客户的一个12.2的数据库日志切换很频繁,把REDO LOG文件大小从512MB加大到1GB后也还是一样。让我们帮忙看看是怎么回事。我们看了一下,每秒的REDO量并不大,大约0.5M左右,可是每小时的切换次数基本上在36次左右,十分有规律。而且每个归档文件的大小也差不太多,大概50多M到60多M。在确认了redo log文件的大小后,我们开始了对这个奇怪的问题的分析。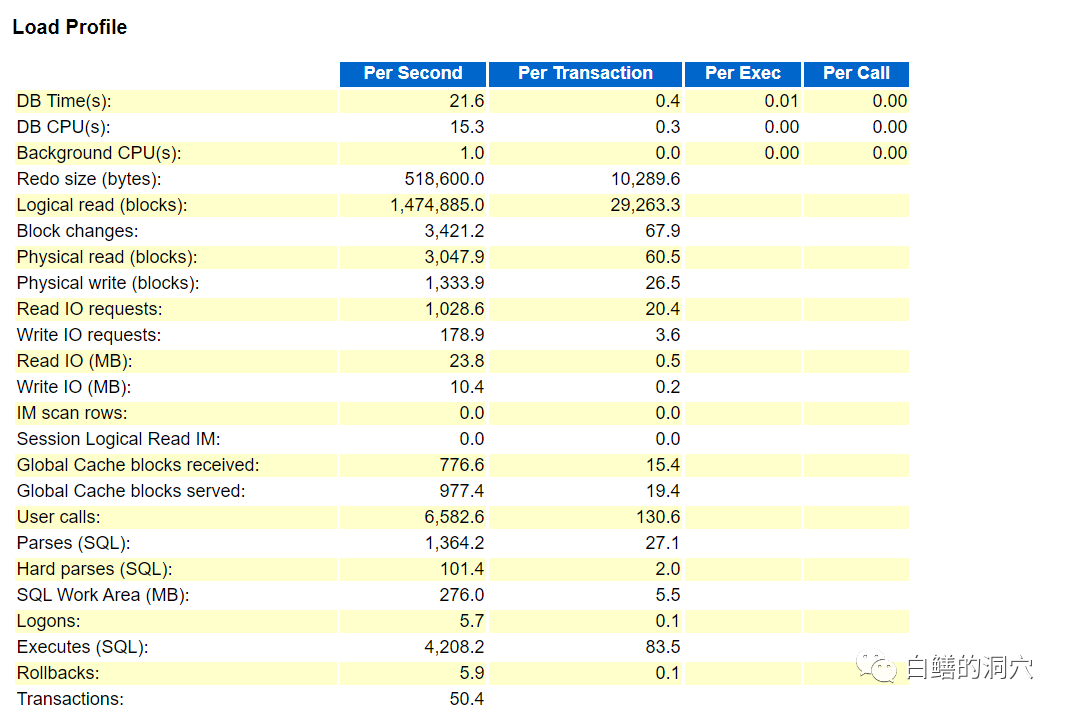
从awr上看到的redo size确实每秒大约0.5M左右,于是我们第一个想到的是检查一下archive_lag_target,这个参数会限制日志切换的时间,可以使redo Log没有写满的时候就发生切换。通过D-SMART的CIB数据我们看到这个参数是缺省值,为0。排除这个问题后,下一步要分析的是否存在数据库或者OS层面的定时任务,这一点也很快被否定了。这是从两个方面分析的,一个是通过日志切换时间的查看,发现虽然间隔时间差不多,但是这个时间是在不断漂移的,不是有规律的计划时间点。另外一个角度是从数据库和OS层面看配置,也没有发现类似的定时任务。再就是查看DG相关的配置和BUG,发现也很正常。于是问题的焦点就放在redo strand上了。这个功能在12c的数据库中是自动打开的。redo strand的目的是为了提高并发写入redo log buffer和redo log文件时候的性能,减少因为串行化闩锁等待导致的REDO性能问题。Oracle会根据CPU_COUNT的值,自动的调整redo strand的数量。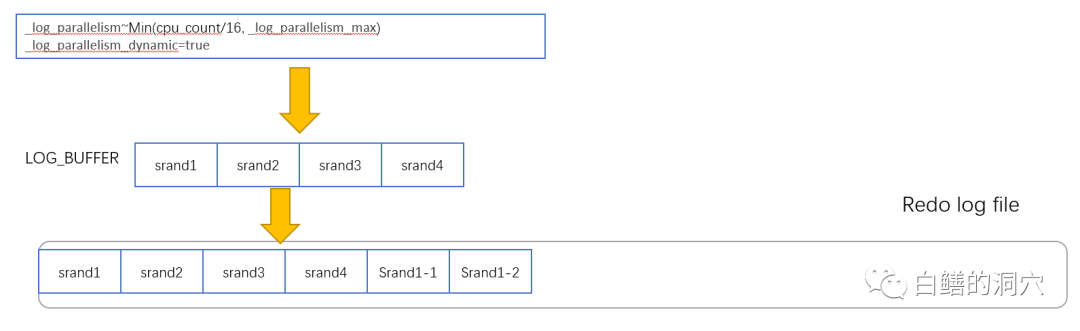
Oracle会根据CPU_COUNT/16来设定strand的数量,在LOG BUFFER中会按照strand数量划分为N个子池,写入REDO数据的时候,可以并发的写入不同的strand,这样可以减少高并发REDO BUFFER写入的性能。为了确保这一机制起作用,在REDO LOG文件中,也是按照strand的方式分配REDO LOG文件,实现某个strand的写入并不会影响其他strand并发写入redo log文件。当redo log切换的时候,在新文件里会为每个strand都分配好一个分区,用于刷入这个strand的数据。以后某个strand写满后,再申请一个新的分区写入。当某个strand写入时文件满了,那么就会产生日志文件切换,没有写入的strand数据会在新的redo log文件中申请空间,完成写入。这种机制可以大大提高REDO并发写入的性能,对于REDO量十分高的系统性能提升十分有帮助。不过针对这种情况,如果REDO LOG文件大小和LOG BUFFER设置不合理,就可能会导致一些问题。我们回过头去看这个案例。这个数据库的log_buffer设置为900M,这是我见过的设置的最大的LOG_BUFFER了,根据Oracle的内存HEAP的定义,实际上这个LOG_BUFFER的大小为1GB,因为这个系统有256个CPU线程,因此strand数量为16,那么一个strand分区的大小也就是64M不到一点(有12M的附加,不同的版本不同,大概50多M),而REDO LOG文件的大小恰巧和LOG BUFFER一样,都是1G,因此每次日志切换,整个文件就马上被完全划分了。如果这时候系统负载不高,只有1个活跃会话在产生REDO,那么只有第一个strand会被使用,其他的strand都是空的。而这个strand分配的REDO LOG空间写完后,就会申请新的SRAN的继续写,如果写不下,就会立马进行日志切换,而不会管其他strand是否是空的。这样情况,一个REDO LOG文件就有15/16的空间被浪费了。这个现象和我们发现的情况完全一致。要解决这个问题,只需要把Log_buffer调整到合理的大小就可以了,比如200M。通过这个案例,我们也可以学到,如果要用好strand的特性,log buffer/cpu_count或者最大并发参数与redo log文件的大小需要做合理的适配,才能获得较好的性能。否则可能反而会引起系统的性能问题。 最后修改时间:2025-03-26 18:32:25
文章转载自
白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





