





分享嘉宾:常冰琳 StarRocks
编辑整理:刘陈亮 中软国际
出品平台:DataFunTalk
实时更新需求 StarRocks 实时更新实现 当前和未来工作
01
实时更新需求
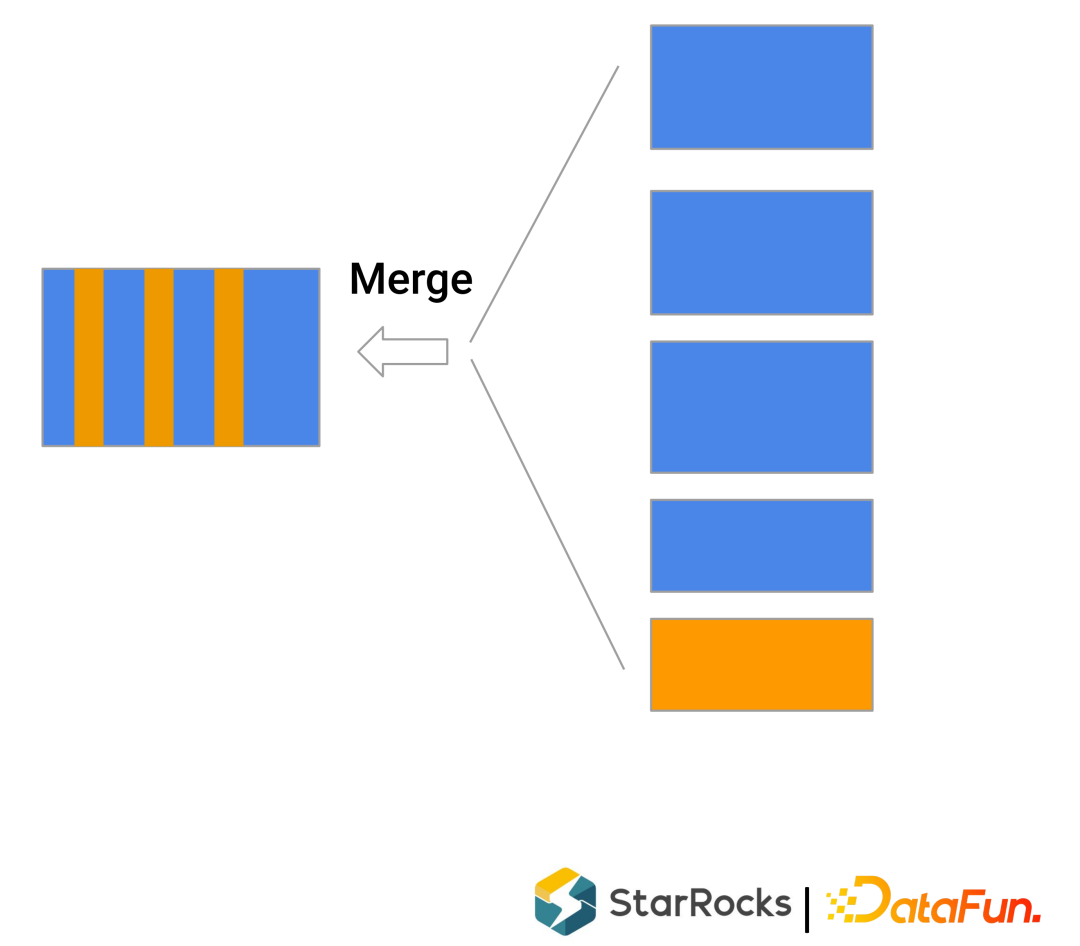
最常使用的就是 T+1 批量ETL方式导入数据,同时通过Overwrite方式实现更新数据的导入。这种方式延迟会比较高,不太适合实时更新的需求。 增量不停的导入数据,数据只能追加(append only),不能更新(update),只能插入(insert)。这在实时日志分析、广告等场景都会用到。 追加更新数据,底层使用MOR(merge-on-read)方式来支持更新(类似LSM结构【日志结构合并树】)。这种方式能完美解决实时更新的需求,但是merge-on-read对查询的性能影响比较高,不太适合实时查询场景。
摄入的数据基本是实时数据,也就是热数据,通常也会是可变的数据(volatile data),经常会被更新到。 很多HTAP的系统都支持实时数据的更新,把TP的数据实时的同步到AP系统里面(一般通过CDC的方式)。

