




“ 这一节我们来讲关于数仓系统的,分布式爬虫在整个大数据中所在的架构地位,还有怎么由单机扩展成分布式,以及其中需要注意的问题。”
01
—
爬虫架构
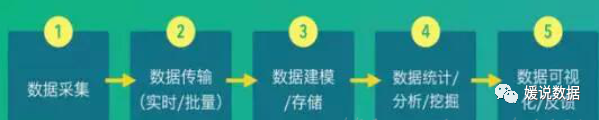
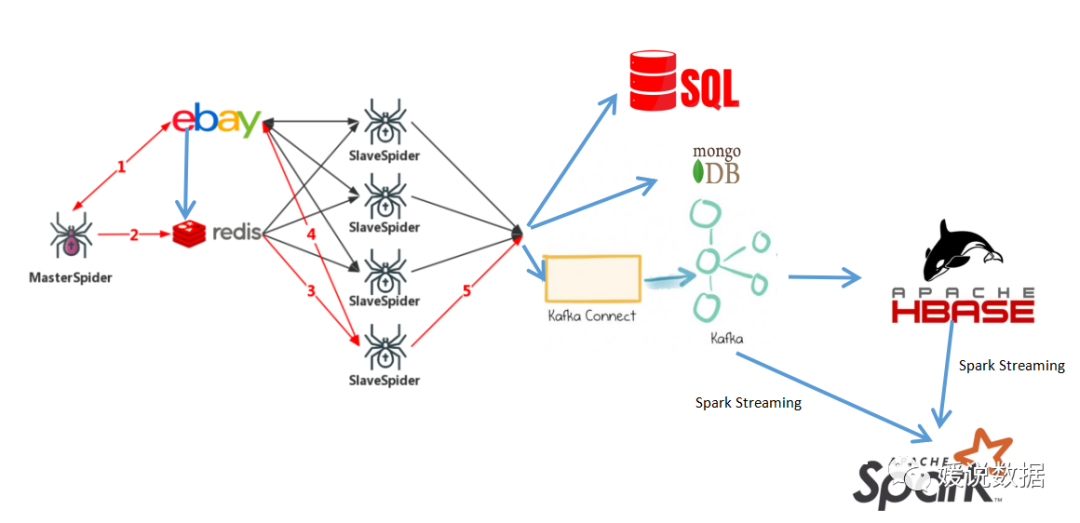
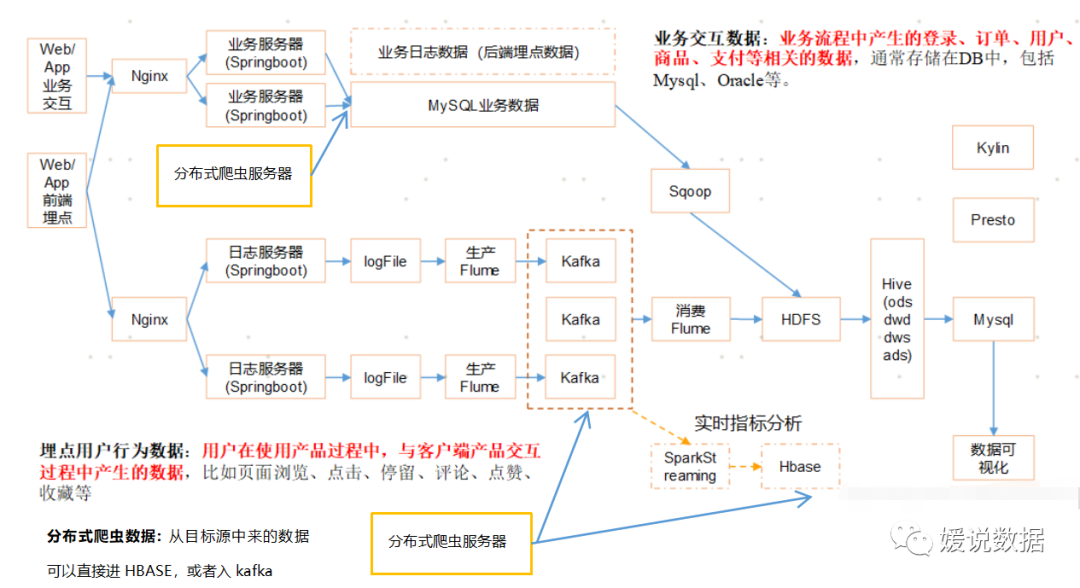
如果分布式爬虫模块,要接入原有数仓系统,就可以如下架构图表示:
02
—
Scrapy爬虫框架基础
框架:
框架就是一个集成了很多功能并且具有很强通用性的一个项目模板。
Scrapy框架:
是爬虫中封装好的一个框架。
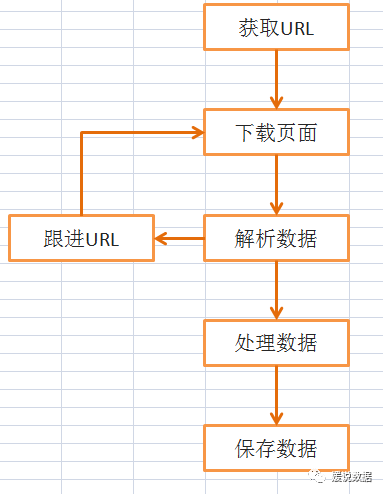
工作流程
Scrapy框架抓取的基本流程是这样(随便画了一下,不要纠结)
为什么使用scrapy框架?
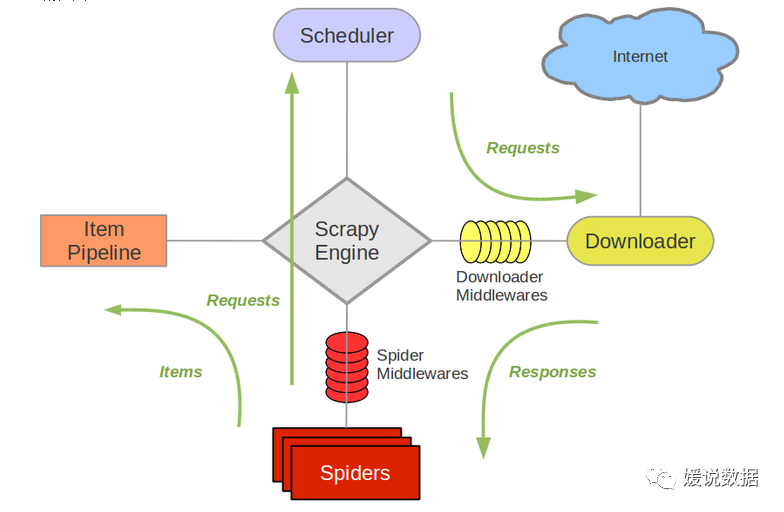
1、Scrapy Engine(引擎): 引擎负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发事件。
2、Scheduler(调度器): 调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
3、Downloader(下载器):下载器负责获取页面数据并提供给引擎,而后提供给spider。
