




“ 上节主要讲了数仓中几个模型,及其atlas元数据管理。这一节我们来讲面试题中常见的其它问题,比如几种常见的表,拉链表怎么处理,还有缓慢变化维”
问题:
数仓各层中分别用了哪些表类型(流水、快照、拉链),拉链表增量更新与回滚整明白
重点
01
—
数仓各层的表类型
数据仓库之拉链表,流水表,全量表,增量表
全量表:每天的所有写最新状态的数据
1、有无变化,都要报
2、每次上报的数据都是所有的数据(变化的+没有变化的)
增量表:新增的数据
1、增量表,只报变化量,无变化不用报
拉链表:
1、记录一个事物从开始,一直到当前状态的所有变化的信息
2、拉链表每次上报的都是历史记录的最终状态,是记录在当前时候的历史总量
流水表:对于表的每一个修改都会记录,可以用户反映实际记录的变更
1、拉链表通常是对账户信息的历史变动进行处理保留的结果,流水表是对每天的交易形成的历史
2、流水表用于统计业务相关情况,拉链表用于统计账户及客户的情况
快照表:数据包含前一天的全量数据,按照每一天进行分区
所有表的优缺点对比:
全量表:可存放最新记录和历史,但是存储消耗大。
快照表:也可以查看历史记录,但是存储消耗大。
拉链表:既可以满足查看历史记录,又可以减少存储消耗。
流水表:在拉链表基础上当需要知道更细的修改记录时,需查看流水表。
增量表:适合订单等存储,而流水表更倾向于用户信息等的变更,两者应用环境不同。
拉链表的应用案例:
案例:
一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G,在HDFS使用双备份或者三备份的话就更大一些。
表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
需求:
需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
方案比较:
方案一:每天只留最新的一份,比如我们每天用Sqoop抽取最新的一份全量数据到Hive中。
每天drop掉前一天的数据,重新抽一份最新的。
优点:节省数据存储空间,使用数据不用加分区
缺点:没有历史数据,数据资产不完整
方案二:
优点:每天一份全量的切片是一种比较稳妥的方案,而且历史数据也在。
缺点:有部分数据每天都是重复的,存储空间占用量太大太大了,如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费。
方案三:
1、记录一个事物从开始,一直到当前状态的所有变化的信息
2、拉链表每次上报的都是历史记录的最终状态,是记录在当前时候的历史总量
如何设计一张拉链表?
在2017-01-01这一天表中的数据是:
注册日期 用户编号 手机号码
2017-01-01 001 111111
2017-01-01 002 222222
2017-01-01 003 333333
2017-01-01 004 444444
在2017-01-02这一天表中的数据是, 用户002和004资料进行了修改,005是新增用户:
注册日期 用户编号 手机号码 备注
2017-01-01 001 111111
2017-01-01 002 233333 (由222222变成233333)
2017-01-01 003 333333
2017-01-01 004 432432 (由444444变成432432)
2017-01-02 005 555555 (2017-01-02新增)
在2017-01-03这一天表中的数据是, 用户004和005资料进行了修改,006是新增用户:
注册日期 用户编号 手机号码 备注
2017-01-01 001 111111
2017-01-01 002 233333
2017-01-01 003 333333
2017-01-01 004 654321 (由432432变成654321)
2017-01-02 005 115115 (由555555变成115115)
2017-01-03 006 666666 (2017-01-03新增)
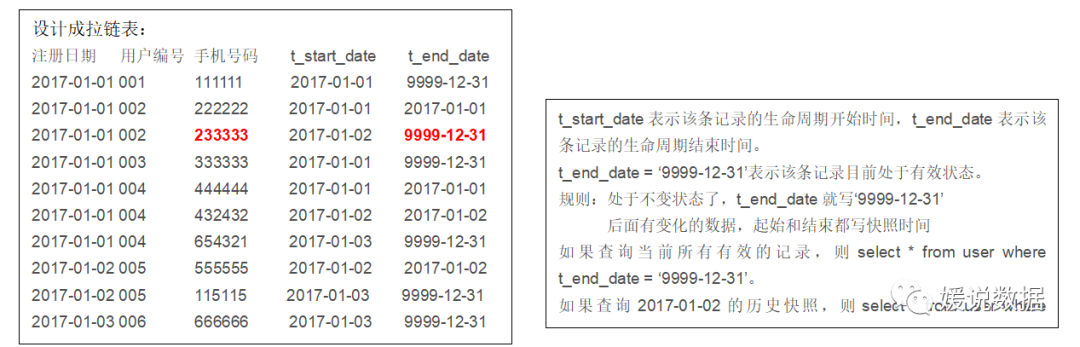
如果在数据仓库中设计成历史拉链表保存该表,则会有下面这样一张表,这是最新一天(即2017-01-03)的数据:
注册日期 用户编号 手机号码 t_start_date t_end_date
2017-01-01 001 111111 2017-01-01 9999-12-31
2017-01-01 002 222222 2017-01-01 2017-01-01
2017-01-01 002 233333 2017-01-02 9999-12-31
2017-01-01 003 333333 2017-01-01 9999-12-31
2017-01-01 004 444444 2017-01-01 2017-01-01
2017-01-01 004 432432 2017-01-02 2017-01-02
2017-01-01 004 654321 2017-01-03 9999-12-31
2017-01-02 005 555555 2017-01-02 2017-01-02
2017-01-02 005 115115 2017-01-03 9999-12-31
2017-01-03 006 666666 2017-01-03 9999-12-31

ods层的用户资料切片表:
CREATE EXTERNAL TABLE ods.user ( user_num STRING COMMENT '用户编号', mobile STRING COMMENT '手机号码', reg_date STRING COMMENT '注册日期'COMMENT '用户资料表'PARTITIONED BY (dt string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'STORED AS ORC LOCATION '/ods/user';)
ods层的user_update表:
CREATE EXTERNAL TABLE ods.user_update ( user_num STRING COMMENT '用户编号', mobile STRING COMMENT '手机号码', reg_date STRING COMMENT '注册日期'COMMENT '每日用户资料更新表'PARTITIONED BY (dt string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'STORED AS ORC LOCATION '/ods/user_update';)
拉链表:
CREATEEXTERNALTABLE dws.user_his ( user_num STRING COMMENT '用户编号', mobile STRING COMMENT '手机号码', reg_date STRING COMMENT '用户编号', t_start_date , t_end_date )COMMENT '用户资料拉链表'ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t' LINES TERMINATED BY'\n'STORED AS ORC LOCATION '/dws/user_his';
假设我们已经已经初始化了2017-01-01的日期,然后需要更新2017-01-02那一天的数据:
INSERT OVERWRITE TABLE dws.user_his
SELECT * FROM (
SELECT
A.user_num,
A.mobile,
A.reg_date,
A.t_start_time,
CASE WHEN A.t_end_time = '9999-12-31' AND B.user_num IS NOT NULL THEN '2017-01-01' ELSE
A.t_end_time END AS t_end_time
FROM dws.user_his AS A LEFT
JOIN
ods.user_update AS B ON A.user_num = B.user_num UNION SELECT C.user_num, C.mobile, C.reg_date, '2017-01-02' AS t_start_time, '9999-12-31' AS t_end_time FROM ods.user_update AS C ) AS T
拉链表增量更新和回滚:
| 订单创建日期 | 订单编号 | 订单状态 |
| 2012-06-20 | 001 | 创建订单 |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
| 订单创建日期 | 订单编号 | 订单状态 |
| 2012-06-20 | 001 | 支付完成(从创建到支付) |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
| 2012-06-21 | 004 | 创建订单 |
| 2012-06-21 | 005 | 创建订单 |
| 订单创建日期 | 订单编号 | 订单状态 |
| 2012-06-20 | 001 | 支付完成(从创建到支付) |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 已发货(从支付到发货) |
| 2012-06-21 | 004 | 创建订单 |
| 2012-06-21 | 005 | 支付完成(从创建到支付) |
| 2012-06-22 | 006 | 创建订单 |
| 订单创建日期 | 订单编号 | 订单状态 | dw_begin_date | dw_end_date |
| 2012-06-20 | 001 | 创建订单 | 2012-06-20 | 2012-06-20 |
| 2012-06-20 | 001 | 支付完成 | 2012-06-21 | 9999-12-31 |
| 2012-06-20 | 002 | 创建订单 | 2012-06-20 | 9999-12-31 |
| 2012-06-20 | 003 | 支付完成 | 2012-06-20 | 2012-06-21 |
| 2012-06-20 | 003 | 已发货 | 2012-06-22 | 9999-12-31 |
| 2012-06-21 | 004 | 创建订单 | 2012-06-21 | 9999-12-31 |
| 2012-06-21 | 005 | 创建订单 | 2012-06-21 | 2012-06-21 |
| 2012-06-21 | 005 | 支付完成 | 2012-06-22 | 9999-12-31 |
| 2012-06-22 | 006 | 创建订单 | 2012-06-22 | 9999-12-31 |
| 订单创建日期 | 订单编号 | 订单状态 | dw_begin_date | dw_end_date |
| 2012-06-20 | 001 | 支付完成 | 2012-06-21 | 9999-12-31 |
| 2012-06-20 | 002 | 创建订单 | 2012-06-20 | 9999-12-31 |
| 2012-06-20 | 003 | 支付完成 | 2012-06-20 | 2012-06-21 |
| 2012-06-21 | 004 | 创建订单 | 2012-06-21 | 9999-12-31 |
| 2012-06-21 | 005 | 创建订单 | 2012-06-21 | 2012-06-21 |
| 订单创建日期 | 订单编号 | 订单状态 |
| 2012-06-20 | 001 | 支付完成(从创建到支付) |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
| 2012-06-21 | 004 | 创建订单 |
| 2012-06-21 | 005 | 创建订单 |
CREATE TABLE orders (
orderid INT,
createtime STRING,
