




在spark物理执行计划生成框架中提到通过QueryExecution.createSparkPlan()
生成的物理执行计划还不能直接交给spark运行,因为缺少必要的operator,如shuffle操作和内部数据格式转换等。本文来探索如何生成可执行物理执行计划executedPlan
,及生成shuffle操作的EnsureRequirements
规则。
1. 生成可执行计划框架
1.1 生成executedPlan入口
可执行物理执行计划的生成是QueryExecution
类中的lazy val executedPlan: SparkPlan
的属性属性,是懒加载。触发时机是:
1. command类操作,如
createView
,insertInto
等,是在初始化DataSet的时触发生成可执行物理计划
// DataSet#logicalPlan
@transient private[sql] val logicalPlan: LogicalPlan = {
val plan = queryExecution.commandExecuted // 触发生成可执行物理执行计划
if (sparkSession.sessionState.conf.getConf(SQLConf.FAIL_AMBIGUOUS_SELF_JOIN_ENABLED)) {
val dsIds = plan.getTagValue(Dataset.DATASET_ID_TAG).getOrElse(new HashSet[Long])
dsIds.add(id)
plan.setTagValue(Dataset.DATASET_ID_TAG, dsIds)
}
plan
}
2. action算子,如
tail
,head
,collect
等,是在执行action时触发生成可执行物理计划
// DataSet#show-->DataSet#head-->DataSet#withAction
private def withAction[U](name: String, qe: QueryExecution)(action: SparkPlan => U) = {
SQLExecution.withNewExecutionId(qe, Some(name)) {
// withInternalError触发生成可执行物理执行计划,是调用QueryExecution#explainString方法是触发
QueryExecution.withInternalError(s"""The "$name" action failed.""") {
qe.executedPlan.resetMetrics()
action(qe.executedPlan)
}
}
}
1.2 生成executedPlan流程
executedPlan生成的完整定义是:
lazy val executedPlan: SparkPlan = {
assertOptimized()
executePhase(QueryPlanningTracker.PLANNING) {
// 实际的生成逻辑
QueryExecution.prepareForExecution(preparations, sparkPlan.clone())
}
}
从中可以看出,实际生成逻辑是定义在QueryExecution.prepareForExecution()
方法中,入参有两个:preparations
是SparkPlan转换规则集合,类型是 Seq[Rule[SparkPlan]]
;plan
是有createSparkPlan生成的缺少必要operator的物理执行计划集合的最佳物理执行计划的复制体。
private[execution] def prepareForExecution(
preparations: Seq[Rule[SparkPlan]],
plan: SparkPlan): SparkPlan = {
val planChangeLogger = new PlanChangeLogger[SparkPlan]()
// 核心逻辑 flodLeft
val preparedPlan = preparations.foldLeft(plan) { case (sp, rule) =>
val result = rule.apply(sp)
planChangeLogger.logRule(rule.ruleName, sp, result)
result
}
