




目录
2 DCN-V2
2.1 DCN-V2原理
2.2 特征交叉层
2.3 特征交叉层的理解
2.4 特征交叉层优化
2.4.1 矩阵分解优化
2.4.2 子空间特征交叉
2.5 DCN-V2的优缺点
2.6 DCN-V2特征交叉代码
相关面试问题
2 DCN-V2
DCN-V2[2]出自论文《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems》,是对DCN工作的延续,针对特征交叉这部分网络结构进行改进和优化,使cross net的具有更强的表达能力,从而学到更有效的特征交叉,提升模型效果。
2.1 DCN-V2原理
上一篇提到DCN的特征交叉层中,
DCN-V2的网络结构,和DCN的结构基本相同,如图5所示,包括左侧的特征交叉网络和右侧的DNN两部分,这两部分可以以并行的形式得到网络输出,即图中所示,也可以通过串行的形式,即在cross net上再接DNN部分,将cross net的输出作为DNN的输入。损失函数为交叉熵损失。
DCN-V2的特征交叉网络,对特征的操作类似DCN,进行相乘和相加操作,实现显式高阶交叉。
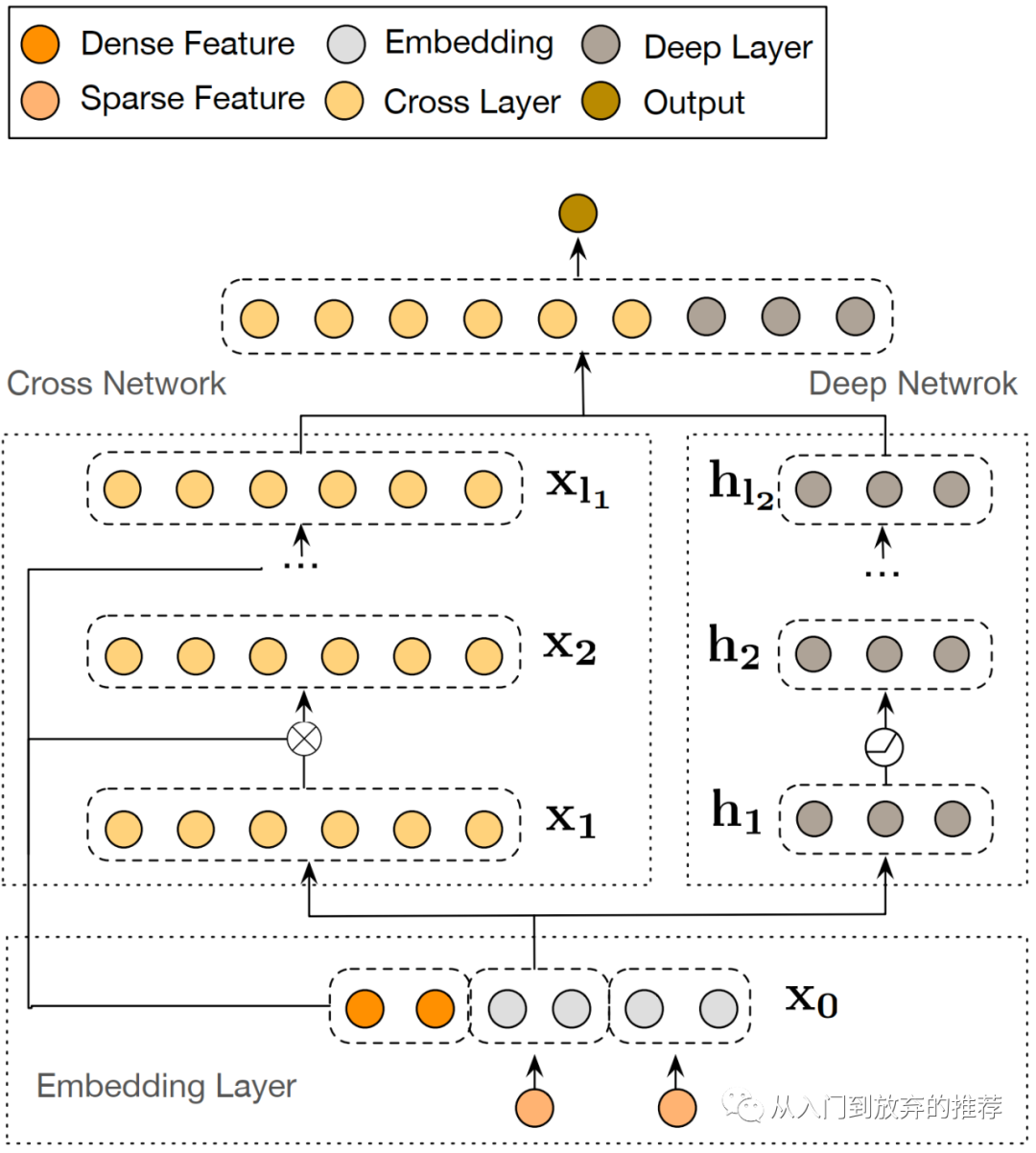
2.2 特征交叉层
DCN-V2的特征交叉层设计思路和DCN相同,利用乘法实现更高一阶的交叉组合,再采用加法得到所有阶的交叉组合项。式子(6)和图6表示了特征交叉层对特征的操作,其中
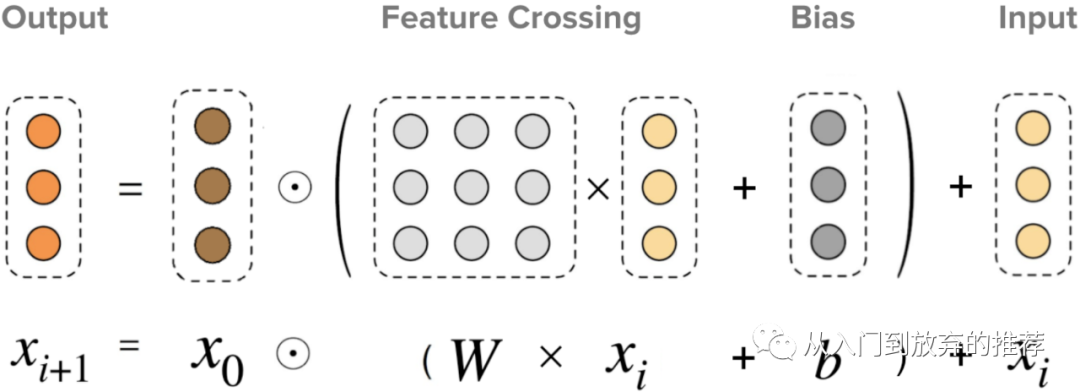
特征交叉层保持了DCN的特点,即:(1)每一层的输入输出保持相同的形状,从而使网络参数随着网络层数呈线性增长;(2) 特征的交叉阶数由网络深度决定,即交叉特征的阶数和网络层数一致;(3) 特征交叉网络的输出,包含了从1阶(特征
特征交叉网络的参数
2.3 特征交叉层的理解
用上一篇文章介绍的归纳法,理解特征交叉层为什么可以实现1阶到L+1阶的所有特征交叉组合项,具体方法可在《为什么DCN可以实现显式高阶特征交叉-模型结构之特征交叉(3)-DCN系列(3.1)附代码》查看。
特征交叉层的参数
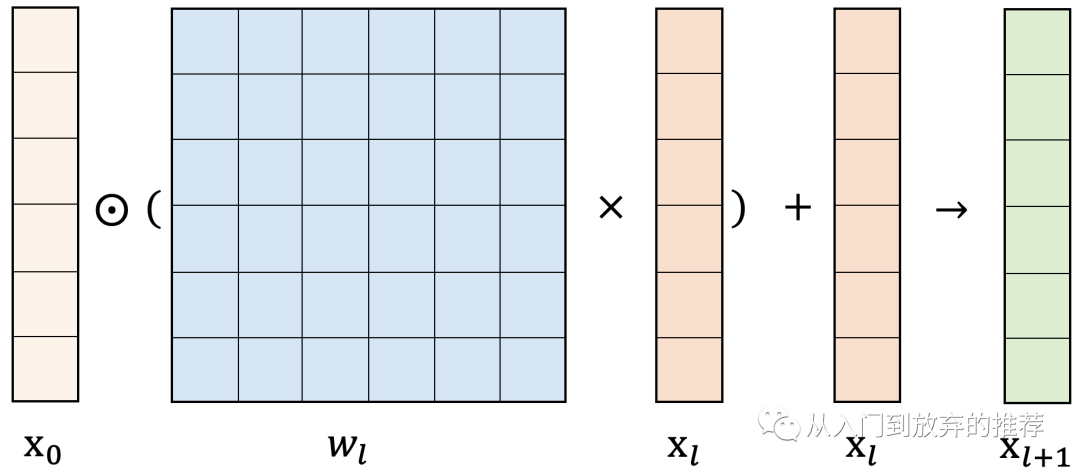
图7 特征交叉层操作示意图
2.4 特征交叉层优化
DCN-V2的特征交叉引入了矩阵参数w,参数量为
受mmoe思路的启发,论文提出一种思路,在多个子空间学习特征的交叉性后,再将其进行融合。在特征交叉层,考虑到交叉组合形成的feature只进行线性组合,论文引入激活函数,在特征变换中引入非线性。
2.4.1 矩阵分解优化
看过前面几篇关于特征交叉的文章的朋友,对这个操作应该不陌生,在《模型结构之特征交叉(2)-FM系列(2.1)-FM,FFM》详细介绍过矩阵分解的思路和原理,简而言之,即把一个复杂矩阵分解为两个简单矩阵相乘。
采用矩阵分解的思路对参数w进行优化,如式子(7)所示,其中,参数量由
2.4.2 子空间特征交叉
DCN-V2借鉴mmoe的思路,在多个子空间学习特征交叉,即有多个expert学习特征交叉,再用gate思路将各个子空间特征交叉结果融合,如式子(8)所示。
为什么说理论上呢,因为网络的的学习是在一个非常高维的空间中,其学习过程非常复杂,实际过程肯能很难收敛到预期。对于采用多个子空间学习特征交叉的优化,在实际过程中,很有可能导致最终效果集中在单个expert上,也就是坍缩现象。我在具体业务上没有在特征交叉上尝试这个优化,但在别的点上试过gate的思路,发现有明显的坍缩现象,因此推测在这个优化点上,大概率会遇到这个问题。针对坍缩现象的缓解,学术界也业界也有一些研究,后面有时间也会介绍。
2.5 DCN-V2的优缺点
对DCV-V2的特征交叉理解清楚后,其优缺点也非常明显。
优点主要源自特征交叉对feature的有差别组合:(1) 交叉组合项形成的feature可以进行有差别的组合,提高了模型对特征交叉的学习能力;(2) 而优化过程引入了多个expert和特征的非线性变化,也强化了特征交叉的学习。
模型在提高对特征交叉学习能力的同时,带来了参数量的增加和模型结构的复杂化,因此也造成了模型的缺点:(1) 参数量增加;(2) 优化过程使得模型更复杂,增加了模型的学习难度,实际上可能难以达到理论上预期的模型效果。
2.6 DCN-V2特征交叉代码
