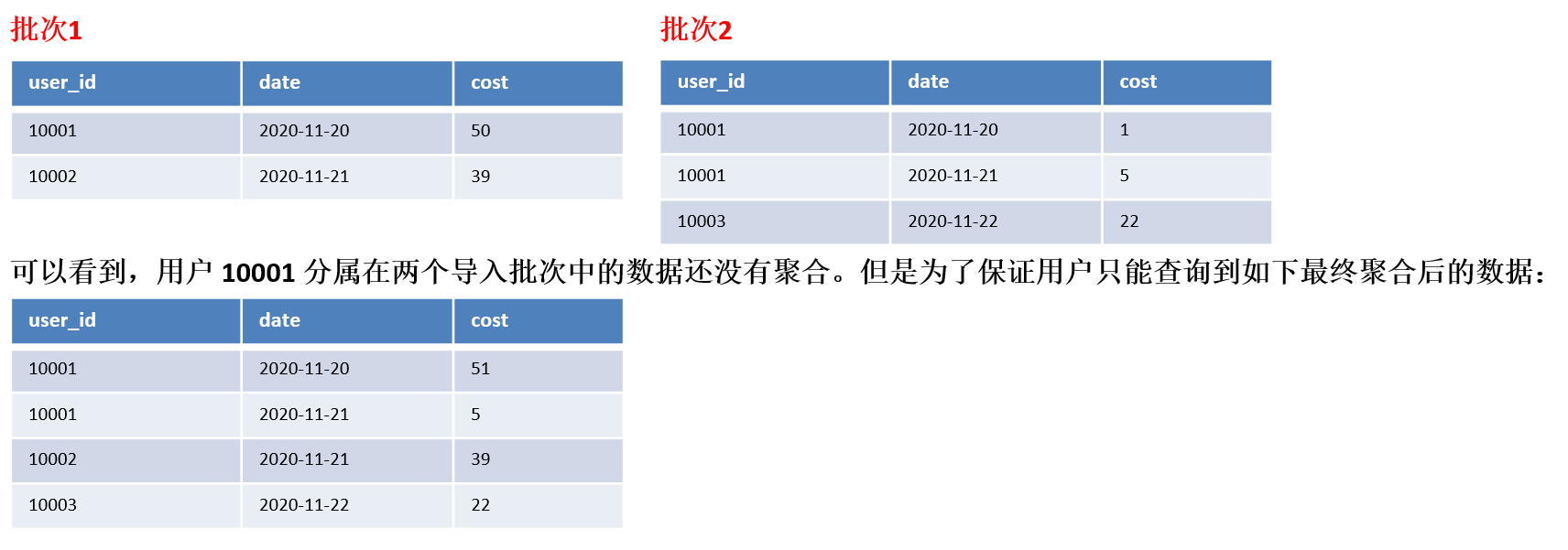
所以,select count(*) from table; 的正确结果应该为 4。但如果我们只扫描 user_id 这一列,如果加上查询时聚合,最终得到的结果是 3(10001, 10002, 10003)。而如果不加查询时聚合,则得到的结果是 5(两批次一共5行数据)。可见这两个结果都是不对的。
为了得到正确的结果,我们必须同时读取 user_id 和 date 这两列的数据,再加上查询时聚合,才能返回 4 这个正确的结果。也就是说,在 count(*) 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是 user_id 和 date),并且聚合后,才能得到语意正确的结果。当聚合列非常多时,count(*) 查询需要扫描大量的数据。
因此,当业务上有频繁的 count(*) 查询时,我们建议用户通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟 count(*)。如刚才的例子中的表结构,我们修改如下:

Duplicate 模型没有聚合模型的这个局限性。因为该模型不涉及聚合语意,在做 count(*) 查询时,任意选择一列查询,即可得到语意正确的结果。
ROLLUP 的几点说明
- ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此 ROLLUP 的含义已经超出了 “上卷” 的范围。这也是为什么我们在源代码中,将其命名为 Materialized Index(物化索引)的原因。
- ROLLUP 是附属于 Base 表的,可以看做是 Base 表的一种辅助数据结构。用户可以在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定。
- ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的ETL阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
- ROLLUP 的数据更新与 Base 表示完全同步的。用户无需关心这个问题。
- ROLLUP 中列的聚合方式,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
- 查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
- 某些类型的查询(如 count(*))在任何条件下,都无法命中 ROLLUP。具体参见接下来的 聚合模型的局限性 一节。
- 可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
- 可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP。
物化视图
物化视图是将预先计算(根据定义好的 SELECT 语句)好的数据集,存储在 Doris 中的一个特殊的表。
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
首先,什么是物化视图?
从定义上来说,就是包含了查询结果的数据库对象,可能是对远程数据的本地Copy;也可能是一个表或多表Join后结果的行或列的子集;也可能是聚合后的结果。说白了,就是预先存储查询结果的一种数据库对象。
适用场景
- 分析需求覆盖明细数据查询以及固定维度查询两方面。
- 查询仅涉及表中的很小一部分列或行。
- 查询包含一些耗时处理操作,比如:时间很久的聚合操作等。
- 查询需要匹配不同前缀索引。
优势
-
对于那些经常重复的使用相同的子查询结果的查询性能大幅提升。
-
Doris自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证base 表和物化视图表的数据一致性。无需任何额外的人工维护成本。
-
查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。
-
自动维护物化视图的数据会造成一些维护开销,会在后面的物化视图的局限性中展开说明。
物化视图 VS Rollup
在没有物化视图功能之前,用户一般都是使用 Rollup 功能通过预聚合方式提升查询效率的。但是 Rollup 具有一定的局限性,他不能基于明细模型做预聚合。
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数。所以物化视图其实是 Rollup 的一个超集。
也就是说,之前 ALTER TABLE ADD ROLLUP 语法支持的功能现在均可以通过 CREATE MATERIALIZED VIEW 实现。
使用物化视图
Doris 系统提供了一整套对物化视图的 DDL 语法,包括创建,查看,删除。DDL 的语法和 PostgreSQL, Oracle都是一致的。
创建物化视图
这里首先你要根据你的查询语句的特点来决定创建一个什么样的物化视图。这里并不是说你的物化视图定义和你的某个查询语句一模一样就最好。这里有两个原则:
- 从查询语句中抽象出,多个查询共有的分组和聚合方式作为物化视图的定义。
- 不需要给所有维度组合都创建物化视图。
首先第一个点,一个物化视图如果抽象出来,并且多个查询都可以匹配到这张物化视图。这种物化视图效果最好。因为物化视图的维护本身也需要消耗资源。
如果物化视图只和某个特殊的查询很贴合,而其他查询均用不到这个物化视图。则会导致这张物化视图的性价比不高,既占用了集群的存储资源,还不能为更多的查询服务。
所以用户需要结合自己的查询语句,以及数据维度信息去抽象出一些物化视图的定义。
第二点就是,在实际的分析查询中,并不会覆盖到所有的维度分析。所以给常用的维度组合创建物化视图即可,从而到达一个空间和时间上的平衡。
通过下面命令就可以创建物化视图了。创建物化视图是一个异步的操作,也就是说用户成功提交创建任务后,Doris 会在后台对存量的数据进行计算,直到创建成功。
CREATE MATERIALIZED VIEW
具体的语法可以通过下面命令查看:
HELP CREATE MATERIALIZED VIEW
支持聚合函数
目前物化视图创建语句支持的聚合函数有:
- SUM, MIN, MAX (Version 0.12)
- COUNT, BITMAP_UNION, HLL_UNION (Version 0.13)
- BITMAP_UNION 的形式必须为:BITMAP_UNION(TO_BITMAP(COLUMN)) column 列的类型只能是整数(largeint也不支持), 或者 BITMAP_UNION(COLUMN) 且 base 表为 AGG 模型。
- HLL_UNION 的形式必须为:HLL_UNION(HLL_HASH(COLUMN)) column 列的类型不能是 DECIMAL , 或者 HLL_UNION(COLUMN) 且 base 表为 AGG 模型
使用限制:
- DML:delete
使用物化视图功能后,由于物化视图实际上是损失了部分维度数据的。所以对表的 DML类型操作会有一些限制。
**例如:**如果表的物化视图Key中不包含删除语句中的条件列,则删除语句不能执行。如果想要删除渠道为APP端的数据,由于存在一个物化视图并不包含渠道这个字段,则这个删除不能执行,因为删除在物化视图中无法被执行。这时候你只能把物化视图先删除,然后删除完数据后,重新构建一个新的物化视图。 未来还会支持构建年表、月表,会用的到 to_mouth 和 to_day 函数。
更新策略
为保证物化视图表和 Base 表的数据一致性, Doris 会将导入,删除等对 base 表的操作都同步到物化视图表中。并且通过增量更新的方式来提升更新效率。通过事务方式来保证原子性。
比如如果用户通过 INSERT 命令插入数据到 base 表中,则这条数据会同步插入到物化视图中。当 base 表和物化视图表均写入成功后,INSERT 命令才会成功返回。
查询自动匹配
物化视图创建成功后,用户的查询不需要发生任何改变,也就是还是查询的 base 表。Doris 会根据当前查询的语句去自动选择一个最优的物化视图,从物化视图中读取数据并计算。
用户可以通过 EXPLAIN 命令来检查当前查询是否使用了物化视图。
物化视图中的聚合和查询中聚合的匹配关系:
查询物化视图
查看当前表都有哪些物化视图,以及他们的表结构都是什么样的。通过下面命令:
desc table all;
演示
创建物化视图
操作步骤
说明
1
首先你需要有一个Base表
CREATE TABLE sales_records**(**
id INT COMMENT “销售记录的id”,
seller_id INT COMMENT “销售员的id”,
store_id INT COMMENT “门店的id”,
sale_date DATE COMMENT “售卖时间”,
sale_amt BIGINT COMMENT “金额”
)
DISTRIBUTED BY HASH**(id)** BUCKETS 10**;**
2
基于这个Base表的数据提交一个创建物化视图的任务
CREATE MATERIALIZED VIEW mv_1 AS
SELECT seller_id**,sale_date,SUM(sale_amt)**
FROM sales_records
GROUP BY seller_id**,sale_date;**
提交完创建物化视图的任务后,Doris就会异步在后台生成物化视图的数据,构建物化视图。在构建期间,用户依然可以正常的查询和导入新的数据。创建任务会自动处理当前的存量数据和所有新到达的增量数据,从而保持和Base表的数据一致性。用户无需担心一致性问题。
3
查询物化视图
desc sales_records all;
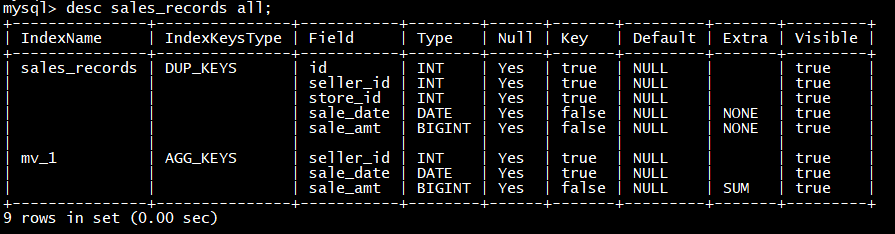
可以看到当前 sales_records表一共有一张物化视图:saller_amt,以及他们的表结构
查询物化视图

操作步骤
说明
1
基于这个Base表的数据再次提交两个创建物化视图的任务
CREATE MATERIALIZED VIEW mv_2 AS
SELECT store_id**,sale_date,SUM(sale_amt)**
FROM sales_records
GROUP BY store_id**,sale_date;**
CREATE MATERIALIZED VIEW mv_3 AS
SELECT seller_id**,SUM(sale_amt)**
FROM sales_records
GROUP BY seller_id**;**
3
查询物化视图
desc sales_records all;
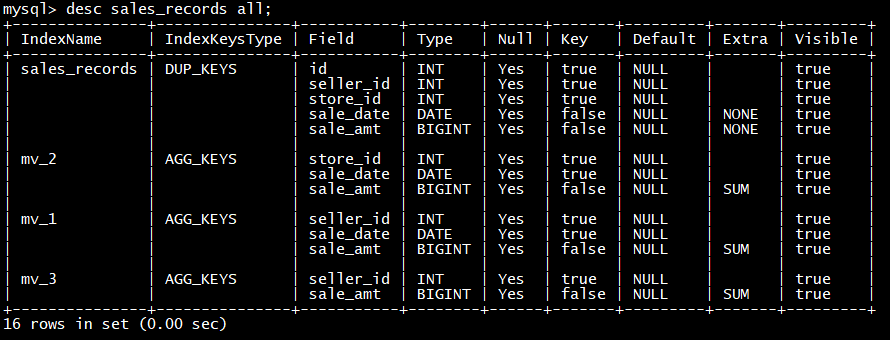
自动匹配

物化视图的自动匹配分为下面两个步骤:
- 根据查询条件筛选出一个最优的物化视图:这一步的输入是所有候选物化视图表的元数据,根据查询的条件从候选集中输出最优的一个物化视图
- 根据选出的物化视图对查询进行改写:这一步是结合上一步选择出的最优物化视图,进行查询的改写,最终达到直接查询物化视图的目的。
选择最优
下面详细解释一下第一步最优物化视图是被如何选择出来的。

这里分为两个步骤:
- 对候选集合进行一个过滤。只要是查询的结果能从物化视图数据计算(取部分行,部分列,或部分行列的聚合)出都可以留在候选集中,过滤完成后候选集合大小 >= 1。
- 从候选集合中根据聚合程度,索引等条件选出一个最优的也就是查询花费最少物化视图。
这里再举一个相对复杂的例子,来体现这个过程。

首先先说过滤候选集这个过程。
候选集过滤目前分为4层,每一层过滤后去除不满足条件的物化视图。
**例如:**查询2月10日各个销售员都买了多少钱。
- 首先候选集中包括所有的物化视图以及Base表共4个。
- 第一层过滤先判断查询Where中的谓词涉及到的数据是否能从物化视图中得到,也就是销售时间列是否在表中存在。由于第三个物化视图中根本不存在销售时间列。所以在这一层过滤中,mv_3就被淘汰了。
- 第二层是过滤查询的分组列是否为候选集的分组列的子集,也就是销售员id是否为表中分组列的子集。由于第二个物化视图中的分组列并不涉及销售员id。所以在这一层过滤中,mv_2也被淘汰了。
- 第三层过滤是看查询的聚合列是否为候选集中聚合列的子集,也就是对销售额求和是否能从候选集的表中聚合得出。这里Base表和物化视图表均满足标准。
- 最后一层是过滤看查询需要的列是否存在于候选集合的列中。由于候选集合中的表均满足标准,所以最终候选集合中的表为销售明细表,以及mv_1这两张。
候选集过滤完后输出一个集合,这个集合中的所有表都能满足查询的需求,但每张表的查询效率都不同。
这时候就需要在这个集合根据前缀索引是否能匹配到,以及聚合程度的高低来选出一个最优的物化视图。
**例如:**从表结构中可以看出,Base表的销售日期列是一个非排序列,而物化视图表的日期是一个排序列,同时聚合程度上mv_1表明显比Base表高。
所以最后选择出mv_1作为该查询的最优匹配。
查询改写
最后再根据选择出的最优解,改写查询。
例如:刚才的查询选中mv_1后,将查询改写为从mv_1中读取数据,过滤出日志为2月10日的mv_1中的数据然后返回即可。
有些情况下的查询改写还会涉及到查询中的聚合函数的改写。比如业务方经常会用到Count、Distinct对PV、UV进行计算。

例如:
广告点击明细记录表中存放哪个用户点击了什么广告,从什么渠道点击的,以及点击的时间。并且在这个Base表基础上构建了一个物化视图表,存储了不同广告不同渠道的用户Bitmap值。
由于bitmap_union这种聚合方式本身会对相同的用户user_id进行一个去重聚合。当用户查询广告在Web端的UV的时候,就可以匹配到这个物化视图。匹配到这个物化视图表后就需要对查询进行改写,将之前的对用户id求 count(distinct) 改为对物化视图中bitmap_union列求count。
所以最后查询取物化视图的第一和第三行求Bitmap聚合中有几个值。
适用场景
上面介绍了两种数据模型——明细模型和聚合模型,也介绍了两种预聚合方式物化视图和Rollup。那么在数据模型的选择上:
- 如果用户的分析都是固定维度的分析类查询,比如报表类业务,且完全不关心明细数据时,则用聚合模型最合适。
- 如果用户需要查询明细数据,比如交易明细,则用明细模型合适。
对于物化视图和Rollup来说:
- 他们的共同点都是通过预聚合的方式来提升查询效率。
实际上物化视图是Rollup的一个超集,在覆盖Rollup的工作同时,还支持更灵活的聚合方式。
因此,如果对数据的分析需求既覆盖了明细查询也存在分析类查询,则可以先创建一个明细模型的表,并构建物化视图。
动态分区
动态分区是在 Doris 0.12 版本中引入的新功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
目前实现了动态添加分区及动态删除分区的功能。
原理
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。
通过动态分区功能,用户可以在建表时设定动态分区的规则。FE 会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
使用方式
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则。
- 建表时指定:
CREATE TABLE tbl1
(…)
PROPERTIES
(
“dynamic_partition.prop1” = “value1”,
“dynamic_partition.prop2” = “value2”,
…
)
- 运行时修改
ALTER TABLE tbl1 SET
(
“dynamic_partition.prop1” = “value1”,
“dynamic_partition.prop2” = “value2”,
…
)
动态分区规则参数
在实现上,需要修改fe.conf配置文件,动态分区的规则参数都以 dynamic_partition. 为前缀:
- dynamic_partition.enable
是否开启动态分区特性。可指定为 TRUE 或 FALSE。如果不填写,默认为 TRUE。如果为 FALSE,则 Doris 会忽略该表的动态分区规则。
- dynamic_partition.time_unit
动态分区调度的单位。可指定为 HOUR、DAY、WEEK、MONTH。分别表示按天、按星期、按月进行分区创建或删除。
-
- 当指定为 HOUR 时,动态创建的分区名后缀格式为 yyyyMMddHH,例如2020032501。小时为单位的分区列数据类型不能为 DATE。
- 当指定为 DAY 时,动态创建的分区名后缀格式为 yyyyMMdd,例如20200325。
- 当指定为 WEEK 时,动态创建的分区名后缀格式为yyyy_ww。即当前日期属于这一年的第几周,例如 2020-03-25 创建的分区名后缀为 2020_13, 表明目前为2020年第13周。
- 当指定为 MONTH 时,动态创建的分区名后缀格式为 yyyyMM,例如 202003。
- dynamic_partition.time_zone
动态分区的时区,如果不填写,则默认为当前机器的系统的时区,例如 Asia/Shanghai,如果想获取当前支持的时区设置,可以参考 https://en.wikipedia.org/wiki/List_of_tz_database_time_zones。
- dynamic_partition.start
动态分区的起始偏移,为负数。根据 time_unit 属性的不同,以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。如果不填写,则默认为 -2147483648,即不删除历史分区。
- dynamic_partition.end
动态分区的结束偏移,为正数。根据 time_unit 属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区。
- dynamic_partition.prefix
动态创建的分区名前缀。
- dynamic_partition.buckets
动态创建的分区所对应的分桶数量。
- dynamic_partition.replication_num
动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量。
- dynamic_partition.start_day_of_week
当 time_unit 为 WEEK 时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点。
- dynamic_partition.start_day_of_month
当 time_unit 为 MONTH 时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月1号,28 表示每月28号。默认为 1,即表示每月以1号位起始点。暂不支持以29、30、31号为起始日,以避免因闰年或闰月带来的歧义。
注意事项
动态分区使用过程中,如果因为一些意外情况导致dynamic_partition.start和dynamic_partition.end 之间的某些分区丢失,那么当前时间与 dynamic_partition.end 之间的丢失分区会被重新创建,dynamic_partition.start与当前时间之间的丢失分区不会重新创建。
示例
- 表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近7天的分区,并且预先创建未来3天的分区。
操作步骤
说明
1
开启动态分区功能,可以在fe.conf中设置dynamic_partition.enable=true,也可以使用命令进行修改,使用命令修改,并dynamic_partition_check_interval_seconds调度时间设置为5秒,意思是每过5秒根据配置刷新分区,这里设置为5秒,真实场景可以设置为12小时
curl --location-trusted -u root:123456 -XGET http://node1:8030/api/_set_config?dynamic_partition_enable=true
curl --location-trusted -u root:123456 -XGET http://node1:8030/api/_set_config?dynamic_partition_check_interval_seconds=5
ADMIN SET FRONTEND CONFIG (“dynamic_partition_enable”=“true”);
ADMIN SET FRONTEND CONFIG (“dynamic_partition_check_interval_seconds”=“5”);