planChangeLogger.logBatch("Preparations", plan, preparedPlan)
preparedPlan
}
为什么要复制一份SparkPlan呢?(尝试思考下)
相比LogicalPlan的解析(Analyzer)和优化(Optimizer)的执行流程,物理执行计划到可执行物理执行计划的执行流程比较简单,就是利用scala集合的foldLeft
方法对物理执行计划逐个执行规则算法最终得到可执行物理计划。
foldLeft
函数的定义是foldLeft[B](z: B)(op: (B, A) => B): B
,是scala的函数柯里化应用。第一个参数z
表示初始对象,是B类型;第二个参数op: (B, A)
是一个tuple,op._1是B类型,表示上一个函数返回的结果对象,如果是集合第一次调用则表示的是初始对象,op._2是A类型(集合的元素类型),表示的是集合的当前遍历到的元素。语言描述比较抽象,以上述生成可执行计划为例用图表示:
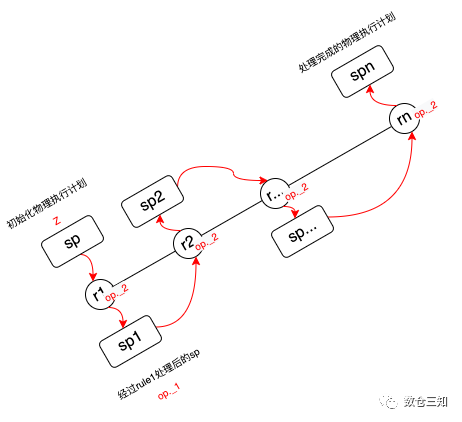
总体来说执行流程较为简单,接下来我们来看下具体的转化规则。
1.3 生成executedPlan规则
物理执行计划生成可执行计划的规则定义在:
// object QueryExecution中
private[execution] def preparations(
sparkSession: SparkSession,
adaptiveExecutionRule: Option[InsertAdaptiveSparkPlan] = None,
subquery: Boolean): Seq[Rule[SparkPlan]]
adaptiveExecutionRule
是AQE功能的规则,因为AQE比较复杂,是一种加强功能,因此这里对该规则暂不做过多介绍,在调试的时候回将该规则注释掉。除AQE规则以外,生成规则列表如下(按照执行顺序排列):
| 序号 | 名称 | 描述 |
| 1 | CoalesceBucketsInJoin | 合并SortMergeJoin和ShuffledHashJoin。 |
| 2 | PlanDynamicPruningFilters | 重写动态修剪谓词,以便重用广播的结果。对于未计划为广播散列连接的连接,我们将备用机制与子查询重复。 |
| 3 | PlanSubqueries | 处理子查询。 |
| 4 | RemoveRedundantProjects | 删除多余的 ProjectExec 节点。 |
| 5 | EnsureRequirements | 通过在需要的地方插入ShuffleExchangeExec运算符,确保输入数据的Partitioning满足每个运算符的Distribution要求。 |
| 6 | ReplaceHashWithSortAgg | 根据一定的条件基于哈希的聚合替换为排序聚合。 |
| 7 | RemoveRedundantSorts | 删除多余的 SortExec 节点 |
| 8 | DisableUnnecessaryBucketedScan | 禁用不必要的分桶表扫描。 |
| 9 | ApplyColumnarRulesAndInsertTransitions | 应用任何用户定义的ColumnarRule并找到正确的位置来插入转换到/从列格式数据。 |
| 10 | CollapseCodegenStages | 全代码生成规则。 |
| 11 | ReuseExchangeAndSubquery | 在包括子查询在内的整个 Spark 计划中找出重复的交换和子查询,然后对所有引用使用相同的交换或子查询。 |
规则还是比较多,计划会分享EnsureRequirements
和CollapseCodegenStages
两个规则,先分享下EnsureRequirements
规则的分析。
2. EnsureRequirements规则
2.1 前置知识
在物理执行计划生成框架那篇文章中提到,SparkPlan类中定义了数据如何进行分区与排序:
// 表示当前物理节点对输出数据(数据输出)怎么进行分区。
def outputPartitioning: Partitioning
// 表示当前节点对子节点(数据输入)的数据分布情况的要求
def requiredChildDistribution: Seq[Distribution]
上述方法引入了对分区和分布的抽象,分别是Partitioning
和Distribution
。这两个是判断数据是否要增加shuffle节点的依据。接下我们依次对这两个抽象进行梳理。
