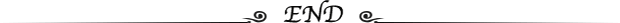服务(Service
)
解决的问题
Pod
是非永久性资源。 如果你使用 Deployment
来运行你的应用程序,则它可以动态创建和销毁 Pod。
每个 Pod
都有自己的 IP
地址,但是在 Deployment
中,在同一时刻运行的 Pod
集合可能与稍后运行该应用程序的 Pod
集合不同。
这导致了一个问题: 如果一组 Pod
(称为“后端”)为集群内的其他 Pod
(称为“前端”)提供功能, 那么前端如何找出并跟踪要连接的 IP
地址,以便前端可以使用提供工作负载的后端部分?
定义
Kubernetes Service
定义了这样一种抽象:一个 Pod
的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod
能够被 Service
访问到,通常是通过 Label Selector
.
Service
能够提供负载均衡的能力,但是在使用上有以下限制:
只提供 4
层负载均衡能力,而没有 7
层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上 4
层负载均衡是不支持的
假设,你有一组 pod
,那如何使用一个 Service
为这组 pod
提供负载均衡的能力呢? 刚才说了, 通过 Label Selector
选择出符合条件的 Pod
. 当请求访问到 Service
, 则会请求转到对应的一个 pod
上。 还有一种方式就是 非 Label Selector
方式.
Selector关联
举一个例子:
假定有一组 Pod
,它们对外暴露了 80
端口,同时还被打上 app.kubernetes.io/name=proxy
标签
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app.kubernetes.io/name: proxy
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
name: http-web-svc
然后创建了一个 Service
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app.kubernetes.io/name: proxy
ports:
- name: name-of-service-port
protocol: TCP
port: 80
targetPort: http-web-svc
Kubernetes
为该服务分配一个 IP
地址(有时称为 “集群 IP”),该 IP
地址由服务代理使用. 服务选择算符的控制器不断扫描与其选择算符匹配的 Pod
(即 app.kubernetes.io/name=proxy
的 Pod
) ,然后将所有更新发布到也称为 “my-service”
的 Endpoint
对象。
即使 Service
中使用同一配置名称混合使用多个 Pod
,各 Pod
通过不同的端口号支持相同的网络协议, 此功能也可以使用。这为 Service
的部署和演化提供了很大的灵活性。 例如,你可以在新版本中更改 Pod
中后端软件公开的端口号,而不会破坏客户端。
非Selector关联
举个例子:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
创建 一个 Service
. 由于此服务没有选择算符,因此不会自动创建相应的 Endpoints
对象。 你可以通过手动添加 Endpoints
对象,将服务手动映射到运行该服务的网络地址和端口:
apiVersion: v1
kind: Endpoints
metadata:
# 这里的 name 要与 Service 的名字相同
name: my-service
subsets:
- addresses:
- ip: 192.0.2.42
ports:
- port: 9376
Service 可以管理多少个 Endpoint
截止目前 kubernetes v1.22
. 一个 Service
最多管理 1000
个 Pod
. 如果某个 Endpoints
资源中包含的端点个数超过 1000
,则 Kubernetes v1.22
版本 (及更新版本)的集群会将为该 Endpoints
添加注解 endpoints.kubernetes.io/over-capacity: truncated
。 这一注解表明所影响到的 Endpoints
对象已经超出容量,此外 Endpoints
控制器还会将 Endpoints
对象数量截断到 1000。
如何解决
可以使用 EndpointSlices
来解决.