2
创建一张调度单位为天,可以删除历史分区的动态分区表
CREATE TABLE order_dynamic_partition1
(
id int,
time date,
money double,
areaName varchar(50)
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
DISTRIBUTED BY HASH**(id)** buckets 10
PROPERTIES**(**
“dynamic_partition.enable” = “true”,
“dynamic_partition.time_unit” = “DAY”,
“dynamic_partition.start” = “-7”,
“dynamic_partition.end” = “3”,
“dynamic_partition.prefix” = “p”,
“dynamic_partition.buckets” = “10”,
“replication_num” = “1”
);
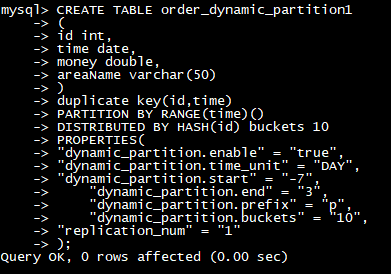
假设当前日期为 2021-02-15。则根据以上规则,tbl1 会产生以下分区:
p20210215: [“2021-02-15”, “2021-02-16”)
p20210216: [“2021-02-16”, “2021-02-17”)
p20210217: [“2021-02-17”, “2021-02-18”)
p20210218: [“2021-02-18”, “2021-02-19”)
在第二天,即 2021-02-16,会创建新的分区 p20200602: [“2021-02-19”, “2021-02-20”)
在 2021-02-23 时,因为 dynamic_partition.start 设置为 7,则将删除7天前的分区,即删除分区 p20210215。
3
查看分区表情况SHOW DYNAMIC PARTITIONS TABLES,更新最后调度时间
SHOW DYNAMIC PARTITION TABLES;

4
插入测试数据
insert into order_dynamic_partition1 values(1,‘2021-02-15 11:00:00’, 200.0**,** ‘北京’);
insert into order_dynamic_partition1 values(1,‘2021-02-16 11:00:00’, 200.0**,** ‘北京’);
insert into order_dynamic_partition1 values(1,‘2021-02-17 11:00:00’, 200.0**,** ‘北京’);

5
使用命令查看表下的所有分区:show partitions from order_dynamic_partition1;

- 表 tbl1 分区列 k1 类型为 DATETIME,创建一个动态分区规则。按星期分区,只保留最近2个星期的分区,并且预先创建未来2个星期的分区
操作步骤
说明
1
创建一张调度单位为周,保留最近两周的分区数据
CREATE TABLE order_dynamic_partition2
(
id int,
time date,
money double,
areaName varchar(50)
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
DISTRIBUTED BY HASH**(id)** buckets 10
PROPERTIES**(**
“dynamic_partition.enable” = “true”,
“dynamic_partition.time_unit” = “WEEK”,
“dynamic_partition.start” = “-2”,
“dynamic_partition.end” = “2”,
“dynamic_partition.prefix” = “p”,
“dynamic_partition.buckets” = “8”
);
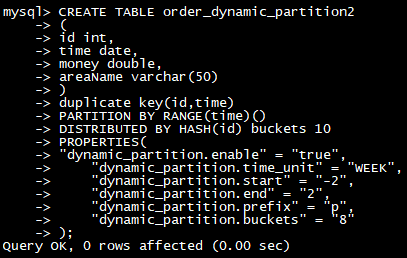
假设当前日期为 2020-05-29,是 2020 年的第 22 周。默认每周起始为星期一。则根于以上规则,tbl1 会产生以下分区:
p2020_22: [“2020-05-25 00:00:00”, “2020-06-01 00:00:00”)
p2020_23: [“2020-06-01 00:00:00”, “2020-06-08 00:00:00”)
p2020_24: [“2020-06-08 00:00:00”, “2020-06-15 00:00:00”)
其中每个分区的起始日期为当周的周一。同时,因为分区列 k1 的类型为 DATETIME,则分区值会补全时分秒部分,且皆为 0。
在 2020-06-15,即第25周时,会删除2周前的分区,即删除 p2020_22。
在上面的例子中,假设用户指定了周起始日为 “dynamic_partition.start_day_of_week” = “3”,即以每周三为起始日。则分区如下:
p2020_22: [“2020-05-27 00:00:00”, “2020-06-03 00:00:00”)
p2020_23: [“2020-06-03 00:00:00”, “2020-06-10 00:00:00”)
p2020_24: [“2020-06-10 00:00:00”, “2020-06-17 00:00:00”)
即分区范围为当周的周三到下周的周二。
注:2019-12-31 和 2020-01-01 在同一周内,如果分区的起始日期为 2019-12-31,则分区名为 p2019_53,如果分区的起始日期为 2020-01-01,则分区名为 p2020_01。
- 表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按月分区,不删除历史分区,并且预先创建未来2个月的分区。同时设定以每月3号为起始日。
操作步骤
说明
1
创建一张调度单位为月,不删除历史数据
CREATE TABLE order_dynamic_partition3
(
id int,
time date,
money double,
areaName varchar(50)
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
DISTRIBUTED BY HASH**(id)** buckets 10
PROPERTIES**(**
“dynamic_partition.enable” = “true”,
“dynamic_partition.time_unit” = “MONTH”,
“dynamic_partition.end” = “2”,
“dynamic_partition.prefix” = “p”,
“dynamic_partition.buckets” = “8”,
“dynamic_partition.start_day_of_month” = “3”
);
假设当前日期为 2020-05-29。则根于以上规则,tbl1 会产生以下分区:
p202005: [“2020-05-03”, “2020-06-03”)
p202006: [“2020-06-03”, “2020-07-03”)
p202007: [“2020-07-03”, “2020-08-03”)
因为没有设置 dynamic_partition.start,则不会删除历史分区。
假设今天为 2020-05-20,并设置以每月28号为起始日,则分区范围为:
p202004: [“2020-04-28”, “2020-05-28”)
p202005: [“2020-05-28”, “2020-06-28”)
p202006: [“2020-06-28”, “2020-07-28”)
查看动态分区表调度情况
通过以下命令可以进一步查看当前数据库下,所有动态分区表的调度情况:
SHOW DYNAMIC PARTITION TABLES;

LastUpdateTime: 最后一次修改动态分区属性的时间
LastSchedulerTime: 最后一次执行动态分区调度的时间
State: 最后一次执行动态分区调度的状态
LastCreatePartitionMsg: 最后一次执行动态添加分区调度的错误信息
LastDropPartitionMsg: 最后一次执行动态删除分区调度的错误信息
数据导出
数据导出(Export)是 Doris 提供的一种将数据导出的功能。该功能可以将用户指定的表或分区的数据,以文本的格式,通过 Broker 进程导出到远端存储上,如 HDFS/BOS 等。
使用示例
Export 的详细命令可以通过 HELP EXPORT; 。举例如下:
EXPORT TABLE db1**.**tbl1
PARTITION (p1,p2)
TO “hdfs://host/path/to/export/”
PROPERTIES
(
“column_separator”=",",
“exec_mem_limit”=“2147483648”,
“timeout” = “3600”
)
WITH BROKER “hdfs”
(
“username” = “user”,
“password” = “passwd”,
);
column_separator
列分隔符。默认为 \t
line_delimiter
行分隔符。默认为 \n
exec_mem_limit
表示 Export 作业中,一个查询计划在单个 BE 上的内存使用限制。默认 2GB。单位字节
timeout
作业超时时间。默认 2小时。单位秒
tablet_num_per_task
每个查询计划分配的最大分片数。默认为 5
提交作业后,可以通过 SHOW EXPORT 命令查询导入作业状态。结果举例如下:
JobId**😗* 14008
State: FINISHED
Progress**😗* 100**%**
TaskInfo**😗* {“partitions”:["*"],“exec mem limit”:2147483648,“column separator”:",",“line delimiter”:"\n",“tablet num”:1,“broker”:“hdfs”,“coord num”:1,“db”:“default_cluster:db1”,“tbl”:“tbl3”}
Path: bos**😕/bj-test-cmy/export/**
CreateTime**😗* 2019**-06-25 17:08😗*24
StartTime**😗* 2019**-06-25 17:08😗*28
FinishTime**😗* 2019**-06-25 17:08😗*34
Timeout**😗* 3600
ErrorMsg**😗* N**/**A
JobId
作业的唯一 ID
State
作业状态
PENDING:作业待调度
EXPORTING:数据导出中
FINISHED:作业成功
CANCELLED:作业失败
Progress
作业进度。该进度以查询计划为单位。假设一共 10 个查询计划,当前已完成 3 个,则进度为 30%。
TaskInfo
以 Json 格式展示的作业信息:
db:数据库名
tbl:表名
partitions:指定导出的分区。* 表示所有分区。
exec mem limit:查询计划内存使用限制。单位字节。
column separator:导出文件的列分隔符。
line delimiter:导出文件的行分隔符。
tablet num:涉及的总 Tablet 数量。
broker:使用的 broker 的名称。
coord num:查询计划的个数。
Path
远端存储上的导出路径
CreateTime
StartTime
FinishTime
作业的创建时间、开始调度时间和结束时间
Timeout
作业超时时间。单位是秒。该时间从 CreateTime 开始计算
ErrorMsg
如果作业出现错误,这里会显示错误原因
案例演示
操作步骤
说明
1
查询site_visit表数据,将site_visit表的数据导入到hdfs中
select * from site_visit**;**

2
执行导出作业
EXPORT TABLE test_db**.**site_visit
TO “hdfs://node1:8020/datas/output”
WITH BROKER “broker_name” (
“username”=“root”,
“password”=“123456”
);
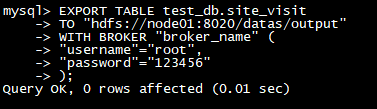
3
查看导出作业
其他导出案例参考
- 将testTbl表中的分区p1,p2导出到hdfs上,broker使用kerberos 认证方式,同时配置 namenode HA
EXPORT TABLE testTbl
PARTITION (p20200101)
TO “hdfs://my_cluster/user/platform/miuiads/stat_event_cube_bak2017/date=20200101”
WITH BROKER “broker1”(
“hadoop.security.authentication”=“kerberos”,
“kerberos_principal”="",
“kerberos_keytab”="",
“dfs.nameservices”=“my_cluster”,
“dfs.ha.namenodes.my_cluster”=“nn1,nn2”,
“dfs.namenode.rpc-address.my_cluster.nn1”=“node1:8020”,
“dfs.namenode.rpc-address.my_cluster.nn2”=“node2:8020”,
“dfs.client.failover.proxy.provider”=“org.apache.hadoop.hdfs.server.namenode.ha.ZkConfiguredFailoverProxyProvider”
);
- 将testTbl表中的所有数据导出到hdfs上,以","作为列分隔符
EXPORT TABLE testTbl
TO “hdfs://hdfs_host:port/a/b/c”
PROPERTIES (“column_separator”=",")
WITH BROKER “broker_name” (
“username”=“xxx”,
“password”=“yyy”
);
注意事项
- 不建议一次性导出大量数据,一个 Export 作业建议的导出数据量最大在几十 GB,过大的导出会导致更多的垃圾文件和更高的重试成本,如果表数据量过大,建议按照分区导出。
- 如果 Export 作业运行失败,在远端存储中产生的临时目录tmp,以及已经生成的文件不会被删除,需要用户手动删除。
- 如果 Export 作业运行成功,在远端存储中产生的tmp目录,根据远端存储的文件系统语义,可能会保留,也可能会被清除,如果该目录没有被清除,需要手动清除。
- Export 作业只会导出 Base 表的数据,不会导出 Rollup Index 的数据。
- Export 作业会扫描数据,占用 IO 资源,可能会影响系统的查询延迟。
Colocation Join
Colocation Join 是在 Doris 0.9 版本中引入的新功能。旨在为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,加速查询。
原理
Colocation Join 功能,是将一组拥有相同 CGS 的 Table 组成一个 CG。并保证这些 Table 对应的数据分片会落在同一个 BE 节点上。使得当 CG 内的表进行分桶列上的 Join 操作时,可以通过直接进行本地数据 Join,减少数据在节点间的传输耗时。
一个表的数据,最终会根据分桶列值 Hash、对桶数取模的后落在某一个分桶内。假设一个 Table 的分桶数为 8,则共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 个分桶(Bucket),我们称这样一个序列为一个 BucketsSequence。每个 Bucket 内会有一个或多个数据分片(Tablet)。当表为单分区表时,一个 Bucket 内仅有一个 Tablet。如果是多分区表,则会有多个。
使用限制:
- 建表时两张表的分桶列和数量需要完全一致,并且桶的个数也需要一致
- 副本数,两张表的所有分区和副本数需要一致
使用方式
建表
建表时,可以在 PROPERTIES 中指定属性 “colocate_with” = “group_name”,表示这个表是一个 Colocation Join 表,并且归属于一个指定的 Colocation Group。
示例:
CREATE TABLE tbl **(**k1 int, v1 int sum)
DISTRIBUTED BY HASH**(k1)**
BUCKETS 8
PROPERTIES**(**
“colocate_with” = “group1”
);
如果指定的 Group 不存在,则 Doris 会自动创建一个只包含当前这张表的 Group。
如果 Group 已存在,则 Doris 会检查当前表是否满足 Colocation Group Schema。
如果满足,则会创建该表,并将该表加入 Group。同时,表会根据已存在的 Group 中的数据分布规则创建分片和副本。
Group 归属于一个 Database,Group 的名字在一个 Database 内唯一。在内部存储是 Group 的全名为 dbId_groupName,但用户只感知 groupName。
删表
当 Group 中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过 DROP TABLE 命令删除后,会在回收站默认停留一天的时间后,再删除),该 Group 也会被自动删除
查看 Group
SHOW PROC ‘/colocation_group’;

