




作者:升雨
前言
PolarDB-X 2.0提供了透明分布式的能力,默认进行主键的哈希拆分,让用户无感知的从单机数据库迁移到分布式数据库。拆分键的选择是学术界和工业界研究已久的问题,一个重要选型是tp优先还是ap优先,两者难以同时兼顾。tp优先[1]的目的是减少分布式事务。filter优先,让sql尽量不跨库。ap优先[2]的目的是利用下推的优势,网络优化,优先处理等值join。PolarDB-X的主键拆分对于tp查询很友好,但对于ap查询并不友好。因此,在迁移PolarDB-X之后若发现默认的拆分方式不能满足ap需求,可以基于实际workload进行拆分键推荐,结合PolarDB-X的拆分变更能力进行智能的拆分键调整。
ap优先的拆分键推荐主要有两种方式:借助优化器[3]结果比较准确,但是运行时间太长,将优化器当成黑盒或深度修改优化器,相对快一点,但速度依然无法令人满意;不借助优化器[4]相对较快,但依然需要穷举所有的可能,且代价估不准。借助优化器的算法难以优化的原因是目标函数的结果无法预测,所以无法给出有效的剪枝。为了能够尽量快的进行推荐,PolarDB-X的拆分键推荐不借助优化器,少用统计信息,基于Amazon RedShift定义的问题设计了一个高效的推荐算法。
问题定义
本节内容参考自Amazon RedShift的论文[4]。
拆分键推荐
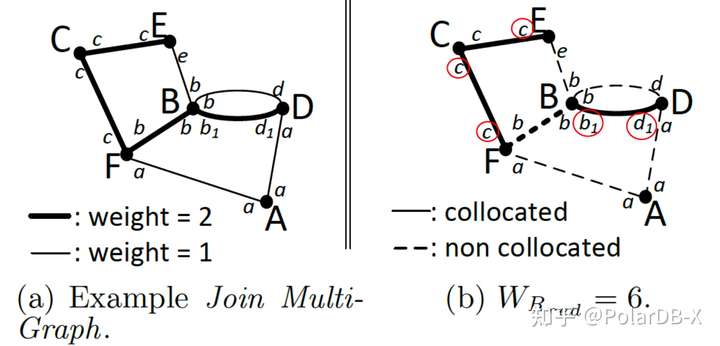
问题定义为每个表选择一个拆分列,使得可以节省的网络代价最大。join可下推需要两个表使用的拆分键恰好是这条边的两个列。下图(b)中A、B、C、D、E、F分别用a、b1、c、d1、c、c做拆分键,则<C,c,E,c,2>、<C,c,F,c,2>、<B,b1,D,d1,2>可以下推,这种拆分可以节省的代价为6。
Join Multi-Graph
给定n条查询,第i条查询被看作m个二元 join
构建Join Multi-Graph,每张表是一个点,每个jk是一条边,边上有两个列名和代价,下图(a)中最上面的一条边就是<C,c,E,c,2>。这个图可重边,例如BD之间就有两条边(因为列名不同)。
不可近似性
这个问题不可近似比为
RedShift的算法为整数线性规划,若超时则调用四个随机算法取个大的。这个算法的问题随机算法缺乏稳定性、超时无法自主控制。基于以上缺点,PolarDB-X设计了一个基于branch-and-bound的穷举算法。
算法设计
先看看暴力穷举的伪代码

这个算法的问题在于穷举到最后一张表才会做计算,很多拆分方案完全没用却被穷举了。从耗时就可以看出没有实际使用价值。
| 表 | 属性 | 时间(s) |
| 12表 8列 | 平均度数8 | 68.986 |
| redshift 13表 | 平均度数10 | 72.81 |
| 星状图 17表 | 平均度数16 | 32.696 |
对于这个算法运行过慢的问题,我们从以下四个层面进行优化。
基于branch-and-bound的穷举算法
对于一个穷举到表 level 的方案
1. 当前P的weight。
2. col导致的weight。
3. 表level+1到表|V|的最佳方案的weight。
4. 表level+1到表|V|的只考虑Shard导致的最佳方案的weight,即每张表分别选最优列(区间求和)。
3与4的方案可能不是同一个方案,但 1+2+3+4 的值绝对是一个上界。 计算层面,3是由exactSearch函数里倒序搜索直接迭代计算出来的。1,2,4可以在穷举Shard时在search函数中进行维护,用树状数组维护4的区间和,每个表的max值用数组记录。