4、Spider(爬虫):Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。每个spider负责处理一个特定(或一些)网站。
5、Item Pipeline(管道):Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存储到数据库中)。
6、Downloader Middlewares(下载中间件):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
7、Spider Middlewares(Spider中间件):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Scrapy组件间协调流程:
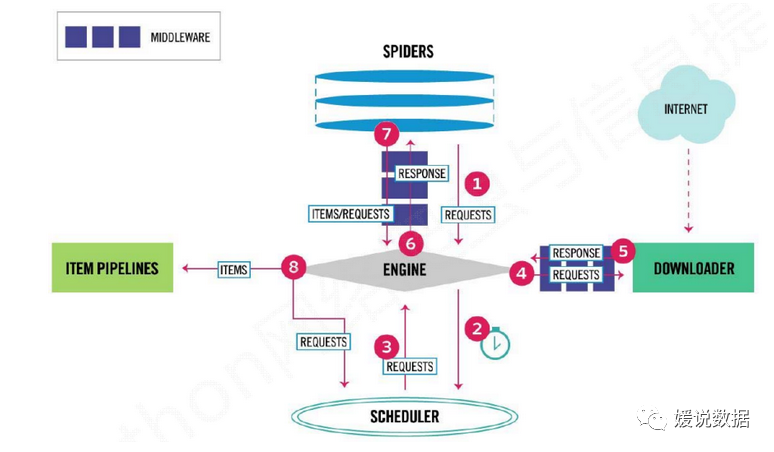
Engine向Spiders请求URL;
Spiders爬取URL对象并返回给Engine;
Engine将URL对象执行入队操作存入Scheduler中;
Scheduler执行出队操作,将URL通过Engine处理提交给Downloader;
Downloader拿到URL后执行下载操作,并将response通过Engine处理返回给Spiders;
Spiders解析从Downloader返回的response(提取所需数据),如果解析出的是URL对象则重复执行步骤2,如果解析出的是item对象则需要进行结构化数据处理,并将处理后的item通过Engine处理传到Pipeline进行进一步处理。
Scrapy基础工程怎么创建:
安装scrapy框架