EndpointSlices
是一种 API
资源,可以为 Endpoints
提供更可扩展的替代方案。 尽管从概念上讲与 Endpoints
非常相似,但 EndpointSlices
允许跨多个资源分布网络端点。 默认情况下,一旦到达 100
个 Endpoint
,该 EndpointSlice
将被视为“已满”, 届时将创建其他 EndpointSlices
来存储任何其他 Endpoints
。
Service
的类型
Service
在 K8s
中有以下五种类型
ClusterIp
:默认类型,自动分配一个仅Cluster
内部可以访问的虚拟IP
,这种类型使得 Service 只能从集群内访问。NodePort
:在ClusterIP
基础上为Service
在每台机器上绑定一个端口,这样就可以通过 :NodePort
来访问该服务LoadBalancer
:在NodePort
的基础上,借助cloud provider
创建一个外部负载均衡器,并将请求转发到:NodePortExternalName
:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有kubernetes 1.7
或更高版本的kube-dns
才支持Ingress
:Ingress
是对集群中服务的外部访问进行管理的API
对象,典型的访问方式是HTTP
。Ingress
可以提供负载均衡、SSL
终结和基于名称的虚拟托管。Ingress
公开从集群外部到集群内服务的HTTP
和HTTPS
路由。 流量路由由Ingress
资源上定义的规则控制。
代理
VIP
和 Service
代理
在 Kubernetes
集群中,每个 Node
运行一个 kube-proxy
进程。 kube-proxy
负责为 Service
实现了一种 VIP(虚拟IP)
的形式,而不是 ExternalName
的形式。 在 Kubernetes v1.0
版本,代理完全在 userspace
。在 Kubernetes v1.1
版本,新增了 iptables
代理,但并不是默认的运行模式。 从 Kubernetes v1.2
起,默认就是iptables
代理。 在 Kubernetes v1.8.0-beta.0
中,添加了 ipvs 代理在 Kubernetes 1.14
版本开始默认使用 ipvs
代理. 在 Kubernetes v1.0
版本, Service
是 “4层”
(TCP/UDP over IP
)概念。 在 Kubernetes v1.1
版本,新增了 Ingress API(beta 版)
,用来表示 “7层”(HTTP)
服务
代理模式的分类
userspace
kube-proxy
会监视 Kubernetes kubelet
对 Service
对象和 Endpoints
对象的添加和移除操作。 对每个 Service
,它会在本地 Node
上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service
的某个 pod
上. 使用哪个后端 Pod
,是 kube-proxy
基于 SessionAffinity
来确定的。
最后,它配置 iptables
规则,捕获到达该 Service
的 clusterIP
(是虚拟IP) 和 Port
的请求,并重定向到代理端口,代理端口再代理请求到后端Pod
