北京银行“京Lake”数据湖平台历经4年的核心能力研发,凭借产品的技术创新顺利通过中国信通院云原生数据湖评测。“京Lake”在所有检测项中均表现出色,顺利获取“中国信通院云原生数据湖基础能力专项评测”证书。
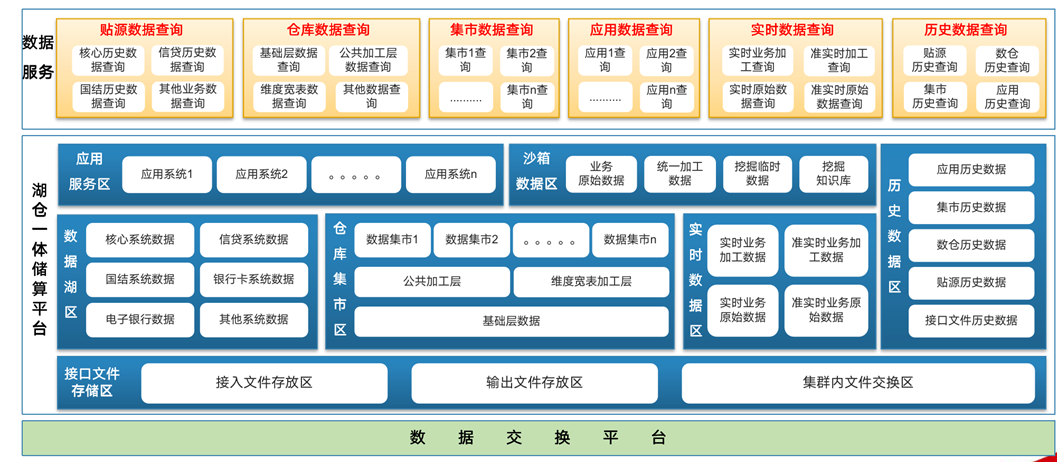
“京Lake”融合了东方国信Cirrodata-OLAP分布式数据库和开源增强大数据组件,基于大数据存储计算资源集中管理,实现数据统一交换、集中存储计算、统一数据安全、统一运营运维,目前已经完成了北京银行数据湖区、仓库集市区、实时数据区、应用服务区的成功落地。
“京Lake”北京银行数据湖平台是北京银行以“开源技术+自主研发”为基础构建的符合金融级要求的企业级数据湖产品。结合云原生与北京银行业务场景需求,实现CDC增量数据获取技术、数据湖存储技术、湖仓一体存储、湖仓批流计算和数据湖管理运维等数据湖方面的定制化研发。
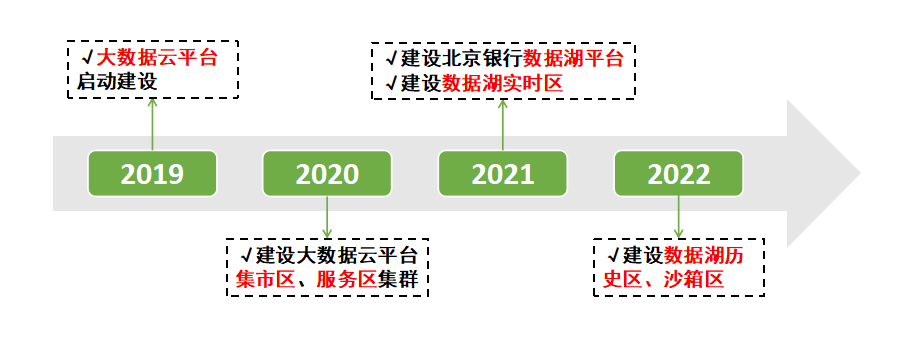
“京Lake”融合了行云Cirrodata-OLAP分布式数据库和开源增强大数据组件,北京银行数据湖平台研发历程可追溯至2019年,并相继于2020年和2021年分别搭建北京银行大数据云平台和北京银行数据湖集群。之后不断迭代,于2022年完成生态整合发布“京Lake” 北京银行数据湖平台V1.0版本。
京Lake使用的大数据组件为云原生产品,基于Hadoop生态组件进行封装和功能增强。在将原生态组件有机结合的基础上,研发一站式管理能力,更好地支持集群管理和运维;此外,增加多租户管理模块、提升HDFS块处理效率、优化HBase入库吞吐率、加强流式采集和计算能力,使组件满足金融级企业数据平台的应用需求。
京Lake使用的CirroData-OLAP分布式云化数据库是一款面向海量数据分析应用领域的国产数据库,融合了分布式存储和MPP并行计算的各自优势,同时支持大规模高通量数据加工、高并发低延迟查询分析和实时流式数据处理。数据库结合组合数据压缩算法及智能索引技术,帮助企业轻松实现云平台上的伸缩扩展、随需部署。