modifiedtime STRING,
status STRING
) stored AS textfile; CREATE TABLE t_ods_orders_inc (
orderid INT,
createtime STRING,
modifiedtime STRING,
status STRING
) PARTITIONED BY (day STRING)
stored AS textfile;
CREATE TABLE t_dw_orders_his (
orderid INT,
createtime STRING,
modifiedtime STRING,
status STRING,
dw_start_date STRING,
dw_end_date STRING
) stored AS textfile; INSERT overwrite TABLE t_ods_orders_inc PARTITION (day = ‘2015-08-20′)
SELECT orderid,createtime,modifiedtime,status
FROM orders
WHERE createtime <= ‘2015-08-20′;INSERT overwrite TABLE t_dw_orders_his
SELECT orderid,createtime,modifiedtime,status,
createtime AS dw_start_date,
‘9999-12-31′ AS dw_end_date
FROM t_ods_orders_inc
WHERE day = ‘2015-08-20′;spark-sql> select * from t_dw_orders_his;
1 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
2 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
3 2015-08-19 2015-08-21 支付 2015-08-19 9999-12-31
4 2015-08-19 2015-08-21 完成 2015-08-19 9999-12-31
5 2015-08-19 2015-08-20 支付 2015-08-19 9999-12-31
6 2015-08-20 2015-08-20 创建 2015-08-20 9999-12-31
7 2015-08-20 2015-08-21 支付 2015-08-20 9999-12-31
Time taken: 2.296 seconds, Fetched 7 row(s)INSERT overwrite TABLE t_ods_orders_inc PARTITION (day = '${day}')
SELECT orderid,createtime,modifiedtime,status
FROM orders
WHERE createtime = '${day}' OR modifiedtime = '${day}';INSERT overwrite TABLE t_ods_orders_inc PARTITION (day = '2015-08-21')
SELECT orderid,createtime,modifiedtime,status
FROM orders
WHERE createtime = '2015-08-21' OR modifiedtime = '2015-08-21';spark-sql> select * from t_ods_orders_inc where day = '2015-08-21';
3 2015-08-19 2015-08-21 支付 2015-08-21
4 2015-08-19 2015-08-21 完成 2015-08-21
7 2015-08-20 2015-08-21 支付 2015-08-21
8 2015-08-21 2015-08-21 创建 2015-08-21
Time taken: 0.437 seconds, Fetched 4 row(s)
DROP TABLE IF EXISTS t_dw_orders_his_tmp;
CREATE TABLE t_dw_orders_his_tmp
AS
SELECT
orderid,
createtime,
modifiedtime,
status,
dw_start_date,
dw_end_date
FROM
(SELECT
a.orderid,
a.createtime,
a.modifiedtime,
a.status,
a.dw_start_date,
CASE WHEN b.orderid IS NOT NULL AND a.dw_end_date > '2015-08-21' THEN '2015-08-20' ELSE a.dw_end_date END AS dw_end_date
FROM t_dw_orders_his a
left outer join (SELECT * FROM t_ods_orders_inc WHERE day = '2015-08-21') b
ON (a.orderid = b.orderid)
UNION ALL
SELECT
orderid,
createtime,
modifiedtime,
status,
modifiedtime AS dw_start_date,
'9999-12-31' AS dw_end_date
FROM t_ods_orders_inc
WHERE day = '2015-08-21'
) x
ORDER BY orderid,dw_start_date;
INSERT overwrite TABLE t_dw_orders_his
SELECT * FROM t_dw_orders_his_tmp;spark-sql> select * from t_dw_orders_his order by orderid,dw_start_date;