充分理解DCN-V2的原理后,其代码实现则比较简单,在DCN代码的基础上做一些改动即可。对于特征交叉的引入矩阵分解、多个expert和非线性的优化,在代码中进行相应的实现即可。
代码2 DCN-V2 cross net 参数使用矩阵 代码实现
def dcnv2_cross_net_matrix(params, input_layer, mode, layer_dropout=1):'''cross net module: w use matrixReference: DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning to Rank Systemsinput_layer: [B, N]x_{l+1} = x_0*(tf.matmul(W_l, x_l) + b_l) + x_l'''layer_name = 'cross_layers_m'embedding_layer_l = input_layer # [B, N]input_size = input_layer.shape[1].value # return the N numberoutput_size = params.cross_layers['out_dim']layer_num = params.cross_layers['layer_num']kernel_initializer = tf.glorot_uniform_initializer()bias_initializer = tf.zeros_initializer()# process cross netfor i in range(layer_num):index = i + 1kernel = tf.get_variable(name="{0}_kernel_{1}".format(layer_name, index),shape=[input_size, input_size],dtype=tf.float32,initializer=kernel_initializer,) # [N, N]bias = tf.get_variable(name="{0}_bias_{1}".format(layer_name, index),shape=[input_size],dtype=tf.float32,initializer=bias_initializer,) # [N]embedding_layer_l_w = tf.tensordot(embedding_layer_l, # [B, N]kernel, # [N, N]axes=(1, 0),name="{0}_l_w_{1}".format(layer_name, index),) # [B, N]embedding_layer_l = tf.add(tf.multiply(input_layer, tf.add(embedding_layer_l_w, bias)), embedding_layer_l)if layer_dropout < 1.0:embedding_layer_l = tf.layers.dropout(embedding_layer_l, rate=(1 - layer_dropout),training=(mode == tf.estimator.ModeKeys.TRAIN),name="{0}_layer_{1}_dropout".format(layer_name, index),)# process outputoutput_w = tf.get_variable("{0}_output_w".format(layer_name),shape=[input_size, output_size],dtype=tf.float32,initializer=kernel_initializer,)output_layer = tf.matmul(embedding_layer_l, output_w, name="{0}_output".format(layer_name)) # [B, Output]return output_layer
代码3 DCN-V2 cross net 使用矩阵分解 代码实现