流程分析,抓取内容分析
比如要抓取慕课网的内容是全部的课程名称,课程图片,课程人数,课程简介,课程URL
通过浏览器的调试工具F12分析网页结构, 查看相关要抓取数据的xpath解析

执行命令创建工程:
scrapy startproject scrapytest
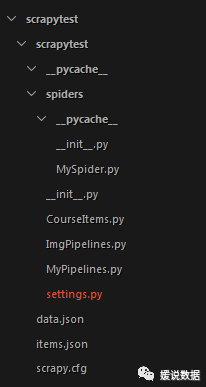
scrapytest是工程名框架会自动在当前目录下创建一个同名的文件夹,工程文件就在里边。
目录结构如下图:
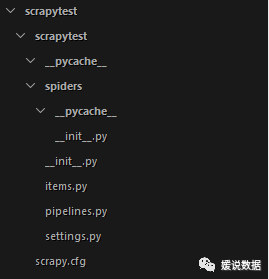
scrapy.cfg: 项目的配置文件
scrapytest/: 该项目的python模块。之后您将在此加入代码。
scrapytest/items.py: 项目中的item文件.
scrapytest/pipelines.py: 项目中的pipelines文件.
scrapytest/settings.py: 项目的设置文件.
scrapytest/spiders/: 放置spider代码的目录.
创建爬虫文件:
创建爬虫文件--->定义容器Item--->
创建Spider文件
在scrapytest/spiders/
目录下创建一个文件MySpider.py
文件包含一个MySpider类,它必须继承scrapy.Spider类。
必须定义一下三个属性:
-name: 用于区别Spider。该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