“京Lake” 目前已经部署超250个节点,日吞吐数据量达5TB,调度任务近万个,现有包括金审2.0、人行金融基础数据统计、支付结算合规监管系统、零售数据集市、对公数据集市、数字金融数据分析平台、全面风险预警平台、财务风险预警平台等几十个系统稳定运行。
“京Lake”可实现批流一体化的数据接入、存储、计算、管理和服务,满足多种金融企业级复合场景需求,包括但不限于:百亿数据上万并发精确查询毫秒级响应、百亿数据关联查询秒级响应、毫秒级高并发实时加工处理、秒级高并发海量数据准实时处理、分钟级PB级数据的上百高并发离线处理等。
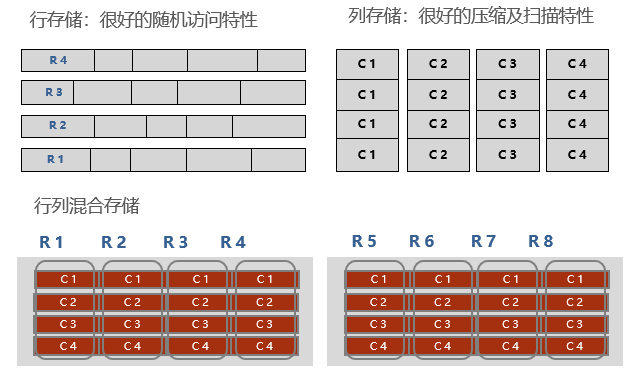
“京Lake”基于先进技术的融合创新实现金融企业级的数据统一采集、统一存储、统一加工、统一标准化、统一建模、统一管理、统一下发、统一服务。采用行列混合存储结构,基于完整子表构成的数据块进行读写,实现3-20倍高压缩比例。同时,每个区描述项中都存储了区数据的最大值和最小值,且每个列的数据是在段中连续存储的,相当于对每个列都有分段的范围索引,能大大提高数据检索的效率。采用C++开发,对计算机资源做了最高效的运用,相对基于Java的Hadoop方案能运用更少的硬件达成同样的性能要求,性价比高。
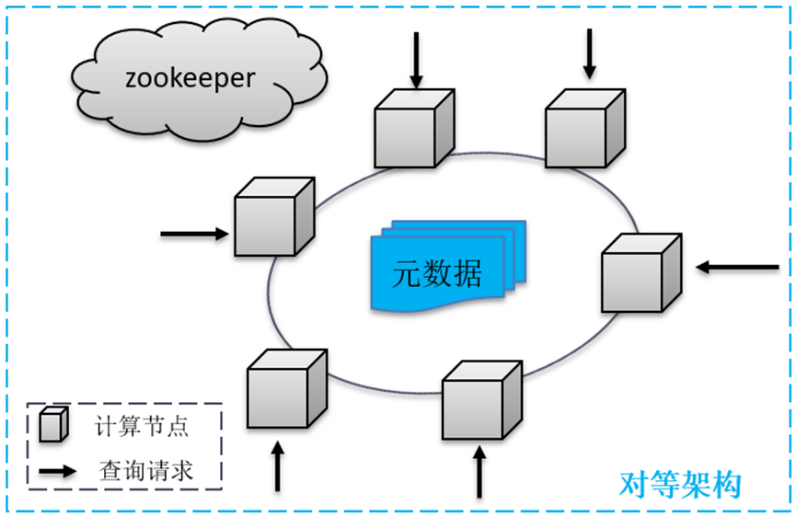
采用无专用入口节点的Master对等技术,集群中的任一节点,都可作为接受SQL请求的入口节点。不需要传统的Master节点H/A机制,不受Master节点软硬件性能的限制,可极为有效的提高整体集群的并发负载能力,均匀的分散集群计算压力。动态数据分片与本地计算资源动态分配结合,在查询计划与执行时进行计算资源的优化与配置,实现了SQL级别的弹性计算能力,低负载时利用空闲资源提高查询性能,高并发时酌量限制计算节点个数以提高并发数。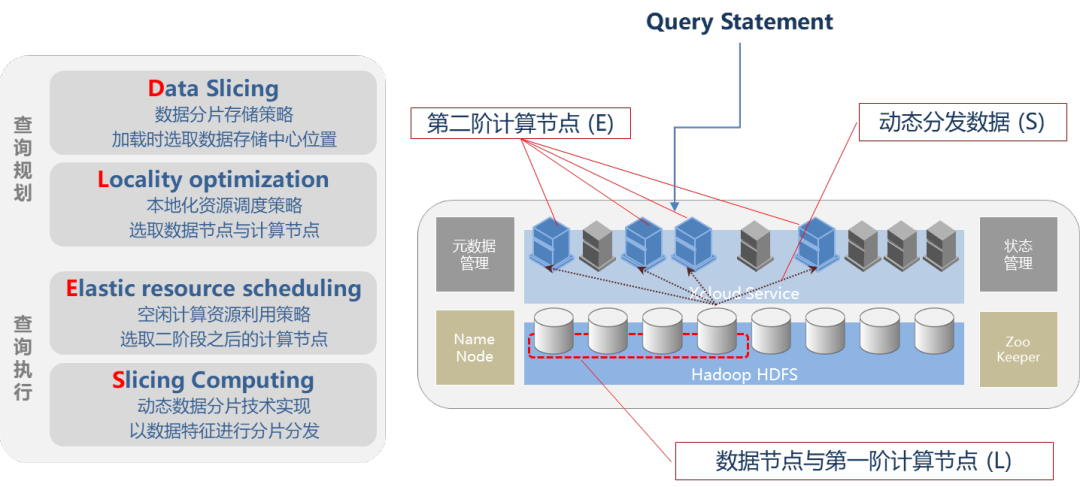
具备数据联邦能力,支持多种异构数据源:支持Oracle、MySQL、CirroData、Infomix、DB2、Hive、Gbase、TeraData等数据库,通过原生接口连接,性能更高。支持使用JDBC的通用连接访问异构数据源,便于快速扩展新业务。