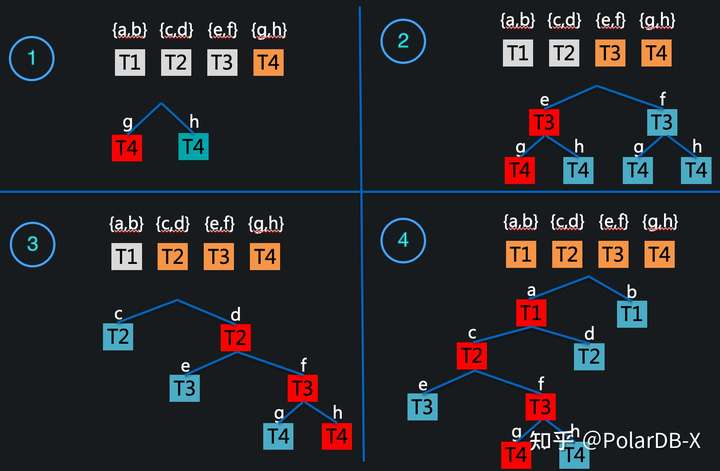
exactSearch 与 naiveSearch 相比看上去搜索空间变大了,但这是剪枝的关键。 下图是一个剪枝的示例,T1可选拆分键为 {a,b},T2可选拆分键为 {c,d},T3可选拆分键为 {e,f},T4可选拆分键为 {g,h} ,4张子图分别代表exactSearch函数2-7行的4次循环,即选择T4的最佳拆分键、选择T3,T4的最佳拆分键、选择T2,T3,T4的最佳拆分键、选择T1,T2,T3,T4的最佳拆分键。红色节点为当前表集的最佳拆分方案,图3得出的,T2,T3,T4的最佳拆分键是{d,f,h}。蓝色为搜索过程中访问到的节点,未遍历到底的节点就是被剪枝的部分。图4中,穷举到 T1=a,T2=d 发现有 upperBound(T1=a,T2=d)<OPT,则进行了剪枝,不再穷举T3,T4的拆分键。
剪枝的能力由upperBound函数、OPT的大小决定,以下加强剪枝的能力。
穷举顺序改成
穷举顺序对于暴力搜索的速度影响很大,例如clique列举问题中的各种启发式[5]。考虑度数为{1,9,10}的列表,列表{10,9,1}的总穷举数为
OPT优化
计算出比较大的OPT可加强剪枝的能力。 在extraSearch每轮循环开始时穷举level表所有可拆分的列与后续表的最优方案拼接,初始化一个较大的OPT。 在search函数中将shard与Lopt[level+1]进行拼接得到一个较大的OPT。
这两个优化可以直接得到拆分方案,实际上是期望中真正计算出拆分方案的地方,而非依靠穷举到最后一张表。

自适应近似
以上提出的剪枝策略并不能改变np-难问题的本质,所以使用近似加速剪枝,即剪枝修改为
其他
算法可能找到一个执行计划,使得有些表无法被下推,这样的表与未被join的表一起先用filter的列做拆分键。否则回退到主键拆分。 另外行数小于阈值的表会被直接推荐为广播表,不参与拆分键推荐的过程。 由于整个算法不借助优化器,生成的计划并不一定会变优,所以最后会有一个whatif的过程计算拆分方式变更前后优化器计算出的sql代价的变化。如果评估发现代价并没有变优,系统会放弃此次推荐的结果。
仿真验证
| 表 | 属性 | 时间(s) |
| 35表 8列 | 平均度数8 | 22.058 |
| 45表 8列 | 平均度数8 | 58.575 |
| redshift 30表 | 平均度数10 | 61.344 |
| redshift 40表 | 平均度数10 | 98.689 |
| redshift 60表 | 平均度数4 | 15.98 |
| 星状图 81表 | 平均度数16 | 17.041 |
| 星状图 101表 | 平均度数16 | 23.012 |
使用示例
在PolarDB-X中使用拆分键推荐,只需要在对应的库中输入sql“sharingadvise”即可(由于需要调用plan cache中的sql作为workload且算法对于CN压力较大,建议在压测阶段进行拆分键推荐)。
以下为workload为tpcc 100仓时基于plan cache进行拆分键推荐的过程演示。
| 属性 | 配置 |
| PolarDB-X | polarx-kernel_5.4.14-16601976_xcluster-20220728 |
| CN | 2台4C32G |
| DN | 2台4C32G |
| TPCC | 100仓 |
| 拆分方式 | auto库随机key拆分 |
| warehouses | 100 |
| terminals | 50 |
| runMins | 30 |
| limitTxnsPerMin | 0 |
| terminalWarehouseFixed | true |
| newOrderWeight | 45 |
| paymentWeight | 43 |
| orderStatusWeight | 4 |
| deliveryWeight | 4 |
| stockLevelWeight | 4 |
初始的情况