2.1.1. Partitioning
Partitioning
描述如何跨分区拆分运算符的输出。有两个主要属性:分区数和是否满足给定的数据分布。Partitioning的属性与方法:
a. val numPartitions: Int
:数据被拆分的分区数。
b. satisfies && satisfies0
:当前的分区情况是否满足所需Distribution规定的分区方案,如果不满足返回true,需要增加重分区的操作。满足返回false,不进行处理。
c. createShuffleSpec
是在spark3.3引入的,具体可以追踪下SPARK-35703,是spark3.2的HashClusteredDistribution的替代。
Partitioning的实现体系是:

UnknownPartitioning
:是默认SparkPlan的默认实现,可以表示对分区没有要求。
SinglePartition
:是指输出只有1个分区
BroadcastPartitioning
:广播分区,分区数为1。
HashPartitioning
:hash分区。
RangePartitioning
:基于范围的分区。
RoundRobinPartitioning
:基于轮询分区,分区数是n,数据是i,则分区号是i mod n。
KeyGroupedPartitioning
:基于表达式的分区,在spark3.3引入可参考SPARK-37377,用于DataSourceV2中。
PartitioningCollection
:分区表达式集合。
2.1.2. Distribution
Distribution
描述了如何在集群中的物理机器节点上对元组(数据)进行分区。用在SparkPlan中表示当前算子(操作)对数据输入(子节点)的分布情况。有两个方法:
a. def requiredNumPartitions: Option[Int]
:此分布所需的分区数。如果为 None,则此分布允许任意数量的分区
b. def createPartitioning(numPartitions: Int): Partitioning
:为这个分布创建一个默认分区,它可以在匹配给定数量的分区的同时满足这个分布。
Distribution
的实现体系:

AllTuples
:表示只有一个分区并且数据集位于同一位置的分布。所需分区数为1,可以构建出SinglePartition
分区器。例如:GlobalLimitExec算子等。
BroadcastDistribution
:广播分布,表示将元组广播到每个节点的数据。将整组元组转换为不同的数据结构是很常见的。例如:BroadcastHashJoinExec、BroadcastNestedLoopJoinExec算子等。
ClusteredDistribution
:hash分布,数据经过 clustering: Seq[Expression]
进行hash计算进行分布。例如:ShuffledHashJoinExec、SortMergeJoinExec算子等 。
OrderedDistribution
:表示已根据排序Expressions对元组进行排序的数据分布。例如SortExec算子。
StatefulOpClusteredDistribution
:Structured Streaming分数据分布。
UnspecifiedDistribution
:表示一个分布,其中没有对数据的协同定位做出任何承诺。
2.1.3. Partitioning和Distribution关系
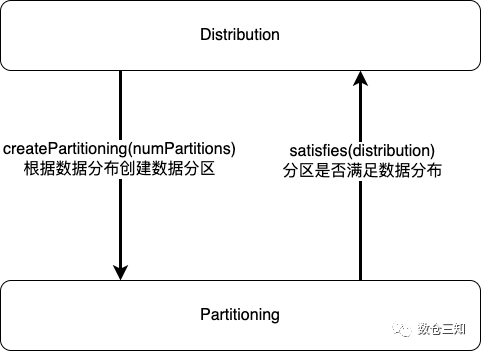
2.1.4 Exchange
在多个线程或进程之间交换数据的运算符的基类。交换是启用并行性的关键运算符类别。尽管实现方式有很大不同,但其概念类似于 Goetz Graefe 在“Volcano -- An Extensible and Parallel Query Evaluation System”中描述的交换运算符。
通俗来说就是当上下游数据数据分布不满足或者数据分布不兼容时候引入该操作。
Exchange的实现体系:
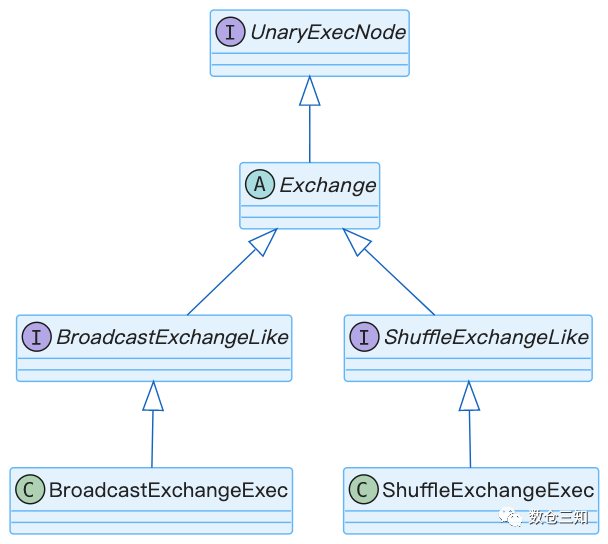
2.2 算法梳理
熟悉了上述前置知识,我们来看EnsureRequirements规则的算法。EnsureRequirements的作用是当数据上下游分布不满足或者不兼容的时候引入Exchange节点,以及确保排序的正确性。