def dcnv2_cross_net_matrix_factorization(params, input_layer, mode, layer_dropout=1):'''x_{l+1} = x_0*(tf.matmul(W_l, x_l) + b_l) + x_l, W_l use matrix factorization, W * X = U * (V * X)input_layer: [B, N]'''layer_name = 'cross_layers_mfl'embedding_layer_l = input_layer # [B, N]input_size = input_layer.shape[1].value # return the N numberoutput_size = params.cross_layers['out_dim']layer_num = params.cross_layers['layer_num']factorize_dim = params.cross_layers['fac_dim']kernel_initializer = tf.glorot_uniform_initializer()bias_initializer = tf.zeros_initializer()# process cross netfor i in range(layer_num):index = i + 1kernel_v = tf.get_variable(name="{0}_kernel_v_{1}".format(layer_name, index),shape=[input_size, factorize_dim],dtype=tf.float32,initializer=kernel_initializer,) # [N, K]kernel_u = tf.get_variable(name="{0}_kernel_u_{1}".format(layer_name, index),shape=[input_size, factorize_dim],dtype=tf.float32,initializer=kernel_initializer,) # [N, K]bias = tf.get_variable(name="{0}_bias_{1}".format(layer_name, index),shape=[input_size],dtype=tf.float32,initializer=bias_initializer,) # [N]embedding_layer_l_v = tf.tensordot(embedding_layer_l, # [B, FD]kernel_v, # [N, K]axes=(1, 0),name="{0}_l_v_{1}".format(layer_name, index),) # [B, K]embedding_layer_l_uv = tf.tensordot(embedding_layer_l_v, # [B, K]tf.transpose(kernel_u), # [K, N]axes=(1, 0),name="{0}_l_uv_{1}".format(layer_name, index),) # [B, N]embedding_layer_l = tf.add(tf.multiply(input_layer, tf.add(embedding_layer_l_uv, bias)), embedding_layer_l)if layer_dropout < 1.0:embedding_layer_l = tf.layers.dropout(embedding_layer_l, rate=(1 - layer_dropout),training=(mode == tf.estimator.ModeKeys.TRAIN),name="{0}_layer_{1}_dropout".format(layer_name, index),)# process outputoutput_w = tf.get_variable("{0}_output_w".format(layer_name),shape=[input_size, output_size],dtype=tf.float32,initializer=kernel_initializer,)output_layer = tf.matmul(embedding_layer_l, output_w, name="{0}_output".format(layer_name)) # [B, Output]return output_layer