在mysql下,插入一条数据,如果key(unique key)重复就覆盖数据行。

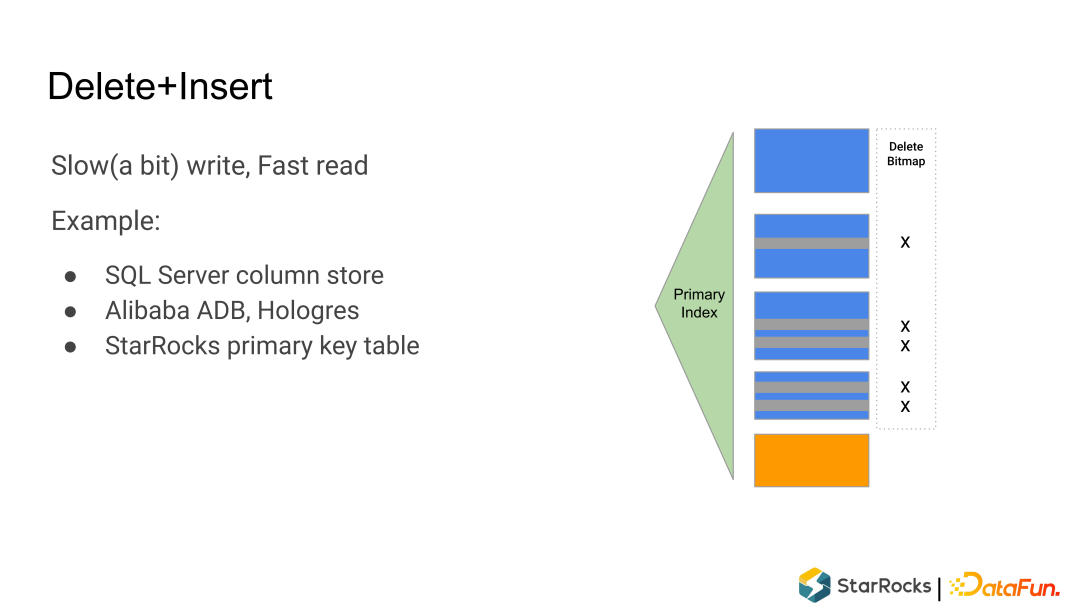
在StarRocks下,有Unique key 表支持 upsert语义,另外 StartRocks 新加了一个 Primary key 的表模型,它支持upsert和delete语义。
02
StarRocks 的实时更新
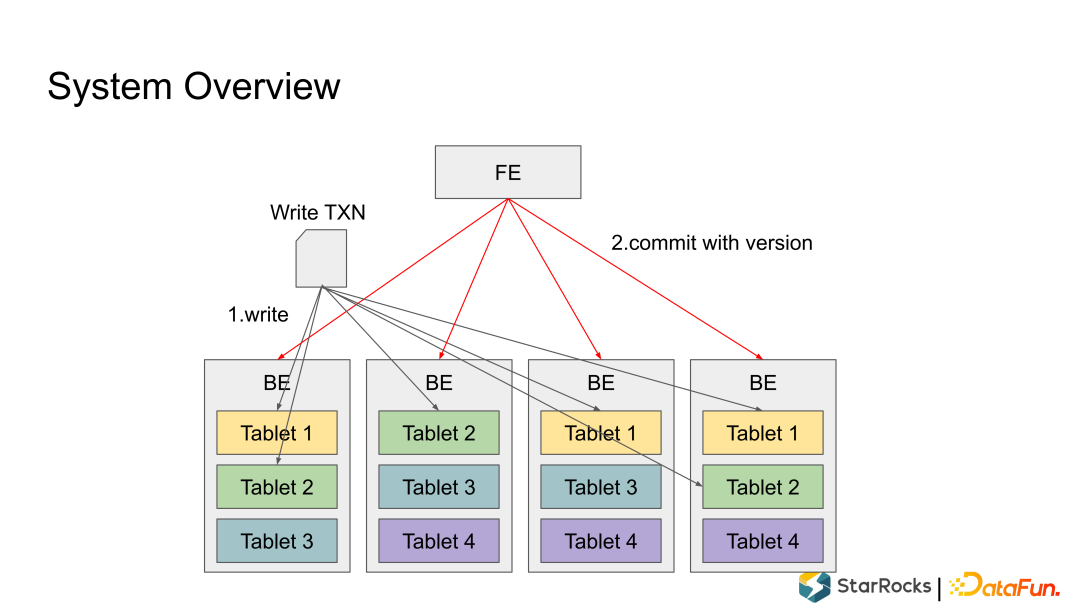
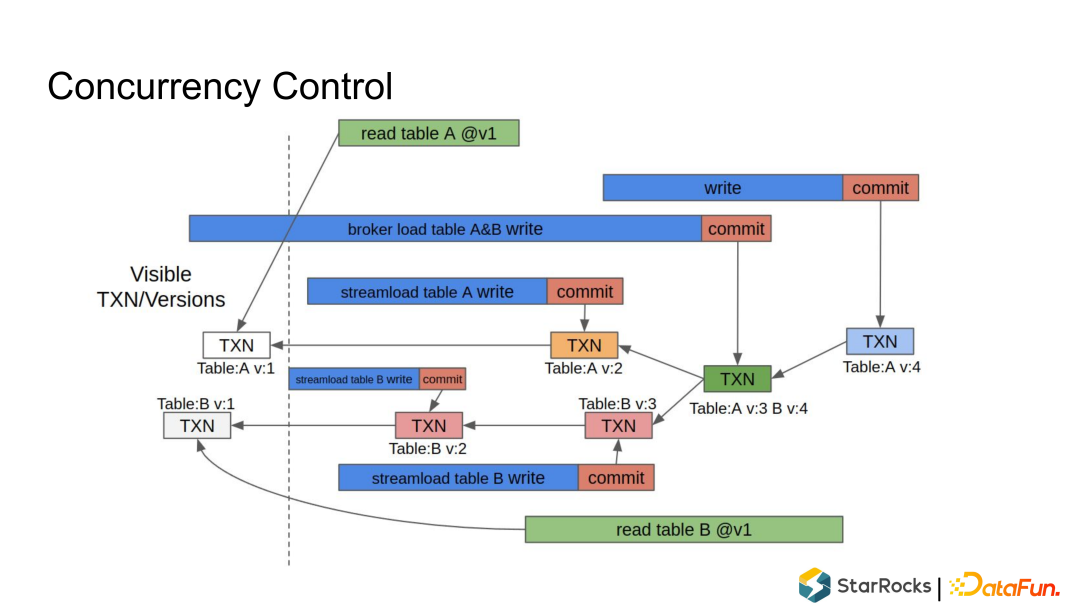
Write 阶段:在第一阶段,将写入事务的数据按照分区分桶规则分散地写入到很多的 Tablet里,每个 Tablet 收到数据后把数据写成内部的列存格式,形成一个 Rowset; Commit 阶段:所有数据都写入成功后,FE 向所有参与的 Tablet 发起事务、提交 Commit,每个 Commit 会携带一个 Version 版本号,代表 Tablet 数据的最新版本。Commit 成功后,整个事务就完成了。
