





异构数据库模型推演关键名词解释 异构数据库模型推演核心原理解析 模型推演的可维护性保障
01
关键名词解释
异构数据库模型推演:用以解决异构数据库间数据同步时目标库数据类型的“最佳选择”问题。 TapType:Tapdata 提供的中间数据类型,可在数据同步之前,将所有数据库类型转换成中间数据库类型,是介于源库和目标库之间的“中转站”。 模型推演算法:采用算分机制进行类型排序, 并返回最匹配数据类型,这个算法可以做到相对稳定。 模块单元测试:模型推演可维护性的解决方法,用以保障模型推演的可持续发展。
为什么需要异构数据库模型推演?
以 MongoDB 到 MySQL 的数据同步为例:

MongoDB 的数据类型

如上图所示,两个数据库之间的数据类型明显不同。假设现要将 MongoDB 中存在的 _id 数据 ObjectId、企业名称、企业创建日期、员工人数同步到 MySQL,就需要选择 MySQL 所适配的数据类型:
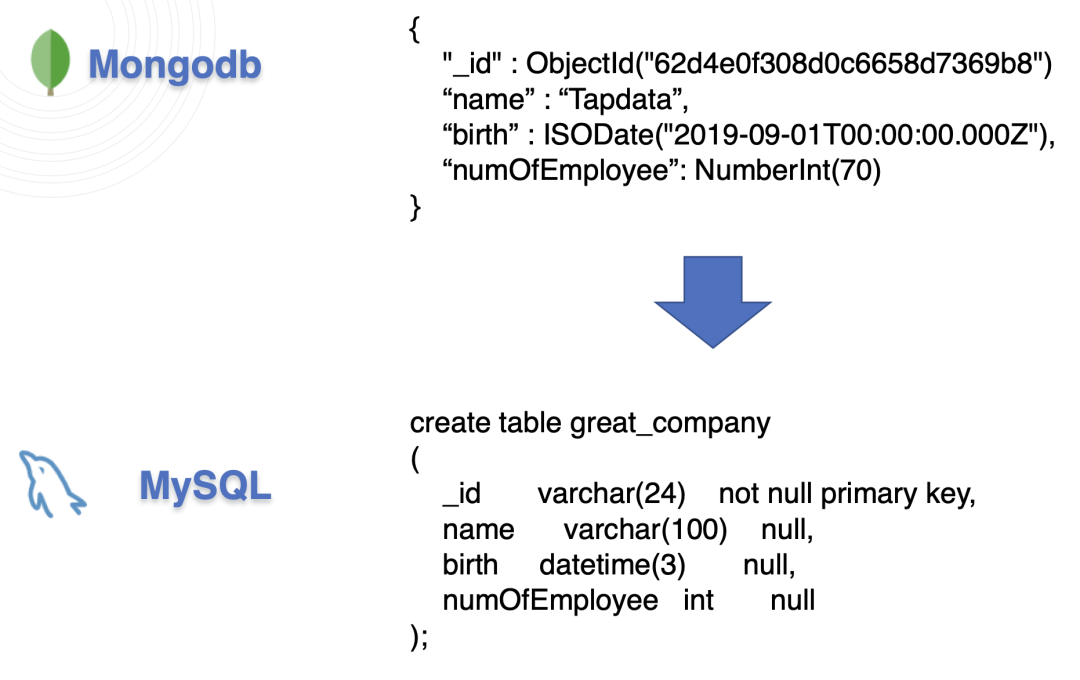
MongoDB 示例库表推演出 MySQL 的建表语句
02
核心思想:引入中间数据类型 TapType
那么我们为什么需要“创造”这样一种中间数据类型呢?
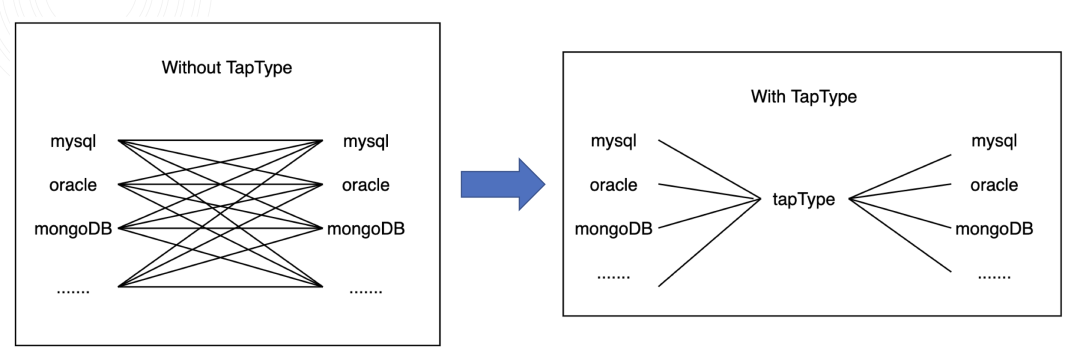
1. 通过 json key 类型表达式匹配数据库类型,json value 描述类型边界
2. 每种 TapType 类型自己专有的属性参数
3. 源库数据流入 Tapdata 引擎时,会对其做一层转换,然后再根据目标库所对应的 TapType 配置对数值进行再生成,这里涉及一个值转换过程。值转换采用 MongoDB 类似的 Codec 设计, 提供默认 Codec 和自定义 Codec 实现
4. 采用算分机制作为核心算法,为原表类型匹配目标表的最佳类型
如何使用中间类型 TapType?
1. 定义数据源的类型表达式以及边界描述