GroupId: 一个 Group 的全集群唯一标识,前半部分为 db id,后半部分为 group id。
GroupName: Group 的全名。
TabletIds: 该 Group 包含的 Table 的 id 列表。
BucketsNum: 分桶数。
ReplicationNum: 副本数。
DistCols: Distribution columns,即分桶列类型。
IsStable: 该 Group 是否稳定(稳定的定义,见 Colocation 副本均衡和修复 一节)。
通过以下命令可以进一步查看一个 Group 的数据分布情况:
BucketIndex: 分桶序列的下标。
BackendIds: 分桶中数据分片所在的 BE 节点 id 列表。
以上命令需要 ADMIN 权限。暂不支持普通用户查看。
修改表 Colocate Group 属性
可以对一个已经创建的表,修改其 Colocation Group 属性。示例:
ALTER TABLE tbl SET (“colocate_with” = “group2”);
- 如果该表之前没有指定过 Group,则该命令检查 Schema,并将该表加入到该 Group(Group 不存在则会创建)。
- 如果该表之前有指定其他 Group,则该命令会先将该表从原有 Group 中移除,并加入新 Group(Group 不存在则会创建)。
也可以通过以下命令,删除一个表的 Colocation 属性:
ALTER TABLE tbl SET (“colocate_with” = “”);
其他相关操作
当对一个具有 Colocation 属性的表进行增加分区(ADD PARTITION)、修改副本数时,Doris 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝
演示
对 Colocation 表的查询方式和普通表一样,用户无需感知 Colocation 属性。
如果 Colocation 表所在的 Group 处于 Unstable 状态,将自动退化为普通 Join。
- 创建表1:
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT “”,
`k2` int(11) NOT NULL COMMENT “”,
`v1` int(11) SUM NOT NULL COMMENT “”
) ENGINE**=**OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN (‘2019-05-31’),
PARTITION p2 VALUES LESS THAN (‘2019-06-30’)
)
DISTRIBUTED BY HASH**(`k2`)** BUCKETS 8
PROPERTIES (
“colocate_with” = “group1”
);
- 创建表2:
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT “”,
`k2` int(11) NOT NULL COMMENT “”,
`v1` double SUM NOT NULL COMMENT “”
) ENGINE**=**OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH**(`k2`)** BUCKETS 8
PROPERTIES (
“colocate_with” = “group1”
);
- 查看查询计划:
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);
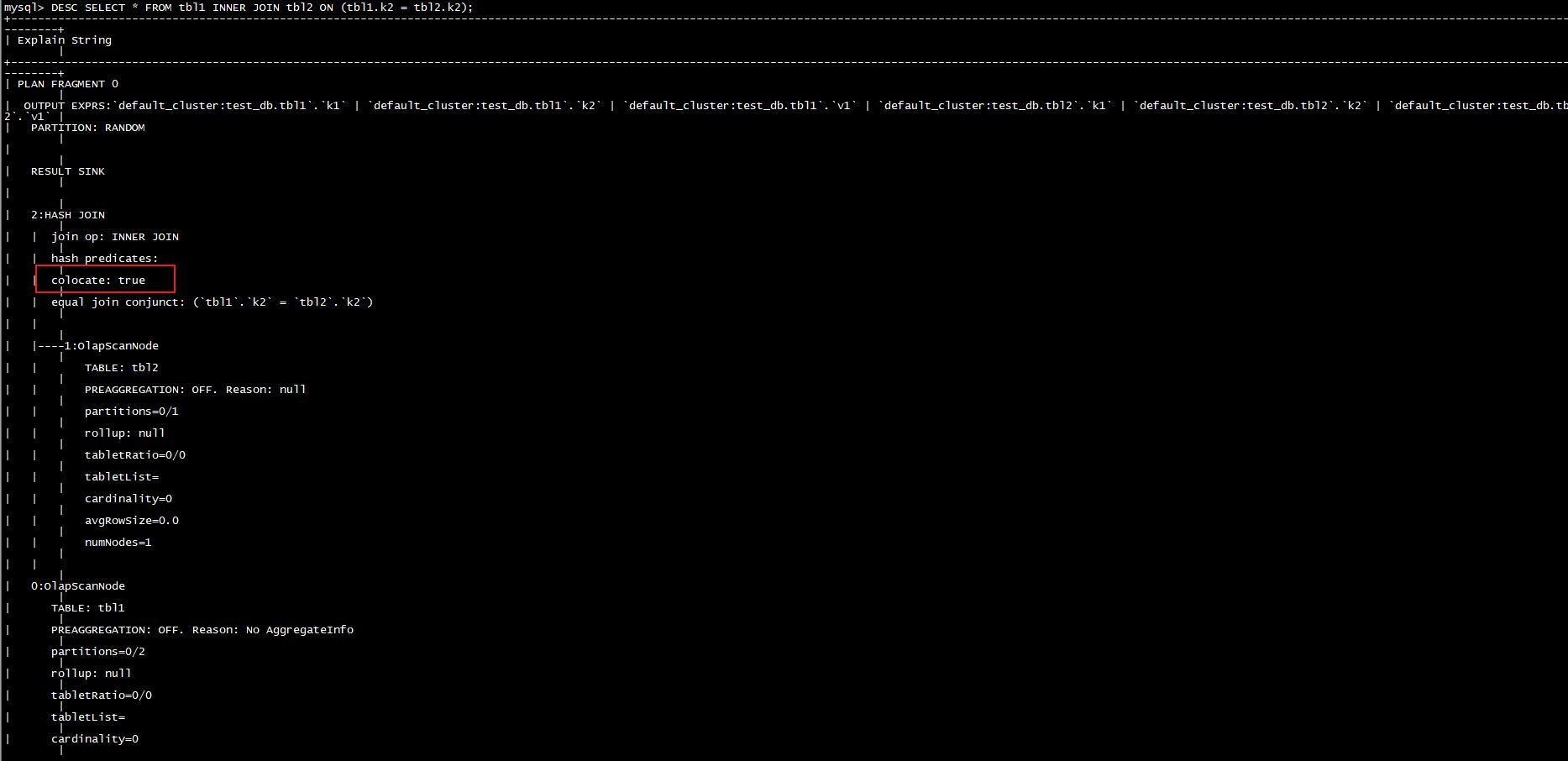
如果 Colocation Join 生效,则 Hash Join 节点会显示 colocate: true。
如果 Colocation Join 生效,则 Hash Join 节点会显示 colocate: true。
SQL函数
- 查看函数名:
show builtin functions in test_db**;**
数学函数
abs(double a)
功能: 返回参数的绝对值
返回类型:double类型
使用说明:使用该函数需要确保函数的返回值是整数。
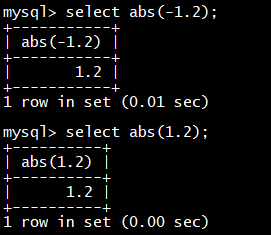
acos(double a)
功能: 返回参数的反余弦值
返回类型:double类型
MySQL 中反余弦函数 ACOS(x) 。x 值的范围必须在 -1 和 1 之间,否则返回 NULL。
SELECT ACOS(2),ACOS(1),ACOS(-1**);**
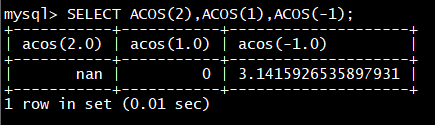
asin(double a)
功能: 返回参数的反正弦值
返回类型:double类型
使用 ASIN 函数计算反正弦值,输入的 SQL 语句和执行结果如下所示。
SELECT ASIN(0.8414709848078965),ASIN(2);
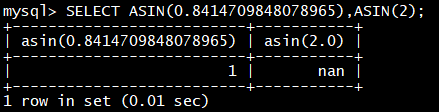
atan(double a)
功能: 返回参数的反正切值
返回类型:double类型
SELECT ATAN(1);
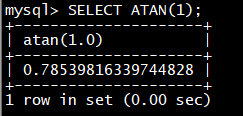
bin(bigint a)
功能: 返回整型的二进制表示形式(即0 和1 序列)
返回类型:string类型
select bin(10);
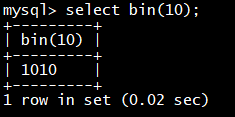
ceil(double a)/ceiling(double a)/dceil(double a)
功能: 返回大于等于该参数的最小整数
返回类型:int类型
SELECT CEILING(3.46);
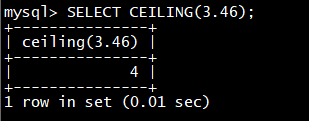
conv(bigint num, int from_base, int to_base)
功能:进制转换函数,返回某个整数在特定进制下的的字符串形式。输入参数可以是整型的字符串形式。如果想要将函数的返回值转换成整数,可以使用CAST函数。
返回类型:string类型
select conv(64,10,8);
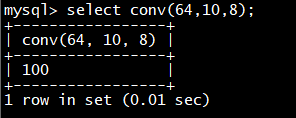
select cast(conv(‘fe’, 16**,** 10**)** as int) as “transform_string_to_int”;

cos(double a)
功能:返回参数的余弦值
返回类型:double类型
SELECT COS(1),COS(0),COS(PI());
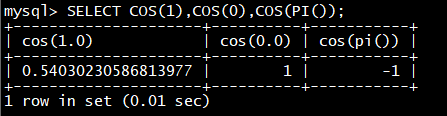
degrees(double a)
功能:将弧度转成角度
返回类型:double类型
SELECT DEGREES(PI());
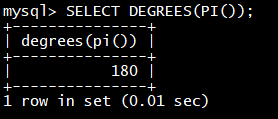
e()
功能:返回数学上的常量e
返回类型:double类型
select e**();**
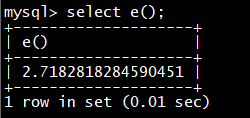
exp(double a)/dexp(double a)
功能: 返回e 的a 次幂(即ea)
返回类型: double 类型
SELECT EXP(3);
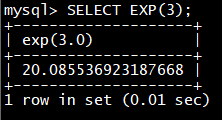
floor(double a)/dfloor(double a)
功能:返回小于等于该参数的最大整数
返回类型:int类型
SELECT FLOOR(5),FLOOR(5.66),FLOOR(-4**),FLOOR(-4.66);**
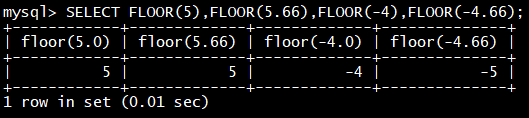
fmod(double a, double b)/fmod(float a, float b)
功能:返回a除以b的余数。等价于%算术符
返回类型:float或者double类型
select fmod**(10,3);**
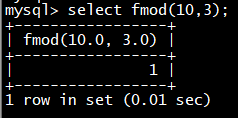
select fmod**(5.5,2);**
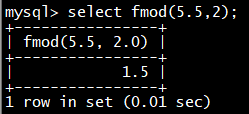
greatest(bigint a[, bigint b …])
功能:返回列表里的最大值
返回类型:和参数类型相同
SELECT GREATEST(3,5,1,8,33,99,34,55,67,43);
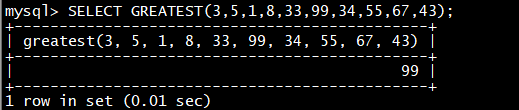
hex(bigint a)/hex(string a)
功能:返回整型或字符串中各个字符的16进制表示形式。
返回类型:string类型
select hex(‘abc’);
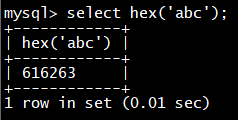
select unhex**(616263);**
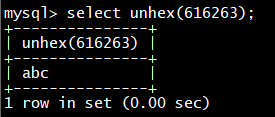
least(bigint a[, bigint b …])
功能:返回列表里的最小值
返回类型:和参数类型相同
SELECT LEAST(1, 5**,** 9**)** AS ‘Result’;
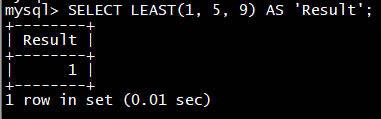
ln(double a)/dlog1(double a)
功能:返回参数的自然对数形式
返回类型:double类型
SELECT In(2);
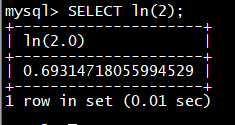
log(double base, double a)
功能:返回log以base为底数,以a为指数的对数值。
返回类型:double类型
select log(2, 3**);**
select log(2, 4**);**
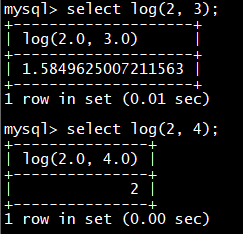
log10(double a)/dlog10(double a)
功能:返回log以10为底数,以a为指数的对数值。
返回类型:double类型
SELECT LOG10(100);
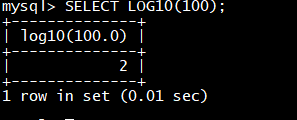
log2(double a)
功能:返回log以2为底数,以a为指数的对数值。
返回类型:double类型
SELECT log2**(100);**
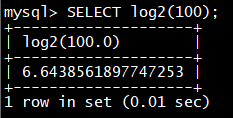
mod(numeric_type a, same_type b)
功能:返回a除以b的余数。等价于%算术符。
返回类型:和输入类型相同
select mod(10,3);
select mod(5.5,2);
negative(int a)/negative(double a)
功能:将参数a的符号位取反,如果参数是负值,则返回正值
返回类型:根据输入参数类型返回int类型或double类型
使用说明:如果你需要确保所有返回值都是负值,可以使用-abs(a)函数。
select negative(2);
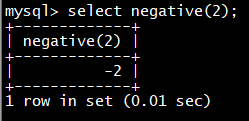
pi()
功能:返回常量Pi
返回类型: double类型
select pi();
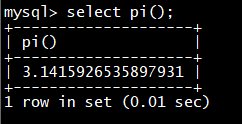
pmod(int a, int b)/pmod(double a, double b)
功能:正取余函数
返回类型:int类型或者double类型(由输入参数决定)
SELECT MOD(29,3);
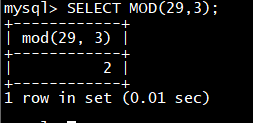
pow(double a, double p)/power(double a, double p)
功能:返回a的p次幂
返回类型:double类型
select pow(2,3);
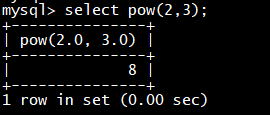
positive(int a)
功能:返回参数的原值,即使参数是负的,仍然返回原值。
返回类型:int类型
使用说明:如果你需要确保所有返回值都是正值,可以使用abs()函数。
select positive(2);
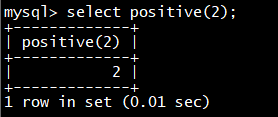
radians(double a)
功能:将弧度转换成角度
返回类型:double类型
这个函数返回a的弧度值,从度转换为弧度。
select radians(2);
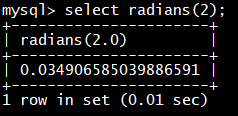
rand()/rand(int seed)/random()/random(int seed)
功能:返回0~1之间的随机值。参数为随机种子。
返回类型:double
使用说明:每次查询的随机序列都会重置,多次调用rand 函数会产生相同的结果。如果每次查询想产生不同的结果,可以在每次查询时使用不同的随机种子。例如select rand(unix_timestamp()) from …
SELECT RAND(1), RAND( ), RAND( );

round(double a)/round(double a, int d)
功能: 取整函数。如果只带一个参数,该函数会返回距离该值最近的整数。如果带2个参数,第二个参数为小数点后面保留的位数。
返回类型:如果参数是浮点类型则返回bigint。如果第二个参数大于1,则返回double类型。
select round(100.456, 2**);**
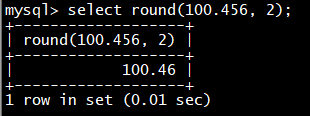
sign(double a)
功能:如果a是整数或者0,返回1;如果a是负数,则返回-1
返回类型:int类型
select sign(3.0);
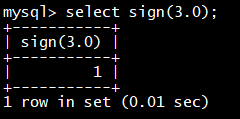
sin(double a)
功能:返回a的正弦值
返回类型:double类型
select sin(2);
sqrt(double a)
功能:返回a的平方根
返回类型:double类型
select sqrt(2);
tan(double a)
功能:返回a的正切值
返回类型:double类型
select tan(1.2);
unhex(string a)
功能:把十六进制格式的字符串转化为原来的格式
返回类型:string类型
select hex(‘abc’);
select unhex**(616263);**
日期函数
CONVERT_TZ(DATETIME dt, VARCHAR from_tz, VARCHAR to_tz)
转换datetime值dt,从 from_tz 由给定转到 to_tz 时区给出的时区,并返回的结果值。 如果参数无效该函数返回NULL。
select convert_tz**(‘2019-08-01 13:21:03’,** ‘Asia/Shanghai’, ‘America/Los_Angeles’);

select convert_tz**(‘2019-08-01 13:21:03’,** ‘+08:00’, ‘America/Los_Angeles’);

CURDATE()
获取当前的日期,以DATE类型返回
SELECT CURDATE**();**
SELECT CURDATE**()** + 0**;**
CURRENT_TIMESTAMP()
获得当前的时间,以Datetime类型返回
select current_timestamp();
current_time()
获得当前的时间,以TIME类型返回
select current_time();
DATE_ADD(DATETIME date,INTERVAL expr type)
向日期添加指定的时间间隔。
date 参数是合法的日期表达式。
expr 参数是您希望添加的时间间隔。
type 参数可以是下列值:YEAR, MONTH, DAY, HOUR, MINUTE, SECOND
select date_add(‘2020-11-30 23:59:59’, INTERVAL 2 DAY);
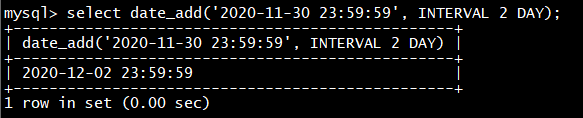
DATE_FORMAT(DATETIME date, VARCHAR format)
将日期类型按照format的类型转化为字符串, 当前支持最大128字节的字符串,如果返回值长度超过128,则返回NULL
date 参数是合法的日期。format 规定日期/时间的输出格式。
可以使用的格式有:
%a | 缩写星期名
%b | 缩写月名
%c | 月,数值
%D | 带有英文前缀的月中的天
%d | 月的天,数值(00-31)
%e | 月的天,数值(0-31)
%f | 微秒
%H | 小时 (00-23)
%h | 小时 (01-12)
%I | 小时 (01-12)
%i | 分钟,数值(00-59)
%j | 年的天 (001-366)
%k | 小时 (0-23)
%l | 小时 (1-12)
%M | 月名
%m | 月,数值(00-12)
%p | AM 或 PM
%r | 时间,12-小时(hh:mm:ss AM 或 PM)
%S | 秒(00-59)
%s | 秒(00-59)
%T | 时间, 24-小时 (hh:mm:ss)
%U | 周 (00-53) 星期日是一周的第一天
%u | 周 (00-53) 星期一是一周的第一天
%V | 周 (01-53) 星期日是一周的第一天,与 %X 使用
%v | 周 (01-53) 星期一是一周的第一天,与 %x 使用
%W | 星期名
%w | 周的天 (0=星期日, 6=星期六)
%X | 年,其中的星期日是周的第一天,4 位,与 %V 使用
%x | 年,其中的星期一是周的第一天,4 位,与 %v 使用
%Y | 年,4 位
%y | 年,2 位
%% | 用于表示 %
select date_format(‘2020-10-04 22:23:00’, ‘%W %M %Y’);
select date_format(‘2020-10-04 22:23:00’, ‘%H:%i:%s’);
select date_format(‘2020-10-04 22:23:00’, ‘%D %y %a %d %m %b %j’);
select date_format(‘2020-10-04 22:23:00’, ‘%H %k %I %r %T %S %w’);
select date_format(‘2020-01-01 00:00:00’, ‘%X %V’);
select date_format(‘2020-06-01’, ‘%d’);
select date_format(‘2020-06-01’, ‘%%%d’);
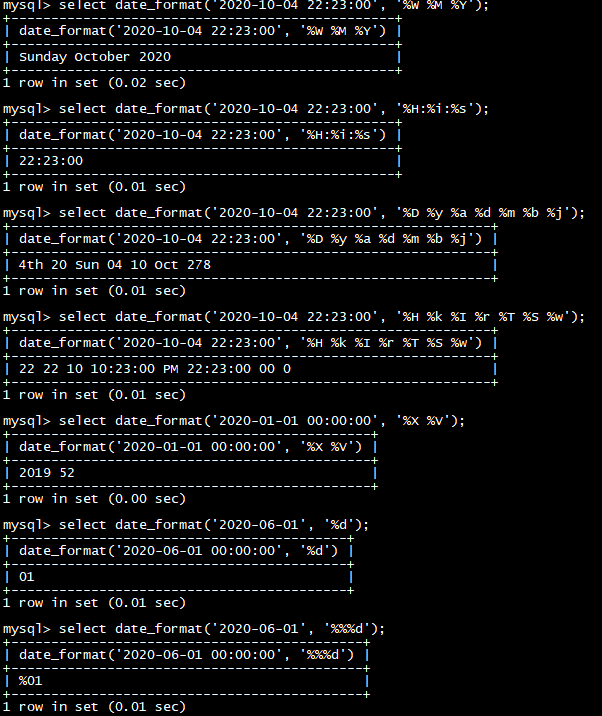
DATE_SUB(DATETIME date,INTERVAL expr type)
从日期减去指定的时间间隔
date 参数是合法的日期表达式。
expr 参数是您希望添加的时间间隔。
type 参数可以是下列值:YEAR, MONTH, DAY, HOUR, MINUTE, SECOND
select date_sub(‘2010-11-30 23:59:59’, INTERVAL 2 DAY);
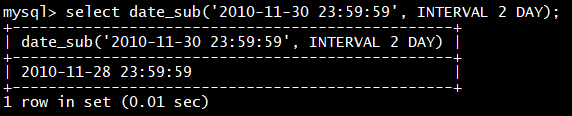
DATEDIFF(DATETIME expr1,DATETIME expr2)
计算expr1 - expr2,结果精确到天。
expr1 和 expr2 参数是合法的日期或日期/时间表达式。
注释:只有值的日期部分参与计算。
select datediff(CAST(‘2020-12-31 23:59:59’ AS DATETIME), CAST(‘2020-12-30’ AS DATETIME));

select datediff(CAST(‘2020-11-30 23:59:59’ AS DATETIME), CAST(‘2020-12-31’ AS DATETIME));

