





栗友们,大家好!我是Zarc~
上篇讲到NER任务的BIO做法,这次来介绍一下基于Span的做法
01
—
背景
首先回顾下BIO方法,BIO的本质就是序列标注,在中文NER任务中就是对每个字的类别进行判断,最终达到对实体进行识别的目的,而Span方法在我看来就是直接判断某一个文本片段是否属于某一类别。
上期说到,在实体识别的时候会遇到嵌套的情况,也就是说某个token可能对应多个实体类别标签的情况,BIO 的做法是采用二元标注或者多头标注这种方法,但是不可避免带来一系列新的问题,对于Span方法而言,这种嵌套问题可以轻易解决。
还是看上期的例子:
六只栗子都喜欢周杰伦、张学友的音乐和电影。
预先定义的实体类别有:【人物、艺术、地点、国籍】
这个时候实体识别结果为:
人物:六只栗子、周杰伦、张学友
艺术:周杰伦的音乐、周杰伦的电影、张学友的音乐、张学友的电影
上面的例子中的艺术实体 张学友的音乐 中嵌套了人物实体 张学友,BIO做法需要多元标注来解决这个问题,Span在处理这段文本的策略是先枚举所有可能存在的连续文本片段,这些片段中肯定也是包含了 张学友、张学友的音乐这两个片段,然后对这些所有的片段进行预测类别,最终得到答案。所以基于Span的方法的目的就是预测出某个实体的边界以及它的实体类别,有点文本分类的味道了。
02
—
问题
不过,聪明的栗友很快就发现了上面做法的问题
首先是枚举出所有可能的实体片段这一条,如果是短文本还好,一旦文本比较长,那一段文本所包含的所有可能的实体片段就会非常的多,这么多的实体里面所包含的正样本是十分有限的,也就是会出现大量的片段是负样本,这样模型在训练的时候,收敛起来会十分缓慢。 可能存在两个相邻的片段,比如说 <张学友,张学友的>这两个实体,一个属于人物类别,一个不属于人物类别,模型在预测时,前者的人物类别置信度为1,后者为0,这种方式虽然从结果上来看没有任何问题,但是会影响神经网络的可训练性,这一点在前两期的SpERT模型中就遇到了,模型收敛起来会很慢。
上述的第一个问题还比较容易解决,可以通过设定一段文本中的最大负样本数量和片段的长度来避免正样本的稀疏性,但是关于第二个问题,目前Span做法的目的就是清晰地预测出实体边界和实体类别,有没有什么好的方案来避免这个问题呢?
03
—
方案
下面带来两篇今年的最新基于Span的NER方案:《Boundary Smoothing for Named Entity Recognition》和 《UNIRE: A Unified Label Space for Entity Relation Extraction》
Boundary Smoothing for Named Entity Recognition[1]
这篇文章主要是提出了一种实体边界平滑策略,对NER标签的边界位置进行平滑处理,提升模型的泛化性,边界平滑可以防止模型对预测实体过于自信,从而获得更好的定标效果。具体做法包含以下两部分:
这种方式可以防止模型将所有的概率质量都集中在稀缺的正样本上面,有助于缓解模型的过度自信。
提出了一种双仿射网络来分别解码输入文本的表示序列 ,这个双仿射网络类似于两个前馈网络,得到的两个表示分别对应实体的开始和结束位置,在实体类型的分类上面,会融合这段文本的开始位置表示、结束位置表示和这段文本的语义表示,然后使用softmax得到对应类别的概率。
对实体边界进行了平滑处理,在之前的做法中,每个带标注的实体边界的边界概率为1,而其相邻的非边界token的边界概率为0,被称为硬边界,如图(a),这里平滑的做法就是拿出带标注的实体边界的一部分边界概率 拿出来平均分配给周围一定距离的非边界token,而这个带标注的边界token的边界概率变成了 1 - ,这样就达到了边界平滑的目的,如图(b)。