*表达式说明:
text相当于精准匹配,这里数据库类型就叫 text,最大边界是 4GB,优先级为 2,为中间类型TapString;
bit varying[($byte)]里的
byte是一个变量,是二进制的长度, 可以在创建表时指定,这里的
[]代表可有可无,在完全没有变量的情况下,就会采用 default 值,所以这部分的最大边界是64,没有
[]的情况就是 64,queryOnly=true 的含义是这个类型只会用于源表读取,目标建表就不会使用它来选择建表字段;
"value": [-2147483648, 2147483647]配置了最小、最大值。
2. 自定义 Codec,指定特定 TapType 类型采用什么数据库类型来接收并如何接收

*表达式说明:
https://tapdata.github.io/docs/Connectors/docs/data-type-expressions.html
推演模型模块划分
1. 如果出现没有映射到的数据库类型, 统一采用 TapRaw 去处理;
2. TapRaw 在目标端如果没有特殊定义, 选择目标库最大的字符串类型接收并且按对象 toString 做值转换(*注意:这一条特指在开发者不知道具体该如何做的情况下,我们通过找到最大字符串的办法来尽可能满足需求,但在实际操作过程中,最终结果往往不会特别好看,因此我们还是希望是大家在做类型描述时能够做到更加精准。当然,如果不可避免地出现这种情况,我们也会有日志打印出来);
3. 如果源库字段边界大于目标库所有字段时, 会选择不匹配里距离源库字段最接近的字段, 并会有警告记录;
4. 类型表达式大小写不敏感,但是对空格敏感。
1. 通过数据库模型对照表能更容易的发现模型推演的问题, 有助于尽早解决
2. 通过类型表达式能支持数据库类型的各种灵活写法
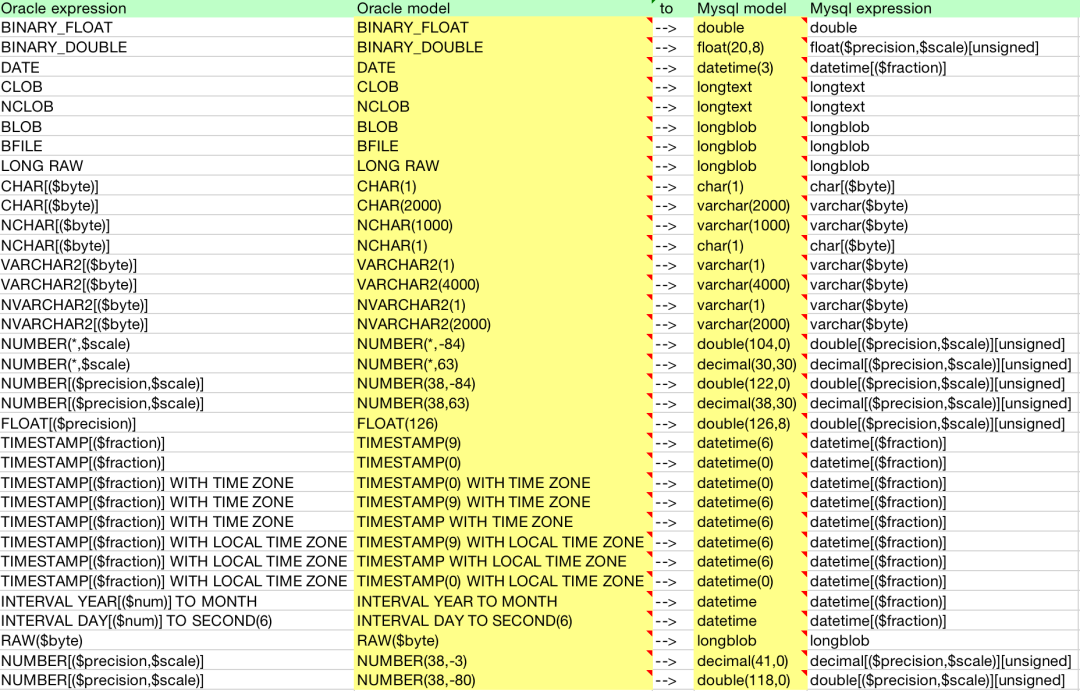
以 Oracle 到 MySQL 为例
以上表为例(Oracle → MySQL),我们会自动读取 PDK 的 Oracle.jar 和 MySQL.jar,并读出其中的类型表达式以及自定义值转换等相关干预,然后会将所有类型依次推演一遍。在这个过程中,我们会自动寻找这些变量边界的最小值和最大值以及中间值,然后自动生成一个类型,并推到目标数据库类型。这个表在这里更多扮演预览的角色,用于验证 Oracle 到 MySQL 的这些类型是否能推演,我们可以通过自身经验,来判断是否有出错的地方,再对应地去调整。
详解如何生成模型推演对照表,👆👆戳这里查看