代码4 DCN-V2 cross net 使用多个expert 代码实现
def dcnv2_cross_net_matrix_factorization_mmoe(params, input_layer, mode, layer_dropout=1):'''cross net module: apply mmoeparams: the model config paramsinput_layer: [B, N]'''layer_name = 'cross_layers_mfnl'embedding_layer_l = input_layer # [B, N]input_size = input_layer.shape[1].value # return the N numberoutput_size = params.cross_layers['out_dim']layer_num = params.cross_layers['layer_num']factorize_dim = params.cross_layers['fac_dim'] # Kexpert_num = params.cross_layers['expert_num'] # Ekernel_initializer = tf.glorot_uniform_initializer()bias_initializer = tf.zeros_initializer()# process cross netfor i in range(layer_num):index = i + 1layer_l_experts = []# extractor gategate_l = tf.layers.dense(embedding_layer_l, units=expert_num, activation=None) # [B, E]gate_l = tf.nn.softmax(gate_l) # [B, E]for expert_id in range(expert_num):kernel_v = tf.get_variable(name="{0}_kernel_v_{1}_expert_{2}".format(layer_name, index, expert_id),shape=[input_size, factorize_dim],dtype=tf.float32,initializer=kernel_initializer,) # [N, K]kernel_u = tf.get_variable(name="{0}_kernel_u_{1}_expert_{2}".format(layer_name, index, expert_id),shape=[input_size, factorize_dim],dtype=tf.float32,initializer=kernel_initializer,) # [N, K]kernel_c = tf.get_variable(name="{0}_kernel_c_{1}_expert_{2}".format(layer_name, index, expert_id),shape=[factorize_dim, factorize_dim],dtype=tf.float32,initializer=kernel_initializer,) # [K, K]bias = tf.get_variable(name="{0}_bias_{1}_expert_{2}".format(layer_name, index, expert_id),shape=[input_size],dtype=tf.float32,initializer=bias_initializer,) # [N]embedding_layer_l_v = tf.tensordot(embedding_layer_l, # [B, N]kernel_v, # [N, K]axes=(1, 