-start_urls: 包含了Spider在启动时进行爬取的url列表。因此,第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。
-parse() 是spider的一个方法。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
代码如下:

定义一个容器保存要爬取的数据
为了定义常用的输出数据,Scrapy提供了Item类。Item对象是种简单的容器,保存了爬取到得数据。其提供了 类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。

在创建完item文件后我们可以通过类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。
常用方法如下

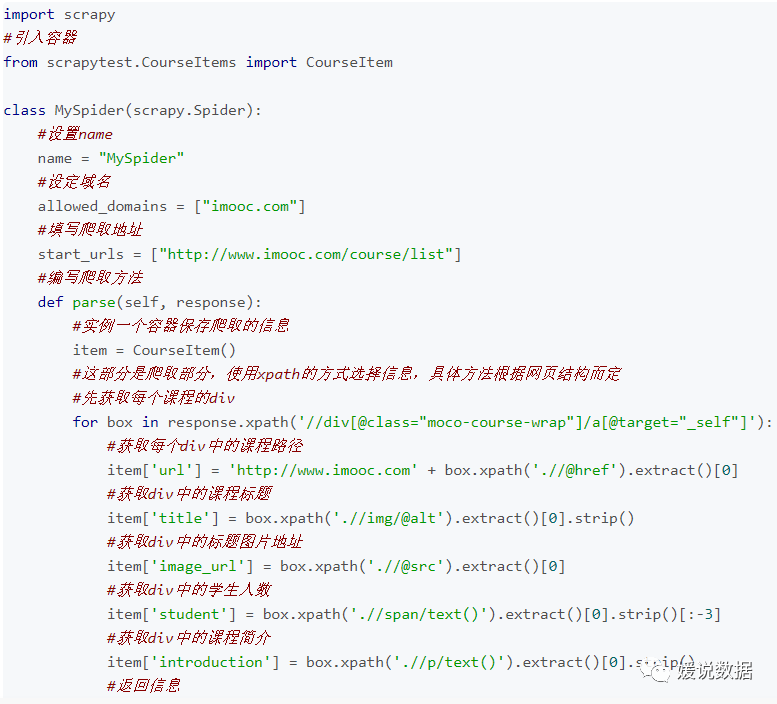
编写核心Spider代码
parse()方法负责处理response并返回处理的数据以及(/或)跟进的URL。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
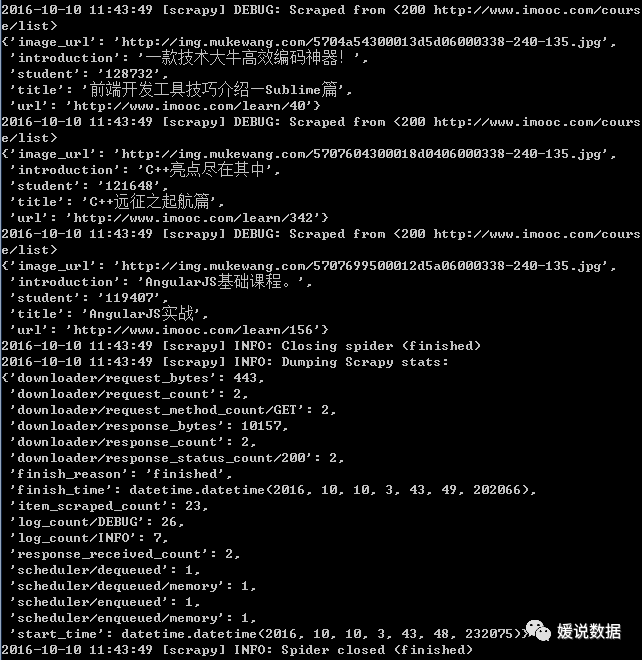
在命令行下进入工程文件夹,然后运行:
scrapy crawl MySpider
使用Pipeline处理数据
要进行信息的验证、储存等工作,这里以储存为例。
当Item在Spider中被收集之后,它将会被传递到Pipeline,一些组件会按照一定的顺序执行对Item的处理。