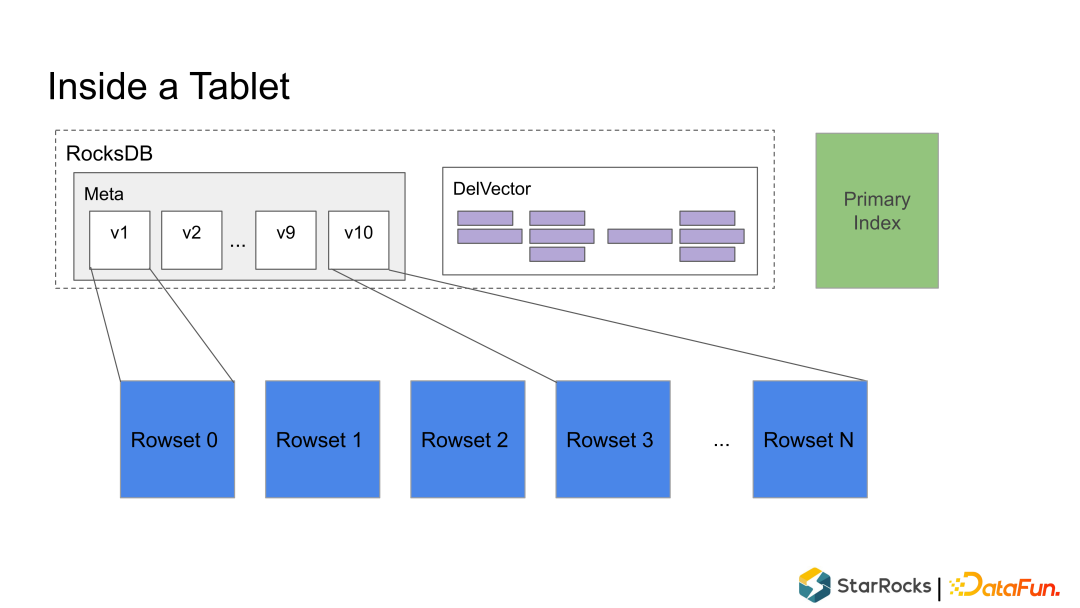
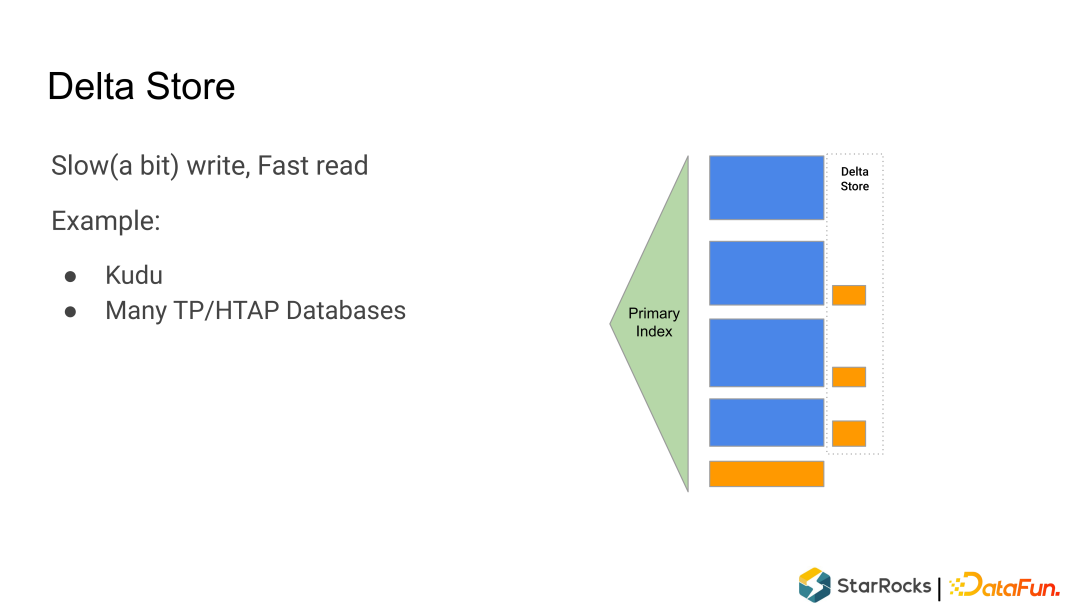
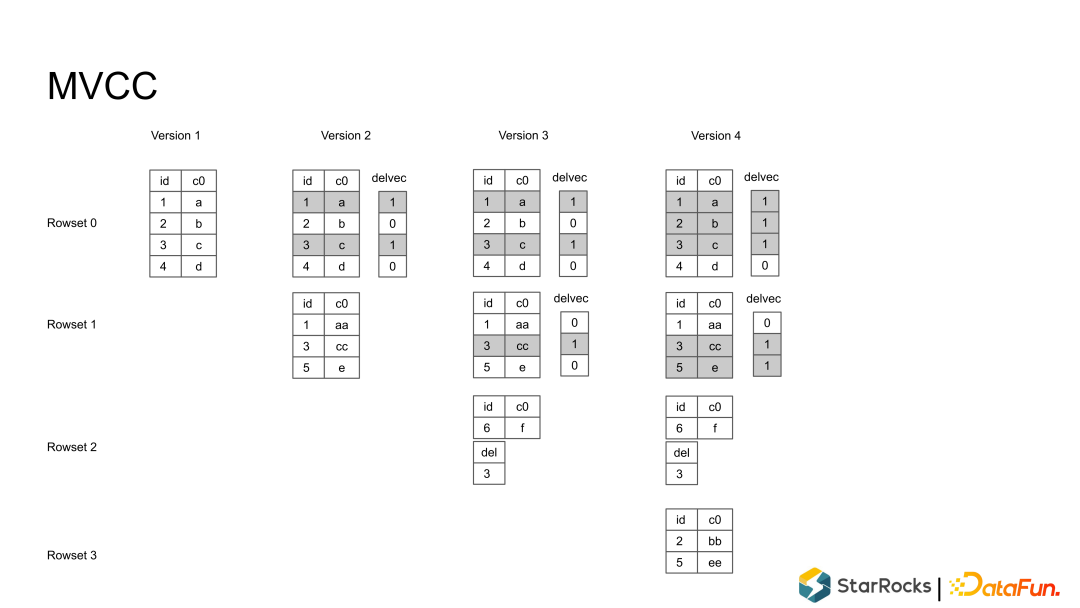
Rowset:一个 Tablet 的所有数据被切分成多个 Rowset,每个 Rowset 以列存文件的形式存储。 Meta(元数据):保存 Tablet 的版本历史以及每个版本的信息,比如包含哪些 Rowset 等。序列化后存储在 RocksDB 中,为了快速访问会缓存在内存中。 DelVector:记录每个 Rowset 中被标记为删除的行,同样保存在 RocksDB 中,也会缓存在内存中以便能够快速访问。 Primary Index(主键索引):保存主键与该记录所在位置的映射。目前主要维护在内存中,正在实现把主键索引持久化到磁盘的功能,以节约内存。

