




导读
InnoDB Cluster是MySQL官方提供的完整的高可用解决方案。MySQL官方有两个Cluster概念很容易混淆,MySQL Cluster和InnoDB Cluster。MySQL Cluster指的是使用NDB引擎的分布式集群,InnoDB Cluster是由mysqlshell、mysql router、MGR三部分组成的具有高可用、一致性、便于管理等特点的数据库集群。下面的文章将从以下几方面介绍InnoDB Cluster: InnoDB Cluster整体结构、InnoDB Cluster部署、MySQL Shell管理集群、InnoDB Cluster限制和总结。
1
InnoDB Cluster整体结构

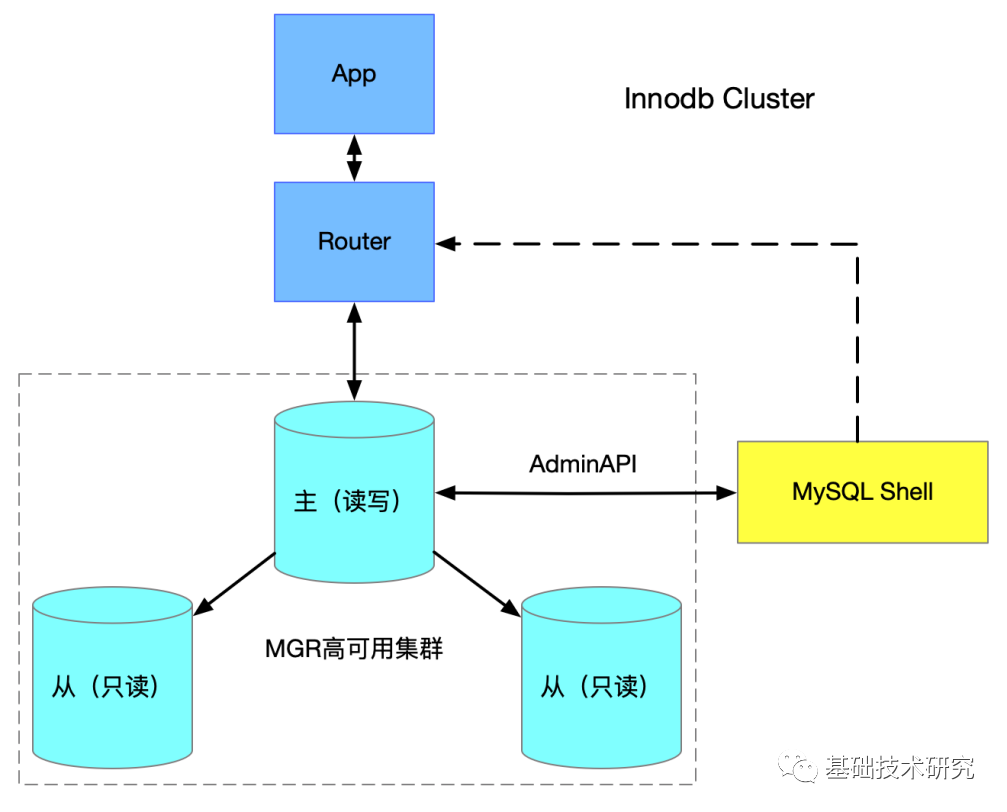
下图是InnoDB Cluster整体结构,MySQL Shell提供了管理员十分方便的接口对集群进行配置和管理。MySQL Router则可以根据Cluster集群元数据自动初始化配置信息,在默认单主模式下不用关心MGR故障切换,Router会自动发现集群的主已经切换,对应用来讲完全是透明的,不用关心集群的状态。MGR基于paxos协议交换节点状态信息,如果主节点发生故障集群会选出新主,基于paxos协议原子广播binlog到多数节点完成事务提交,为集群提供了容灾和数据强一致性。
2
InnoDB Cluster部署
