




“ "大数据架构中,kafka充当一个消息组件的角色,但是如果在数仓中接入一个kafka,怎么快速接入?要注意什么问题了?”
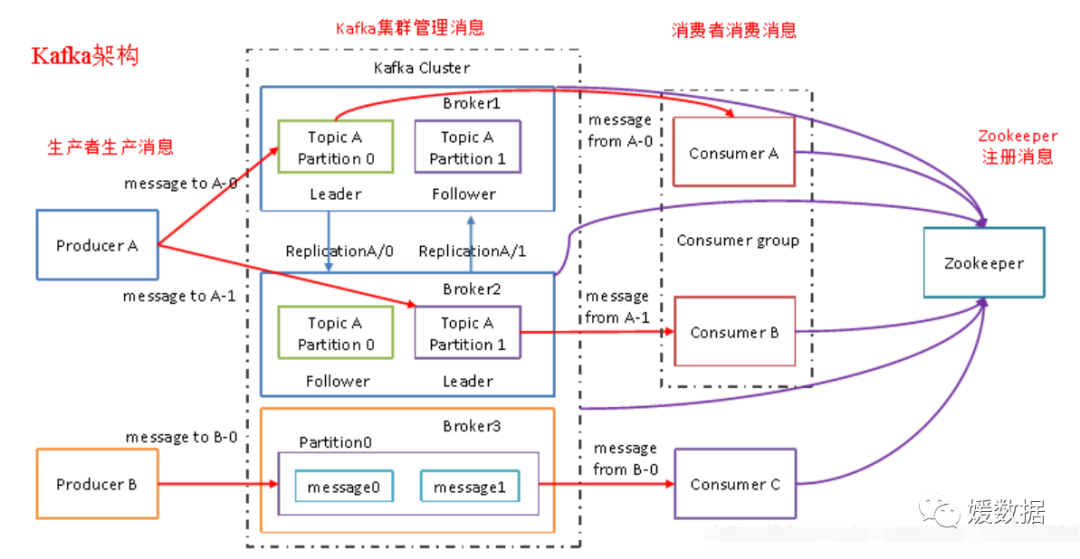
kafka的架构先回忆一波。。。
01
—
kafka的作用

为什么要用kafka?kafka大家可能都不陌生,到底我们为什么选择kafka呢?
首先kafka是一个消息队列,作为消息队列一般会在很多场景中用到,通常可以应用于以下的场景中:
应用解耦
系统交互时,很难一次性就设计出非常完善的接口,可能会随着业务发展,这些交互接口也会不断的变迁,这是可能就需要考虑引入一种基于数据的接口层(消息队列),这样各个系统可以独立的扩展或修改自己的处理过程,只要保证他们准守实现设计的数据格式约束。解耦的同时也提高了系统的稳定性(某个组件失效不会影响其他部分正常运行)和扩展性(可以横向扩展系统以增加处理消息的能力)。
场景说明:用户下单后,订单系统需要通知库存系统。
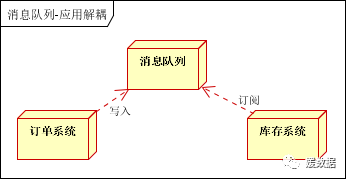
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
异步处理
有时候我们的业务逻辑可能涉及到很多步骤,而且这些步骤可能上下关联性不是很强,如果我们串行执行时,总耗时=每个步骤耗时之和,如果我们让每个步骤并行处理,总耗时< 每个步骤耗时之和,在这里我们就可以引入消息队列,将每个处理步骤发送到消息队列,并且针对每个处理步骤都有对应的线程去监听,这样就能达到串行执行异步化转为并行执行,从而提高系统的的吞吐量。
传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
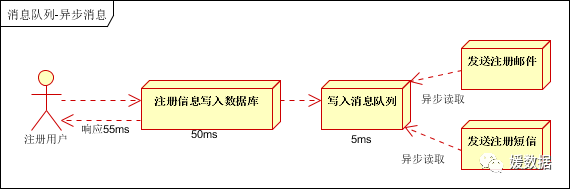
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍。
流量削峰
在秒杀或抢购活动中,一般会因为流量暴增,应用因处理不过来而挂掉,此时一般会引入消息队列,这样流量会先进入消息队列,我们的应用再根据自己的实际处理能力来消费这些消息,从而达到缓解流量暴增对系统构成的压力
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
可以控制活动的人数,可以缓解短时间内高流量压垮应用!