1 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
2 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
3 2015-08-19 2015-08-21 支付 2015-08-19 2015-08-20
3 2015-08-19 2015-08-21 支付 2015-08-21 9999-12-31
4 2015-08-19 2015-08-21 完成 2015-08-19 2015-08-20
4 2015-08-19 2015-08-21 完成 2015-08-21 9999-12-31
5 2015-08-19 2015-08-20 支付 2015-08-19 9999-12-31
6 2015-08-20 2015-08-20 创建 2015-08-20 9999-12-31
7 2015-08-20 2015-08-21 支付 2015-08-20 2015-08-20
7 2015-08-20 2015-08-21 支付 2015-08-21 9999-12-31
8 2015-08-21 2015-08-21 创建 2015-08-21 9999-12-31
Time taken: 0.717 seconds, Fetched 11 row(s)
1 当t-1>e时,s数据、e数据在t天之前产生,保留即可
2 当t-1=e时,e数据在t天产生,需修改
3 当s<t<=e时,e数据在t+n天产生,需修改
4 当s>=t时,s数据、e数据在t+n天产生,删除即可spark-sql> select * from t_dw_orders_his order by orderid,dw_start_date;
1 2015-08-18 2015-08-18 创建 2015-08-18 2015-08-21
1 2015-08-18 2015-08-22 支付 2015-08-22 2015-08-22
1 2015-08-18 2015-08-23 完成 2015-08-23 9999-12-31
2 2015-08-18 2015-08-18 创建 2015-08-18 2015-08-21
2 2015-08-18 2015-08-22 完成 2015-08-22 9999-12-31
3 2015-08-19 2015-08-21 支付 2015-08-19 2015-08-20
3 2015-08-19 2015-08-21 支付 2015-08-21 2015-08-22
3 2015-08-19 2015-08-23 完成 2015-08-23 9999-12-31
4 2015-08-19 2015-08-21 完成 2015-08-19 2015-08-20
4 2015-08-19 2015-08-21 完成 2015-08-21 9999-12-31
5 2015-08-19 2015-08-20 支付 2015-08-19 2015-08-22
5 2015-08-19 2015-08-23 完成 2015-08-23 9999-12-31
6 2015-08-20 2015-08-20 创建 2015-08-20 2015-08-21
6 2015-08-20 2015-08-22 支付 2015-08-22 9999-12-31
7 2015-08-20 2015-08-21 支付 2015-08-20 2015-08-20
7 2015-08-20 2015-08-21 支付 2015-08-21 9999-12-31
8 2015-08-21 2015-08-21 创建 2015-08-21 2015-08-21
8 2015-08-21 2015-08-22 支付 2015-08-22 2015-08-22
8 2015-08-21 2015-08-23 完成 2015-08-23 9999-12-31
9 2015-08-22 2015-08-22 创建 2015-08-22 9999-12-31
10 2015-08-22 2015-08-22 支付 2015-08-22 9999-12-31
11 2015-08-23 2015-08-23 创建 2015-08-23 9999-12-31
12 2015-08-23 2015-08-23 创建 2015-08-23 9999-12-31
13 2015-08-23 2015-08-23 支付 2015-08-23 9999-12-31 1 增加临时表t_dw_orders_his_tmp1,用来记录t-1>e的数据
CREATE TABLE t_dw_orders_his_tmp1
AS
SELECT
orderid,
createtime,
modifiedtime,
status,
dw_start_date,
dw_end_date
FROM
t_dw_orders_his
WHERE
dw_end_date < '2015-08-21'3 2015-08-19 2015-08-21 支付 2015-08-19 2015-08-20
4 2015-08-19 2015-08-21 完成 2015-08-19 2015-08-20
7 2015-08-20 2015-08-21 支付 2015-08-20 2015-08-20
2 增加临时表t_dw_orders_his_tmp2,用来记录t-1=e的数据
CREATE TABLE t_dw_orders_his_tmp2
AS
SELECT
orderid,
createtime,
modifiedtime,
status,
dw_start_date,
'9999-12-31' AS dw_end_date
FROM
t_dw_orders_his
WHERE
dw_end_date = '2015-08-21'1 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
2 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