Pipeline经常进行一下一些操作:
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
这里只进行简单的将数据储存在json文件的操作。
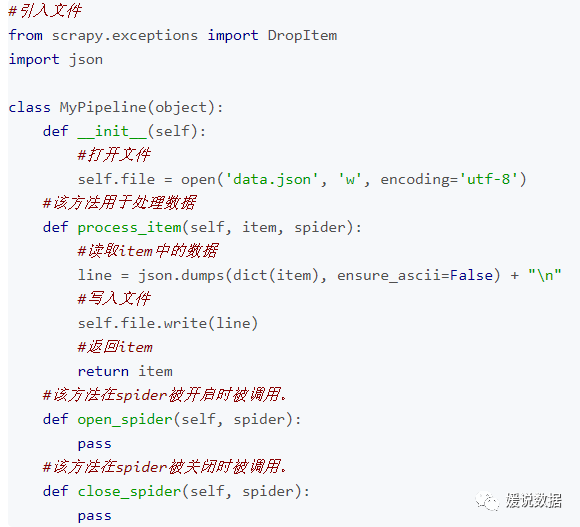
首先在scrapytest/目录下建立一个文件MyPipelines.py
MyPipelines.py代码如下:
settings.py文件配置:
要使用Pipeline,首先要注册Pipeline
找到settings.py文件,这个文件时爬虫的配置文件
在其中添加:
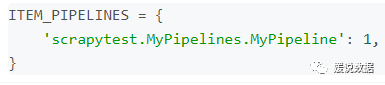
上面的代码用于注册Pipeline,其中scrapytest.MyPipelines.MyPipeline
为你要注册的类,右侧的’1’为该Pipeline的优先级,范围1~1000,越小越先执行。
进行完以上操作,我们的一个最基本的爬取操作就完成了
这时我们再运行:
scrapy crawl MySpider
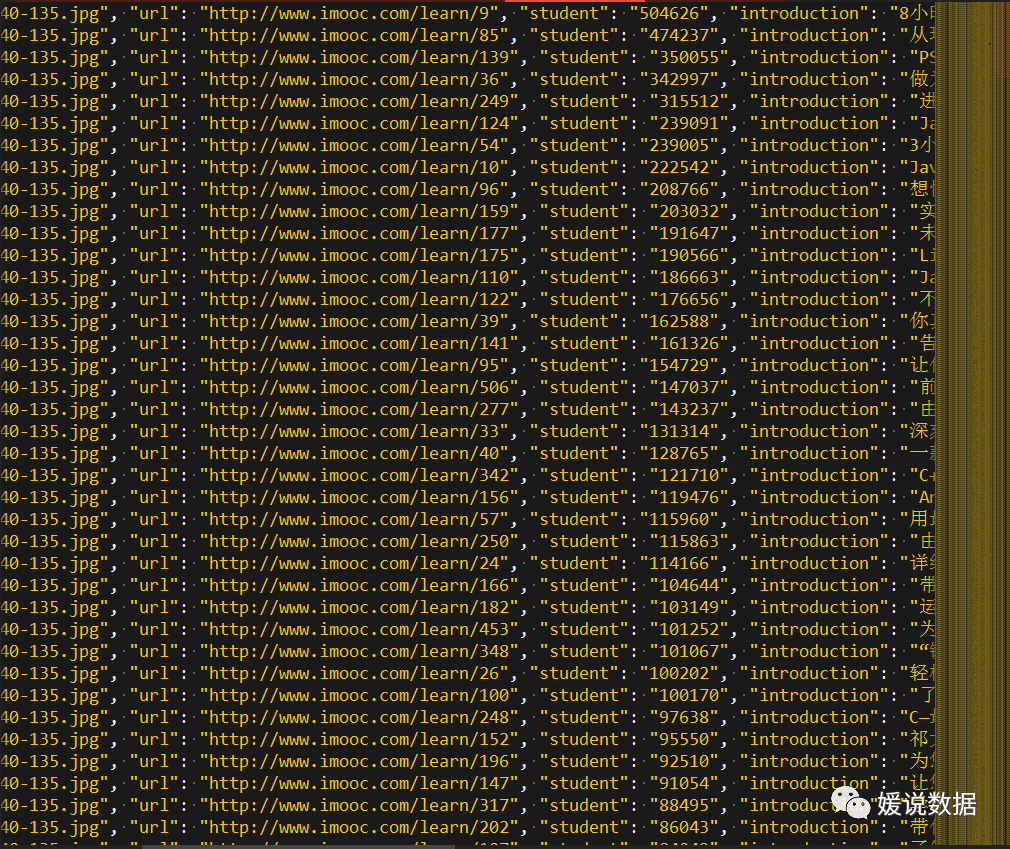
就可以在项目根目录下发现data.json文件,里面存储着爬取的课程信息。
如下图:

扩展功能:
跟进下一级url:
慕课网的课程是分布在去多个页面的,所以为了完整的爬取信息课程信息,我们需要进行url跟进。
为了完成这个目标需要对MySpider.py
文件进行如下更改