DAY(DATETIME date)
获得日期中的天信息,返回值范围从1-31。
参数为Date或者Datetime类型
select day(‘2020-01-31’);
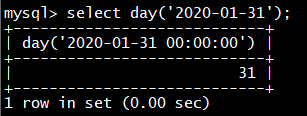
DAYNAME(DATE)
返回日期对应的日期名字
参数为Date或者Datetime类型
select dayname**(‘2020-02-03 00:00:00’);**
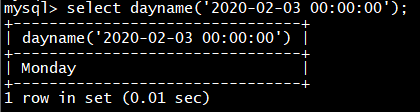
DAYOFMONTH(DATETIME date)
获得日期中的天信息,返回值范围从1-31。
参数为Date或者Datetime类型
select dayofmonth**(‘2020-01-31’);**
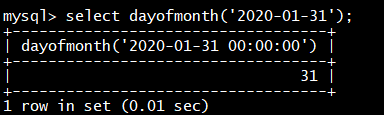
dayofweek(DATETIME date)
DAYOFWEEK函数返回日期的工作日索引值,即星期日为1,星期一为2,星期六为7
参数为Date或者Datetime类型或者可以cast为Date或者Datetime类型的数字
select dayofweek**(‘2020-06-25’);**
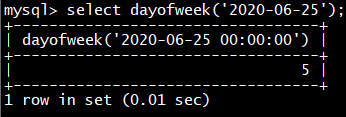
select dayofweek**(cast(**20190620 as date));
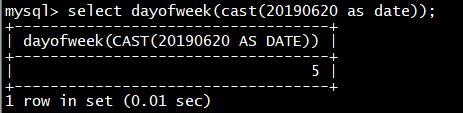
DAYOFYEAR(DATETIME date)
获得日期中对应当年中的哪一天。
参数为Date或者Datetime类型
select dayofyear**(‘2020-02-03 00:00:00’);**
FROM_DAYS(INT N)
通过距离0000-01-01日的天数计算出哪一天
select from_days(730669);
FROM_UNIXTIME(INT unix_timestamp[, VARCHAR string_format])
将 unix 时间戳转化为对应的 time 格式,返回的格式由 string_format 指定
默认为 yyyy-MM-dd HH:mm:ss ,也支持date_format中的format格式
传入的是整形,返回的是字符串类型
目前 string_format 支持格式:
%Y:年。例:2014,1900
%m:月。例:12,09
%d:日。例:11,01
%H:时。例:23,01,12
%i:分。例:05,11
%s:秒。例:59,01
其余 string_format 格式是非法的,返回NULL
如果给定的时间戳小于 0 或大于 253402271999,则返回 NULL。即时间戳范围是:
1970-01-01 00:00:00 ~ 9999-12-31 23:59:59
select from_unixtime**(1196440219);**
select from_unixtime**(1196440219,** ‘yyyy-MM-dd HH:mm:ss’);
select from_unixtime**(1196440219,** ‘%Y-%m-%d’);
select from_unixtime**(1196440219,** ‘%Y-%m-%d %H:%i:%s’);
HOUR(DATETIME date)
获得日期中的小时的信息,返回值范围从0-23。
参数为Date或者Datetime类型
select hour(‘2018-12-31 23:59:59’);
MINUTE(DATETIME date)
获得日期中的分钟的信息,返回值范围从0-59。
参数为Date或者Datetime类型
select minute(‘2018-12-31 23:59:59’);
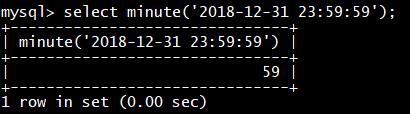
MONTH(DATETIME date)
返回时间类型中的月份信息,范围是1, 12
参数为Date或者Datetime类型
select month(‘1987-01-01’);
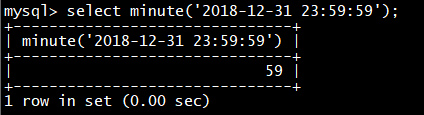
MONTHNAME(DATE)
返回日期对应的月份名字
参数为Date或者Datetime类型
select monthname**(‘2008-02-03 00:00:00’);**
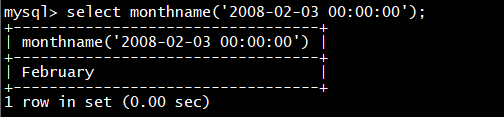
NOW()
获得当前的时间,以Datetime类型返回
select now**();**
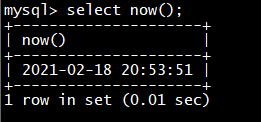
SECOND(DATETIME date)
获得日期中的秒的信息,返回值范围从0-59。
参数为Date或者Datetime类型
select second(‘2018-12-31 23:59:59’);
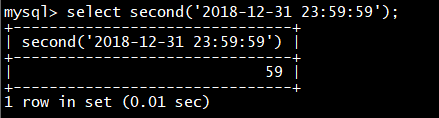
STR_TO_DATE(VARCHAR str, VARCHAR format)
通过format指定的方式将str转化为DATE类型,如果转化结果不对返回NULL
支持的format格式与date_format一致
select str_to_date**(‘2020-12-21 12:34:56’,** ‘%Y-%m-%d %H:%i:%s’);
select str_to_date**(‘2020-12-21 12:34%3A56’,** ‘%Y-%m-%d %H:%i%%3A%s’);
select str_to_date**(‘202042 Monday’,** ‘%X%V %W’);
select str_to_date**(“2020-09-01”,** “%Y-%m-%d %H:%i:%s”);
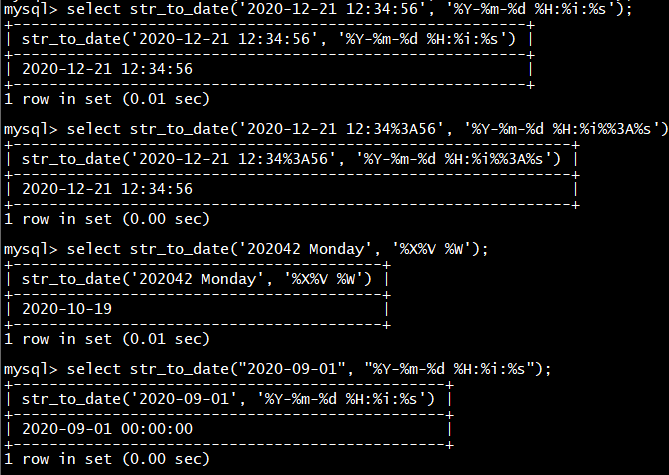
TIMEDIFF(DATETIME expr1, DATETIME expr2)
TIMEDIFF返回两个DATETIME之间的差值
TIMEDIFF函数返回表示为时间值的expr1 - expr2的结果,返回值为TIME类型
SELECT TIMEDIFF**(now(),utc_timestamp());**
SELECT TIMEDIFF**(‘2020-07-11 16:59:30’,‘2019-07-11 16:59:21’);**
SELECT TIMEDIFF**(‘2020-01-01 00:00:00’,** NULL);
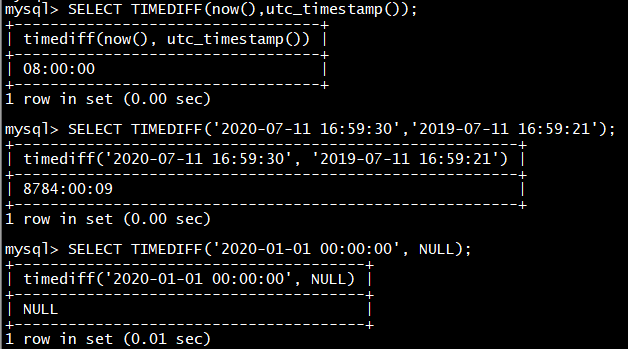
TIMESTAMPADD(unit, interval, DATETIME datetime_expr)
将整数表达式间隔添加到日期或日期时间表达式datetime_expr中。
interval的单位由unit参数给出,它应该是下列值之一:
SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, or YEAR。
SELECT TIMESTAMPADD**(MINUTE,1,‘2020-01-02’);**
SELECT TIMESTAMPADD**(WEEK,1,‘2020-01-02’);**
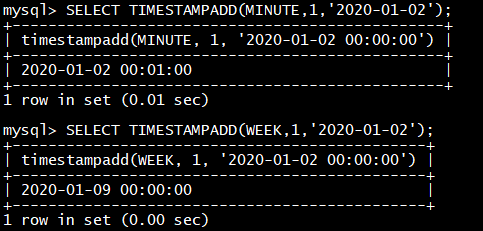
TIMESTAMPDIFF(unit,DATETIME datetime_expr1, DATETIME datetime_expr2)
返回datetime_expr2−datetime_expr1,其中datetime_expr1和datetime_expr2是日期或日期时间表达式。
结果(整数)的单位由unit参数给出。interval的单位由unit参数给出,它应该是下列值之一:
SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, or YEAR
SELECT TIMESTAMPDIFF**(MONTH,‘2003-02-01’,‘2003-05-01’);**
SELECT TIMESTAMPDIFF**(YEAR,‘2002-05-01’,‘2001-01-01’);**
SELECT TIMESTAMPDIFF**(MINUTE,‘2003-02-01’,‘2003-05-01 12:05:55’);**
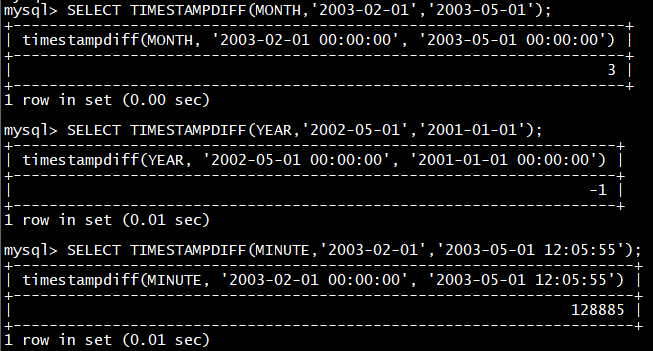
TO_DAYS(DATETIME date)
返回date距离0000-01-01的天数
参数为Date或者Datetime类型
select to_days(‘2007-10-07’);
UNIX_TIMESTAMP()
将 Date 或者 Datetime 类型转化为 unix 时间戳。
如果没有参数,则是将当前的时间转化为时间戳。
参数需要是 Date 或者 Datetime 类型。
对于在 1970-01-01 00:00:00 之前或 2038-01-19 03:14:07 之后的时间,该函数将返回 0。
Format 的格式请参阅 date_format 函数的格式说明。
该函数受时区影响。
select unix_timestamp**();**
select unix_timestamp**(‘2007-11-30 10:30:19’);**
select unix_timestamp**(‘2007-11-30 10:30-19’,** ‘%Y-%m-%d %H:%i-%s’);
select unix_timestamp**(‘2007-11-30 10:30%3A19’,** ‘%Y-%m-%d %H:%i%%3A%s’);
select unix_timestamp**(‘1969-01-01 00:00:00’);**
UTC_TIMESTAMP()
返回当前UTC日期和时间在 “YYYY-MM-DD HH:MM:SS” 或
"YYYYMMDDHHMMSS"格式的一个值
根据该函数是否用在字符串或数字语境中
select utc_timestamp**(),utc_timestamp()** + 1**;**
WEEKOFYEAR(DATETIME date)
获得一年中的第几周
参数为Date或者Datetime类型
select utc_timestamp**(),utc_timestamp()** + 1**;**
YEAR(DATETIME date)
返回date类型的year部分,范围从1000-9999
参数为Date或者Datetime类型
select year(‘1987-01-01’);
地理位置函数
ST_AsText(GEOMETRY geo)
将一个几何图形转化为WKT(Well Known Text)的表示形式
SELECT ST_AsText**(ST_Point(24.7,** 56.7**));**
ST_Circle(DOUBLE center_lng, DOUBLE center_lat, DOUBLE radius)
将一个WKT(Well Known Text)转化为地球球面上的一个圆。其中center_lng表示的圆心的经度, center_lat表示的是圆心的纬度,radius表示的是圆的半径,单位是米,最大支持99999994
SELECT ST_AsText**(ST_Circle(111,** 64**,** 10000**));**
ST_Contains(GEOMETRY shape1, GEOMETRY shape2)
判断几何图形shape1是否完全能够包含几何图形shape2
SELECT ST_Contains**(ST_Polygon(“POLYGON ((0 0, 10 0, 10 10, 0 10, 0 0))”),** ST_Point**(5,** 5**));**

SELECT ST_Contains**(ST_Polygon(“POLYGON ((0 0, 10 0, 10 10, 0 10, 0 0))”),** ST_Point**(50,** 50**));**

ST_Distance_Sphere(DOUBLE x_lng, DOUBLE x_lat, DOUBLE y_lng, DOUBLE x_lat)
计算地球两点之间的球面距离,单位为 米。传入的参数分别为X点的经度,X点的纬度,Y点的经度,Y点的纬度。
select st_distance_sphere**(116.35620117,** 39.939093**,** 116.4274406433**,** 39.9020987219**);**

ST_GeometryFromText(VARCHAR wkt)
将一个WKT(Well Known Text)转化为对应的内存的几何形式
SELECT ST_AsText**(ST_GeometryFromText(“LINESTRING (1 1, 2 2)”));**

ST_LineFromText(VARCHAR wkt)
将一个WKT(Well Known Text)转化为一个Line形式的内存表现形式
SELECT ST_AsText**(ST_LineFromText(“LINESTRING (1 1, 2 2)”));**

ST_Point(DOUBLE x, DOUBLE y)
通过给定的X坐标值,Y坐标值返回对应的Point。 当前这个值只是在球面集合上有意义,X/Y对应的是经度/纬度(longitude/latitude);ps:直接select ST_Point()会卡主,慎重!!!
SELECT ST_AsText**(ST_Point(24.7,** 56.7**));**
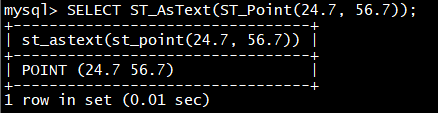
ST_Polygon(VARCHAR wkt)
将一个WKT(Well Known Text)转化为对应的多边形内存形式
SELECT ST_AsText**(ST_Polygon(“POLYGON ((0 0, 10 0, 10 10, 0 10, 0 0))”));**

ST_X(POINT point)
当point是一个合法的POINT类型时,返回对应的X坐标值
SELECT ST_X**(ST_Point(24.7,** 56.7**));**
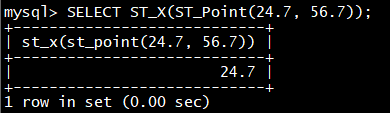
ST_Y(POINT point)
当point是一个合法的POINT类型时,返回对应的Y坐标值
SELECT ST_Y**(ST_Point(24.7,** 56.7**));**
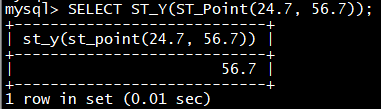
字符串函数
append_trailing_char_if_absent(VARCHAR str, VARCHAR trailing_char)
如果’s’字符串非空并且末尾不包含’c’字符,则将’c’字符附加到末尾。 trailing_char只包含一个字符,如果包含多个字符,将返回NULL
select append_trailing_char_if_absent**(‘a’,‘c’);**
select append_trailing_char_if_absent**(‘ac’,‘c’);**
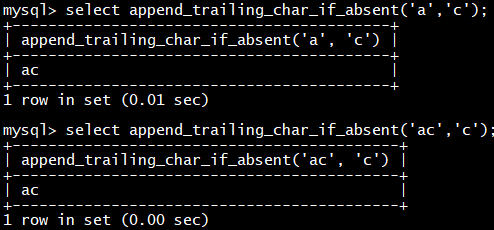
ascii(VARCHAR str)
返回字符串第一个字符对应的 ascii 码
select ascii(‘1’);
select ascii(‘234’);
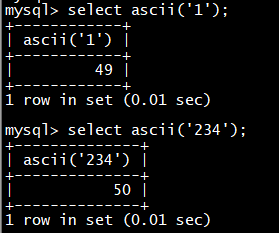
char_length(VARCHAR str)
返回字符串的长度,对于多字节字符,返回字符数, 目前仅支持utf8 编码。这个函数还有一个别名 character_length。
select char_length**(“abc”);**
select char_length**(“中国”);**
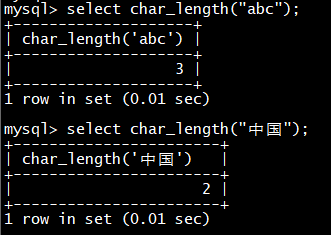
concat(VARCHAR,…)
将多个字符串连接起来, 如果参数中任意一个值是 NULL,那么返回的结果就是 NULL
select concat(“a”, “b”);
select concat(“a”, “b”, “c”);
select concat(“a”, null, “c”);
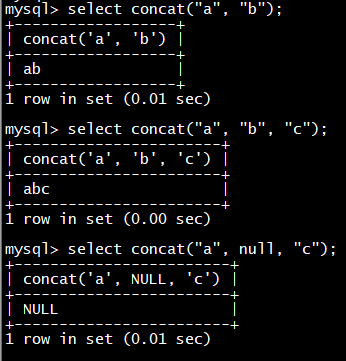
concat_ws(VARCHAR sep, VARCHAR str,…)
使用第一个参数 sep 作为连接符,将第二个参数以及后续所有参数拼接成一个字符串. 如果分隔符是 NULL,返回 NULL。 concat_ws函数不会跳过空字符串,会跳过 NULL 值
select concat_ws(“or”, “d”, “is”);
select concat_ws(NULL, “d”, “is”);
select concat_ws(“or”, “d”, NULL,“is”);
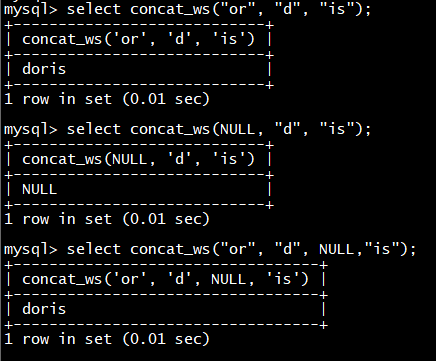
ENDS_WITH (VARCHAR str, VARCHAR suffix)
如果字符串以指定后缀结尾,返回true。否则,返回false。任意参数为NULL,返回NULL。
select ends_with**(“Hello doris”,** “doris”);
select ends_with**(“Hello doris”,** “Hello”);
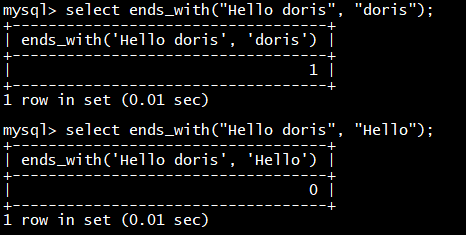
find_in_set(VARCHAR str, VARCHAR strlist)
返回 strlist 中第一次出现 str 的位置(从1开始计数)。strlist 是用逗号分隔的字符串。如果没有找到,返回0。任意参数为 NULL ,返回 NULL。
select find_in_set**(“b”,** “a,b,c”);
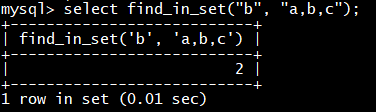
get_json_double(VARCHAR json_str, VARCHAR json_path)
解析并获取 json 字符串内指定路径的浮点型内容。 其中 json_path 必须以 $ 符号作为开头,使用 . 作为路径分割符。如果路径中包含 . ,则可以使用双引号包围。 使用 [ ] 表示数组下标,从 0 开始。 path 的内容不能包含 ", [ 和 ]。 如果 json_string 格式不对,或 json_path 格式不对,或无法找到匹配项,则返回 NULL。
获取 key 为 “k1” 的 value
SELECT get_json_double**(’{“k1”:1.3, “k2”:“2”}’,** “$.k1”);
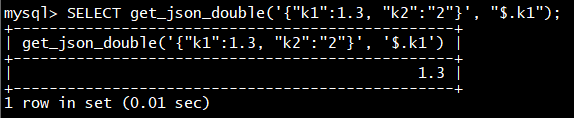
获取 key 为 “my.key” 的数组中第二个元素
SELECT get_json_double**(’{“k1”:“v1”, “my.key”:[1.1, 2.2, 3.3]}’,** ‘$.“my.key”[1]’);