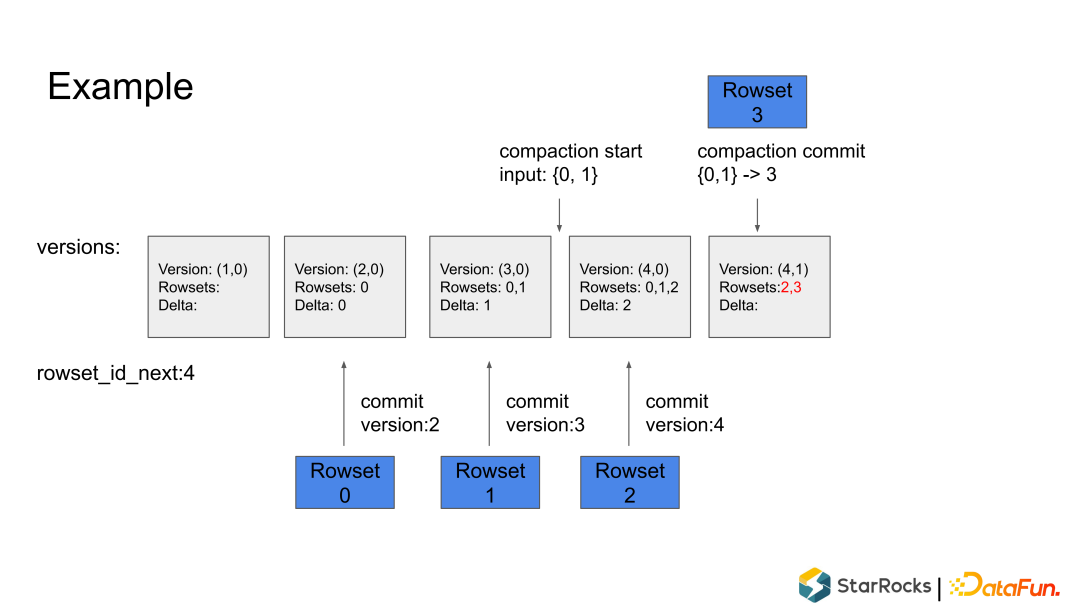
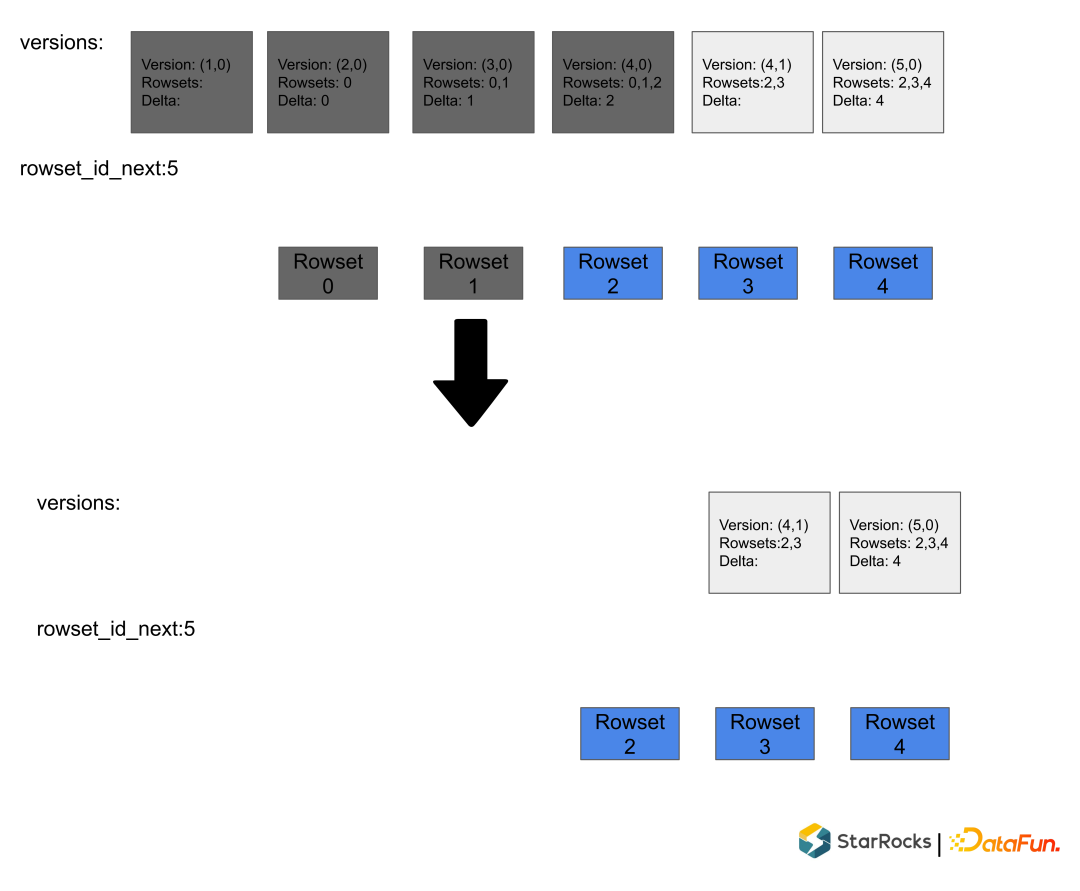
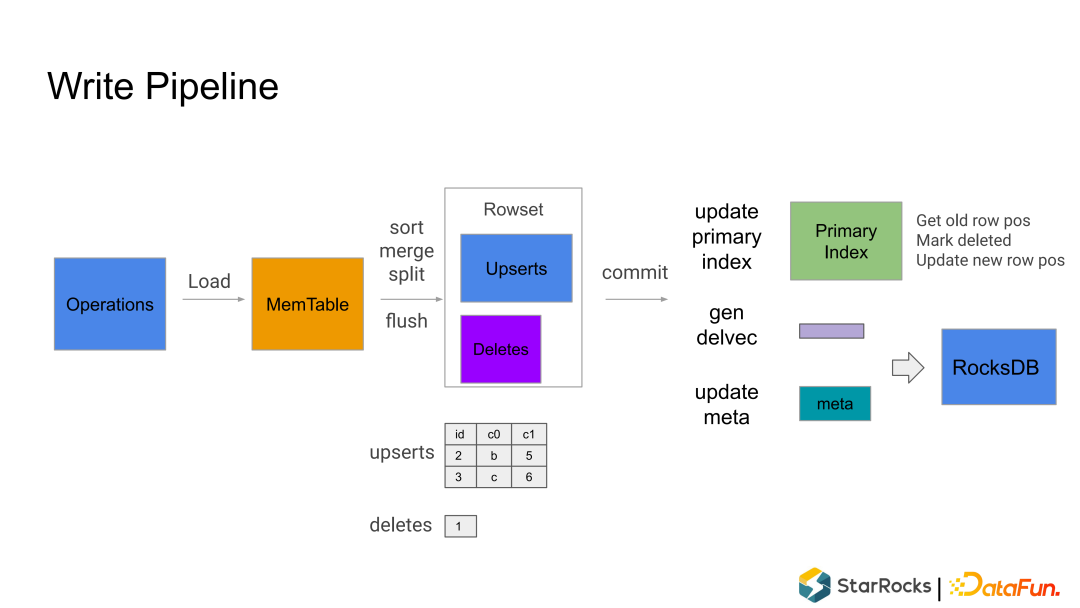
写入流程可以并发执行 但是 Commit 需要序列化(顺序)执行

Key 是主键通过二进制编码后形成的 Binary String串 Value 是一个unit64位的行位置信息,前面32位是rowset_id,后面32位是rowset内部的rowid HashMap 使用的是高性能的开源 phmap 库,每次操作耗时仅 20ns~200ns,单核可以达到 5M-50M op/s。如果一个导入事务有1千万行,要写入10个bucket,每个bucket 进行100万的hashmap的操作,这100万的操作在Primary index里面只需要0.1左右。这个commit过程是非常快的,也能保证整个系统多个写事务的并发操作。