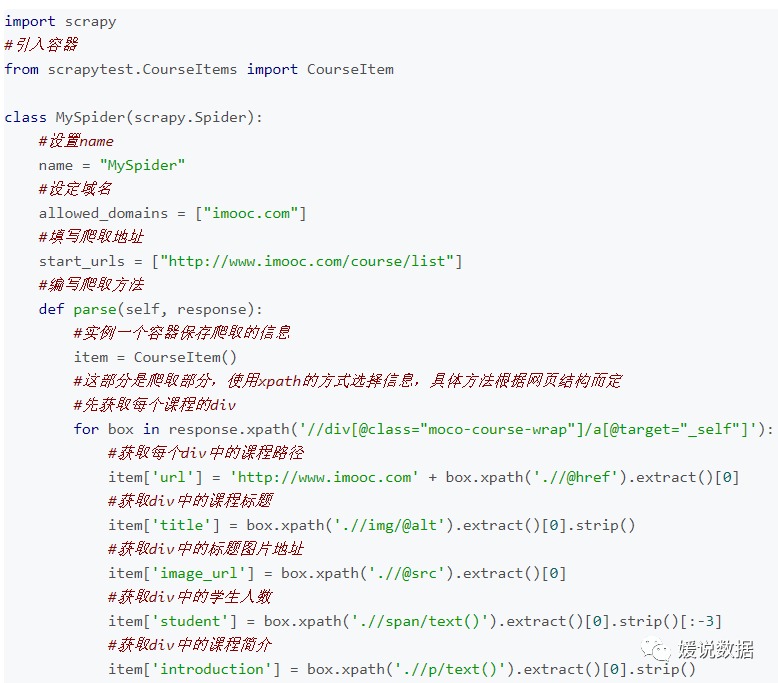

加代码前后对比:
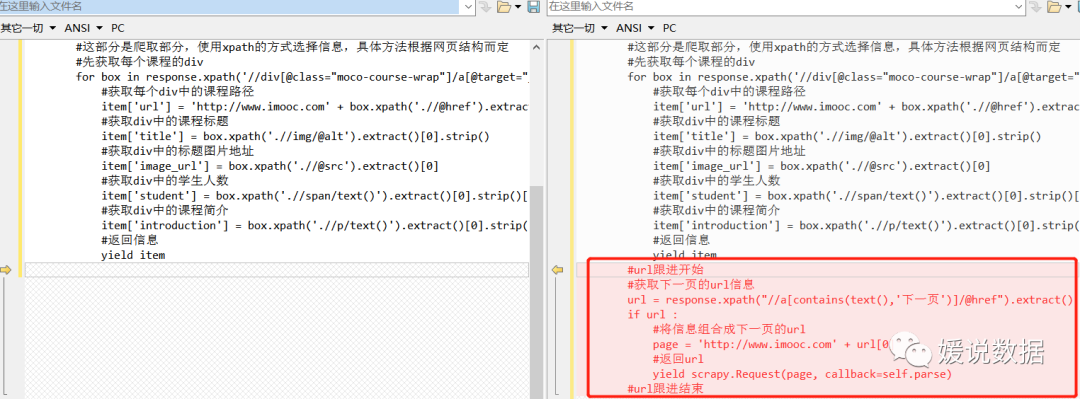
修改成功后就可以自动进行url跟进了。
下载图片
在上文我们爬取了慕课网全部的课程信息,但是每个课程的标题图片我们只获得了url并没有下载下了,这里我们进行图片下载的编写。
首先我们在CourseItems.py
文件中添加如下属性
#图片地址image_path = scrapy.Field()
接下来我们需要创建一个Pipeline用来下载图片。
这里我们创建一个ImgPipelines.py
代码如下:
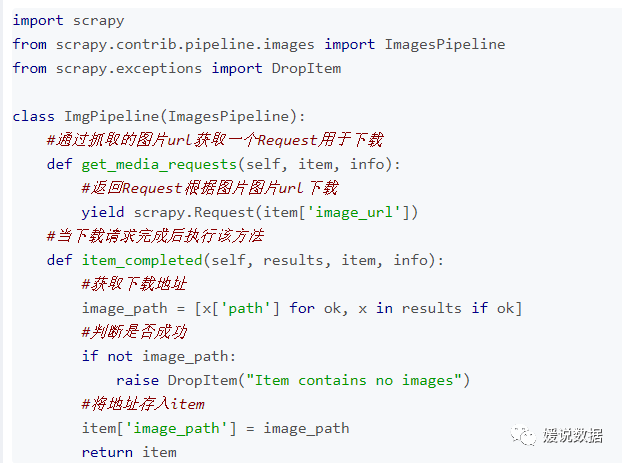
这里我们使用的是Scrapy提供的ImagesPipeline,这个pipeline专门进行图片的下载,
这里、主要用到两个方法:get_media_requests() 和item_completed()
get_media_requests(item, info)方法是通过抓取的图片url来返回一个Request,这个Request将对图片进行下载。
在下载请求完成后(下载成功或失败)就会调用item_completed()方法。
item_completed(results, items, info)
方法在下载请求完成后执行.
参数results包含三个项目
这里我们使用的是Scrapy提供的ImagesPipeline,这个pipeline专门进行图片的下载,