。
默认情况下,用户空间模式下的 kube-proxy
通过轮转算法选择后端。
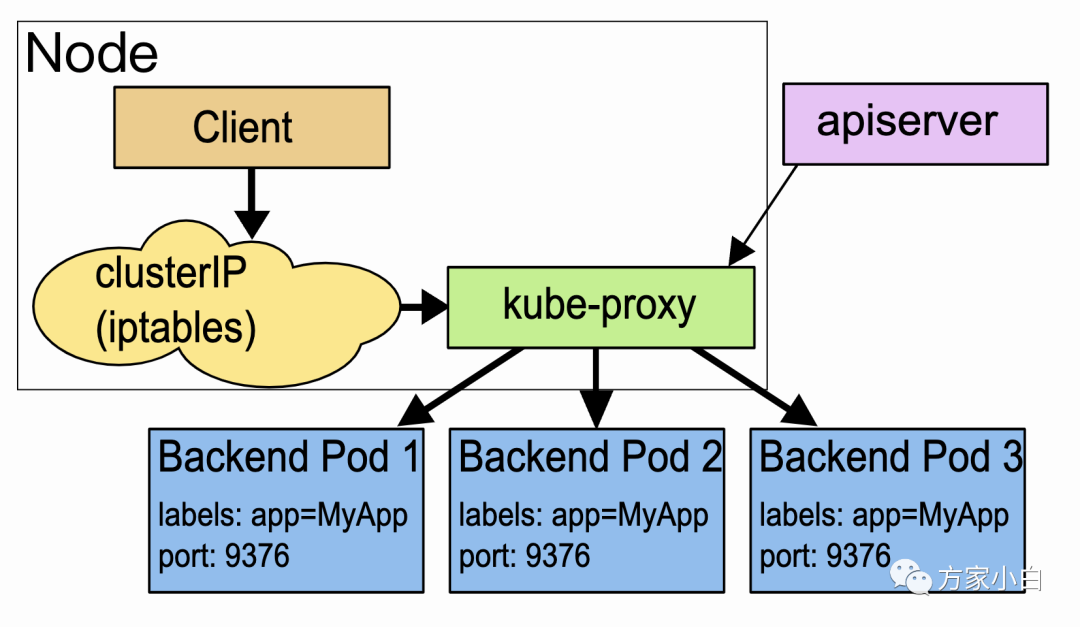
iptables
这种模式,kube-proxy
会监视 Kubernetes
控制节点对 Service
对象和 Endpoints
对象的添加和移除。 对每个 Service
,它会配置 iptables
规则,从而捕获到达该 Service
的 clusterIP
和端口的请求,进而将请求重定向到 Service
的一组后端中的某个 Pod
上面。 对于每个 Endpoints
对象,它也会配置 iptables
规则,这个规则会选择一个后端组合。
默认的策略是,kube-proxy
在 iptables
模式下随机选择一个后端。
使用 iptables
处理流量具有较低的系统开销,因为流量由 Linux netfilter
处理, 而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy
在 iptables
模式下运行,并且所选的第一个 Pod
没有响应,则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy
将检测到与第一个 Pod
的连接已失败, 并会自动使用其他后端 Pod
重试。
你可以使用 Pod
就绪探测器 验证后端 Pod
可以正常工作,以便 iptables
模式下的 kube-proxy
仅看到测试正常的后端。 这样做意味着你避免将流量通过 kube-proxy
发送到已知已失败的 Pod
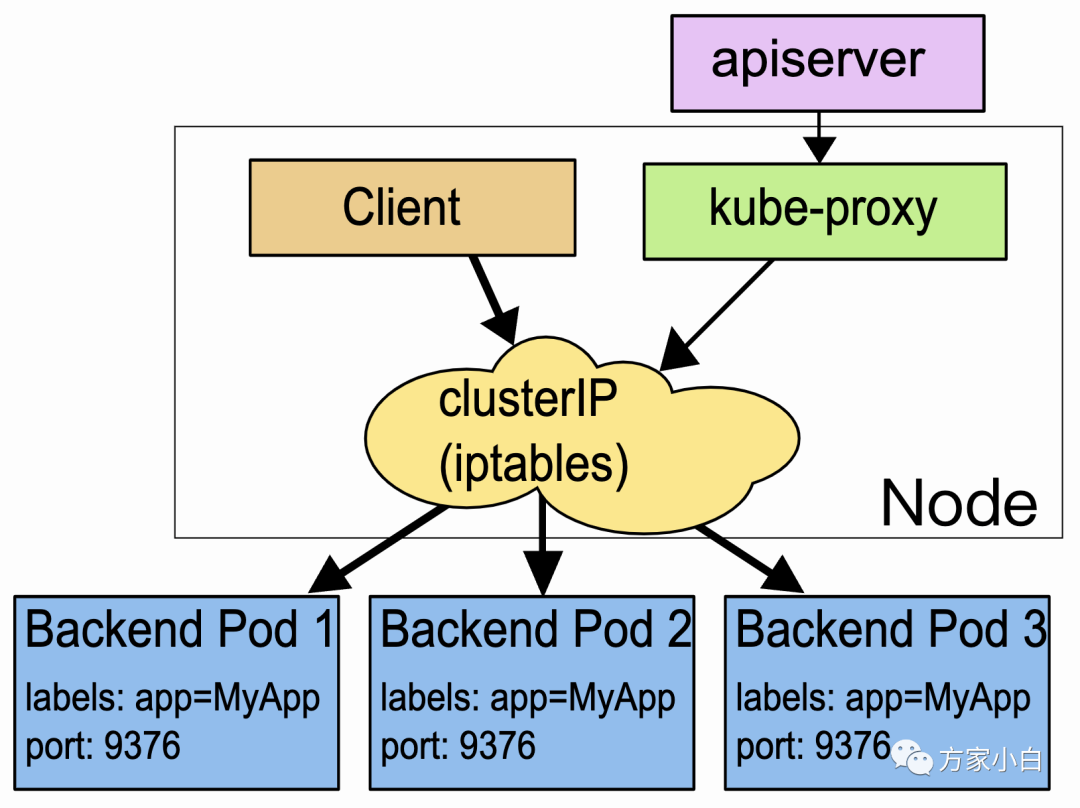
ipvs
这种模式,kube-proxy
会监视 Kubernetes Service
对象和 Endpoints
,调用 netlink
接口以相应地创建ipvs
规则并定期与 Kubernetes Service
对象和 Endpoints
对象同步 ipvs
规则,以确保 ipvs
状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod
. 与 iptables
类似,ipvs
于 netfilter
的 hook
功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs
可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs
为负载均衡算法提供了更多选项,例如:
rr
:轮询调度lc
:最小连接数dh
:目标哈希sh
:源哈希sed
:最短期望延迟nq
: 不排队调度
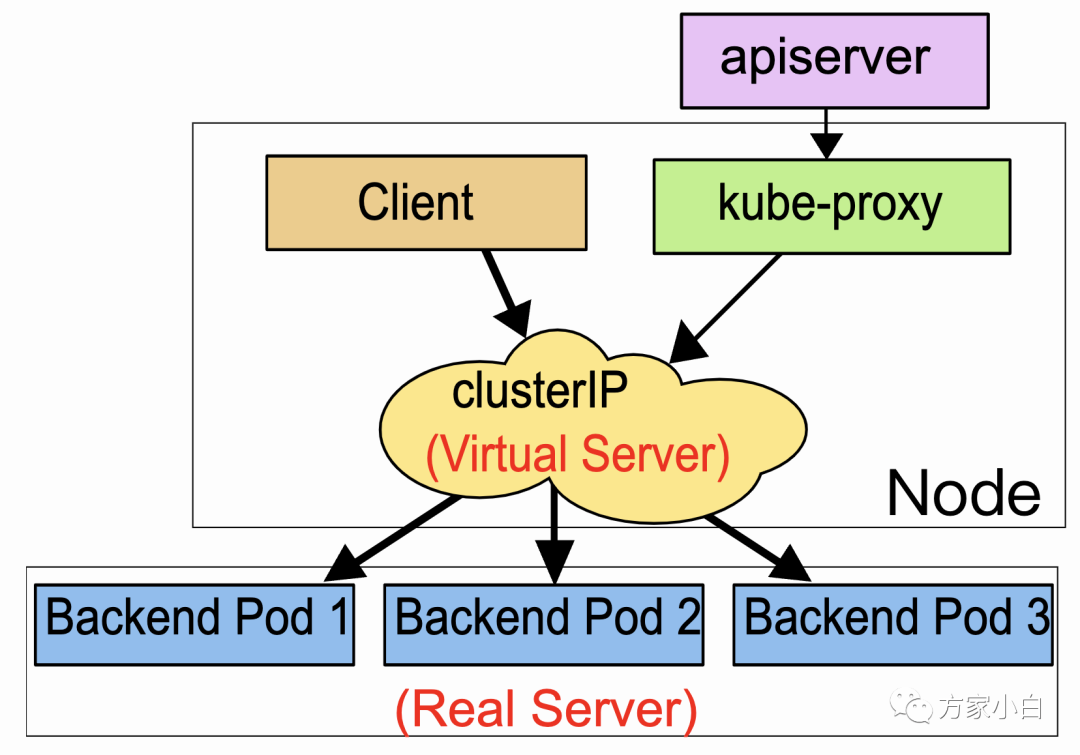
Service 类型实验
ClusterIP
clusterIP
主要在每个 node
节点使用 iptables
等代理方式, 将发向 clusterIP
对应端口的数据,转发到 kube-proxy
中。然后 kube-proxy
自己内部实现有负载均衡的方法,并可以查询到这个 service
下对应 pod
的地址和端口,进而把数据转发给对应的 pod
的地址和端口。 这种类型使得 Service 只能从集群内访问。
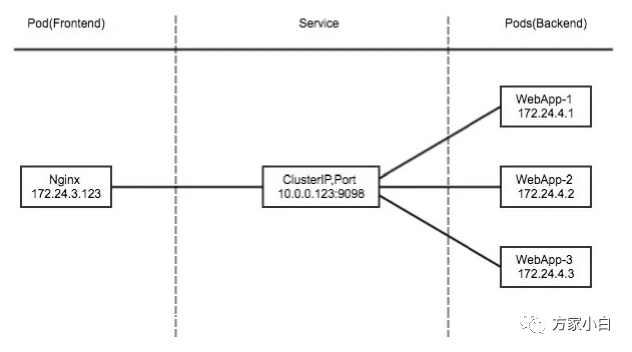