cd 到 plugin-kit 目录下,执行指令: ./bin/pdk modelPrediction -o ./output ../connectors/dist/mongodb-connector-v1.0-SNAPSHOT.jar ../connectors/dist/mysql-connector-v1.0-SNAPSHOT.jar
03
综上所述,模型推演的实现无疑是一个相当复杂的过程。随着数据库类型的不断扩充,其逻辑复杂度也在不断提升,如何在这样的背景下始终确保模型推演的可维护性,也是我们不得不面对的一个问题。下面我们就站在软件工程的视角,来聊一聊我们将如何促成模型推演的可持续发展。
1. 模块初期只写主线单元测试, 把用 main 方法测试的习惯改到单元测试里, 不浪费
2. 当出现 bug 时,优先想着用单元测试的方式验证怀疑的 bug 逻辑, 即便不是这个模块的问题, 也积攒了一条测试用例
1. 新功能的改动影响到了旧功能的逻辑,单元测试发挥了最大价值, 避免被别人发现 bug
2. 可能是由于逻辑的变化, 这个测试用例跑不过是合情合理的, 那么就需要顺手把预期值修改一下, 继续保持单元测试的正确性
TapBoolean:布尔值 TapDate:日期
TapArray:数组
TapRaw:未知类型
TapNumber:数字
TapBinary:二进制
TapTime:时间
TapMap:Map 值
TapString:字符串
TapDateTime:日期+时间
TapYear:年
TapBooleanValue TapDateValue TapArrayValue TapRawValue TapNumberValue TapBinaryValue TapTimeValue TapMapValue TapStringValue TapDateTimeValue TapYearValue
而在进入目标库的 PDK Connector 时,我们会先把这些 TypeValue 再转换成为各自的原始值,让 PDK 的开发者把数据真实地写到目标库。
② 匹配过程
int[($bit)][unsigned][zerofill]为例:
[]
代表可有可无()
没有特殊含义$
代表指向一个变量,到符号结尾就会自动截断成为一个变量,此处意味着 bit 可能是 int(8)、int(32) ,或是 int(64)
intint(8)
int(32)
unsignedint(64)
unsigned zerofill
如此一来,就可以大大简化我们在处理类型映射时的书写复杂度。PDK 开发者们就需要用这个方式来描述我们的数据类型表达式的匹配关系。