获取二级路径为 k1.key -> k2 的数组中,第一个元素
SELECT get_json_double**(’{“k1.key”:{“k2”:[1.1, 2.2]}}’,** ‘$.“k1.key”.k2[0]’);

get_json_int(VARCHAR json_str, VARCHAR json_path)
解析并获取 json 字符串内指定路径的整型内容。 其中 json_path 必须以 $ 符号作为开头,使用 . 作为路径分割符。如果路径中包含 . ,则可以使用双引号包围。 使用 [ ] 表示数组下标,从 0 开始。 path 的内容不能包含 ", [ 和 ]。 如果 json_string 格式不对,或 json_path 格式不对,或无法找到匹配项,则返回 NULL
获取 key 为 “k1” 的 value
SELECT get_json_int**(’{“k1”:1, “k2”:“2”}’,** “$.k1”);
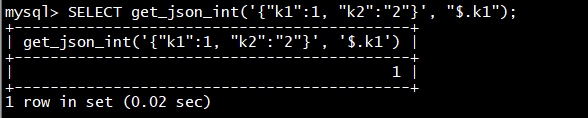
获取 key 为 “my.key” 的数组中第二个元素
SELECT get_json_int**(’{“k1”:“v1”, “my.key”:[1, 2, 3]}’,** ‘$.“my.key”[1]’);

获取二级路径为 k1.key -> k2 的数组中,第一个元素
SELECT get_json_int**(’{“k1.key”:{“k2”:[1, 2]}}’,** ‘$.“k1.key”.k2[0]’);

get_json_string(VARCHAR json_str, VARCHAR json_path)
解析并获取 json 字符串内指定路径的字符串内容。 其中 json_path 必须以 $ 符号作为开头,使用 . 作为路径分割符。如果路径中包含 . ,则可以使用双引号包围。 使用 [ ] 表示数组下标,从 0 开始。 path 的内容不能包含 ", [ 和 ]。 如果 json_string 格式不对,或 json_path 格式不对,或无法找到匹配项,则返回 NULL
获取 key 为 “k1” 的 value
SELECT get_json_string**(’{“k1”:“v1”, “k2”:“v2”}’,** “$.k1”);

获取 key 为 “my.key” 的数组中第二个元素
SELECT get_json_string**(’{“k1”:“v1”, “my.key”:[“e1”, “e2”, “e3”]}’,** ‘$.“my.key”[1]’);

获取二级路径为 k1.key -> k2 的数组中,第一个元素
SELECT get_json_string**(’{“k1.key”:{“k2”:[“v1”, “v2”]}}’,** ‘$.“k1.key”.k2[0]’);

获取数组中,key 为 “k1” 的所有 value
SELECT get_json_string**(’[{“k1”:“v1”}, {“k2”:“v2”}, {“k1”:“v3”}, {“k1”:“v4”}]’,** ‘$.k1’);

group_concat(VARCHAR str[, VARCHAR sep])
该函数是类似于 sum() 的聚合函数,group_concat 将结果集中的多行结果连接成一个字符串。第二个参数 sep 为字符串之间的连接符号,该参数可以省略。该函数通常需要和 group by 语句一起使用。
select value from test**;**
select group_concat**(value)** from test**;**
select group_concat**(value,** " ") from test**;**
instr(VARCHAR str, VARCHAR substr)
返回 substr 在 str 中第一次出现的位置(从1开始计数)。如果 substr 不在 str 中出现,则返回0。
select instr(“abc”, “b”);
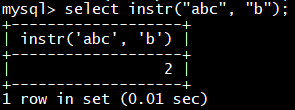
select instr(“abc”, “d”);
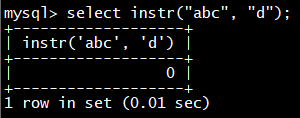
lcase(VARCHAR str)
与lower一致
left(VARCHAR str)
它返回具有指定长度的字符串的左边部分, 长度的单位为utf8字符
select left(“Hello doris”,5);
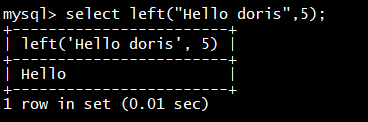
length(VARCHAR str)
返回字符串的字节。
select length(“abc”);
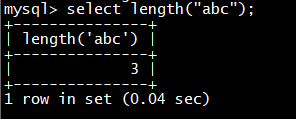
select length(“中国”);
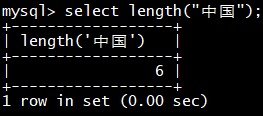
locate(VARCHAR substr, VARCHAR str[, INT pos])
返回 substr 在 str 中出现的位置(从1开始计数)。如果指定第3个参数 pos,则从 str 以 pos 下标开始的字符串处开始查找 substr 出现的位置。如果没有找到,返回0
SELECT LOCATE**(‘bar’,** ‘foobarbar’);
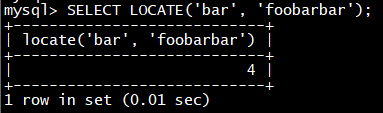
SELECT LOCATE**(‘xbar’,** ‘foobar’);
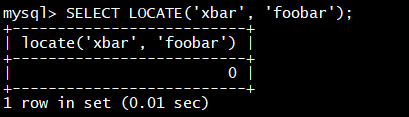
SELECT LOCATE**(‘bar’,** ‘foobarbar’, 5**);**
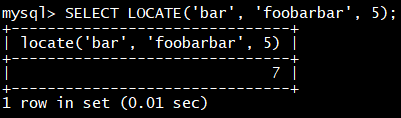
lower(VARCHAR str)
将参数中所有的字符串都转换成小写
SELECT lower(“AbC123”);
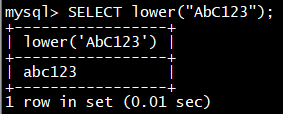
lpad(VARCHAR str, INT len, VARCHAR pad)
返回 str 中长度为 len(从首字母开始算起)的字符串。如果 len 大于 str 的长度,则在 str 的前面不断补充 pad 字符,直到该字符串的长度达到 len 为止。如果 len 小于 str 的长度,该函数相当于截断 str 字符串,只返回长度为 len 的字符串。len 指的是字符长度而不是字节长度。
SELECT lpad(“hi”, 5**,** “xy”);
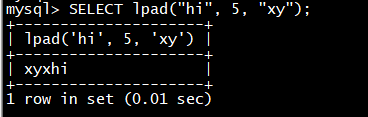
SELECT lpad(“hi”, 1**,** “xy”);
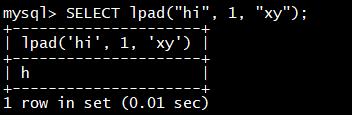
ltrim(VARCHAR str)
将参数 str 中从开始部分连续出现的空格去掉
SELECT ltrim(’ ab d’);
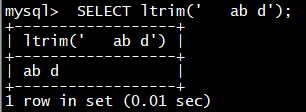
money_format(Number)
将数字按照货币格式输出,整数部分每隔3位用逗号分隔,小数部分保留2位
select money_format**(17014116);**
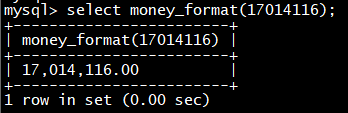
select money_format**(1123.456);**
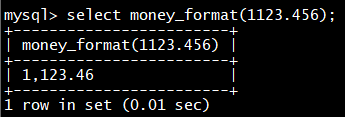
select money_format**(1123.4);**
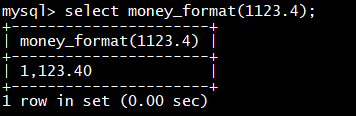
NULL_OR_EMPTY (VARCHAR str)
如果字符串为空字符串或者NULL,返回true。否则,返回false
select null_or_empty**(null);**
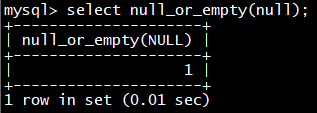
select null_or_empty**("");**
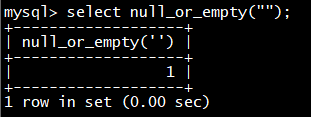
select null_or_empty**(“a”);**
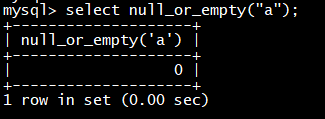
regexp_extract(VARCHAR str, VARCHAR pattern, int pos)
对字符串 str 进行正则匹配,抽取符合 pattern 的第 pos 个匹配部分。需要 pattern 完全匹配 str 中的某部分,这样才能返回 pattern 部分中需匹配部分。如果没有匹配,返回空字符串。
SELECT regexp_extract**(‘AbCdE’,** ‘([[:lower:]]+)C([[:lower:]]+)’, 1**);**

SELECT regexp_extract**(‘AbCdE’,** ‘([[:lower:]]+)C([[:lower:]]+)’, 2**);**

regexp_replace(VARCHAR str, VARCHAR pattern, VARCHAR repl)
对字符串 str 进行正则匹配, 将命中 pattern 的部分使用 repl 来进行替换
SELECT regexp_replace**(‘a b c’,** " ", “-”);
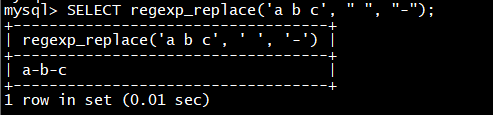
SELECT regexp_replace**(‘a b c’,’(b)’,’<\\1>’);**
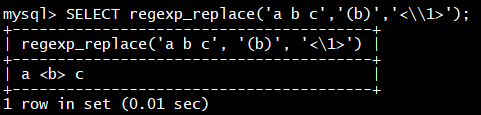
repeat(VARCHAR str, INT count)
将字符串 str 重复 count 次输出,count 小于1时返回空串,str,count 任一为NULL时,返回 NULL
SELECT repeat(“a”, 3**);**
SELECT repeat(“a”, -1**);**
reverse(VARCHAR str)
将字符串反转,返回的字符串的顺序和源字符串的顺序相反。
SELECT REVERSE(‘hello’);
SELECT REVERSE(‘你好’);
right(VARCHAR str)
它返回具有指定长度的字符串的右边部分, 长度的单位为utf8字符
SELECT right(‘Hello doris’,5);
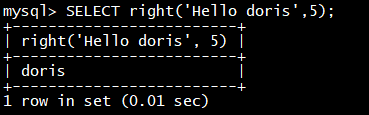
rpad(VARCHAR str, INT len, VARCHAR pad)
返回 str 中长度为 len(从首字母开始算起)的字符串。如果 len 大于 str 的长度,则在 str 的后面不断补充 pad 字符,直到该字符串的长度达到 len 为止。如果 len 小于 str 的长度,该函数相当于截断 str 字符串,只返回长度为 len 的字符串。len 指的是字符长度而不是字节长度。
SELECT rpad(“hi”, 5**,** “xy”);
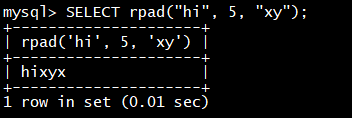
SELECT rpad(“hi”, 1**,** “xy”);
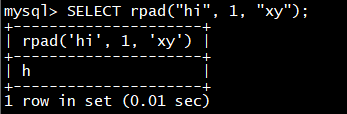
split_part(VARCHAR content, VARCHAR delimiter, INT field)
根据分割符拆分字符串, 返回指定的分割部分(从一开始计数)。
select split_part**(“hello world”,** " ", 1**);**
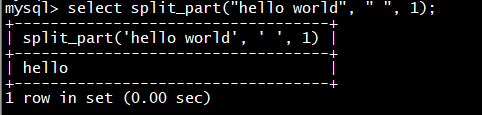
select split_part**(“hello world”,** " ", 2**);**
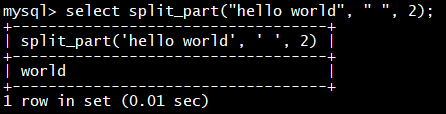
select split_part**(“2019年7月8号”,** “月”, 1**);**
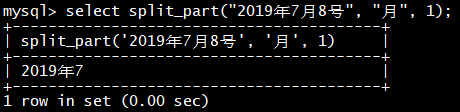
select split_part**(“abca”,** “a”, 1**);**
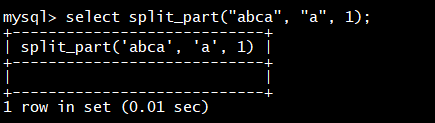
STARTS_WITH (VARCHAR str, VARCHAR prefix)
如果字符串以指定前缀开头,返回true。否则,返回false。任意参数为NULL,返回NULL。
select starts_with**(“hello world”,“hello”);**
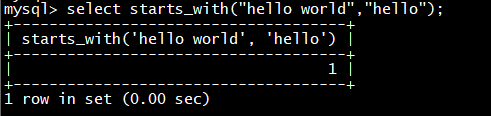
select starts_with**(“hello world”,“world”);**
strleft(VARCHAR str)
它返回具有指定长度的字符串的左边部分,长度的单位为utf8字符
select strleft**(“Hello doris”,5);**
strright(VARCHAR str)
它返回具有指定长度的字符串的右边部分, 长度的单位为utf8字符
select strright**(“Hello doris”,5);**
聚合函数
APPROX_COUNT_DISTINCT(expr)
返回类似于 COUNT(DISTINCT col) 结果的近似值聚合函数。
它比 COUNT 和 DISTINCT 组合的速度更快,并使用固定大小的内存,因此对于高基数的列可以使用更少的内存。
select city**,approx_count_distinct(user_id)** from site_visit group by city**;**
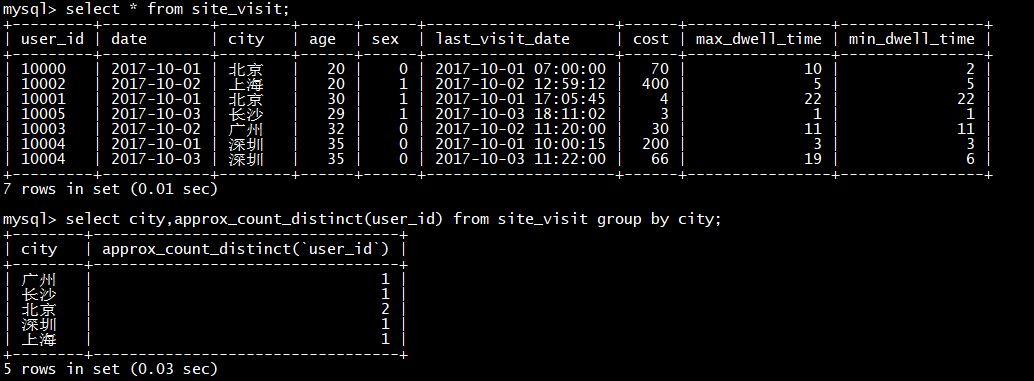
AVG([DISTINCT] expr)
用于返回选中字段的平均值
可选字段DISTINCT参数可以用来返回去重平均值
SELECT date, AVG(cost) FROM site_visit group by date;
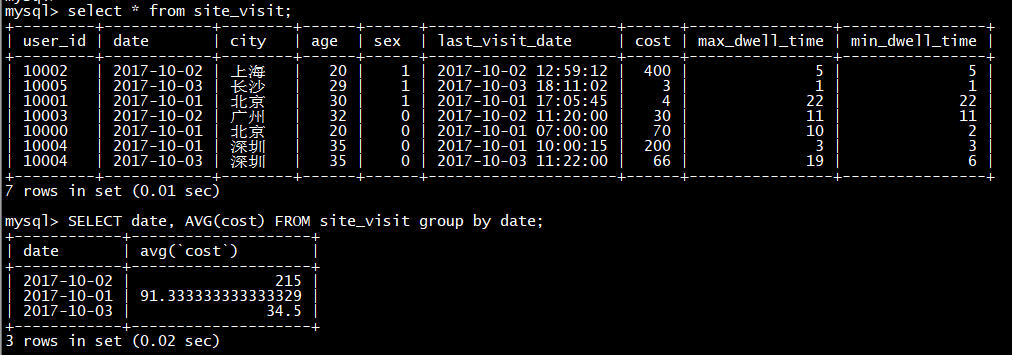
SELECT date, AVG(distinct cost**)** FROM site_visit group by date;
BITMAP_UNION
步骤
说明
1
创建表
CREATE TABLE `pv_bitmap` (
`dt` int(11) NULL COMMENT “”,
`page` varchar(10) NULL COMMENT “”,
`user_id` bitmap BITMAP_UNION NULL COMMENT “”
) ENGINE**=**OLAP
AGGREGATE KEY(`dt`, `page`)
COMMENT “OLAP”
DISTRIBUTED BY HASH**(`dt`)** BUCKETS 2**;**
注:当数据量很大时,最好为高频率的 bitmap_union 查询建立对应的 rollup 表
ALTER TABLE pv_bitmap ADD ROLLUP pv (page, user_id**);**
2
插入数据
insert into pv_bitmap values(20191206, ‘xiaoxiang’, to_bitmap**(101));**
insert into pv_bitmap values(20191206, ‘waimai’, to_bitmap**(101));**
insert into pv_bitmap values(20191207, ‘xiaoxiang’, to_bitmap**(101));**
insert into pv_bitmap values(20191207, ‘waimai’, to_bitmap**(102));**
insert into pv_bitmap values(20191208, ‘xiaoxiang’, to_bitmap**(101));**
insert into pv_bitmap values(20191208, ‘waimai’, to_bitmap**(101));**
3
查询数据
BITMAP_UNION(expr) : 计算两个 Bitmap 的并集,返回值是序列化后的 Bitmap 值
select bitmap_count**(bitmap_union(user_id))** from pv_bitmap**;**
BITMAP_COUNT(expr) : 计算 Bitmap 的基数值
select bitmap_union_count**(user_id)** from pv_bitmap**;**
BITMAP_UNION_COUNT(expr): 和 BITMAP_COUNT(BITMAP_UNION(expr)) 等价
BITMAP_UNION_INT(expr) : 和 COUNT(DISTINCT expr) 等价 (仅支持 TINYINT,SMALLINT 和 INT)
select bitmap_union_int**(id)** from pv_bitmap**;**