定长主键使用定长的字符串类型(如:FixSlice) 保存到hashmap里面,就不需要保存字符串长度 变长主键设计一个shard by length的 hashmap,类似clickhouse里的hashmap,可以节约 1/2 ~ 1/3 的内存 cashe on-demand loading,如果一个表暂时没有更新操作(6分钟内没有load),就不加载到内存
优化常量和基数低的主键列,减少内存占用 使用原始列128bit hash 做为主键,风险是有可能有冲突,但是冲突概率非常低,对特定应用可用
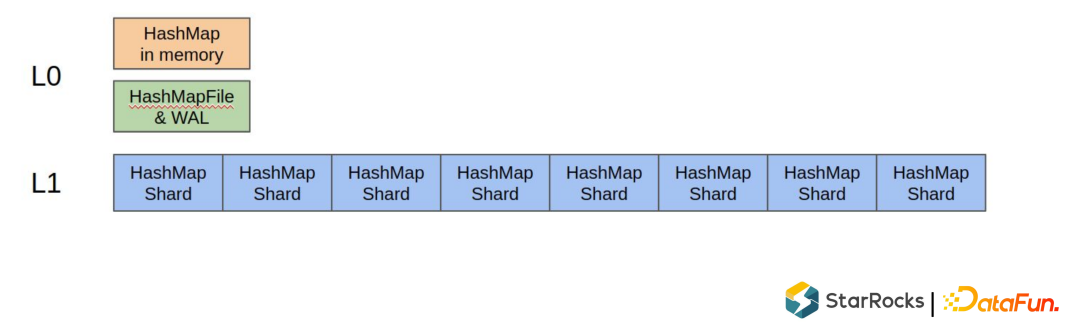
L0层 映射在内存里,有一个buffer,同时写 WAL(预写日志系统,一种高效的日志算法)或者 FlushSnapshot 。 L1层是 Shard HashMap,保存在磁盘上,每个shard 大概1M左右大小。如果有批量的读操作,可以根据 shard 把批量读操作也跟L1 shard 大小一样分成很多 bucket 。
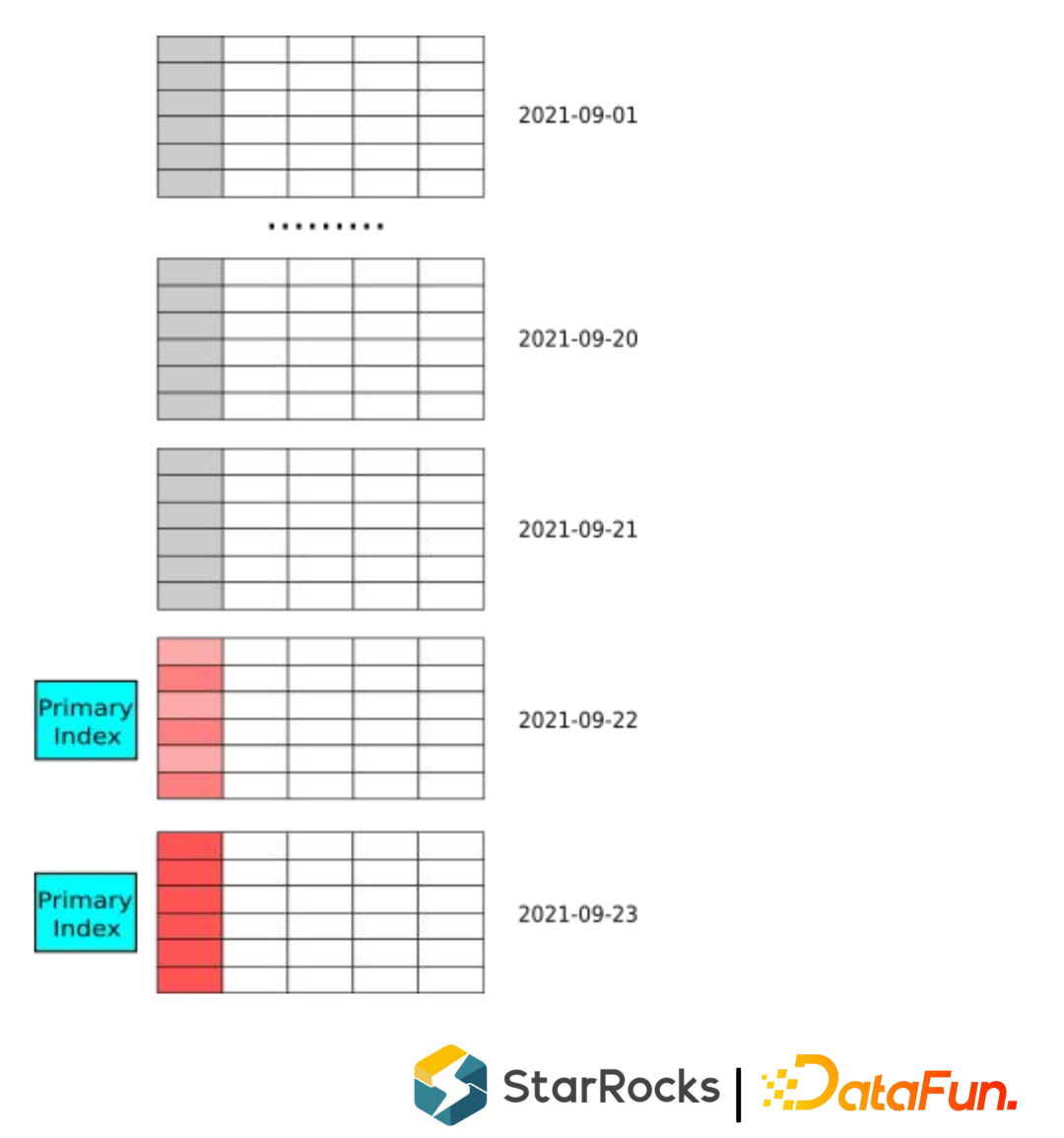