这里、主要用到两个方法:get_media_requests() 和item_completed()
get_media_requests(item, info)方法是通过抓取的图片url来返回一个Request,这个Request将对图片进行下载。
在下载请求完成后(下载成功或失败)就会调用item_completed()方法。
item_completed(results, items, info)
方法在下载请求完成后执行.
参数results包含三个项目:

该方法需要返回item供后续操作。
编写完ImgPipelines后照例需要注册一下。
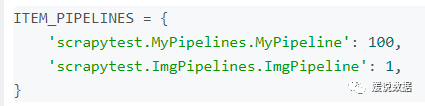
注意这里的顺序,因为我要先下载图片再获得图片的路径,所以应该先处理ImgPipeline再处理MyPipeline,所以说ImgPipeline的数字小一些。
同时,因为是下载图片这里需要注册一下保存地址,还是在settings.py
文件
这样在运行爬虫就会下载图片了,就像这样
同时注意了,因为要进行下载任务,所以说电脑不好的同学很有可能内存溢出,所以不推荐在pipeline中执行下载等任务,可以在后期处理。如果非要处理的话可以更改CONCURRENT_ITEMS参数减少并发处理item的数量来降低系统开销。
CONCURRENT_ITEMS属性默认为100,就是同时处理100个item可以适当降低,实在不行就是1。
总结
把多余的文件删除后的目录结构
上面的处理结束后我们就成功的抓取了慕课网的全部课程信息了。
03
—
单机如何处理成分布式爬虫