为了实现图上的功能,主要需要以下几个组件的协同工作:
apiserver
用户通过kubectl
命令向apiserver
发送创建service
的命令,apiserver
接收到请求后将数据存储到etcd
中kube-proxy kubernetes
的每个节点中都有一个叫做kube-porxy
的进程,这个进程负责感知service
,pod
的变化,并将变化的信息写入本地的iptables
规则中.iptables
使用NAT
等技术将virtualIP
的流量转至endpoint
中
创建一个deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: cluster-ip-demo
spec:
replicas: 3
selector:
matchLabels:
app: cluster-ip-demo
tag: cluster-ip-v1
template:
metadata:
labels:
app: cluster-ip-demo
tag: cluster-ip-v1
env: test
spec:
containers:
- name: cluster-ip-demo-container
image: fangjiaxiaobai/my-app:v3
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
env:
- name: "MY_APP_VERSION"
value: "3.0"

把 Deploymenet
绑定到 Service
上
apiVersion: v1
kind: Service
metadata:
name: service-cluster-ip-demo
spec:
type: ClusterIP
selector:
app: cluster-ip-demo
tag: cluster-ip-v1
ports:
- name: http
port: 80
targetPort: 80
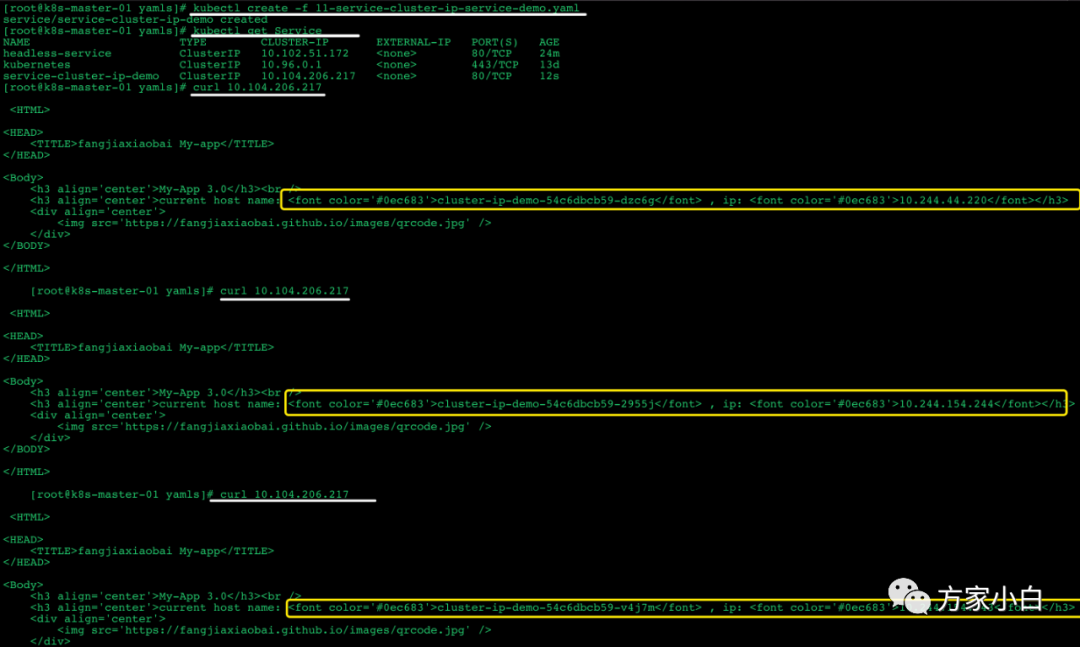
Headless Service
有时不需要或不想要负载均衡sc以及单独的 Service IP
。遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)
的值为 “None”
来创建 Headless Service
。这类 Service
并不会分配 Cluster IP
, kube-proxy
不会处理它们,而且平台也不会为它们进行负载均衡和路由
apiVersion: v1
kind: Service
metadata:
name: headless-service
namespace: default
spec:
selector:
app: headless-app
clusterIp: "None"
ports:
- port: 80
targetPort: 80
使用dig
命令可以验证一下
dig -t A headless-service.default.svc.cluster.local. @10.96.0.10
NodePort
nodePort
的原理在于在 node
上开了一个端口,将向该端口的流量导入到 kube-proxy
,然后由 kube-proxy
进一步到给对应的 pod
