




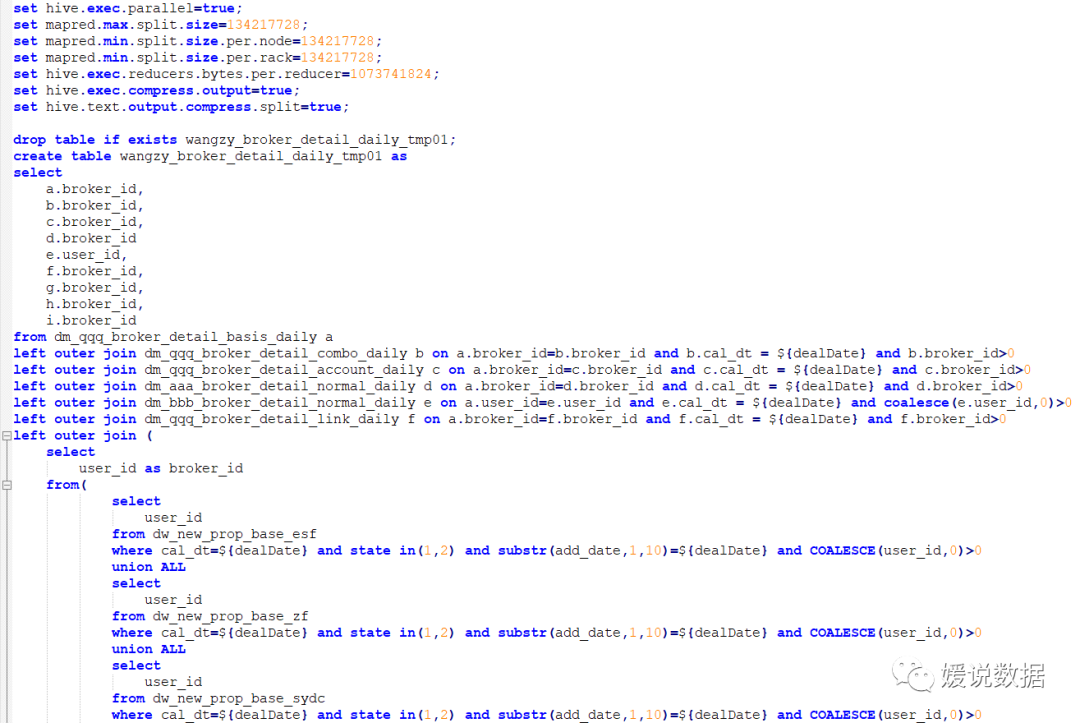
第一版的sql:

第一次优化:开启mapjoin



hive0.11 版本以前 ---要在写的SQL里面加mapjoin
SELECT关键字后面添加/*+ MAPJOIN(tablelist) */提示优化器转化为map join
select /* +mapjoin(a) */ a.id aid, name, age from a join b on a.id = b.id;
select /* +mapjoin(movies) */ a.title, b.rating from movies a join ratings b on a.movieid =
b.movieid;
hive0.11 版本以后 ---开启参数即可。
优化完后运行时间直接从2小时46分降到了2小时。
备注:如何查看当前hive版本号
方法一
查看jar包版本:
whereis hive 获取 hive位置 查看hive的jar包版本
方法二