"to"
是我们通用的一个最重要的 value 部分,需要由此来表明这个表达式应该去到什么样的 TapType 类型,属于必填关键字段。
{"name" : "typeName", Optional, name of data type, will display to users. If not specified, name will be generated automatically by removing all variables."queryOnly" : true, Optional, default is false. The type is only for query, will not be used for table creation."priority" : 1 Optional, default is Integer.MAX_VALUE. If source type matches multiple target types which is the same score (bit or bytes), then the target type will be selected when the priority is the smallest."pkEnablement" : true Optional, default is true. Whether the data type can be primary key or not.}
"name"
:给表达式起别名。在命名方面,我们会通过自动拆解表达式,默认 int 作为名字存在。但如果表达式写得比较复杂,拆解之后可能会变得不好看。这时就可以选择利用name
自定义一个别名;"queryOnly" : true
:任何 TapType 类型都适用,代表这是一个只用于查询的类型,即只会在查询时参考这些信息,在建表时则不会采用这个字段类型。例如在数据库中,存在一些聚合字段,或是一些不常用的字段、过期字段等,不希望将其用于建表,就可以通过这个方式过滤掉;"priority"
:现阶段用得并不是太多,大致了解即可,主要用于表示所有其他参数完全一致的情况下会优先选择谁;"pkEnablement"
:这是一个关键参数,表意为“能不能做主键”,在建表时,基于经验,我们会知道哪些适合建主件,而哪些不适合。这样的情况下,就需要我们给这些类型分别做上标记。在选择类型时,如果是主键,我们会选择"pkEnablement" : true
的那个类型去做推演运算;更多非通用字段解析,详见完整版视频回放,搭配文档食用效果更佳哦。 https://tapdata.github.io/docs/Connectors/docs/data-type-expressions.html
事实上,众多参数中,除了"to"
是必填项,其他都可选填,但大量不填的直接后果就是推演到目标类型的时候不精准。换言之,开发者输入的信息越多越精准,推演结果也就越精准。因此这里也要求开发者根据自身对数据库类型的理解,尽可能完成相关参数的精准填写。
https://www.github.com/tapdata/tapdata
如果您对我们的项目感兴趣,欢迎给 Tapdata 【Star+Fork+Watch】三连击

我们期待与您共创一个优秀的开源项目以及一个开放成熟的开源社区,见证实时数据的更多可能,下一期教程内容,或许就源自您提出的问题!

 入群彩蛋
入群彩蛋
活动结束了,还有问题没得到解答?别担心!在 Tapdata 社区群,开源项目核心成员将为大家线上答疑,帮助开发者们快速理清困惑。
与此同时,作为 Tapdata 社区活跃用户,你还可以:
获得 Tapdata 开源 Issue、需求的特殊优先级
第一时间收获社区最新资讯(包括但不限于开发计划、核心技术、业务场景等)
参与活动、领取开源体验官新手任务、获得商务双肩包、潮牌 T 恤等更多好礼
有机会受邀加入 Tapdata Committer Program,成为正式的 Tapdata Committer
有机会直接参与并影响 Tapdata 的未来走向
【推荐阅读】
↓↓ 点击 阅读原文 观看完整回放