创建 Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: node-port-container-demo
spec:
replicas: 3
selector:
matchLabels:
app: node-port-service
tag: node-port-tag-v3
template:
metadata:
labels:
app: node-port-service
tag: node-port-tag-v3
env: test
spec:
containers:
- name: cluster-ip-demo-container
image: fangjiaxiaobai/my-app:v3
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
env:
- name: "MY_APP_VERSION"
value: "3.0"
绑定到 Service
上。
apiVersion: v1
kind: Service
metadata:
name: node-port-service
namespace: default
spec:
type: NodePort
selector:
app: node-port-service
tag: node-port-tag-v3
env: test
ports:
- name: http
port: 80
targetPort: 80

可以在浏览器上访问 Node
的 IP
(http://192.168.0.10:31024/
), 多次访问查看 hostname
和 ip
的变化.
LoadBalancer
loadBalancer
和 nodePort
其实是同一种方式。区别在于 loadBalancer
比 nodePort
多了一步,就是可以调用 cloud provider
去创建 LB
来向节点导流.
ExternalName
这种类型的 Service
通过返回 CNAME
和它的值,可以将服务映射到 externalName
字段的内容( 例如:hub.atguigu.com
)。 ExternalName Service
是 Service
的特例,它没有 selector
,也没有定义任何的端口和 Endpoint
。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务
apiVersion: v1
kind: Service
metadata:
name: external-name-service
namespace: default
spec:
type: ExternalName
externalName: www.fangjiaxiaobai.cn

当查询主机 my-service.defalut.svc.cluster.local
( SVC_NAME.NAMESPACE.svc.cluster.local
)时,集群的 DNS
服务将返回一个值 my.database.example.com
的 CNAME
记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS
层,而且不会进行代理或转发
下一篇,我们介绍另外一种 资源控制器 Ingress
.
最后
希望和你一起遇见更好的自己