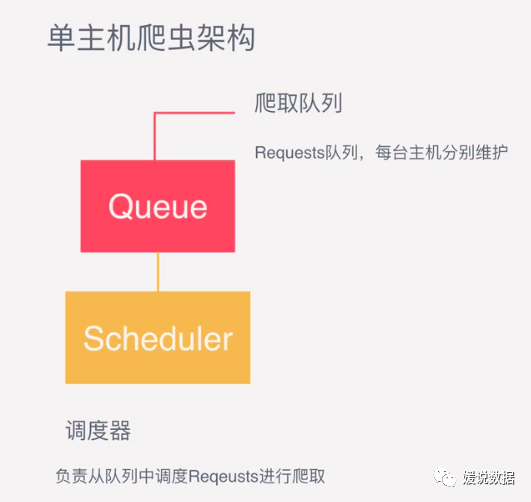
由上面02点可以知道,scrapy单机模式,通过一个scrapy引擎通过一个调度器,将Requests队列中的request请求发给下载器,进行页面的爬取。
单机处理架构如下:
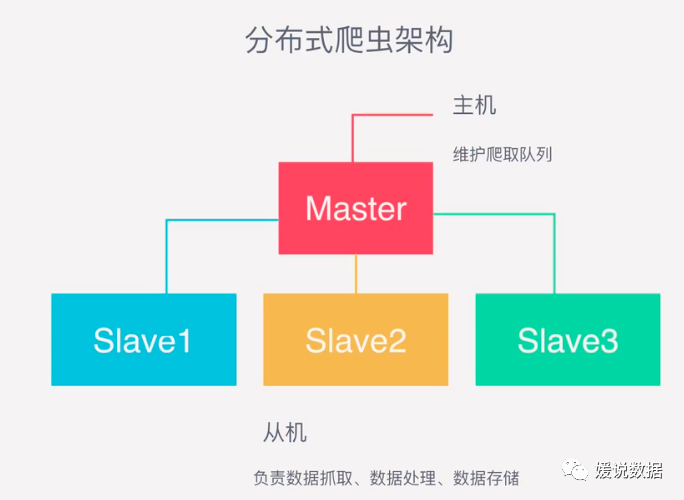
那么分布式多台主机协作的关键是共享一个爬取队列。
将爬虫继承的类从 scrapy.Spider 变成 scrapy_redis.spiders.RedisSpider(或者先import (from scrapy_redis.spiders import RedisSpider));或者是从 scrapy.CrawlSpider 变成 scrapy_redis.spiders.RedisCrawlSpider。
将爬虫中的start_urls删掉。增加一个redis_key="xxx"。这个redis_key是为了以后在redis中控制爬虫启动的。爬虫的第一个url,就是在redis中通过这个发送出去的。
修改配置文件:
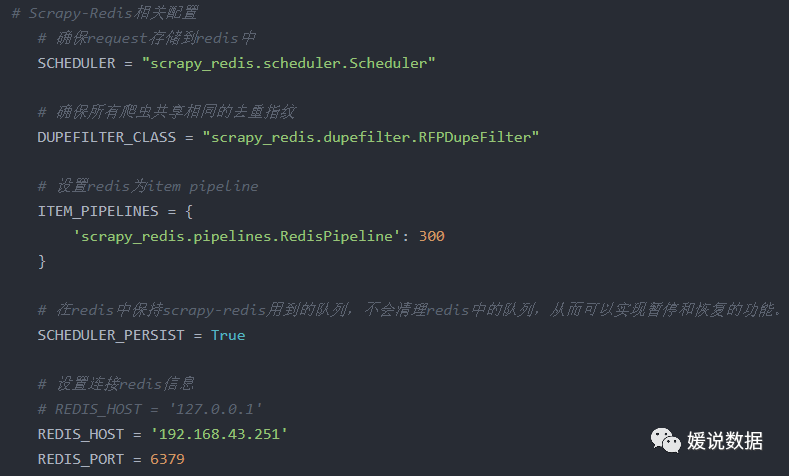
运行爬虫:
在爬虫服务器上。进入爬虫文件所在的路径,然后输入命令:scrapy runspider [爬虫名字]。
在Redis服务器上,推入一个开始的url链接:redis-cli> lpush [redis_key] start_url开始爬取。
#我是媛姐,一枚有多年大数据经验的程序媛,打过螺丝搬过砖,关注数仓,关注分析。愿你我走得更远!