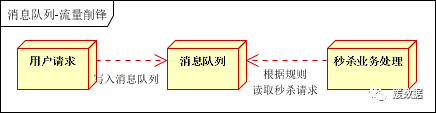
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面
秒杀业务根据消息队列中的请求信息,再做后续处理
日志处理
有时我们需要采集日志,系统运行中会产生大量的日志,尤其是在流量高峰时,而这项日志需要存储在其他地方,一般进行其他的计算或处理,日志在写入磁盘此时,由于磁盘IO速度可能不是很快,会对系统造成压力,这时我们就可以引入比较高性能的消息队列(kafka往往会被用到),消息队列可以起到缓冲作用。
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下
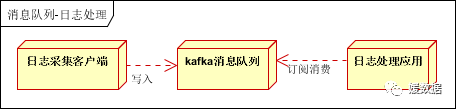
日志采集客户端,负责日志数据采集,定时写受写入Kafka队列
Kafka消息队列,负责日志数据的接收,存储和转发
日志处理应用:订阅并消费kafka队列中的日志数据
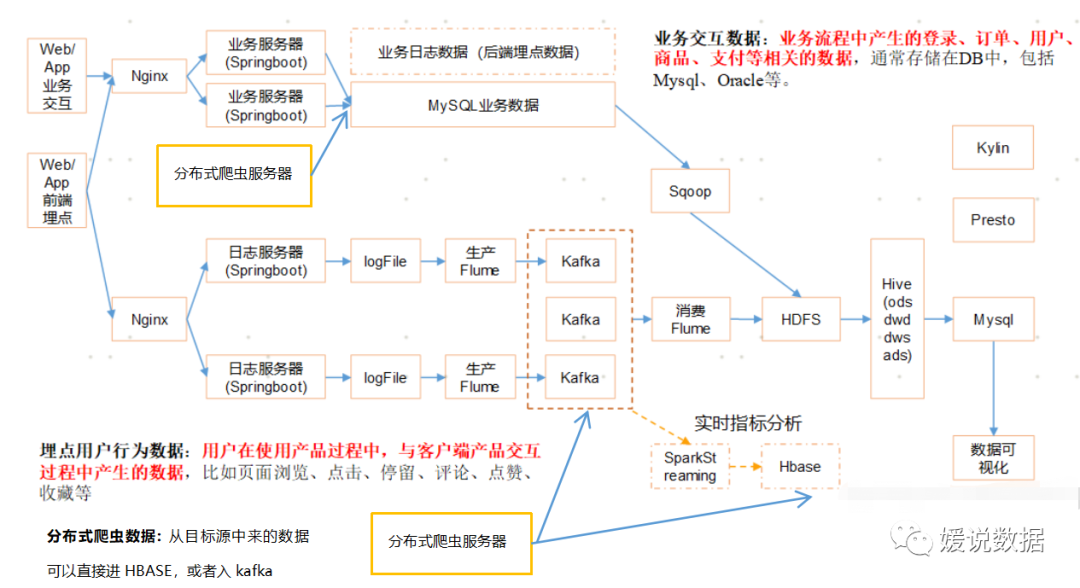
在通用的数仓架构、离线处理部分,我们很多时候可以看到kafka组件的身影:
消息通信
消息队列一般都内置了高效的通信机制,有点对点通信,也有发布订阅式通信,因此也可以用在纯的消息通讯。
冗余存储
消息队列一般会把消息存储起来,只有消费完成后,才把消息删除,这样就防止了某些时候因为处理异常,而导致消息丢失的问题
实时数仓分析