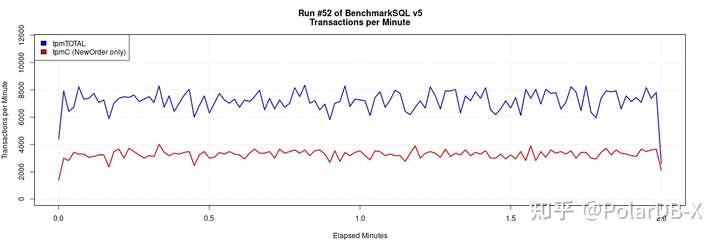
压测结果
拆分键推荐
sharingadvise指令会根据plan cache给出相关的sql建议以及预计的代价变化。

执行上面推荐出来的拆分键变更语句

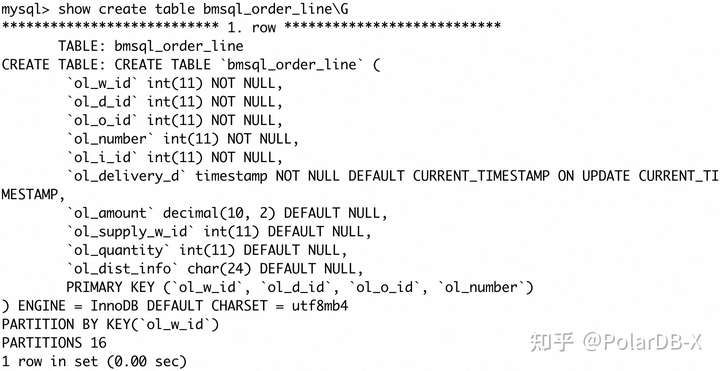
验证拆分键变化
再次压测TPCC,tpmC提升至8倍
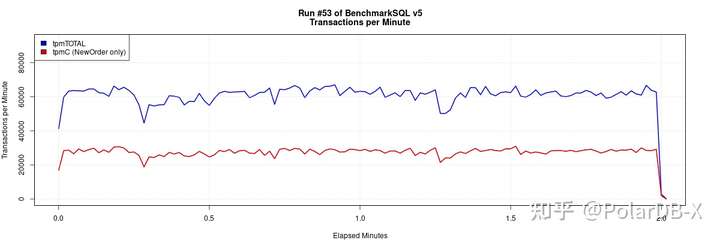
总结
从上面的实验可以发现,即使是tp查询,错误的拆分键也会因为大量引入分布式事务导致性能受到很大的影响。PolarDB-X“手自一体”的方案对于拆分键的选择有一定要求,拆分键推荐提供了手动选择拆分键的方案,减轻人力负担。
参考文献
[1] Andrew Pavlo, Carlo Curino, and Stanley Zdonik. 2012. Skew-aware automatic database partitioning in shared-nothing, parallel OLTP systems. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data (SIGMOD '12). Association for Computing Machinery, New York, NY, USA, 61–72.
[2] Erfan Zamanian, Carsten Binnig, and Abdallah Salama. 2015. Locality-aware Partitioning in Parallel Database Systems. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD '15). Association for Computing Machinery, New York, NY, USA, 17–30.
[3] Rimma Nehme and Nicolas Bruno. 2011. Automated partitioning design in parallel database systems. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of data (SIGMOD '11). Association for Computing Machinery, New York, NY, USA, 1137–1148.
[4] Panos Parchas, Yonatan Naamad, Peter Van Bouwel, Christos Faloutsos, and Michalis Petropoulos. 2020. Fast and effective distribution-key recommendation for amazon redshift. Proc. VLDB Endow. 13, 12 (August 2020), 2411–2423.
[5] Rong-Hua Li, Sen Gao, Lu Qin, Guoren Wang, Weihua Yang, and Jeffrey Xu Yu. 2020. Ordering heuristics for k-clique listing. Proc. VLDB Endow. 13, 12 (August 2020), 2536–2548.
[6] Carlo Curino, Evan Jones, Yang Zhang, and Sam Madden. 2010. Schism: a workload-driven approach to database replication and partitioning. Proc. VLDB Endow. 3, 1–2 (September 2010), 48–57
文章来源:阿里云数据库