第二次优化: 寻找数据倾斜
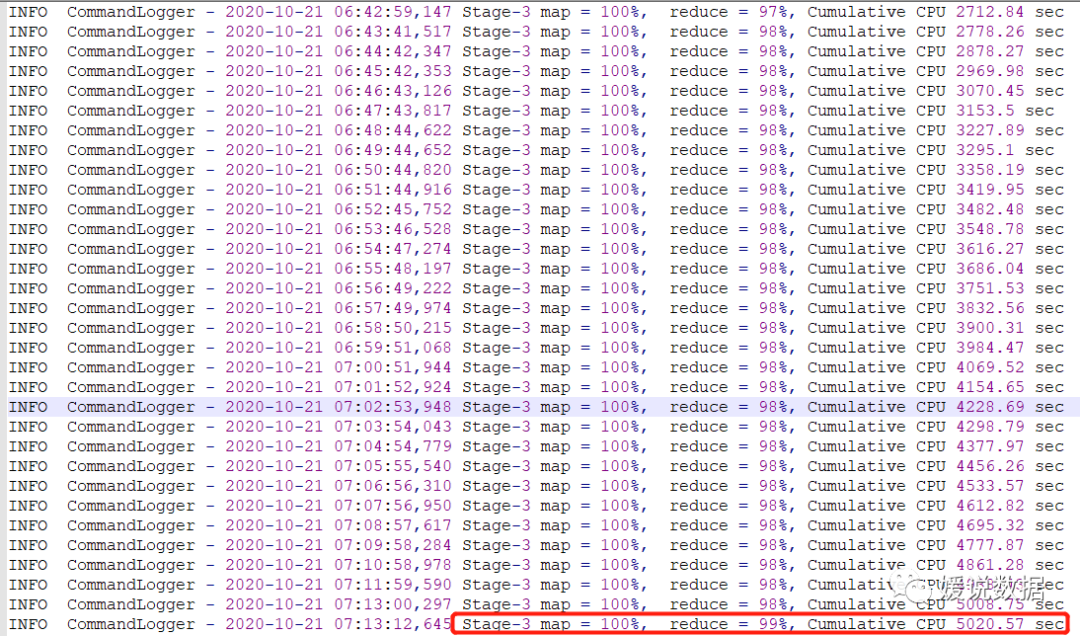
所以继续去CDH平台,yarn的历史日志去确认是否数据倾斜。

stage3的时候,数据倾斜。
所以,只要找到stage是哪个语句就能找到数据倾斜的地方。
通过explain。将sql输出语法树。
这个语法树会非常的长。但是只要找到stage-3是哪个语句就好了。
语法树的日志就不详细贴出。
通过文本搜索’Stage-3’。
在语法树的下面能看到 alias:e 的标签。
所以,上面的sql语句是e表的join出现了数据倾斜。
回顾join e表的语句。
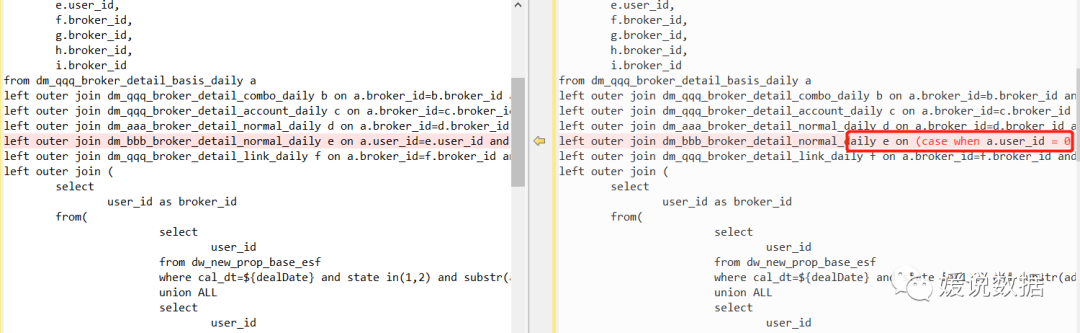
left outer join dm_bbb_broker_detail_normal_daily e on a.user_id=e.user_id and e.cal_dt = ${dealDate} and coalesce(e.user_id,0)>0
通过查找。可以发现是主表的user_id倾斜了。里面user_id为0的条数有几十万条。定位找到了数据倾斜的地方。优化就变得简单了。
现在直接将主表的user_id打散就好了。
left outer join dm_bbb_broker_detail_normal_daily e on (case when a.user_id = 0 then cast(ceiling(rand() * -65535) as bigint) else a.user_id end)=e.user_id and e.cal_dt = ${dealDate} and coalesce(e.user_id,0)>0
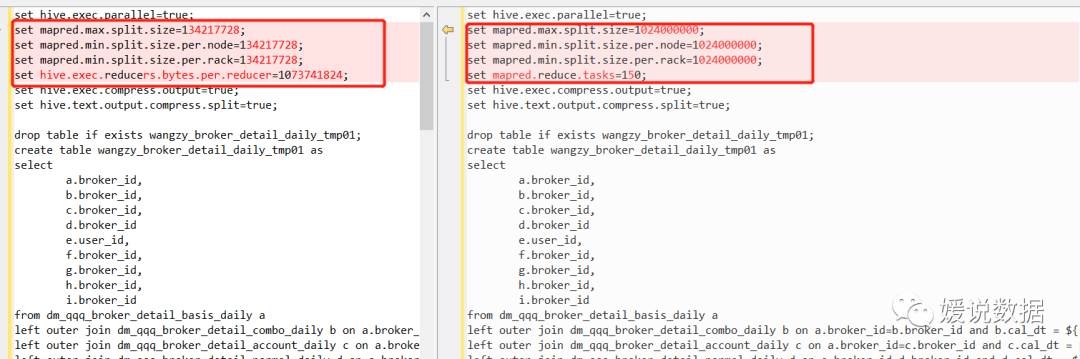
第三次优化:调整map数量与reduce数量
set mapred.max.split.size=134217728;
set mapred.min.split.size.per.node=134217728;
set mapred.min.split.size.per.rack=134217728;
set hive.exec.reducers.bytes.per.reducer=1073741824;
从上面的参数可以看到。这里sql设置的map切分是128兆。随便挑一个任务去yarn看一下详细情况。
能看到起了100多个map。
但是每一个map的时间都很短
这里就会造成了yarn会启动大量的map,造成了资源浪费。所以减少map数量迫在眉睫。经过调试确定下列参数。
set mapred.max.split.size=1024000000;
set mapred.min.split.size.per.node=1024000000;
set mapred.min.split.size.per.rack=1024000000;
set mapred.reduce.tasks=150;
将map切分数量过大了近10倍,能明显减少map数量
这里需要经过多次的调试,确定一个最优的值。
最后将直接缩短到了50分钟
前后更改SQL对比:
map、reduce参数更改:
表关联关联键特殊数据处理随机数:
开启mapjoin,小表先加载内存:

2. 继承UDF类;
3. 重写evaluate方法。
创建一个HelloUdf类继承UDF,并且重写evaluate方法

打jar包

上传jar包

在项目中是否自定义过UDF、UDTF函数,以及用他们处理了什么问题,及自定义步骤?
1)自定义过。
2)用UDF函数解析公共字段;用UDTF函数解析事件字段。
自定义UDF:继承UDF,重写evaluate方法
自定义UDTF:继承自GenericUDTF,重写3个方法:initialize(自定义输出的列名和类型),process(将结果返回forward(result)),close
为什么要自定义UDF/UDTF,因为自定义函数,可以自己埋点Log打印日志,出错或者数据异常,方便调试.
列转行,行转列问题
列转行
其实也就是一行中的一个字段的数据,拆成好几行的数据,其中经常用到的函 数列举如下:
split()函数:
hsql中split(item,'分隔符')
lateral view:
这个和explode要结合起来一起用
explode将复杂结构一行拆成多行,实现行转列,如
id name
1 hell,hao,de
select explode(split(name,',')) from tablename;
id name
1 hello
1 hao
1 he
Lateral view:
lateral view用于和split、explode等UDTF一起使用的,lateral view把一行拆分 成一行或者多行,再把结果组合,产生一个支持别名表的虚拟表。
select id,name2 from tablename lateral view explode(split(name,’,’)) c as name2;
案例:

XDC123 计划买车,已买房,已买车
DFG456 计划买房,计划买房,已买房,已买车
CXY789 计划买车,计划买房,已买房,已买车
...
分析:数据拆出来,每个人生阶段这种事件会有很多重复,明细是要分组;
步骤:
按',' 拆分数据;
explode一行拆分成多行
laterval view组合2.命名成虚拟表
laterval view explode ---整条命名成 as 新字段
select stage_someone, count(distinct UID) from LifeStage lateral view explode(split(stage,',')) LifeStage_tmp as stage_someone group by stage_someone;
行转列:
XDC123 计划买车
XDC123 已买车
XDC123 已买房
.....
数据变换:
XDC123 已买房,已买车, 计划买车
所有数据拼合成一行

select UID,concat_ws(',',collect_set(stage)) as stages from LifeStage group by UID;