Kafka通常用于实时流式数据体系结构以提供实时分析。由于Kafka是一个快速,可扩展,耐用和容错的发布、订阅消息传递系统,Kafka被用于JMS,RabbitMQ和AMQP可能因为数量和响应速度而不被考虑的情况。Kafka具有更高的吞吐量,可靠性和复制特性,使其适用于跟踪服务呼叫(跟踪每个呼叫)或跟踪传统MOM可能不被考虑的物联网传感器数据。Kafka可以与Flume Flafka,Spark Streaming,Storm,HBase,Flink和Spark一起工作,以实时接收,分析和处理流数据。Kafka是用于提供Hadoop大数据湖泊的数据流。Kafka代理支持在Hadoop或Spark中进行低延迟后续分析的大量消息流。此外,Kafka流媒体(一个子项目)可用于实时分析。
上面的离线日志也已经说明了其中的架构。
02
—

kafka怎么接入数仓
那么kafka怎么才能接入数仓系统?我们常见就是flume整合kafa,还有爬虫接入kafka, kafka整合了SparkStreaming。
flume整合kafka
整合会常用配置模式:扫描指定文件
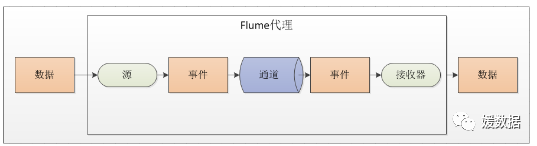
注意:(1)源将事件写到一个多或者多个通道中;(2)接收器只从一个通道接收事件;(3)代理可能会有多个源、通道与接收器。


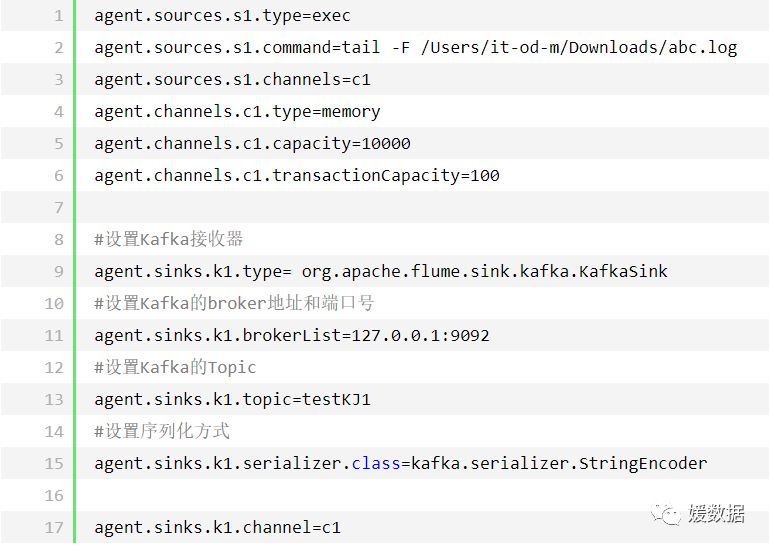
与Kafka结合时,通常采用这种配置模式
配置好参数以后,使用如下命令启动Flume:
1 |
|
最后一行显示Component type:SINK,name:k1 started表示启动成功.