主机名 | IP | MGR | Router | MySQLShell |
jc8c-0007 | 192.168.0.37 | Node1 | - | 安装 |
jc8c-0003 | 192.168.0.52 | Node2 | 安装 | 安装 |
jc8c-0008 | 192.168.0.82 | Node3 | - | 安装 |
2. 安装包准备
mysql-8.0.19-linux-glibc2.12-x86_64.tar.xz
mysql-shell-8.0.19-linux-glibc2.12-x86-64bit.tar.gz
mysql-router-8.0.19-linux-glibc2.12-x86_64.tar.xz






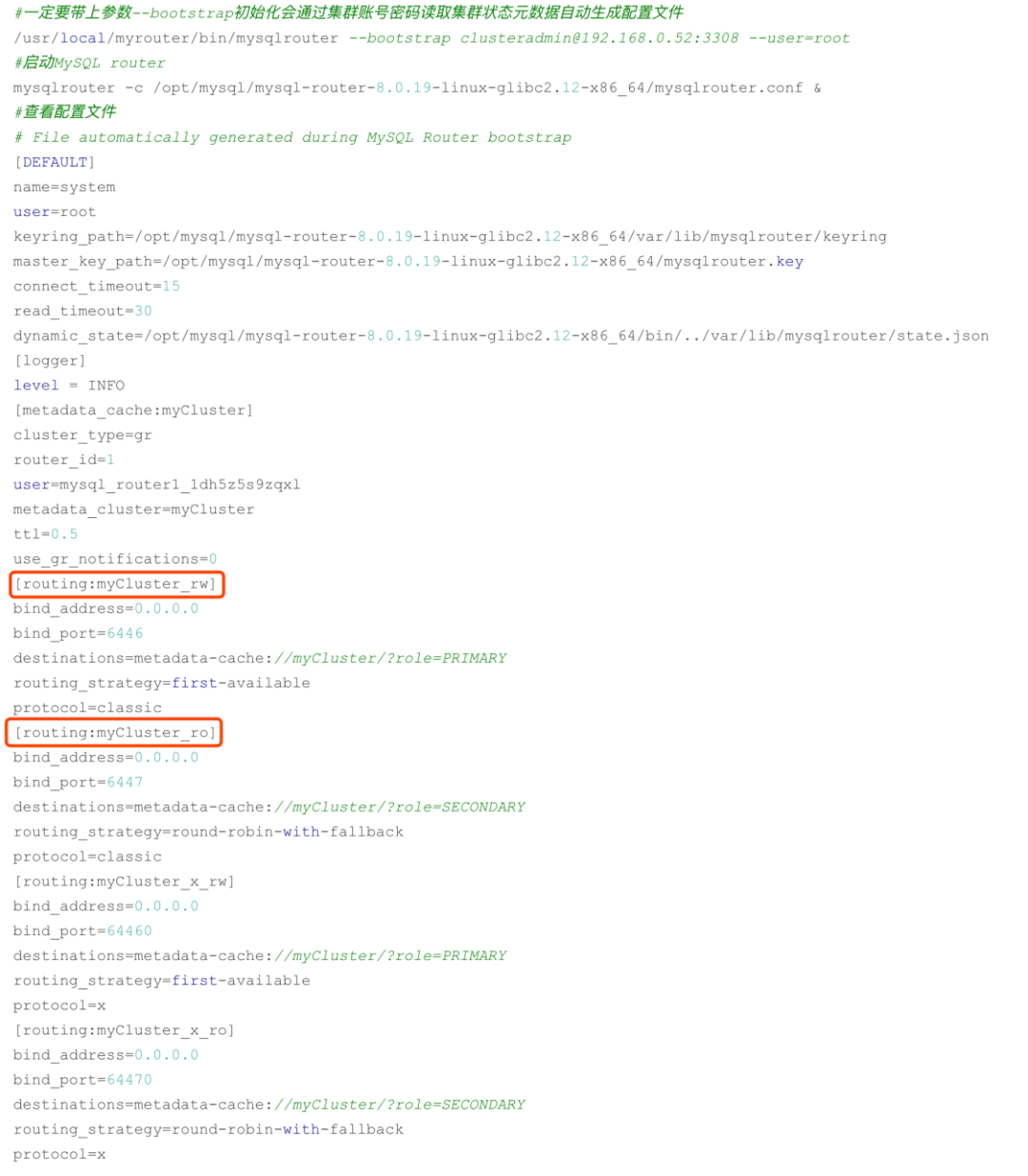
1)当MySQL Router初始化带上参数--bootstrap会自动到mysql_innodb_cluster_metadata库中读取集群状态信息,自动生成配置信息。
2)查看配置信息,可以看到读写端口6446,只读端口6447。针对文档存储的操作专门提供了支持X协议的端口64460、64470。
3)初始化过程中会创建router使用的账号:
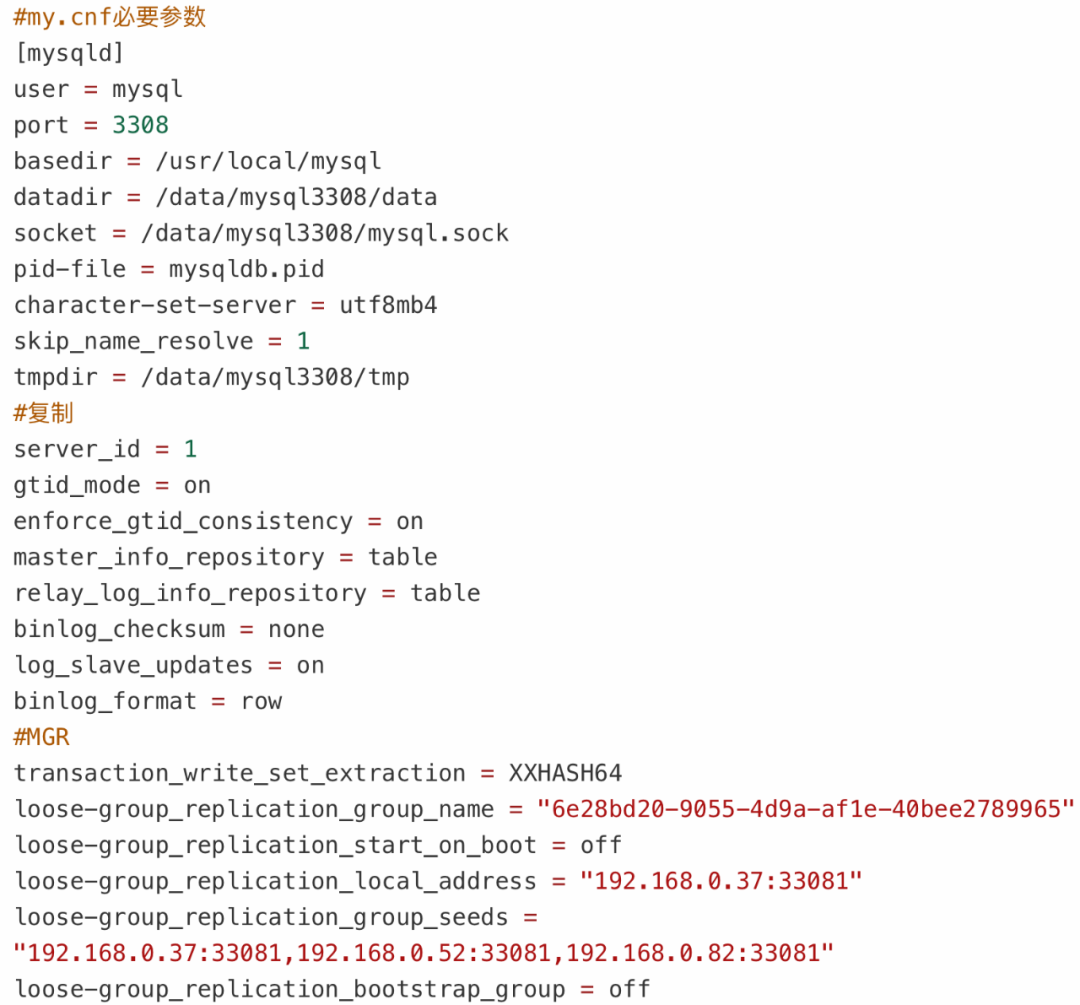
a) 参数server_id在集群成员间要设置不一样(例如:1、2、3)。
b) 参数binlog_checksum需要关掉,MGR暂时不支持。