EnsureRequirements的构造参数有两个:
a. optimizeOutRepartition: Boolean = true
指示此规则是否应优化用户指定的重新分区随机播放的标志。这在大多数情况下是正确的,但在 AQE 优化可能会更改计划输出分区并需要在计划中保留用户指定的重新分区 shuffle 时可能是错误的。
b. requiredDistribution: Option[Distribution] = None
确保根要求分布。该值用于 AQE,以防我们更改最终阶段的输出分区。
这两个参数都有默认值,在执行的时候使用的都是默认值(除AQE规则外)。
EnsureRequirements规则的执行流程是:
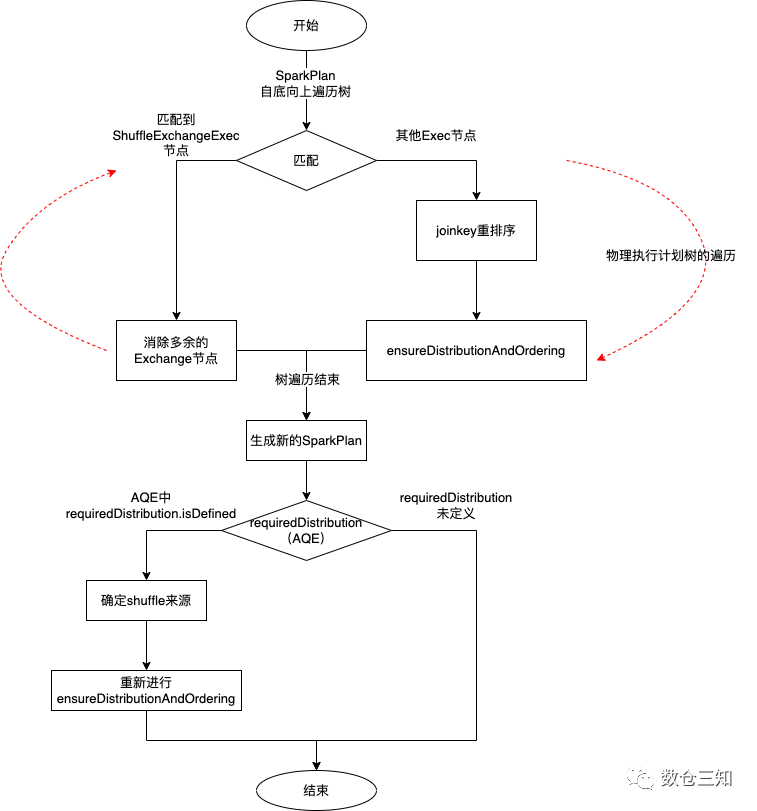
其中比较重要的方式是ensureDistributionAndOrdering
,在spark3.3分支中方法体很长,其中增加Exchange节点的逻辑是:
var children = originalChildren.zip(requiredChildDistributions).map {
case (child, distribution) if child.outputPartitioning.satisfies(distribution) =>
child
case (child, BroadcastDistribution(mode)) =>
BroadcastExchangeExec(mode, child)
case (child, distribution) =>
val numPartitions = distribution.requiredNumPartitions
.getOrElse(conf.numShufflePartitions)
ShuffleExchangeExec(distribution.createPartitioning(numPartitions), child, shuffleOrigin)
}
核心是判断数据输入的分区是否满足当前节点对该子节点的分布需求。通过child.outputPartitioning.satisfies(distribution)
进行判断,分三种情况:
a. 满足分布要求,不添加Exchange,原样返回;
b. 不满足分布要求,并且是Broadcast的分布,增加BroadcastExchangeExec节点;
c. 不满足分布要求,且不是Broadcast的分布,增加ShuffleExchangeExec节点。
剩余方法体的主要功能是处理确保同一键数据分布到同一分区内,类似于spark3.2的HashClusteredDistribution分布,有兴趣的可以查看下SPARK-35703。
2.3 具体实例
以一个具体的SQL进行分析:
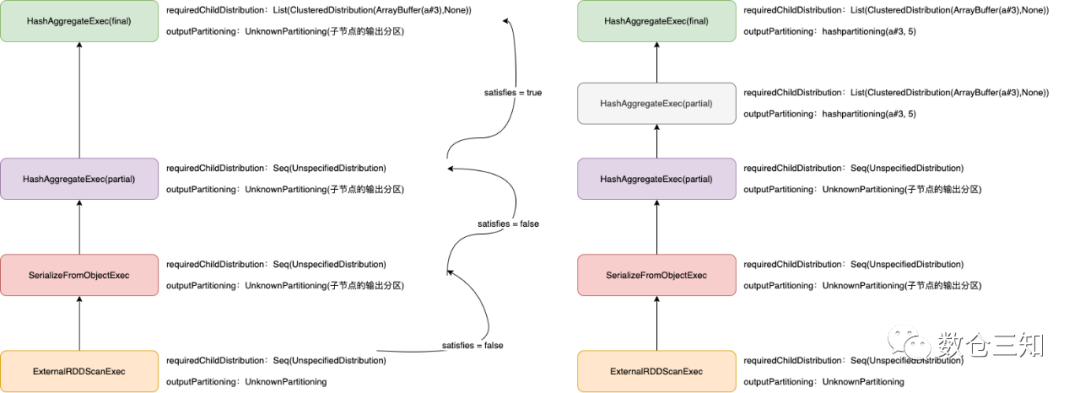
select a, count (b) from testdata2 group by a
其生成的物理执行计划是:
HashAggregate(keys=[a#3], functions=[count(1)], output=[a#42, count(b)#43])
+- HashAggregate(keys=[a#3], functions=[partial_count(1)], output=[a#3, count#47L])
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#3]
+- Scan[obj#2]
可执行物理执行计划是:
*(2) HashAggregate(keys=[a#3], functions=[count(1)], output=[a#3, count(b)#35L])
+- Exchange hashpartitioning(a#3, 5), ENSURE_REQUIREMENTS, [plan_id=29]
+- *(1) HashAggregate(keys=[a#3], functions=[partial_count(1)], output=[a#3, count#39L])
+- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#3]
+- Scan[obj#2]
图解执行过程:
3 小结
本文分析了物理执行计划生成可执行计划的流程及增加Exchange节点的EnsureRequirements规则的算法。
下一篇将介绍全代码生成规则及其前置内容。