说明:在启动Flume之前,Zookeeper和Kafka要先启动成功,不然启动Flume会报连不上Kafka的错误。


爬虫系统整合kafka
分布式爬虫一般采用scrapy框架,而scrapy框架和其它组件整合的核心在于pipline通道。
比如会设计成下列通用的项目结构:
consumer --- pykafka的消费者模块(测试接收以及之后接收爬虫数据)
producer --- pykafka的生产者模块(测试发送)
scrapy_kafka --- Scrapy + pykafka的爬虫(爬的目的网站)
以下是pipeline的代码, 主要也就是这部分和Kafka进行数据交互



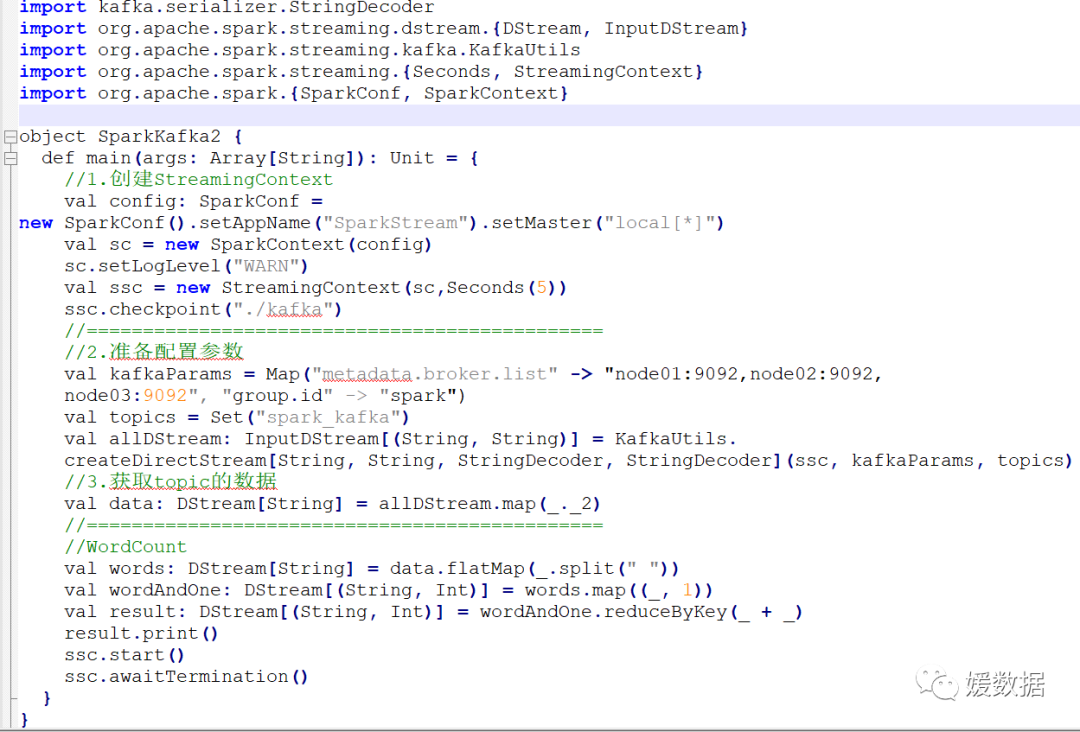
kafka整合SparkStreaming
kafka整合kafka通常有两种模式:
Receiver接收方式 和 Direct直连方式,
KafkaUtils.createDirectStream是开发中使用,要求掌握,
Direct方式会定期地从kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者API读取一定范围的数据。
Direct的缺点是无法使用基于zookeeper的kafka监控工具
Direct相比基于Receiver方式有几个优点:
简化并行
不需要创建多个kafka输入流,然后union它们,sparkStreaming将会创建和kafka分区数一样的rdd的分区数,而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的分区数据是一一对应的关系。
高效
Receiver实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,第一次是被kafka复制,另一次是写到WAL中。而Direct不使用WAL消除了这个问题。