c) group_replication_bootstrap_group参数要设置off,以免多台节点重启导致脑裂。
d) 当初始化完所有成员实例后,需要检查参数配置是否符合要求,dba.checkInstanceConfiguration(),如果不符合就会有对应提示,修改即可,如下图所示:
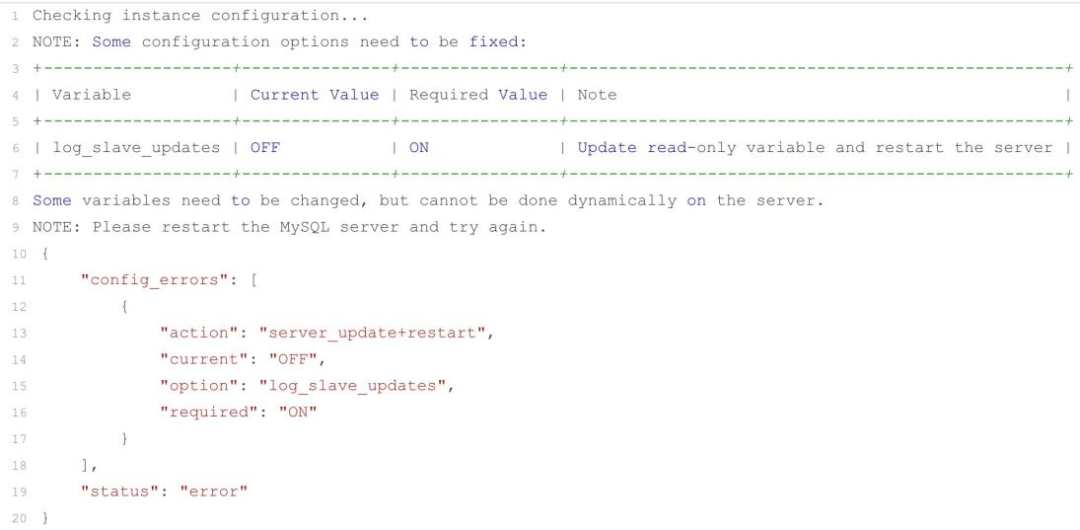
e) 添加成员节点时观察集群操作:
当修改完检查不符合要求的参数时,再次检查状态会显示ok:

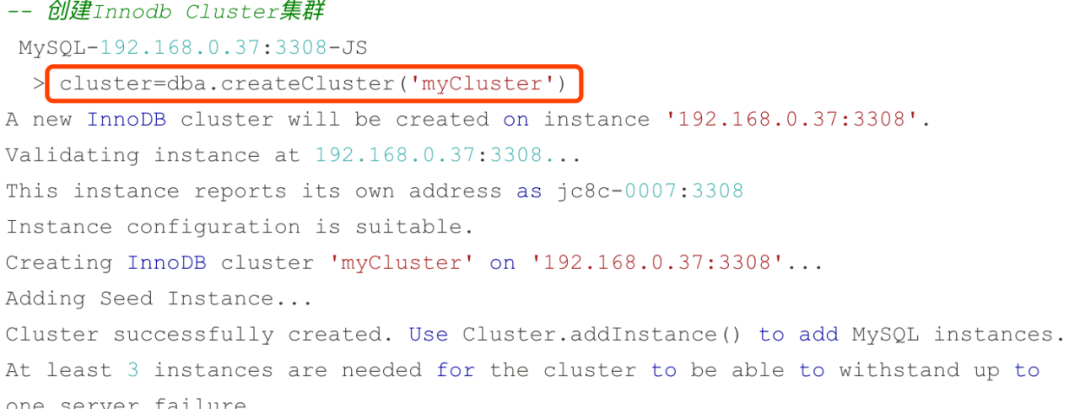
创建一个InnoDB集群myCluster成功后就可以添加集群实例了:
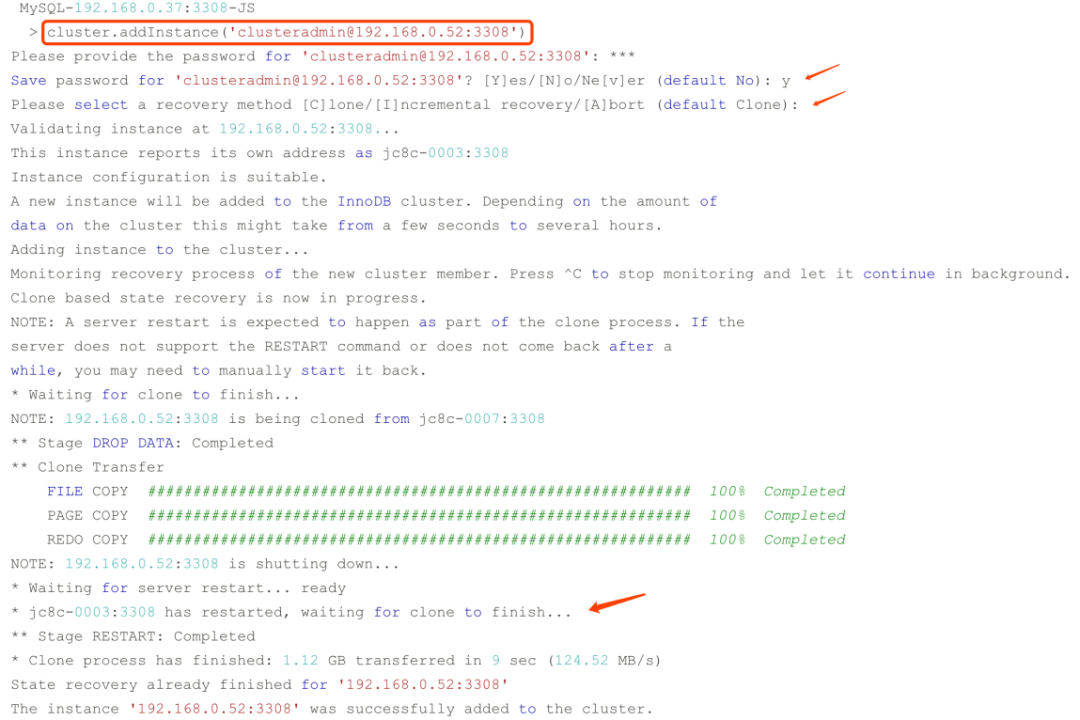
再添加节点的时候,会在输入集群账号密码时提示是否保存密码,选了yes,下次操作就可以免去输入密码。然后就开始从已有实例同步全量和增量数据加入集群,这个过程会用到之前文章介绍的clone插件,直接远程把数据复制到新加入的实例,然后重启加入集群。关于克隆组件原理,可以参考我上一篇文章《MySQL 8.0 新特性解读》。
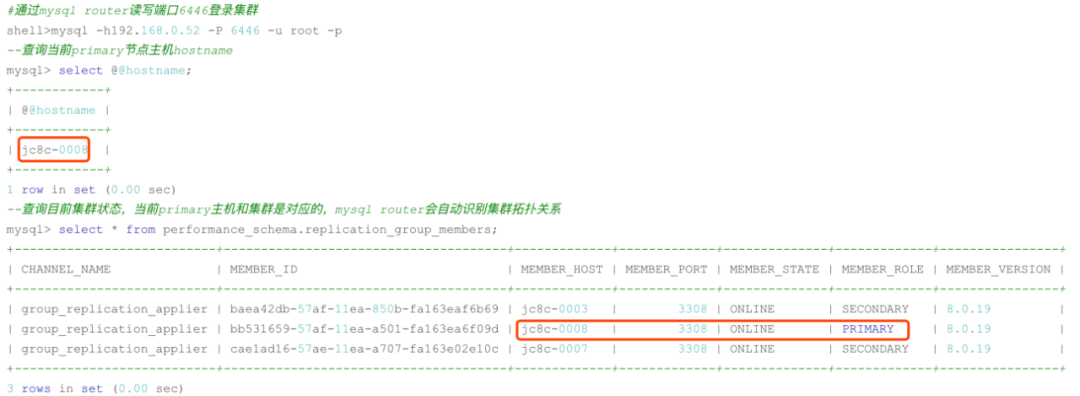
最后我们通过命令就可以看见集群状态信息了。可以看到集群名称、当前主实例是哪个节点、哪个节点是读写或者只读、集群是否可以failover、当前信息来源节点等。