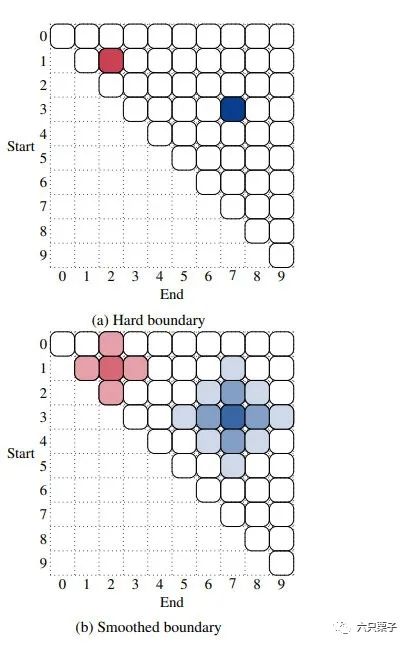
边界平滑示意图 UNIRE: A Unified Label Space for Entity Relation Extraction[2]
这篇文章的主要思想是构建词与词之间的关系来达到识别实体的目的,既能够做实体识别,也可以做关系抽取,这里只介绍实体识别的做法,首先看下网络架构图:
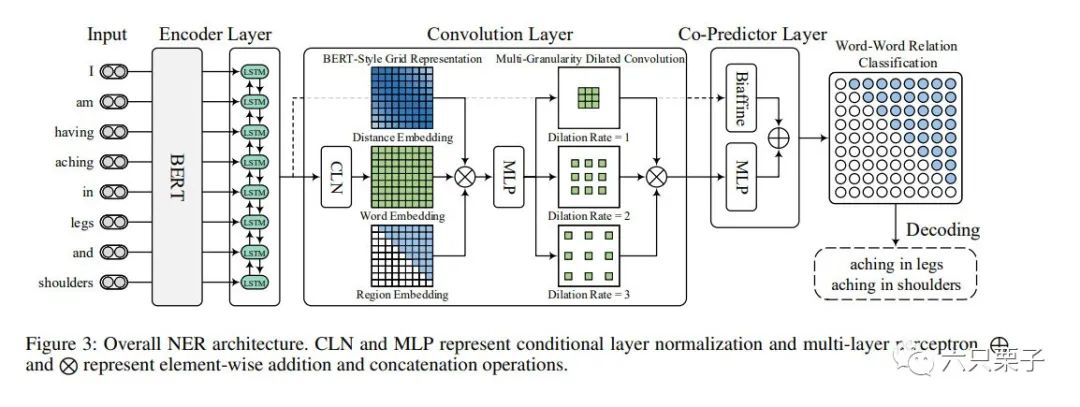
W2NER网络架构图
Encoder部分,Encoder部分采用的是BERT,再用双向LSTM进一步加强上下文表示, 卷积模块,卷积模块的主要作用是将token序列建模为word-word的网络表征,这里是一个2D结构,它主要包含三个部分: Conditional Layer Normalization(CLN):用于生成词对网络表示的归一化条件层,对Encoder部分输出的词向量,经过CLN层,可以得到文本中的词对表示(就是任意两个token之间的关系) BERT-Style Grid Representation:BERT 样式的网格表示构建以丰富词对的表示网格,根据Bert的三个输入token embeddings、position embeddings和segment embeddings,分别对单词、位置和句子信息进行建模。这里采用类似的思想,利用三个网络分别获得token之间的相对位置信息、token表示、CLN网络中的上三角区域信息,连接这三种表示并且采用多层感知器网络(MLP)来减少它们的维度信息获得网络中的位置区域感知表示。 Multi-Granularity Dilated Convolution:为了捕获近距离和远距离单词之间的交互的多粒度扩张卷积,采用具有不同扩张率 (膨胀率)(例如,)的多个二维扩张卷积 来捕捉不同距离的单词之间的交互,因为模型的目标是预测这些词之间的关系。 Co-Predictor Layer联合预测层 ,在卷积模块之后,获得了词对网格表示 ,使用 MLP 预测每对token之间的关系。通过与用于关系分类的(Biaffine Predictor)双仿射预测器合作来增强 MLP 预测器(基于词对网格表示的 MLP 预测器)。因此,同时采用这两个预测器来计算词对 ( ) 的两个独立关系分布,并将它们组合为最终预测。
04
—
总结
总的来说,基于Span和基于BIO的方案各有千秋,两者的使用体验来看的话,BIO方案对于简单任务的效果很好,收敛也很快,Span的方案能够胜任那些复杂任务,但是效果要看具体的任务情况,我个人还是更喜欢Span的方案一些~
好了,NER任务的两种主要方案就介绍完了,其实还有那些基于机器阅读理解的做法,有兴趣的栗友也可以去查阅一下相关资料,相信这些应该是可以让你在面试中游刃有余了
最后,关注六只栗子,面试不迷路~
05
—
参考资料
Boundary Smoothing for Named Entity Recognition: https://arxiv.org/pdf/2204.12031.pdf
[2]UNIRE: A Unified Label Space for Entity Relation Extraction: https://arxiv.org/abs/2107.04292
作者 Zarc
编辑 一口栗子