恰好一次语义(Exactly-once-semantics)
Receiver读取kafka数据是通过kafka高层次api把偏移量写入zookeeper中,虽然这种方法可以通过数据保存在WAL中保证数据不丢失,但是可能会因为sparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次。
Direct的Exactly-once-semantics(EOS)通过实现kafka低层次api,偏移量仅仅被ssc保存在checkpoint中,消除了zk和ssc偏移量不一致的问题。
API
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
03
—
kafka三剑客:保证数据可靠性
ISR、ACK、HW 低水位,三个底层原理保证数据可靠性
ISR确保了leader和follower信息同步的状态,而ack应答机制是producer和broker(leader和follower)间信息传输状态的保证,而HW策略是leader和follower信息不同步的时候的处理机制,这三个底层原理,保证了kafka数据传输的可靠性。
ack应答机制:
ack应答机制,ack可以看做一种信号,用于消费者来确认消息是否落盘
ack应答机制包括两个方面:
1.producer发送消息到leader收到消息之后发送ack
2.leader和follower之间同步完成数据会发送ack
其中kafka应答机制用的-1,即最慢、可靠的模式
Kafka producer有三种ack机制 初始化producer时在config中进行配置
ack=0
意味着producer不等待broker同步完成的确认,继续发送下一条(批)信息。提供了最低的延迟。但是最弱的持久性,当服务器发生故障时,就很可能发生数据丢失。例如leader已经死亡,producer不知情,还会继续发送消息broker接收不到数据就会数据丢失