在线电商订单表 共享打车和共享单车的骑行订单数据 移动端 App 和 IOT 设备的 sessions

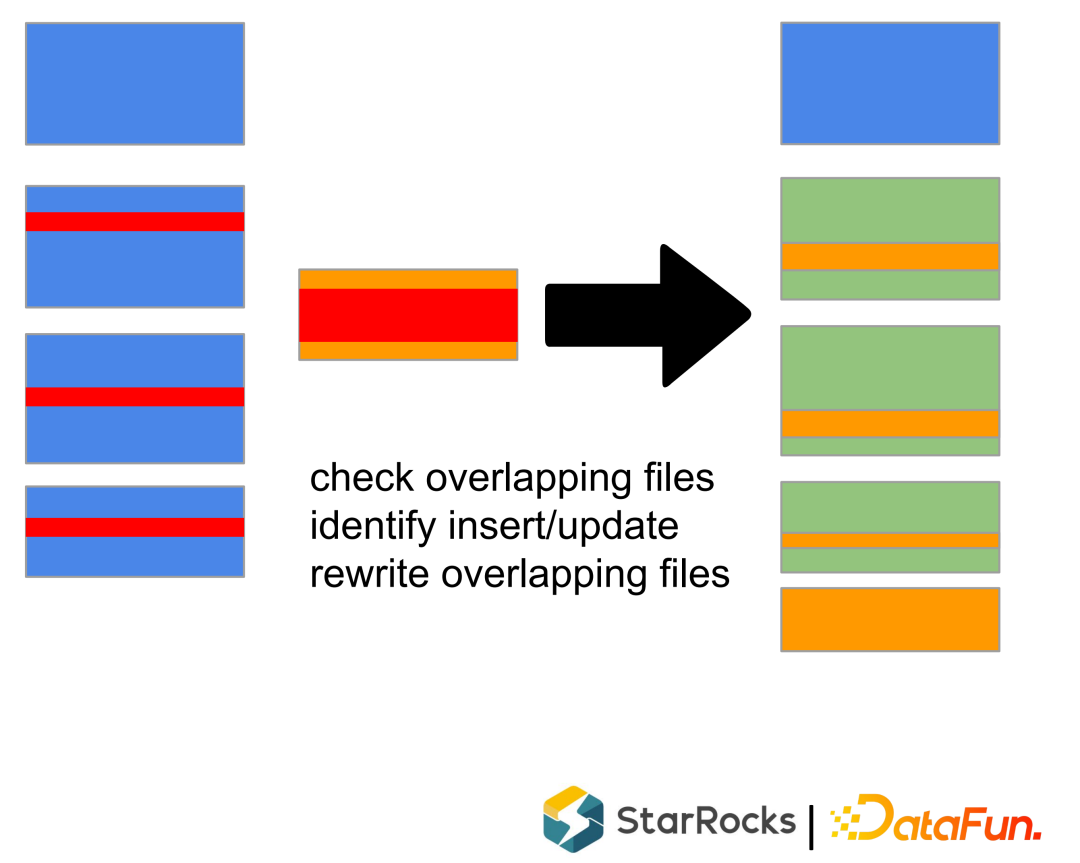
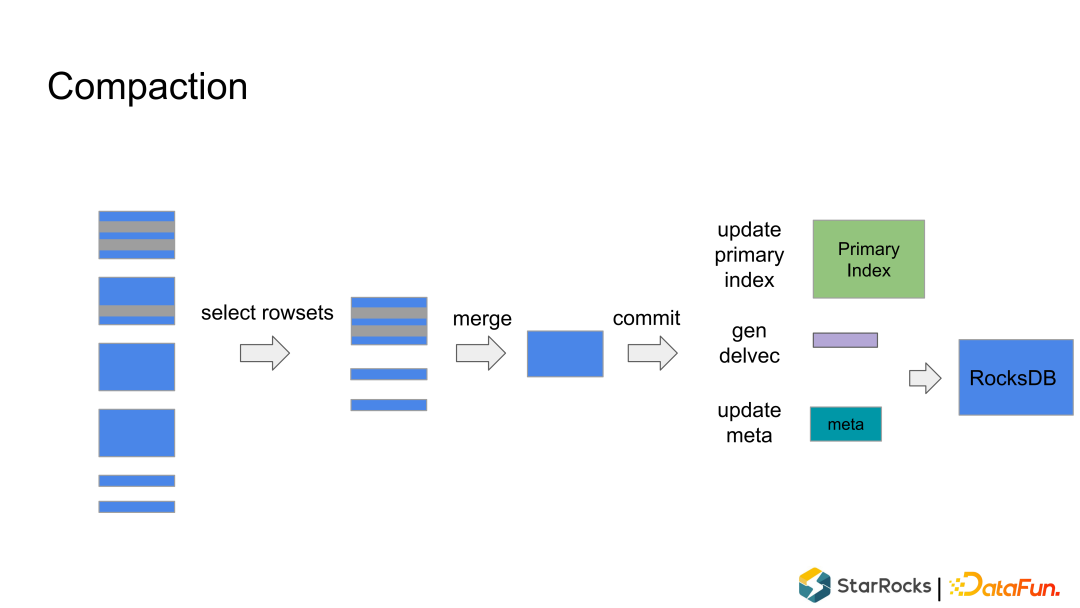
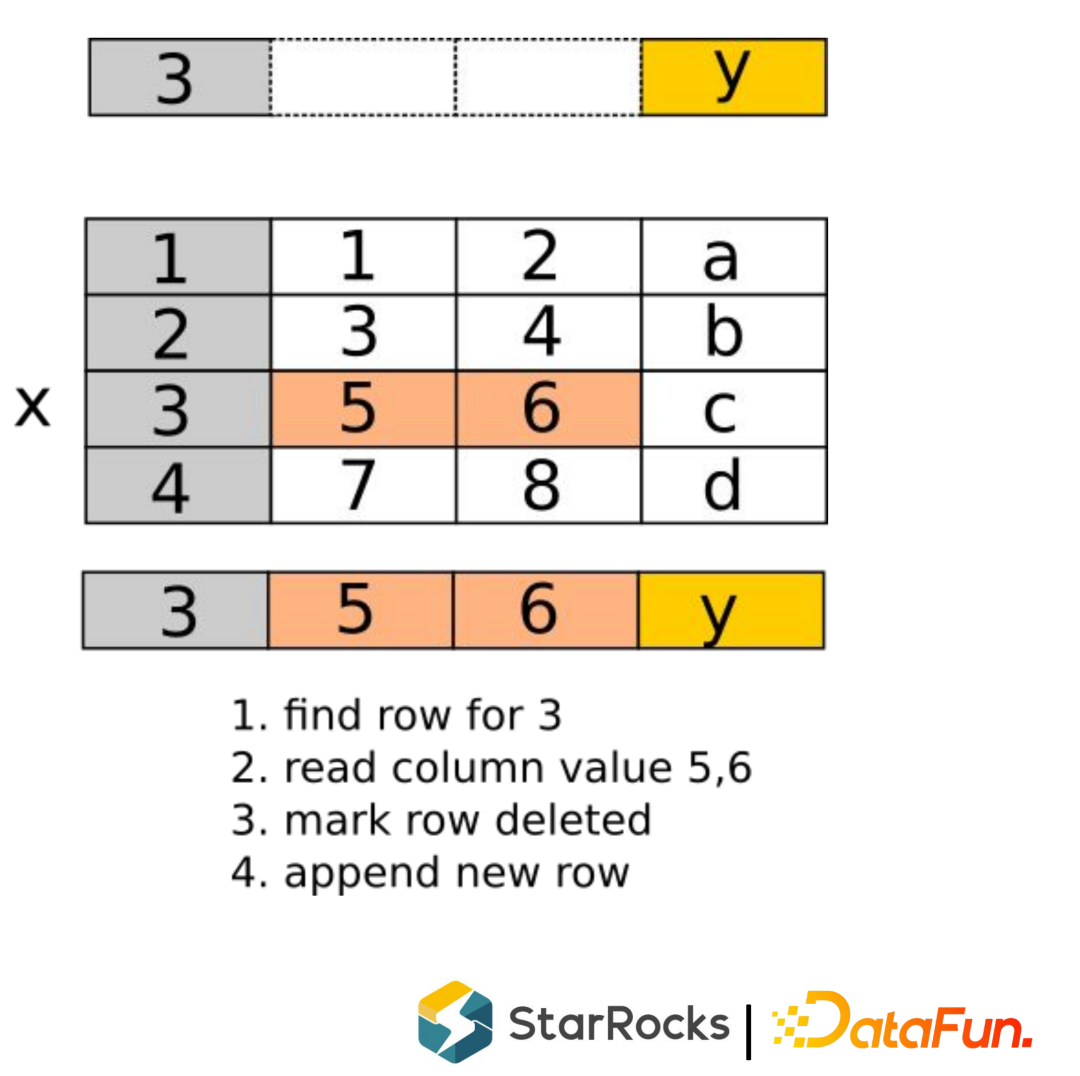
没有重复记录,不需要考虑相同Key的merge。 没有 delete range delete 的记录,rocksdb 曾经出行过 range delete bug。 由于引入了主键索引,Compaction 会使得记录的实际位置发生变化,这个变化需要同时反应到Primary Index里面, 这个数据就增加了复杂度。
根据策略,挑选一些 Rowsets。 merge Rowsets,生成新的 Rowset。 作为一个 Commit 把元数据写入到 rocksdb里面,同时生成 DelVector,在元数据中原子替换掉输入的 Rowsets 也写入到rocksdb里面。