0),name="{0}_l_v_{1}_expert_{2}".format(layer_name, index, expert_id),) # [B, K]embedding_layer_l_v = tf.tanh(embedding_layer_l_v)embedding_layer_l_cv = tf.tensordot(embedding_layer_l_v, # [B, K]tf.transpose(kernel_c), # [K, K]axes=(1, 0),name="{0}_l_cv_{1}_expert_{2}".format(layer_name, index, expert_id),) # [B, K]embedding_layer_l_cv = tf.tanh(embedding_layer_l_cv)embedding_layer_l_ucv = tf.tensordot(embedding_layer_l_cv, # [B, K]tf.transpose(kernel_u), # [K, N]axes=(1, 0),name="{0}_l_ucv_{1}_expert_{2}".format(layer_name, index, expert_id),) # [B, N]embedding_layer_l_cur = tf.multiply(input_layer, tf.add(embedding_layer_l_ucv, bias)) # [B, N]layer_l_experts.append(embedding_layer_l_cur)layer_l_experts = tf.stack(layer_l_experts, 2) # [B, N, E]moe_l = tf.reduce_sum(layer_l_experts * (tf.expand_dims(gate_l, axis=1)),axis=2) # reduce_sum([B, N, E]*[B, 1, E]) = [B, N]embedding_layer_l = tf.add(moe_l, embedding_layer_l) # [B, N]if layer_dropout < 1.0:embedding_layer_l = tf.layers.dropout(embedding_layer_l, rate=(1 - layer_dropout),training=(mode == tf.estimator.ModeKeys.TRAIN),name="{0}_layer_{1}_expert_{2}_dropout".format(layer_name, index, expert_id),)# process outputoutput_w = tf.get_variable("{0}_output_w".format(layer_name),shape=[input_size, output_size],dtype=tf.float32,initializer=kernel_initializer,)output_layer = tf.matmul(embedding_layer_l, output_w, name="{0}_output".format(layer_name)) # [B, Output]return output_layer
相关面试问题
DCN-V2的原理
网络结构,参数量
和DCN的区别,相比DCN的优缺点
DCN-V2对特征交叉采用的优化
非线性问题(抖音面试遇到过)
引入多个expert学习不同子空间的特征交叉,可能面临的坍缩问题,怎么解决
下一篇将介绍xDeepFM。
以及朋友们有什么想要一起探讨的,可以在评论区告诉我,共同学习一起进步呀~
reference
[2] DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems。https://arxiv.org/pdf/2008.13535.pdf
推荐系列文章:
- 推荐模型结构-特征交叉
- 基础知识类
- 工具类
微信最近对公众号的推送算法改版较大,为了更好地找到我,动动手对这个公众号置顶呀~
公众号的内容会同时在知乎专栏更新,有兴趣的朋友可以在知乎找我玩(知乎账号:婷播播),知乎专栏:推荐学习笔记。
生活的思考和记录会在另一个公众号更新,有兴趣的朋友也可以动手关注一下