ack=1
意味着producer要等待leader成功收到数据并得到确认,才发送下一条message。此选项提供了较好的持久性较低的延迟性。Partition的Leader死亡,follwer尚未复制,数据就会丢失
ack=-1
意味着producer得到follwer确认,才发送下一条数据。持久性最好,延时性最差。
三种机制性能递减,可靠性递增。
ISR(In-Sync Replicas ):与leader保持同步的follower集合。ISR(in sync replica)的含义是同步的replica,相对的就有out of sync replica,也就是跟不上同步节奏的replica,现在面临的有两个问题,当replica 跟不上进度时该怎么处理(或原本跟不上节奏的现在又跟上节奏了该如何处理)、如何去判定跟不跟得上节奏。
第一个问题很简单,跟上节奏就加入ISR,跟不上节奏就踢出ISR。
HW 低水位:
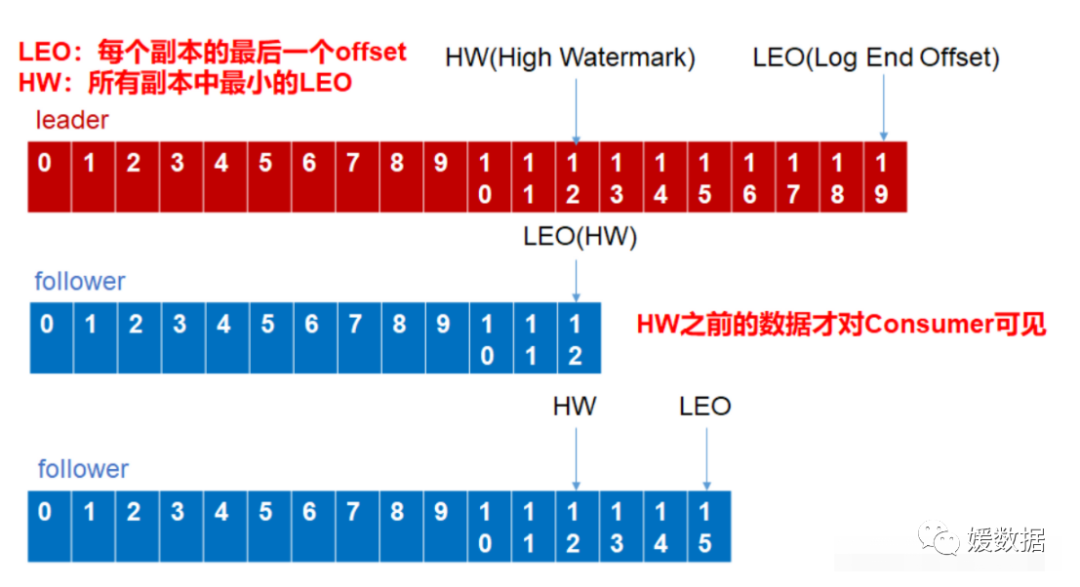
LEO:每个副本的最后一个Offset
HW:所有副本中最小的LEO
(1)follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
(2)leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。(是否丢数据是acks保证)
04
—

kafka怎么查看偏移量
查看kafka偏移量
进入kafka的bin目录
cd opt/cloudera/parcels/KAFKA-3.0.0-1.3.0.0.p0.40/lib/kafka/bin
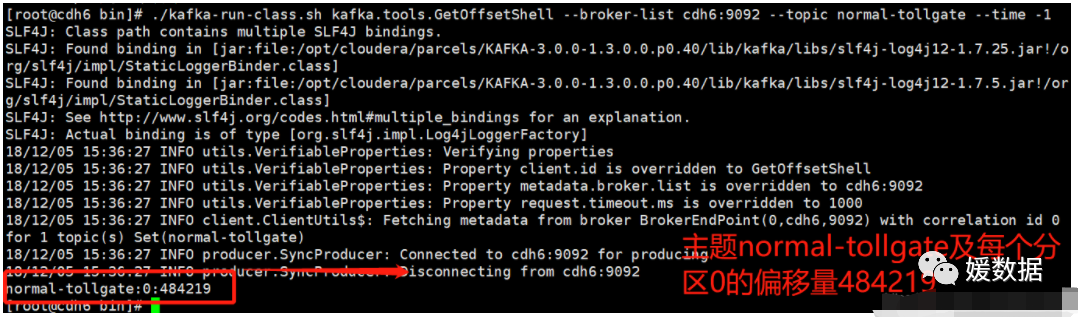