COUNT([DISTINCT] expr)
用于返回满足要求的行的数目
select count(*) from site_visit group by date;
select count(date) from site_visit group by date;
select count(distinct date) from site_visit group by date;
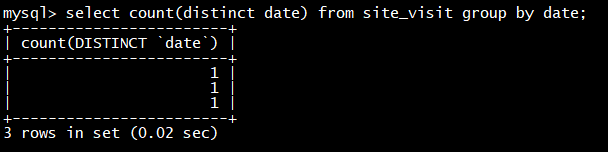
HLL_UNION_AGG(hll)
HLL是基于HyperLogLog算法的工程实现,用于保存HyperLogLog计算过程的中间结果
它只能作为表的value列类型、通过聚合来不断的减少数据量,以此来实现加快查询的目的
基于它得到的是一个估算结果,误差大概在1%左右,hll列是通过其它列或者导入数据里面的数据生成的
导入的时候通过hll_hash函数来指定数据中哪一列用于生成hll列,它常用于替代count distinct,通过结合rollup在业务上用于快速计算uv等
select HLL_UNION_AGG**(uv_set)** from test_uv**;**
MAX(expr)
返回expr表达式的最大值
select max(cost) from site_visit group by date;
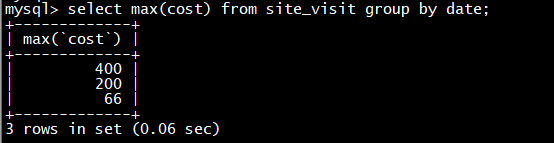
MIN(expr)
返回expr表达式的最小值
select min(cost) from site_visit group by date;
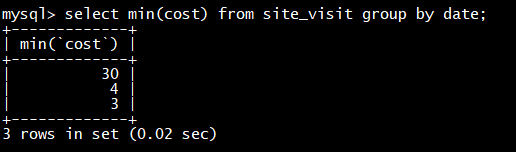
SUM(expr)
用于返回选中字段所有值的和
select sum(cost) from site_visit group by date;
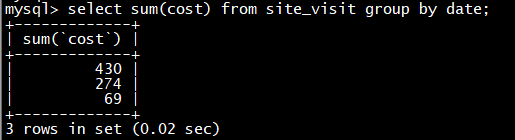
Bitmap函数
BITMAP_AND(BITMAP lhs, BITMAP rhs)
计算两个输入bitmap的交集,返回新的bitmap.
select bitmap_count**(bitmap_and(to_bitmap(1),** to_bitmap**(2)))** cnt**;**

select bitmap_count**(bitmap_and(to_bitmap(1),** to_bitmap**(1)))** cnt**;**

BITMAP_CONTAINS(BITMAP bitmap, BIGINT input)
计算输入值是否在Bitmap列中,返回值是Boolean值.
select bitmap_contains**(to_bitmap(1),2)** cnt**;**
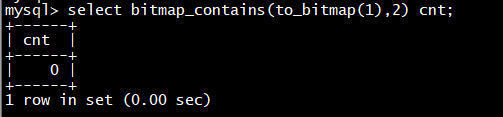
select bitmap_contains**(to_bitmap(1),1)** cnt**;**
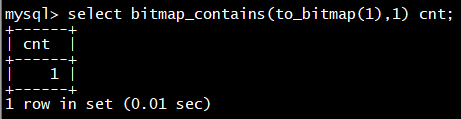
BITMAP_EMPTY()
返回一个空bitmap。主要用于 insert 或 stream load 时填充默认值。例如
select bitmap_count**(bitmap_empty());**
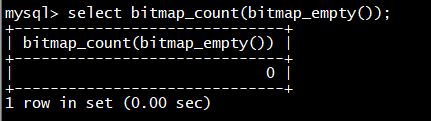
BITMAP_FROM_STRING(VARCHAR input)
将一个字符串转化为一个BITAMP,字符串是由逗号分隔的一组UINT32数字组成. 比如”0, 1, 2”字符串会转化为一个Bitmap,其中的第0, 1, 2位被设置. 当输入字段不合法时,返回NULL
select bitmap_to_string**(bitmap_empty());**
select bitmap_to_string**(bitmap_from_string(“0, 1, 2”));**
select bitmap_from_string**("-1, 0, 1, 2");**
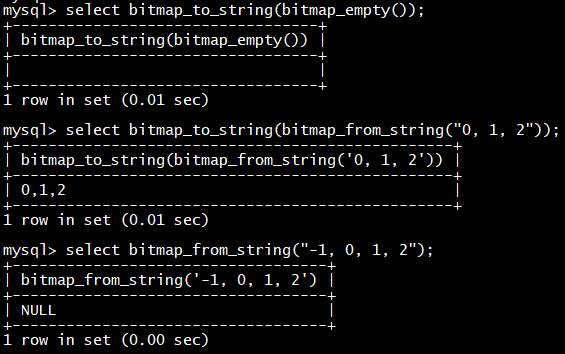
BITMAP_HAS_ANY(BITMAP lhs, BITMAP rhs)
计算两个Bitmap列是否存在相交元素,返回值是Boolean值.
select bitmap_has_any**(to_bitmap(1),to_bitmap(2))** cnt**;**
select bitmap_has_any**(to_bitmap(1),to_bitmap(1))** cnt**;**
BITMAP_HASH(expr)
对任意类型的输入计算32位的哈希值,返回包含该哈希值的bitmap。主要用于stream load任务将非整型字段导入Doris表的bitmap字段。例如
select bitmap_count**(bitmap_hash(‘hello’));**
BITMAP_OR(BITMAP lhs, BITMAP rhs)
计算两个输入bitmap的并集,返回新的bitmap.
select bitmap_count**(bitmap_or(to_bitmap(1),** to_bitmap**(2)))** cnt**;**

select bitmap_count**(bitmap_or(to_bitmap(1),** to_bitmap**(1)))** cnt**;**

BITMAP_TO_STRING(BITMAP input)
将一个bitmap转化成一个逗号分隔的字符串,字符串中包含所有设置的BIT位。输入是null的话会返回null。
select bitmap_to_string**(null);**
select bitmap_to_string**(bitmap_empty());**
select bitmap_to_string**(to_bitmap(1));**
select bitmap_to_string**(bitmap_or(to_bitmap(1),** to_bitmap**(2)));**
代码操作
Spark Doris Connector
Spark Doris Connector 可以支持通过 Spark 读取 Doris 中存储的数据。
- 当前版本只支持从Doris中读取数据。
- 可以将Doris表映射为DataFrame或者RDD,推荐使用DataFrame。
- 支持在Doris端完成数据过滤,减少数据传输量。
版本兼容
- Connector:1.0.0
- Spark:2.x
- Doris:0.12+
- Java:8
- Scala:2.11
编译与安装
在 extension/spark-doris-connector/ 源码目录下执行:
sh build.sh
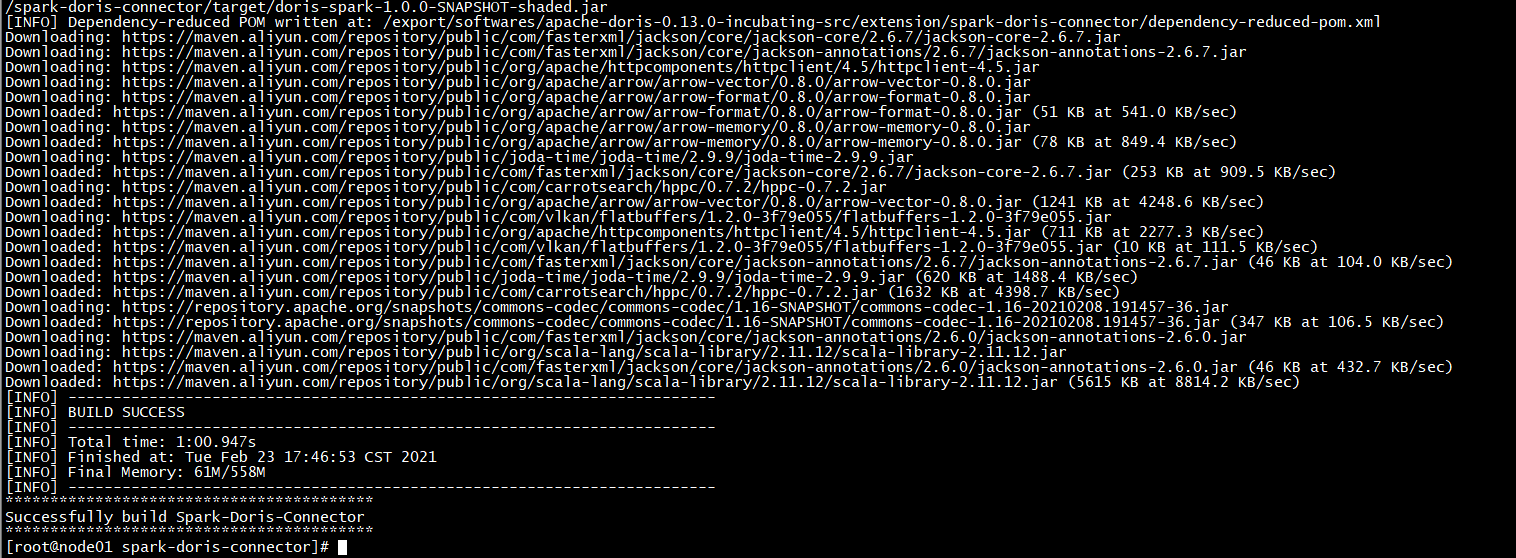
编译成功后,会在 output/ 目录下生成文件 doris-spark-1.0.0-SNAPSHOT.jar。
将此文件复制到 Spark 的 ClassPath 中即可使用 Spark-Doris-Connector。
例如:
Local 模式运行的 Spark,将此文件放入 jars/ 文件夹下。
Yarn集群模式运行的Spark,则将此文件放入预部署包中。
使用示例
SQL
CREATE TEMPORARY VIEW spark_doris
USING doris
OPTIONS**(**
“table.identifier”=“YOUR_DORIS_TABLE_NAME”,
“fenodes”=“YOUR_DORIS_FE_RESFUL_PORT”,
“user”="$YOUR_DORIS_USERNAME",
“password”="$YOUR_DORIS_PASSWORD"
);
SELECT * FROM spark_doris**;**
DataFrame
val dorisSparkDF = spark**.read.format(“doris”)**
.option(“doris.table.identifier”, “YOUR_DORIS_TABLE_NAME”)
.option(“doris.fenodes”, “YOUR_DORIS_FE_RESFUL_PORT”)
.option(“user”, “$YOUR_DORIS_USERNAME”)
.option(“password”, “$YOUR_DORIS_PASSWORD”)
.load()
dorisSparkDF**.show(5)**
RDD
import org**.apache.doris.spark.**_
val dorisSparkRDD = sc**.dorisRDD(**
tableIdentifier = Some(“YOUR_DORIS_TABLE_NAME”),
cfg = Some(Map(
“doris.fenodes” -> “YOUR_DORIS_FE_RESFUL_PORT”,
“doris.request.auth.user” -> “$YOUR_DORIS_USERNAME”,
“doris.request.auth.password” -> “$YOUR_DORIS_PASSWORD”
))
)
dorisSparkRDD**.collect()**
配置
- 通用配置项
Key
Default Value
Comment
doris.fenodes
–
Doris FE http 地址,支持多个地址,使用逗号分隔
doris.table.identifier
–
Doris 表名,如:db1.tbl1
doris.request.retries
3
向Doris发送请求的重试次数
doris.request.connect.timeout.ms
30000
向Doris发送请求的连接超时时间
doris.request.read.timeout.ms
30000
向Doris发送请求的读取超时时间
doris.request.query.timeout.s
3600
查询doris的超时时间,默认值为1小时,-1表示无超时限制
doris.request.tablet.size
Integer.MAX_VALUE
一个RDD Partition对应的Doris Tablet个数。
此数值设置越小,则会生成越多的Partition。从而提升Spark侧的并行度,但同时会对Doris造成更大的压力。
doris.batch.size
1024
一次从BE读取数据的最大行数。增大此数值可减少Spark与Doris之间建立连接的次数。
从而减轻网络延迟所带来的的额外时间开销。
doris.exec.mem.limit
2147483648
单个查询的内存限制。默认为 2GB,单位为字节
doris.deserialize.arrow.async
false
是否支持异步转换Arrow格式到spark-doris-connector迭代所需的RowBatch
doris.deserialize.queue.size
64
异步转换Arrow格式的内部处理队列,当doris.deserialize.arrow.async为true时生效
- SQL 和 Dataframe 专有配置
Key
Default Value
Comment
user
–
访问Doris的用户名
password
–
访问Doris的密码
doris.filter.query.in.max.count
100
谓词下推中,in表达式value列表元素最大数量。超过此数量,则in表达式条件过滤在Spark侧处理。
- RDD 专有配置
Key
Default Value
Comment
doris.request.auth.user
–
访问Doris的用户名
doris.request.auth.password
–
访问Doris的密码
doris.read.field
–
读取Doris表的列名列表,多列之间使用逗号分隔
doris.filter.query
–
过滤读取数据的表达式,此表达式透传给Doris。Doris使用此表达式完成源端数据过滤。
Doris 和 Spark 列类型映射关系
Doris Type
Spark Type
NULL_TYPE
DataTypes.NullType
BOOLEAN
DataTypes.BooleanType
TINYINT
DataTypes.ByteType
SMALLINT
DataTypes.ShortType
INT
DataTypes.IntegerType
BIGINT
DataTypes.LongType
FLOAT
DataTypes.FloatType
DOUBLE
DataTypes.DoubleType
DATE
DataTypes.StringType1
DATETIME
DataTypes.StringType1
BINARY
DataTypes.BinaryType
DECIMAL
DecimalType
CHAR
DataTypes.StringType
LARGEINT
DataTypes.StringType
VARCHAR
DataTypes.StringType
DECIMALV2
DecimalType
TIME
DataTypes.DoubleType
HLL
Unsupported datatype
注:Connector中,将DATE和DATETIME映射为String。由于Doris底层存储引擎处理逻辑,直接使用时间类型时,覆盖的时间范围无法满足需求。所以使用 String 类型直接返回对应的时间可读文本。
演示
- 创建maven项目
- 导入pom依赖
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<scala.version>2.11</scala.version>
<junit.version>4.12</junit.version>
<http.version>4.5.11</http.version>
<spark.version>2.4.0-cdh6.2.1</spark.version>
<parquet.version>1.9.0-cdh6.2.1</parquet.version>
<fastjson.version>1.2.62</fastjson.version>
<mysql.version>5.1.44</mysql.version>
<jtuple.version>1.2</jtuple.version>
<maven-compiler-plugin.version>3.1</maven-compiler-plugin.version>
<maven-surefire-plugin.version>2.19.1</maven-surefire-plugin.version>
<maven-shade-plugin.version>3.2.1</maven-shade-plugin.version>
- 读取doris数据
package cn.itcast.doris
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.doris.spark._
/**
* 需求:从doris中读取数据
*/
object TestReadDoris {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster(“local[*]”);
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
val df = sparkSession.read.format(“jdbc”)
.option(“url”, “jdbc:mysql://node1:9030/test_db”)
.option(“user”, “root”)
.option(“password”, “123456”)
.option(“dbtable”, “example_site_visit”)
.load()
df.show()
sparkSession.stop()
}
}
- 数据写入doris
package cn.itcast.doris
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 需求:将数据写入到doris中
*/
object TestWriteDoris {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster(“local[*]”);
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
val df = sparkSession.createDataFrame(Array(
(10004, “2021-02-01”, “深圳”, 30, 0, “2021-02-01 10:00:15”, 100, 10, 10),
(10005, “2021-02-01”, “北京”, 30, 0, “2021-02-01 10:00:15”, 100, 10, 10)
)).toDF(“user_id”, “date”, “city”, “age”, “sex”, “last_visit_date”, “cost”, “max_dwell_time”, “min_dwell_time”)
val props = new Properties()
props.setProperty(“user”, “root”)
props.setProperty(“password”, “123456”)
df.write.mode(SaveMode.Append).jdbc(“jdbc:mysql://node1:9030/test_db”, “example_site_visit”, props)
sparkSession.stop()
}
}
Doris案例篇
基于Doris的有道精品课数据中台建设实践
背景
业务背景
根据业务需求,目前有道精品课的数据层架构上可分为离线和实时两部分。
离线系统主要处理埋点相关数据,采用批处理的方式定时计算。
而实时流数据主要来源于各个业务系统实时产生的数据流以及数据库的变更日志,需要考虑数据的准确性、实时性和时序特征,处理过程非常复杂。
有道精品课数据中台团队依托于其实时计算能力在整个数据架构中主要承担了实时数据处理的角色,同时为下游离线数仓提供实时数据同步服务。
数据中台主要服务的用户角色和对应的数据需求如下:
- 运营/策略/负责人主要查看student的整体情况,查询数据中台的一些课程维度实时聚合数据
- 辅导/销售主要关注所服务student的各种实时明细数据
- 品控主要查看课程/老师/辅导各维度整体数据,通过T+1的离线报表进行查看
- 数据分析师对数据中台T+1同步到离线数仓的数据进行交互式分析
数据中台前期系统架构及业务痛点
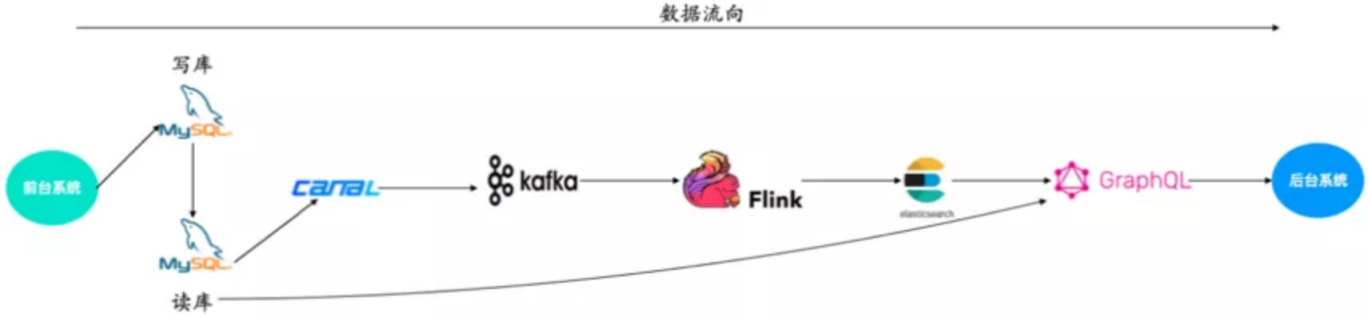
如上图所示,在数据中台1.0架构中我们的实时数据存储主要依托于Elasticsearch,遇到了以下几个问题:
- 聚合查询效率不高
- 数据压缩空间低
- 不支持多索引的join,在业务设计上我们只能设置很多大宽表来解决问题
- 不支持标准SQL,查询成本较高
实时数仓选型
基于上面的业务痛点,我们开始对实时数仓进行调研。当时调研了Doris, ClickHouse, TiDB+TiFlash, Druid, Kylin。
OLAP引擎
优势
劣势
Doris
兼容MySQL协议
支持Online Schema Change
支持更新
集群扩缩容自动化
支持基于时间分区,冷热数据分离
开源较晚,目前还在孵化中
ClickHouse
单机性能强劲
向量化引擎
数据压缩空间大
不支持标准SQL
集群扩缩容不能自动Rebalance
对更新支持不好
运维成本较高
TiDB+TiFlash
兼容MySQL协议
向量化引擎
业务数据和分析数据同步方便(内部Raft同步)
TiFlash不开源
落地公司较少
架构主要面向TP场景
Druid
基于时间分区,聚合数据查询较快
支持冷热数据分离
不支持明细数据存储
不支持标准SQL
Kylin
支持标准SQL查询
支持预聚合
社区发展较好
依赖较多
明细查询支持较弱
资源消耗较多
由于起初我们数据中台只有两名开发,而且存储相关的东西需要自行运维,所以我们对运维的成本是比较敏感的,在这一方面我们首先淘汰了Kylin和ClickHouse。
在查询方面,我们的场景大多为明细+聚合多维度的分析,所以Druid也被排除。
最后我们对聚合分析的效率方面进行对比,由于Doris支持Bitmap和RollUp,而TiDB+TiFlash不支持,所以我们最终选择了Doris来作为我们数据中台的主存储。
基于Apache Doris的数据中台2.0
架构升级
在完成了实时数仓的选型后,我们针对Doris做了一些架构上的改变以发挥它最大的作用,主要分为以下几个方面:
- Flink双写
将所有Flink Job改写,在写入Elasticsearch的时候旁路输出一份数据到Kafka,并对复杂嵌套数据创建下游任务进行转化发送到Kafka,Doris使用Routine Load导入数据。
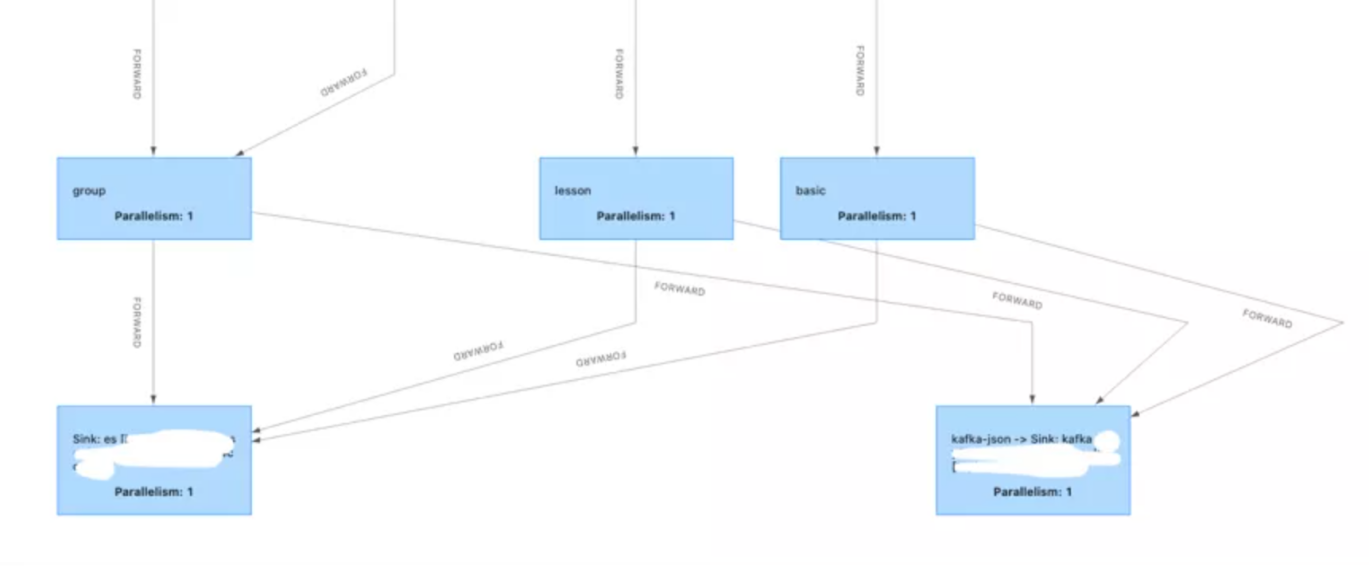
- Doris on ES
由于之前我们的实时数仓只有ES,所以在使用Doris的初期,我们选择了通过Doris创建ES外表的方式来完善我们的Doris数仓底表。同时也降低了查询成本,业务方可以无感知地使用数仓底表。
具体查询Demo如下所示,我们通过student的基础信息Join各种练习信息,对student数据进行补齐。

