“ 上一节,我们讲了Hadoop体系中关于HQL常见的问题第一个系列,HQL优化及其UDF\UDTF函数,行转列、列转行问题。这一节讲常见的开窗函数以及应用等。"
普通的聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。因此,普通的聚合函数每组(Group by)只返回一个值,而开窗函数则可为窗口中的每行都返回一个值。简单理解,就是对查询的结果多出一列,这一列可以是聚合值,也可以是排序值。 聚合函数,比如:sum(...)、 max(...)、min(...)、avg(...)等 数据排序函数, 比如 :rank(...)、row_number(...)等 统计和比较函数, 比如:lead(...)、lag(...)、 first_value(...)等DENSE_RANK() 排序相同时会重复,总数会减少1) OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化5)UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点8) NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。数据准备
样例数据
[职工姓名|部门编号|职工ID|工资|岗位类型|入职时间]- Michael|1000|100|5000|full|2014-01-29
- Will|1000|101|4000|full|2013-10-02
- Wendy|1000|101|4000|part|2014-10-02
- Steven|1000|102|6400|part|2012-11-03
- Lucy|1000|103|5500|full|2010-01-03
- Lily|1001|104|5000|part|2014-11-29
- Jess|1001|105|6000|part|2014-12-02
- Mike|1001|106|6400|part|2013-11-03
- Wei|1002|107|7000|part|2010-04-03
- Yun|1002|108|5500|full|2014-01-29
- Richard|1002|109|8000|full|2013-09-01
建表语句
加载数据
load data local inpath '/opt/datas/data/employee_contract.txt' into table employee;窗口聚合函数
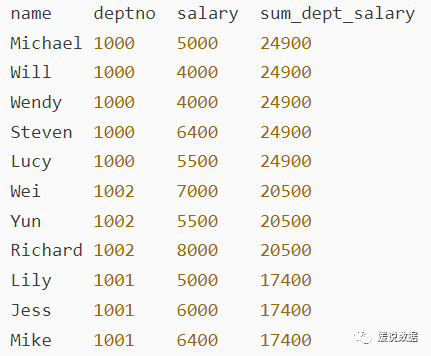
查询姓名、部门编号、工资以及每个部门的总工资,部门总工资按照降序输出窗口排序函数
简介
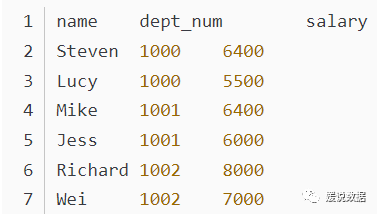
窗口排序函数提供了数据的排序信息,比如行号和排名。在一个分组的内部将行号或者排名作为数据的一部分进行返回,最常用的排序函数主要包括:根据具体的分组和排序,为每行数据生成一个起始值等于1的唯一序列数对组中的数据进行排名,如果名次相同,则排名也相同,但是下一个名次的排名序号会出现不连续。比如查找具体条件的topN行dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。当出现名次相同时,则排名序号也相同。而下一个排名的序号与上一个排名序号是连续的。排名计算公式为:(current rank - 1)/(total number of rows - 1)将一个有序的数据集划分为多个桶(bucket),并为每行分配一个适当的桶数。它可用于将数据划分为相等的小切片,为每一行分配该小切片的数字序号。查询每个部门工资最高的两个人的信息(姓名、部门、薪水)
结果输出
尖叫提示:从 Hive v2.1.0开始, 支持在OVER语句里使用聚集函数,比如:

窗口分析函数
介绍
常用的分析函数主要包括:
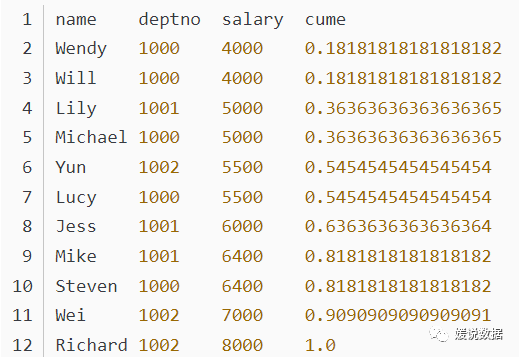
如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。比如,统计小于等于当前工资的人数占总人数的比例 ,用于累计统计.
用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL.
与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL.
取分组内排序后,截止到当前行,第一个值
取分组内排序后,截止到当前行,最后一个值
使用案例

结果输出
生成计划、执行计划,哪几种情况会生成MapReduce任务
单表分析:select a,聚合函数 from XXX group by b
多表join分析:select a.,b. from a join b on a.id=b.id
这两种sql框架,概括了所有的大数据sql,几乎不可能有第三种写法,区别可能是业务复杂,写的复杂点儿而已。
解析sql执行计划流程详解
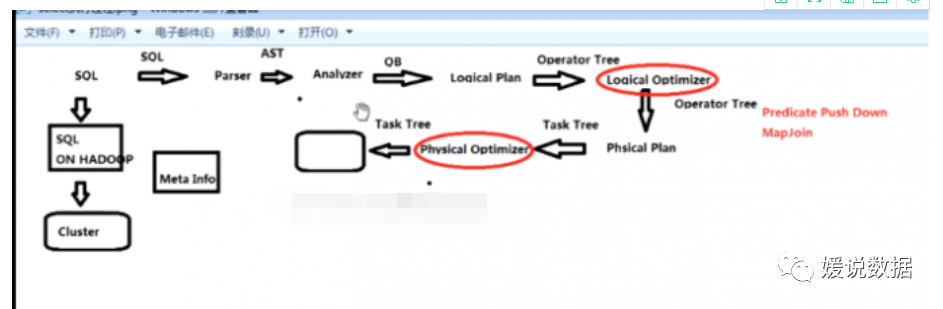
1)parser:将sql解析为AST(抽象语法树),会进行语法校验,AST本质* * 还是字符串
2)Analyzer:语法分析,生成QB(query block)
3)Logicl Plan:逻辑执行计划解析,生成一堆Opertator Tree
4)Logicl Optimizer:进行逻辑执行计划优化,生成一堆Opertator Tree
5)Phsical plan:物理执行计划解析,生成 tasktree
6)Phsical Optimizer:进行物理执行计划优化,生成 t优化后tasktree,该任务即是在集群上执行的作业 任务
六步将普通的sql映射成了作业任务。重点是 逻辑执行计划优化和物理执行计划优化
表中字段类型发生变更
hive sql join 时字段类型不一致问题
在用hive sql 查询数据时会遇到 两个表通过字段join,假如两个字段类型不一样,有可能出现莫名其妙的结果。
解决方法:将2个字段类型转成一样。比如 两个表通过id关联, 一个是 string 一个是 int,可以将 string 转成int eg: (cast id as int) as id
总结:这一节我们讲了hive的一些开窗函数,及其应用的一些小知识。下一节,我们来讲ETL的相关问题。#我是媛姐,一枚有多年大数据经验的程序媛,打过螺丝搬过砖,关注数仓,关注分析。愿你我走得更远!