3
MySQL Shell管理集群
上面已经全面介绍如何配置部署InnoDB Cluster,相信有过部署MGR经验的同学已经发现InnoDB Cluster配置部署真的方便不少。接下来我将会介绍一下如何使用mysqlshell管理集群。
1.使用MySQL Shell登录InnoDB Cluster集群
Shell>mysqlsh -h192.168.0.52 -P 6446 -u root -p
MySQL-192.168.0.52:6446-JS> cs =dba.getCluster()
2.下面介绍一下MySQL Shell内置一些函数作用
MySQL-192.168.0.52:6446-JS> cs.help()
#添加集群节点
addInstance(instance[, options])
#检查集群节点GTID状态
checkInstanceState(instance)
#显示集群拓扑结构
describe()
#断掉所有集群管理内部会话
disconnect()
#停用复制并从集群中注销节点
dissolve([options])
#从仲裁丢失中恢复群集
forceQuorumUsingPartitionOf()
#获取集群名字
getName()
#显示集群可配置参数
options([options])
#把节点重新加入集群
rejoinInstance(instance[,options])
#把节点从集群删掉
removeInstance(instance[, options])
#重新扫描集群拓扑信息
rescan([options])
#重置密码
resetRecoveryAccountsPassword(options)
#设置节点配置
setInstanceOption(instance,option, value)
#设置整个集群的配置
setOption(option, value)
#指定节点切换primary
setPrimaryInstance(instance)
#查看集群状态
status([options])
#切换集群模式为多主
switchToMultiPrimaryMode()
#切换集群模式为单主
switchToSinglePrimaryMode([instance])
3.通过Router的读写端口连接后,自动识别集群关系。MySQL Shell有三种交互方式分别是SQL、JS、Python,默认进入的JS使用方式和MongoDB类似。首先获取集群名称cs=dba.getCluster(),然后就可以通过变量cs.(内置方法)管理集群。

4
InnoDB Cluster限制
InnoDB Cluster下面使用的是MGR,所以使用集群的时候要注意MGR的使用限制,下面我会列举MGR存在的使用限制,以方便大家在使用过程中考虑如何设计自己架构:
所有涉及的数据都必须发生在InnoDB存储引擎的表内。 所有的表必须有明确的主键定义。 需要低延迟、高带宽的网络。 目前集群限制最多允许9个节点。 必须启用binlog。 binlog格式必须是row格式。 必须打开gtid模式。 复制相关信息必须使用表存储。 事务写集合(Transaction write set extraction)必须打开。 log slave updates必须打开。 binlog的checksum目前不支持。 SERIALIZABLE隔离级别目前不支持。 对同一个对象,在集群中不同的实例上,并行地执行DDL(哪怕是相互冲突的DDL)是可行的,但会导致数据一致性等方面的错误,目前阶段不支持在多节点同时执行同一对象的DDL。 外键的级联约束操作目前的实现并不完全支持,不推荐使用。 大事务支持并不友好,建议拆分大事务操作。
5
总 结
过去MGR | 现在InnoDB Clsuter |
添加一个新成员,需要主节点备份全量数据传输到新成员节点服务器上恢复 | 使用Clone插件,自动添加 |
配置复制账户、加入集群 | MySQL Shell 自动配置账号和加入集群 |
应用程序连接MGR需要手动配置第三方的接入层,例如:vip切换脚本、ProxySQL等 | 集成MySQL Router,只需要启动Router应用程序连接,应用无需要关心集群多拓扑变化 |
需要部署监控工具和查询每个成员节点的状态 | 使用MySQL Shell 命令直接可以查看集群状态,亦可以通过命令去切换主实例或者集群模式等 |
参考资料:
[1] MySQL官方手册。