- 数据同步
原来我们使用ES的时候,由于很多表没有数据写入时间,数据分析师需要每天扫全表导出全量数据到Hive,这对我们的集群有很大压力,并且也会导致数据延迟上升,我们在引入了Doris后,对所有数仓表都添加 eventStamp, updateStamp, deleted这三个字段。
-
- eventStamp:事件发生时间
- updateStamp:Doris数据更新时间,在Routine Load中生成
- deleted:数据是否删除,由于我们很多实时数仓需要定时同步到离线数仓,所以数据需要采取软删除的模式
- 数据对下游同步时可以灵活的选择eventStamp或者updateStamp进行增量同步。数据同步我们采用了多种方式,通过Hive表名后缀来决定不同同步场景:
- _f:每天/每小时全量同步,基于Doris Export全量导出
- _i:每天/每小时增量同步,基于Doris Export按分区导出/网易易数扫表导出
- _d:每天镜像同步,基于Doris Export全量导出
- 指标域划分/数据分层
将Elasticsearch中的数据进行整理并结合后续的业务场景,我们划分出了如下四个指标域:
根据上面的指标域,我们基于星型模型开始构建实时数仓,在Doris中构建了20余张数仓底表以及10余张维表,通过网易易数构建了完整的指标系统。
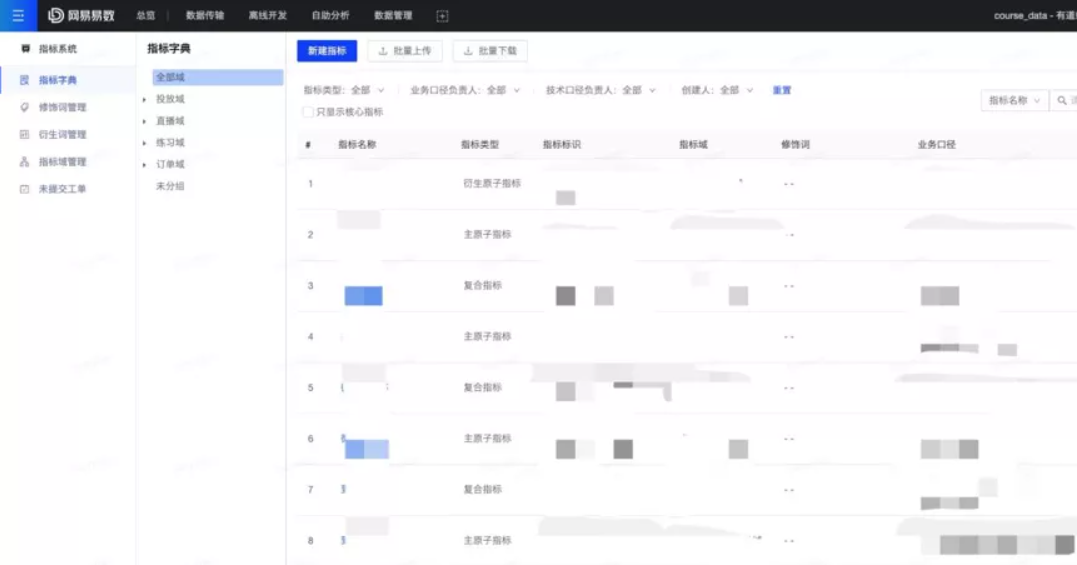
- 微批生成DWS/ADS层
由于我们多数场景都是明细+聚合数据的分析,所以我们基于Doris insert into select的导入方式,实现了一套定时根据DWD层数据生成DWS/ADS层数据的逻辑,延迟最低可以支持到分钟级,整体的多层数仓表计算流程如下图:
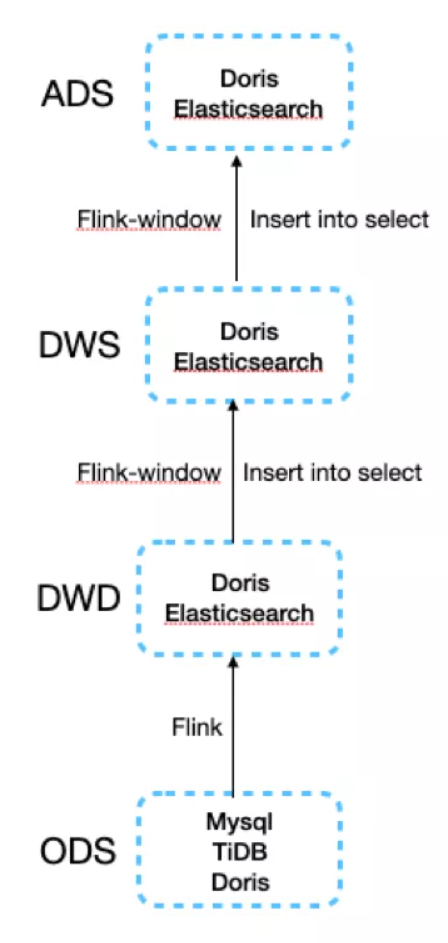
对于明细数据在TiDB或者ES的,我们选择了在Flink中进行窗口聚合写入到下游Doris或者ES中。而对于明细数据只在Doris单独存在的数据,由于我们大部分使用了异步写入的方式,所以数据无法立即可读,我们在外围构建了支持模版化配置的定时执行引擎,支持分钟/小时级别的扫描明细表变更写入下游聚合表,具体模版配置如下图:
需要对监听的源表以及变更字段进行配置,在配置的interval时间窗口内多个源表进行扫描,然后将结果进行merge后生成参数,根据配置的threshold对参数进行拆分后传入多个insert sql中,并在每天凌晨进行T+1的全量聚合,修复微批计算的错误数据。
具体的计算触发逻辑如下图:
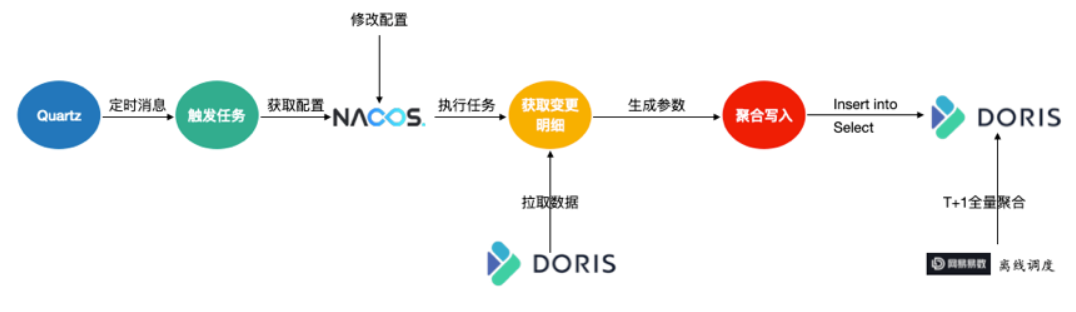
- 数据血缘
我们基于拉取Routine Load和Flink数据以及服务上报的方式实现了数据中台完善的数据血缘,供数据开发/数据分析师进行查询。
由于我们的Flink开发模式为提交jar的形式,为了获取到任务的血缘,我们对每个算子的命名进行了格式化封装,血缘服务定时的拉取/v1/jobs/overview数据进行解析,我们将不同算子的格式命名封装为以下几种:
-
- Source:sourceTypeName [address] [attr]
- Sink:sinkTypeName [address] [attr]
具体的血缘服务逻辑如下图所示:
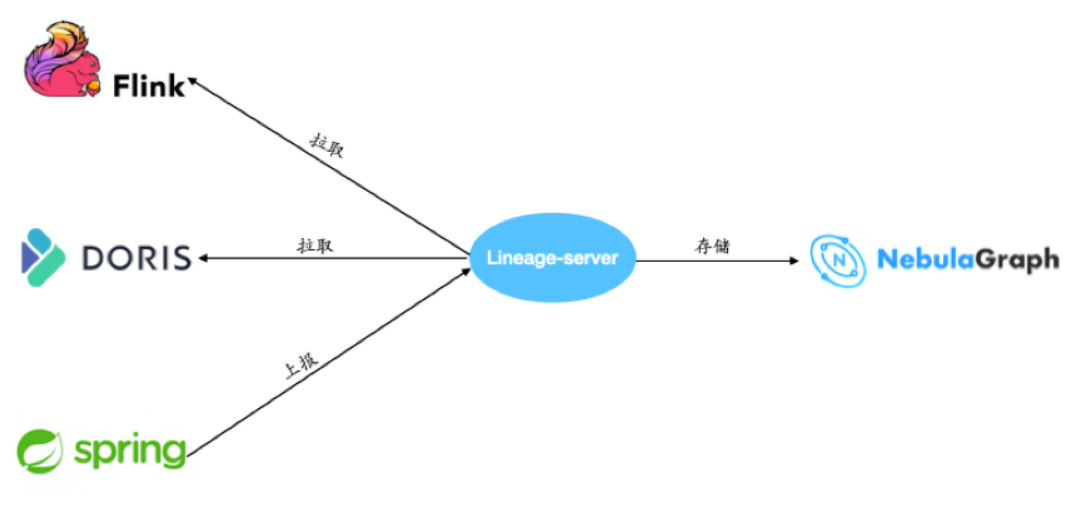
通过血缘服务内部的解析后,批量地将血缘数据拆分成了Node与Edge存储到了NebulaGraph中,前台服务进行查询即可获得如下图所示的一条完整血缘:
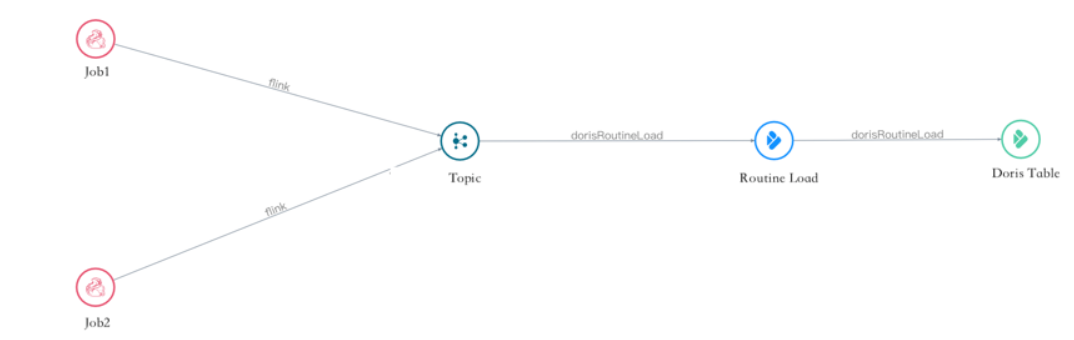
数据中台2.0架构
基于围绕Doris的系统架构调整,我们完成了数据中台2.0架构
- 使用网易易数数据运河替换Canal,拥有了更完善的数据订阅监控
- Flink 计算层引入 Redis/Tidb 来做临时/持久化缓存
- 复杂业务逻辑拆分至 Grpc 服务,减轻 Flink 中的业务逻辑
- 数据适配层新增 Restful 服务,实现一些 case by case 的复杂指标获取需求
- 通过网易易数离线调度跑通了实时到离线的数据同步
- 新增了数据报表/自助分析系统两个数据出口
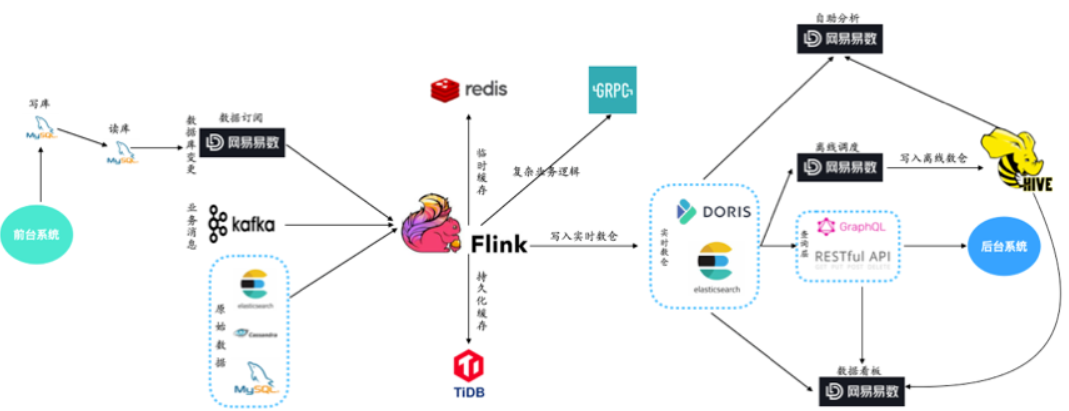
Doris带来的收益
1. 数据导入方式简单,我们针对不同业务场景使用了三种导入方式
- Routine Load:实时异步数据导入
- Broker Load:定时同步离线数仓数据,用于查询加速
- Insert into:定时通过DWD层数仓表生成DWS/ADS层数仓表
- 数据占用空间降低,由原来Es中的1T左右降低到了200G左右
- 数仓使用成本降低
- Doris支持MySQL协议,数据分析师可以直接进行自助取数,一些临时分析需求不需要再将Elasticsearch数据同步到Hive供分析师进行查询。
- 一些在ES中的明细表我们通过Doris外表的方式暴露查询,大大降低了业务方的查询成本。
- 同时因为Doris支持Join,原来一些需要查询多个Index再从内存中计算的逻辑可以直接下推到Doris中,提升了查询服务的稳定性,加快了响应时间。
- 聚合计算速度通过物化视图和列存优势获得了较大提升。
上线表现
目前已经上线了几十个实时数据报表,在线集群的P99稳定在1s左右。同时也上线了一些长耗时分析型查询,离线集群的P99稳定在1min左右。