查询 topic 为 normal-tollgate 的每个Partition 的生产消息的最大偏移位置
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list cdh6:9092 --topic normal-tollgate --time -1
查看 Kafka 数据
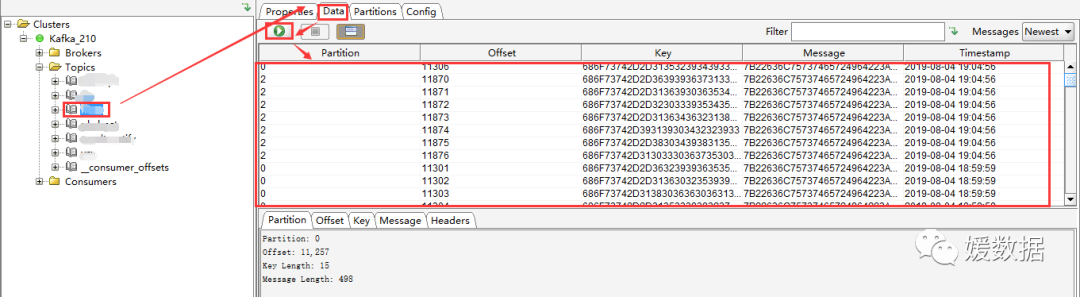
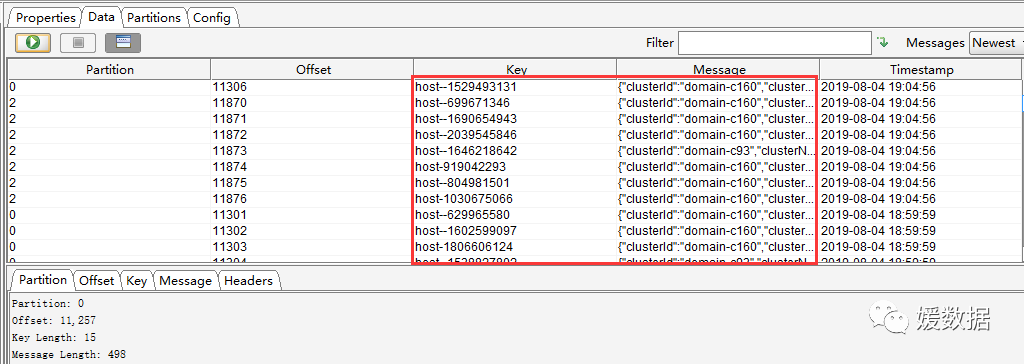
1)查看 Kafka 数据
选择一个Topic --> Data,点击查询即可看到数据(但是Key和Message是二进制的,不能直观的看到具体的消息信息,需要设置展示格式)
Messages选择Newest,表示查看最新的Kafka数据;
结果列表中的每列,通过点击表头,可以按照升序或者降序排序(一般用在时间字段排序,方便查看最新数据)。
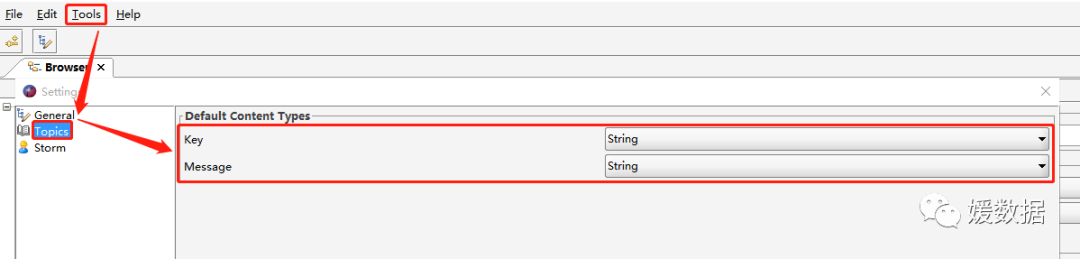
2)设置 Kafka 数据展示格式
在Tools -->Settings --> Topics,将 Key 和 Message 均设置为String 保存。这样是全局设置,对所有 Topic 均生效。

如果只是想单独设置某个 Topic,可以选中某个 Topic,在 Properties --> Content Type 中,将显示格式设置为String,点击 Update --> Refresh 即可生效
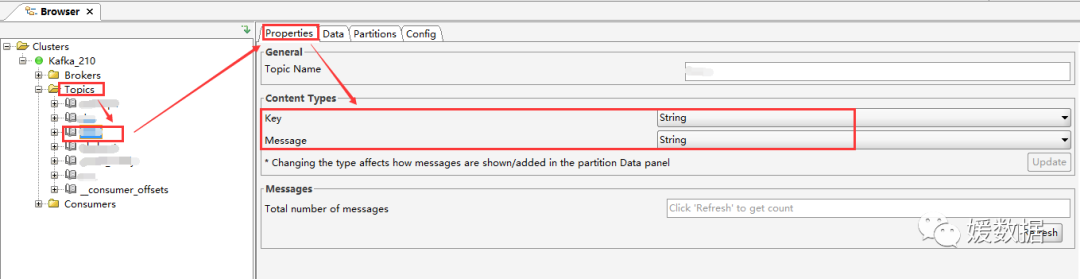
设置后的数据列表如下
05
—

kafka怎么压测数据支撑能力
使用用Kafka自带的脚本进行压力测试。
测试平台:CDH6.2,Kafka2.1