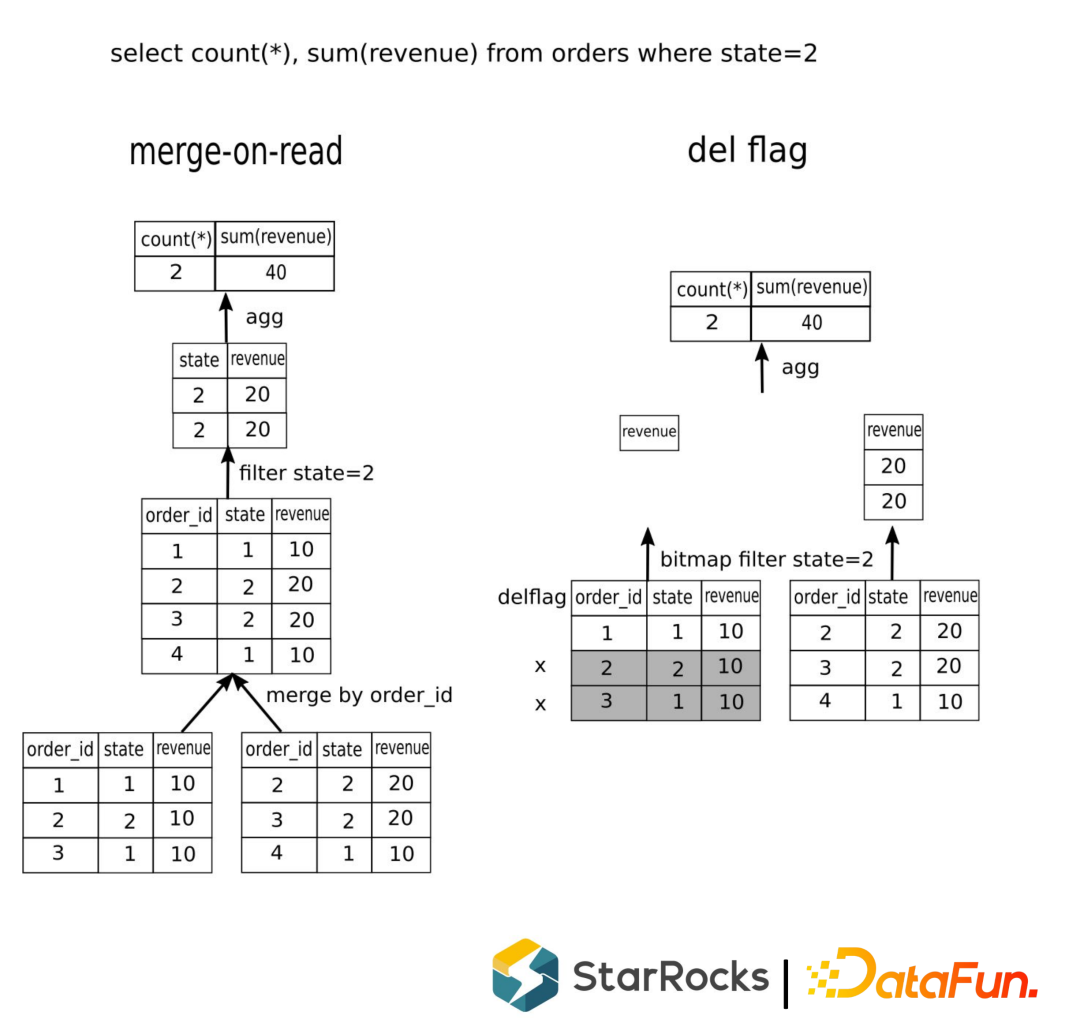
不需要 merge 操作 不需要读 order_id,省 IO 过滤条件下推,利用 bitmap 索引加速查询 只扫描返回 revenue 列
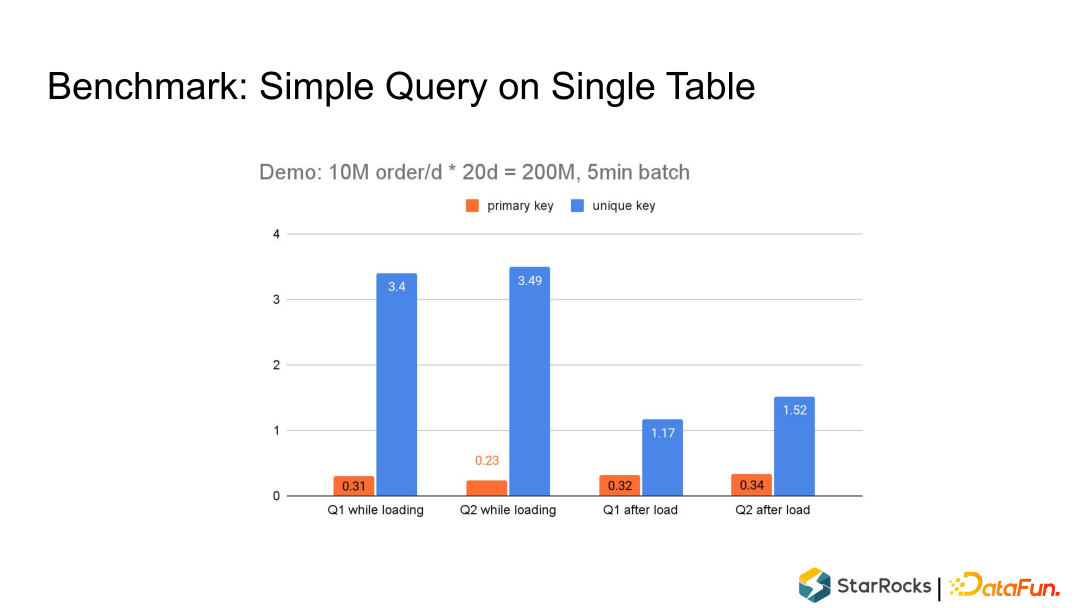
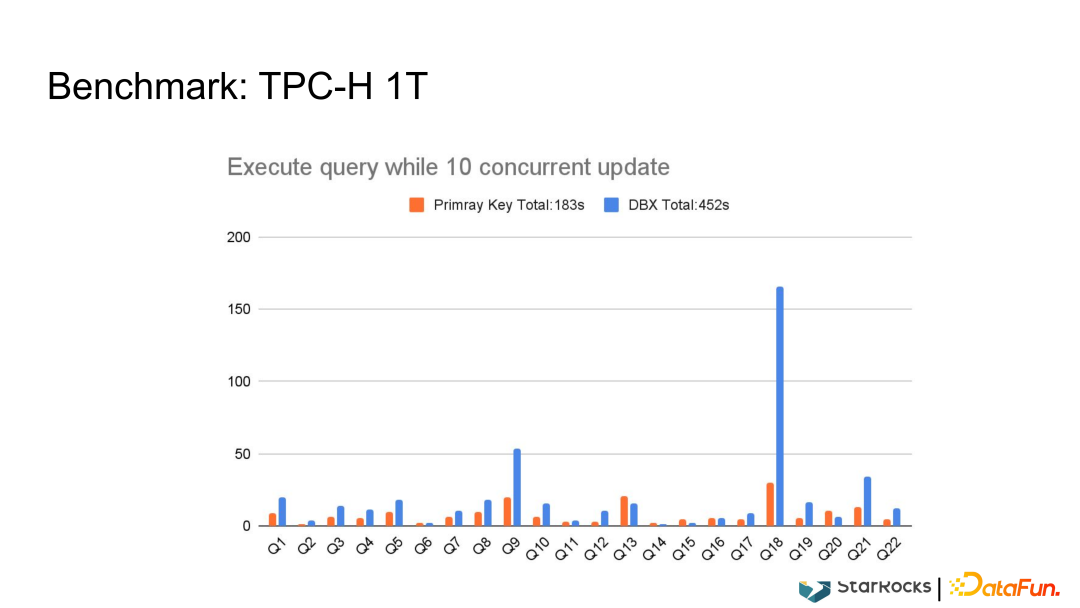
03
当前和未来工作
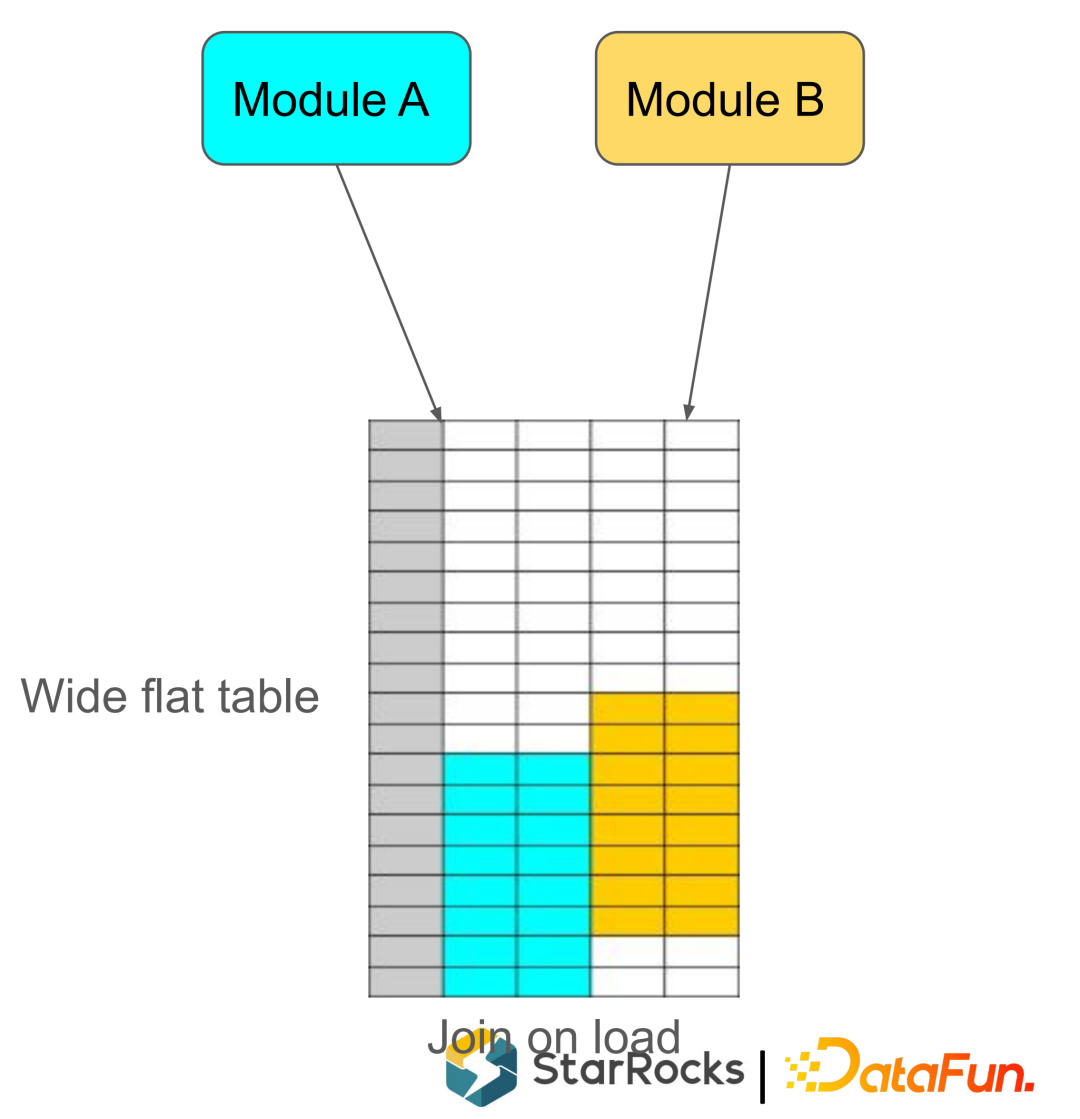
固定列的更新,比如订单表,第一次写入时大部分列已经固化,只会一些固定列比如订单状态。 某列的批量更新,比如 user_profile 表,上游有些像机器学习的任务批量更新用户标签。

大宽表,维护一个大宽表查询时不在需要 Join ,可以提高查询性能。对大宽表一般都是由两个或两个以上的Job 来导入,每个Job 只更新部分列。

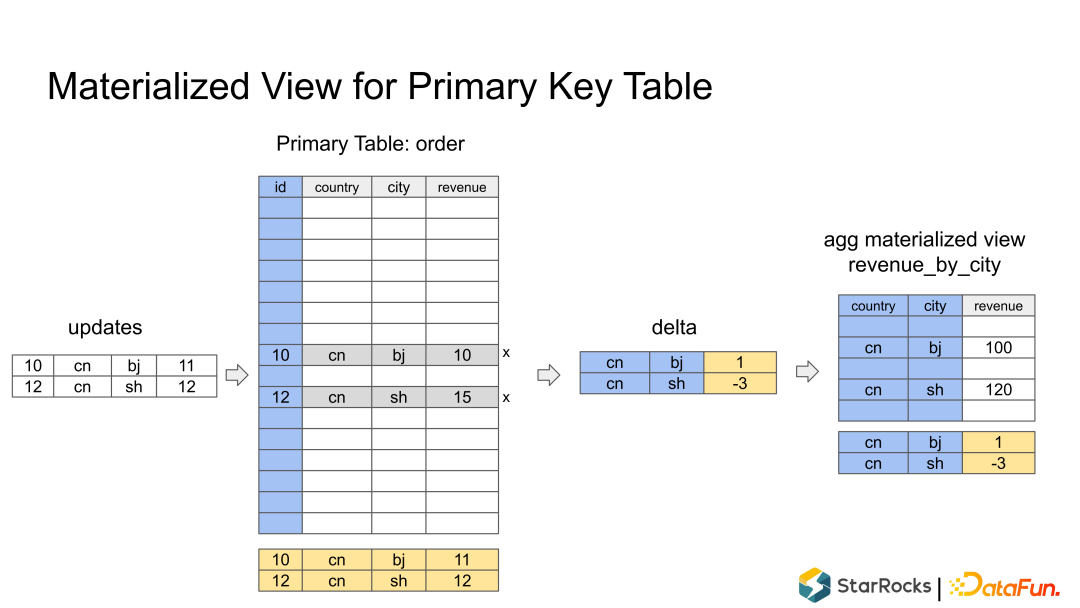
array append map/set add

今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

常冰琳
StarRocks 数据库研发工程师
StarRocks工程师,实时更新存储引擎负责人。13年大数据、云服务、计算机视觉领域经验,曾在百度、VMWare、小米负责Hadoop、查询引擎、OLAP云服务、相机AI特效等相关项目。Apache Kudu Commiter和PMC,多次在国内外技术大会分享Kudu、OLAP、云服务等实践经验。O'Reilly图书《Getting Started With Kudu》译者。
02/免费下载资料

03/预约看直播 免费抽奖

04/关于我们
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,14万+精准粉丝。
🧐 分享、点赞、在看,给个3连击呗!👇
文章转载自DataFunSummit,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