同时我们基于Doris完成了标准化数仓的构建,在数据开发上跑通了一套完整的流程,使我们数据需求的日常迭代更加迅速。
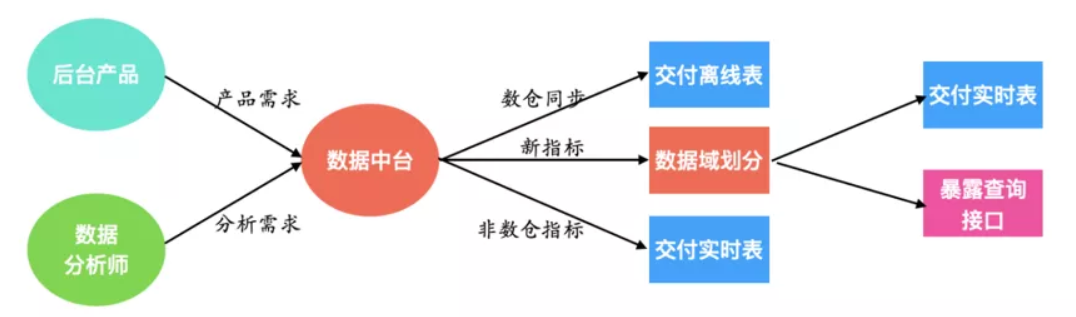
总结和规划
Doris的引入推进了有道精品课数据分层的构建,加速了实时数仓的规范化进程。数据中台团队在此基础上一方面向全平台各业务线提供统一的数据接口,并依托于Doris生产实时数据看板,另一方面定时将实时数仓数据同步至下游离线数仓供分析师进行自助分析,为实时和离线场景提供数据支撑。对于后续工作的开展,我们做了如下规划:
- 基于Doris明细表生成更多的上层聚合表,降低Doris计算压力,提高查询服务的整体响应时间
- 基于Flink实现Doris Connector,实现Flink对Doris的读写功能
- 开发Doris on ES支持嵌套数据的查询
Doris on ES在快手商业化的最佳实践
业务场景介绍
服务介绍
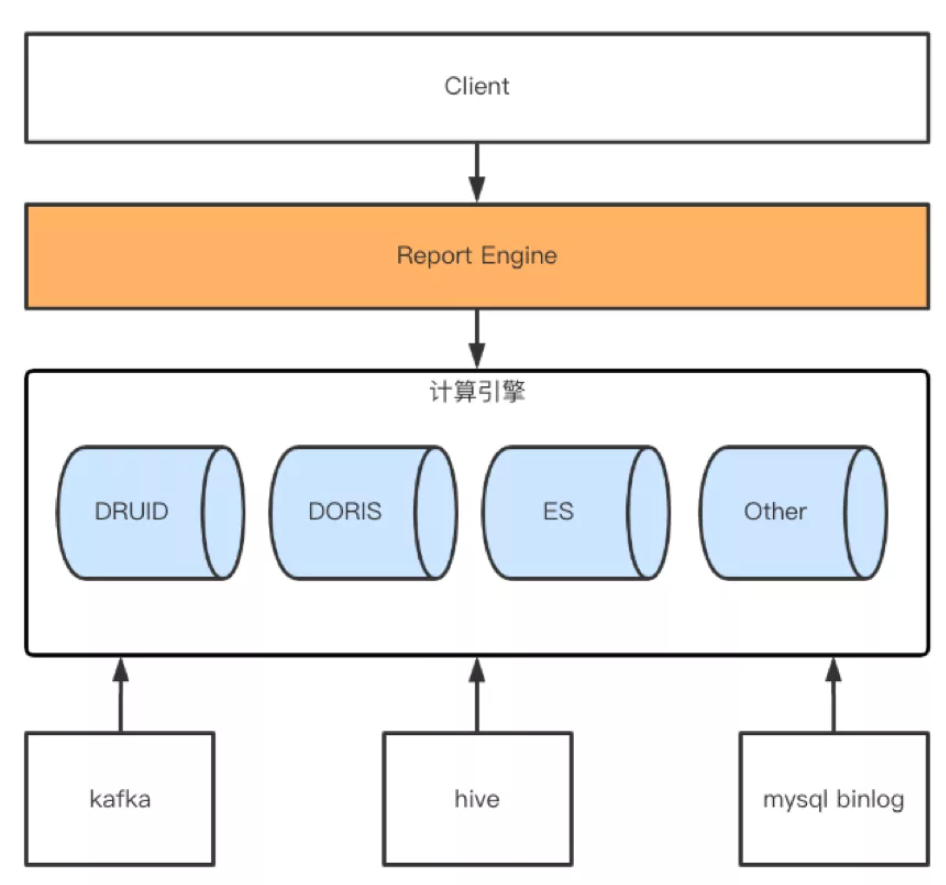
本案例主要侧重介绍Doris on ES(DOE)在我们业务场景的实践,所以数据架构在这里只做简单介绍,如上如图所示。
总体来说数据分为实时+离线两块事实数据写入,外加mysql binlong同步这一部分的维度数据写入。
实时主要是flink+kafka,离线部分基本各大公司都是统一解决方案-HIVE。数据最终导入计算引擎都是由各个引擎适配的工具或组件配合来完成的。如DRUID的KIS(kafka index service)+index_hadoop,Doris的routine load + broker load。
业务场景
业务场景主要为两大块——传统型的OLAP分析查询场景+星型模型join场景下的OLAP多维分析查询。
传统OLAP多维分析查询
如上图,传统OLAP多维分析查询基本上是对事实数据(fact table)的下钻、上卷、切片、切块、旋转操作。
参考blog:
https://blog.csdn.net/xwc35047/article/details/86369465
星型模型join场景下的OLAP多维分析查询
星型模型Join场景下的OLAP多维分析查询与传统OLAP多维分析的区分主要是引入了维度数据(dim table)Join。
select
f**.key_1,**
f**.key_2,**
d**.key_3,**
d**.key_4,**
AGGR_FUNC**(f.value_1),**
AGGR_FUNC**(f.value_2)**
from
f left join d on d**.key** = f**.**key_1 – 维度表必须具有主键,与事实表进行关联
where
f**.**dt in (xxx) and
f**.**key_xx in (xxx) and
d**.**col_2 in (xxx) and – 可以基于维度表的col做filter
d**.key_3 match(‘xxx’)** – match在这里表达的含义是分词模糊匹配场景
group by
f**.key_1,**
f**.key_2,**
d**.key_3,**
d**.**key_4
order by
AGGR_FUNC**(f.value_1)** DESC
having AGGR_FUNC**(f.value_2)** > xxx
limit N
维度数据主要有两大用处:
- 过滤筛选
- 填充其他维度信息,如name等。
这里解释一下为何我们不能做成大宽表模式。通常来说,针对类似场景通用解决方案一般有两种:
- 大宽表,数据以尽可能全的维度,先join好再写入引擎
- 星型模型关联查询,查询的时候才去做关联join
对于以上两种方案各有什么优劣势呢?
大宽表,空间换时间。理论上都是维表主键为唯一ID来填充所有维度,这样只是冗余存储了多条维度数据,但是在OLAP引擎里,不管是DRUID、KYLIN还是DORIS都不会造成数据量的基数膨胀。
优势:应用层查询的时候非常方便,无需关联额外的维表,直接面向大而全的宽表查询。
劣势:对应的弊端就是如果有维度数据update场景,支持的代价非常大。如果update非常频繁,这种方式就不可行了。
星型模型关联查询。
优势:维度数据与事实数据完全分离,维度数据用专门的引擎存储(如mysql、elasticsearch等等),可以支持高频update操作,查询时通过主键关联查询维度数据。
劣势:查询层逻辑相对复杂,且多表join会导致性能受损。
业务挑战
- 超大数据量:单表原始数据每天增量百亿
- 查询高QPS:平均QPS千级别
- 高稳定性要求:在线服务要求稳定性4个9
- 星型模型中,维表需要支持高频的UPDATE操作(update qps约1千),且维表需要支持模糊匹配、分词检索
架构实现
数据生产
事实数据
如上图,数据写入部分:实时数据通过Flink处理,再写入Kafka。最后通过Kafka Index Service摄入到Druid。
事实数据一般量级是非常大的,在我们的场景下,实时数据量比较大,为了减少下游KIS的压力,我们在Flink层加了一层窗口聚合。并且对最终写入kafka的数据进行了KeyBy处理,将相同维度相同取值的数据都发送到同一个topic partion。
做KeyBy操作的核心目的是为了适配Druid引擎的特性。如果以随机的方式发往kafka topic的各个partion,会导致每个partion都可能涵盖所有取值的数据。进而导致每个KIS task包含了所有取值的数据(我们生成环境KIS task数目与topic的partion数是一一对应的),造成KIS task的segment文件大幅膨胀(两种区别的理论值为key By处理生成的segment大小为不做key by的 1/partion总数),影响实时数据的查询性能(这里如果没太看明白可以参考阅读Druid官方文档,了解Druid数据聚合、索引构建原理)。
注意:Key By操作可能会导致引发数据热点,可以通过热点数据动态加盐解决。
维度数据
为什么选用ES做维度数据存储引擎?
- 维表数据量级较高,Mysql存储需要做分库分表支持,但是性能无法满足需求
- 更新频率较高,update QPS约1000
- 业务侧需要支持分词模糊检索
综合以上几点,Elasticsearch(ES)引擎能够非常好的解决上述问题。ES拥有强大的分词检索能力,支持较高频率的update操作,和很好的横向扩展能力。其他如Hbase、Redis等都不能满足上述需求。
数据同步ES过程:如上图所示,维度数据原本存储在Mysql引擎,通过伪装的Mysql从库来监听binlog,将维度数据同步到ES。并且有一个检查与恢复的服务做数据同步监控,支持按时间增量check、全量check、增量回刷、全量回刷等操作。
报表引擎
报表引擎架构实现整体分为REFront 和 REQuery两层,REMeta为独立的元数据管理模块。
- REFront
- REFront 为统一的查询入口层,特点是轻量级、高可用。
- 核心职能为:查询标记、业务逻辑处理、查询分发、流控、熔断降级。
- REQuery
- REQuery 为查询执行层,分组部署,为不同的业务场景提供物理隔离。
- 核心职能为:多引擎适配、多集群路由调度、查询优化、MEM Join、结果分页cache等。
报表引擎通过抽象,在REQuery内部实现MEM Join。支持Druid引擎中的事实数据与ES引擎中的维度数据做关联查询。
为上层业务提供虚拟的cube表查询。屏蔽复杂的跨引擎管理查询逻辑。
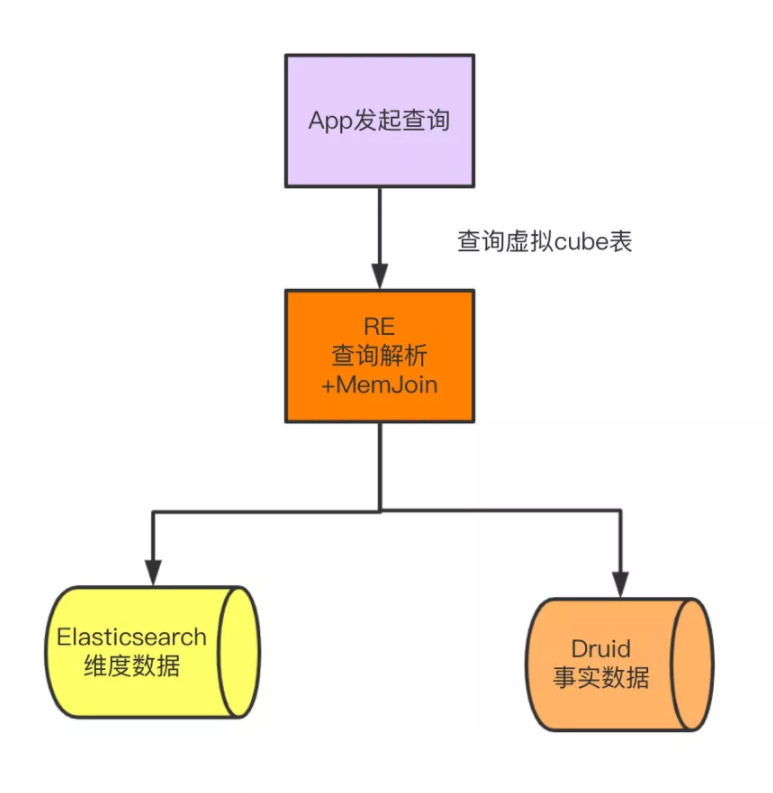
基于Doris on ES的架构实现
Mem Join架构遗留的核心问题
Mem Join是单机实现与串行执行,到单次从ES中拉取的数据量超过10W时,响应时间已经接近10s,大户体验差。而且单节点实现大规模数据Join处理,内存消耗大,有Full GC风险。
Doris+Doris on ES完美配合
上文提到,OLAP分析场景,经常会遇到一个大难题:**针对需要关联维度查询的场景,究竟是做成大宽表还是查询时Join?**总结来说,如果要支持维度数据存储,并且支持Join,目前开源的各类引擎或多或少都存在一些局限性。Druid的lookup Join实现太弱了,真实业务场景如果基本上很难适用。Doris和Clickhouse这里引擎都支持Join,并且支持明细数据存储,但是如要要高频Update,也是没办法做到。如果跳出Olap引擎,在应用层做Join实现,也是一种解法,但是实现成本高。
直到遇见了Doris on ES!
Doris on ES 查询性能如何?
Doris引擎为MPP架构,本身就具备很强的性能及横向扩展能力。Doris on ES构建在这个能力之上,并且对查询做了大量的优化,这给对ES原理理解不深的同学带来了方便。
主要的优化点如下:
- Shard级别并发
- 行列扫描自动适配,优先列式扫描
- 顺序读取,提前终止
- 两阶段查询变为一阶段查询
- Join场景使用Broadcast Join,对于小批量数据Join特别友好
不太完善的地方:
- 目前Doris on ES还不支持聚合下推,但是对于我们维度数据查询场景其实是用不到聚合操作。需要用到聚合操作的场景需要注意一下。不过目前社区也正在开发支持。
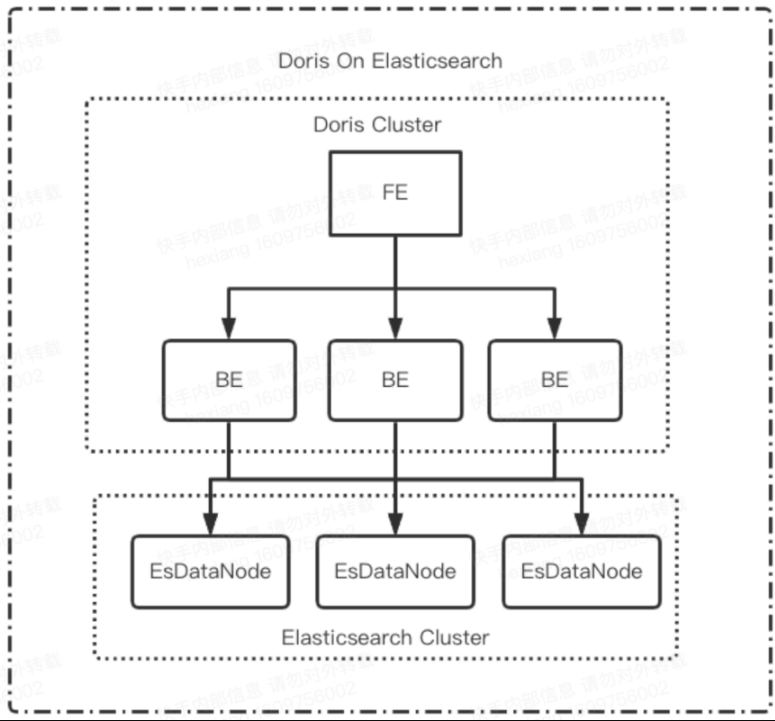
基于DOE的架构实现
数据链路升级
数据链路升级适配比较简单
- Doris构建新的Olap表,配置好物化视图。
- 实时导入基于之前事实数据的kafka topic启动routine load。
- 离线校准通过broker load从hive中导入。
- Doris创建on ES外表(社区正在开发自动同步建表)
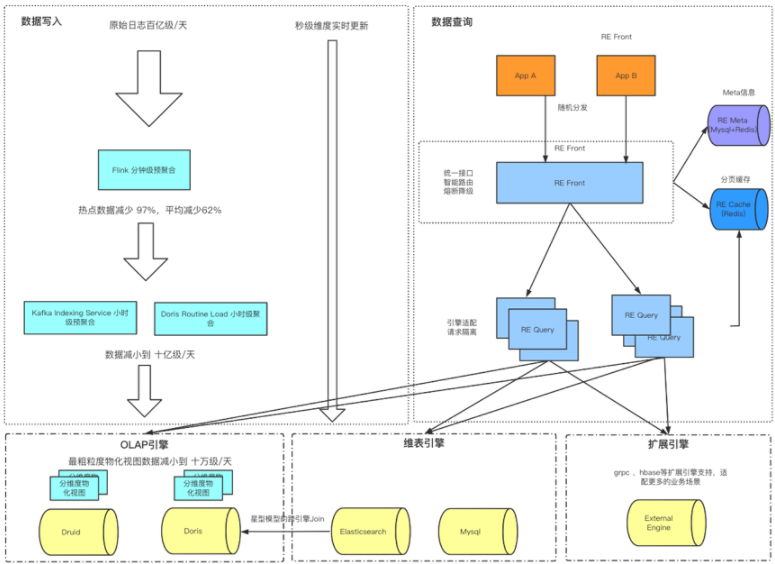
踩坑记录与贡献
贡献
- 动态分区小时支持: https://github.com/apache/incubator-doris/pull/4514
- DOE解决查询路由异常: https://github.com/apache/incubator-doris/pull/4352
- multi fields在多text类型情况下空指针异常:https://github.com/apache/incubator-doris/pull/4300
Tips
- routine load参数问题,主要关注desired_concurrent_number并发数,max_batch_interval,max_batch_rows,max_batch_size,目的是增大单次导入的数据量,提高导入性能
- compact参数问题,主要调整cumulative_compaction_num_threads_per_disk、base_compaction_num_threads_per_disk、min_compaction_failure_interval_sec并且在代码中对因为没拿到锁的异常进行过滤,目的是提高compact频率,加快compact速度,减少小文件的产生
- 高并发下的所有fe hang死问题,主要调整fragment_pool_thread_num_max, fragment_pool_thread_num_min,fragment_pool_queue_size,过小的fragment_pool_thread会导致fragment死锁
- 提高高并发查询性能,高并发下需要降低每个查询的资源使用,主要降低doris_scanner_queue_size、doris_scanner_thread_pool_thread_num,避免创建过多scanner线程
报表引擎适配升级
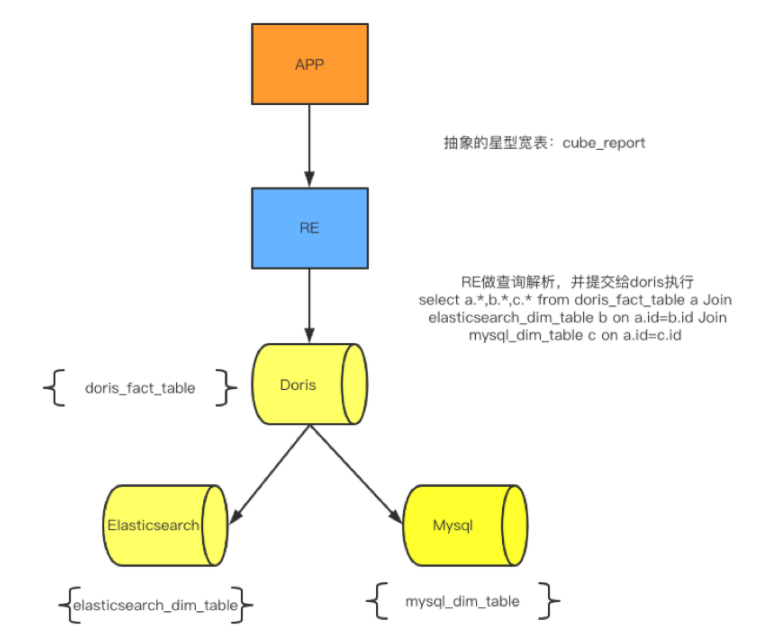
注:上图关联的mysql维表是基于未来规划,目前主要是ES做维表引擎
报表引擎适配
- 抽象基于Doris的星型模型虚拟cube表
- 适配cube表查询解析,智能下推
- 支持灰度上线
线上表现
查询响应时间
事实表查询表现对比
Druid
Doris
99分位耗时Druid大概为270ms,Doris为150ms,延时下降45%
Join场景下cube表查询表现对比
Druid
Doris
99分位耗时Druid大概为660ms,Doris为440ms,延时下降33%
收益总结
- 整体p99耗时下降35%左右
- 资源节省50%左右
- 去除报表引擎内部Mem Join的复杂逻辑,下沉至Doris通过DOE实现,在大查询场景下(维表结果超过10W,性能提升超过10倍,10s->1s)
- 更丰富的查询语义(原本Mem Join实现比较简单,不支持复杂的查询)
总结与未来规划
从测试和线上的表现来看,Doris引擎的表现还是非常优秀的。
多维分析聚合查询场景对比Druid引擎有很大的性能优势,再加上Doris on ES的加持和上层业务的抽象,可以即拥有ES引擎强大的分词检索能力,又不失Olap场景海量数据的聚合分析性能。两者的结合可以为这类需求提供全新的解决方案与思路。
在快手商业化业务场景里面,维度数据与事实数据Join查询是非常普遍的,有了比较不错的实践成果,后续会在Doris on ES解决方案上继续投入。