Kafka压测可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO),一般都是网络IO达到瓶颈。
1.kafka-producer-perf-test.sh
2.kafka-consumer-perf-test.sh
Kafka Producer压力测试

record-size 单条信息大小,字节单位。
num-records 总共发送多少条信息。
throughput 每秒多少条信息。
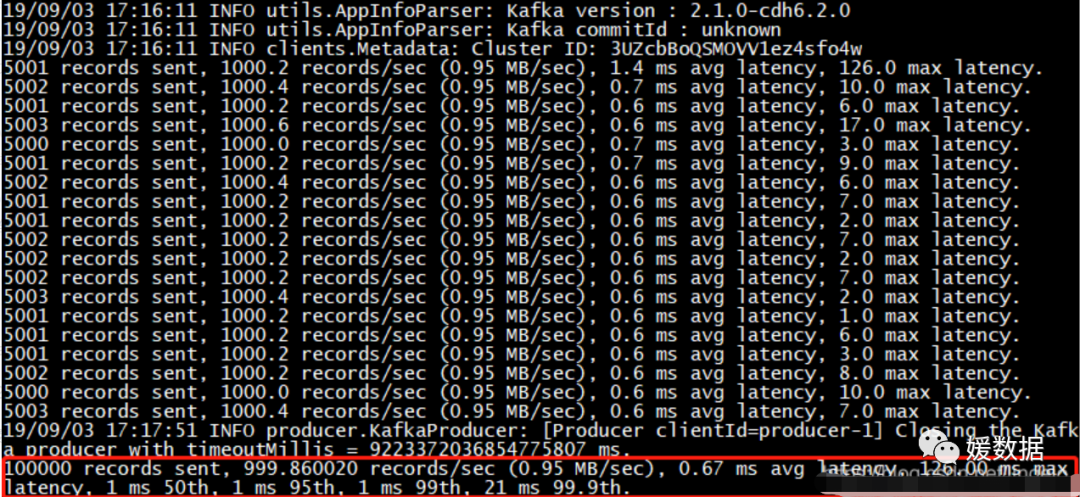
说明:
一共写入10w条消息,平均1000条消息/秒,每秒向Kafka写入了0.95MB的数据,写入的平均延迟为0.67毫秒,最大的延迟为126毫秒。后三个参数,1毫秒内的数据占比50,95,99,21毫秒内数据占比99.9。
Kafka Consumer压力测试

--broker-list broker节点列表
--fetch-size 每次fetch的数据的大小
--messages 共消费的消息数
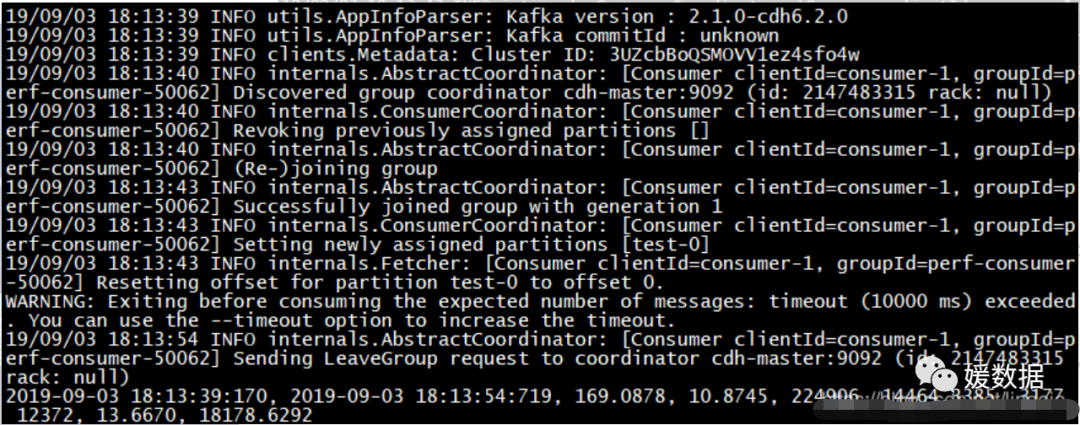
说明:
2019-09-03 18:13:39:170, 2019-09-03 18:13:54:719, 169.0878, 10.8745, 224906, 14464.3385, 3177, 12372, 13.6670, 18178.6292
开始测试时间,测试结束时间,总消费169.0878MB,平均每秒消费10.8745MB/s,总消费224906条,平均每秒消费14464.3385条,负载3177毫秒,fetch消耗12372毫秒,fetch数据13.6670MB/s,fetch18178.6292条/s。
#我是媛姐,一枚有多年大数据经验的程序媛,打过螺丝搬过砖,关注数仓,关注分析。愿你我走得更远!

点个

在看
你最好看