京Lake具备高性能并发复杂查询、即席分析、高并发精准查询等多种业务应用场景的支持能力,通过京Lake服务区的建设,分别对灵活查询场景和复杂查询场景针对性设计了以HBase、Redis等大数据组件为支撑的数据查询加速存储区和以分布式数据库为基础的常规复杂查询存储区,有效满足了业务日常使用需求。
京Lake数据沙箱区提供了一套和实际生产运行系统完全独立的数据探查环境,提供脱敏的生产数据资源以及独立的存储计算资源,为数据分析及数据研发人员提供了一个安全、高效的数据探查使用环境。沙箱区在对数据进行安全处理的同时、保留了数据特性,又支持用户上传数据混合探索,大大提高了业务数据分析使用效率。构建统一存算资源管理平台:利用分布式数据库横向扩展及存算分离特性,对数据湖、数据集市等租户提供统一资源管理服务,屏蔽底层数据源技术差异,计算与存储资源分离,又可以各自独立扩展,避免资源浪费。
数据统一存储、共享互通:数据资源实现技术层面共享,统一文件系统,实现数据“一点存储,灵活应用”,打破数据系统“竖井”情况,支持沙箱、历史数据等应用场景,实现脱敏后数据、历史数据的全在线应用和共享,全面提升数据溯源、稽查等能力,将数据标准、数据质量检查规则落地在数据湖中,第一时间发现数据问题。提升数据指标交付水平:标准化数据交付流程,打通数据交付全生命周期,形成数据交付流水线。线上化数据交付工具,扩大管控半径,提升自主研发能力。自动化数据交付过程,减少人工处理环节,提高交付效能,提升交付质量。形成研发过程资产沉淀,共享数据标准、元数据、指标规则等成果。“京Lake”基于大数据存储计算资源集中管理,实现数据统一交换、集中存储计算、统一数据安全、统一运营运维,目前已经完成了北京银行数据湖区、仓库集市区、实时数据区、应用服务区的成功落地。
数据湖建设已成为当下金融行业数字化转型的重要举措,“京Lake”也将继续以“开源技术+自主研发”为基础不断优化产品核心能力,实现数据驱动业务发展。最后修改时间:2022-09-23 09:29:27
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。