6 2015-08-20 2015-08-20 创建 2015-08-20 9999-12-31
8 2015-08-21 2015-08-21 创建 2015-08-21 9999-12-31
3 增加临时表t_dw_orders_his_tmp3,用来记录s<t<=e的数据
CREATE TABLE t_dw_orders_his_tmp3
AS
SELECT
orderid,
createtime,
modifiedtime,
status,
dw_start_date,
'9999-12-31' dw_end_date
FROM
t_dw_orders_his
WHERE
dw_start_date < '2015-08-22' AND dw_end_date >= '2015-08-22'
3 2015-08-19 2015-08-21 支付 2015-08-21 9999-12-31
4 2015-08-19 2015-08-21 完成 2015-08-21 9999-12-31
5 2015-08-19 2015-08-20 支付 2015-08-19 9999-12-31
7 2015-08-20 2015-08-21 支付 2015-08-21 9999-12-314 所有数据插入新表t_dw_orders_his_new
CREATE TABLE t_dw_orders_his_new
AS
SELECT * FROM t_dw_orders_his_tmp1
UNION ALL
SELECT * FROM t_dw_orders_his_tmp2
UNION ALL
SELECT * FROM t_dw_orders_his_tmp31 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
2 2015-08-18 2015-08-18 创建 2015-08-18 9999-12-31
3 2015-08-19 2015-08-21 支付 2015-08-19 2015-08-20
3 2015-08-19 2015-08-21 支付 2015-08-21 9999-12-31
4 2015-08-19 2015-08-21 完成 2015-08-19 2015-08-20
4 2015-08-19 2015-08-21 完成 2015-08-21 9999-12-31
5 2015-08-19 2015-08-20 支付 2015-08-19 9999-12-31
6 2015-08-20 2015-08-20 创建 2015-08-20 9999-12-31
7 2015-08-20 2015-08-21 支付 2015-08-20 2015-08-20
7 2015-08-20 2015-08-21 支付 2015-08-21 9999-12-31
8 2015-08-21 2015-08-21 创建 2015-08-21 9999-12-3102
—
处理缓慢变化维策略
什么是维度
在数据仓库的DW层中,表根据用途往往会分为2个类型:FACT(事实表)和 DIM(维度表)。
举个例子,如果我们要描述一个餐饮过程:
小明 2020年4月19日下午3点20分 在 海底捞(万达广场) 吃了5道菜,每道菜的单价是4元,总价是20元。
那么这个过程在数仓中,会如此划分:
事实:餐饮过程,单价、数量、总价
维度:小明,餐饮时间,餐饮门店,菜名。
也就是说:
吃了多少东西,多少钱——这些属于事实;
在哪里吃、什么时候吃?这些属于维度。
缓慢变化维概念介绍
什么是缓慢变化维
缓慢变化维(Slowly Changing Dimensions,SCD): 它的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间的流失发生缓慢的变化。
2.怎样处理缓慢变化维?
三种常见的方法
直接覆盖原值 ---无法看到历史值
直接添加维度行---关联使用的时候,没法区分该用哪条数据
添加维度行 + 代理键 + 时间序列 ----数据标识哪条是最新变更,且有效数据
添加属性列---将后面的数据变为新属性,之前的成为旧属性(优点:可以同时分析当前及前一次变化的属性值)
处理方法通常分为3种:
假设有这样一条数据:
id name city
101 luna Chongqing
现在luna离开重庆,前往成都分公司工作,所以需要对city数据进行更新
第一种:直接覆盖原值
id name city
101 luna Chengdu
这样处理,最容易实现,但是没有保留历史数据,无法分析历史变化信息
第二种:添加维度行
当有维度属性发生变化时,生成一条新的维度记录,如下:
id name city
101 luna Chongqing
101 luna Chengdu
但是这样,当与别的表通过id关联时,有两个101的id数据,这样是有问题的;所以就需要代理键的支持。(在数据仓库的术语里面,这个唯一标识数据仓库表记录的键我们称之为 Surrogate Key 代理键)
sk_id id name city
001 101 luna Chongqing
002 101 luna Chengdu
现在每条数据都唯一,但又一个问题,现在不知道哪个是当前在用的数据,虽然可以通过代理键找最大的(因为主键往往是自增的,最大的通常是最新的数据),但某些情况下要插入历史数据就不好找了,所以在维度表中加入时间序列,用NULL来标识哪条是当前最新数据,有变化再进行更新。
sk_id id name city start_time end_tinme
001 101 luna Chongqing 2017/08/27 2018/06/20
002 101 luna Chengdu 2018/06/20 NULL
第三种:添加属性列
id name curr_city old_city
101 luna Chengdu Chongqing
#我是媛姐,一枚有多年大数据经验的程序媛,早期做过电商也有外贸,打过螺丝搬过砖,关注数仓,关注分析。愿你我走得更远!
