




sparkSQL物理执行计划节点生成策略
0. 引言
前篇文章概述了spark-sql中由逻辑执行计划(LogicalPlan)生成物理执行计划(SparkPlan)的执行框架,本质上是LogicalPlan节点自上而下一一生成SparkPlan节点,再自下而上将SparkPlan节点组装成一棵树。但并没有详述LogicalPlan节点生成SparkPlan节点的具体方法,本文主要探索其具体的生成方法。
1. SparkPlan生成方法
在探究SparkPlan节点生成方法之前,请先思考下该如何实现。输入是什么?输出是什么?
1.1 方法入口
生成SparkPlan节点的方法入口是:
// QueryPlanner.scala文件
// QueryPlanner.apply()方法部分代码
val candidates = strategies.iterator.flatMap(_(plan)) // 迭代策略生成物理执行计划节点
def strategies: Seq[GenericStrategy[PhysicalPlan]] // 生成物理执行计划的策略集合
从代码中可以看出来,GenericStrategy
抽象类的 def apply(plan: LogicalPlan): Seq[PhysicalPlan]
定义了物理执行计划生成逻辑。输入一个逻辑执行计划节点,输出物理执行计划节点列表。
1.2 策略详述
GenericStrategy
的定义
abstract class GenericStrategy[PhysicalPlan <: TreeNode[PhysicalPlan]] extends Logging {
// 占位符处理,占位符是替换和递归的标记
protected def planLater(plan: LogicalPlan): PhysicalPlan
// 生成物理执行计划方法
def apply(plan: LogicalPlan): Seq[PhysicalPlan]
}
GenericStrategy
继承体系,分两类通用的策略和实时(streaming)策略,下图是通用策略的部分继承关系:
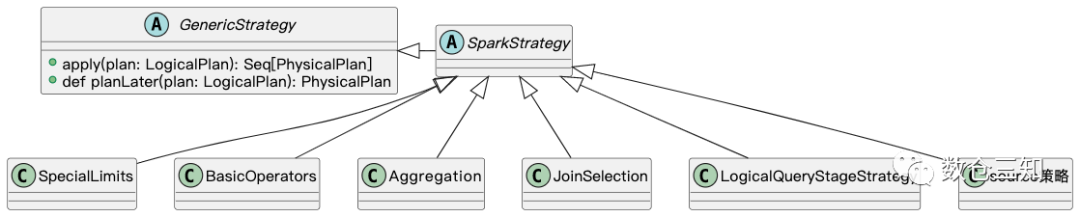
1.3 策略列表
startegies
的实现有两个,分别是SparkPlanner
和IncrementalExecution
中匿名SparkPlanner
的重写。其中IncrementalExecution
主要是streaming使用,这里不做讨论。
SparkPlanner
中策略列表:
override def strategies: Seq[Strategy] =
experimentalMethods.extraStrategies ++ // 实验策略
extraPlanningStrategies // 扩展策略
++ (
LogicalQueryStageStrategy ::
PythonEvals ::
new DataSourceV2Strategy(session) ::
FileSourceStrategy ::
DataSourceStrategy ::
SpecialLimits ::
Aggregation ::
Window ::
JoinSelection ::
InMemoryScans ::
SparkScripts ::
BasicOperators :: Nil)
// 扩展方法
def extraPlanningStrategies: Seq[Strategy] = Nil
其中分为3部分:
1.
experimentalMethods.extraStrategies
实验性质的策略通过spark.experimental.extraStrategies += ...
进行添加。2.
extraPlanningStrategies
扩展策略,可以通过SparkSessionExtensions
可以注入用户自定义生成策略SparkSession => Strategy
。3. 内置的策略。
2. 具体策略
2.1 SpecialLimits
SpecialLimits
将limit逻辑执行计划节点转换成物理执行计划。特殊的是这是唯一一个处理ReturnAnswer
逻辑执行计划的策略,处理方式是添加一个PlanLater占位符。case other => planLater(other) :: Nil
。
2.2 BasicOperators
最基本的物理执行节点生成策略,包含大部分简单的节点转换,如ExternalRDD
、Project
、Filter
、Sort
、Union
等等类型的节点转换。
利用模式匹配生成对应物理执行计划节点,对子节点的处理方式都是用PlanLater
占位符进行包装。
2.3 Aggregation
处理聚合逻辑执行计划策略,聚合在分布式计算环境下较为复杂。聚合的要素是:分组方式groupExpressions
、聚合函数aggExpressions
、输出结果列resultExpression
以及子节点child
。这些要素是从logical.Aggregate
解析得到,解析过程详见PhysicalAggregation.unapply
方法,主要逻辑是1.对逻辑执行计划中的聚合函数进行合并;2.对逻辑执行计划的输出进行重写。
Aggregation
物理执行计划生成有3个case
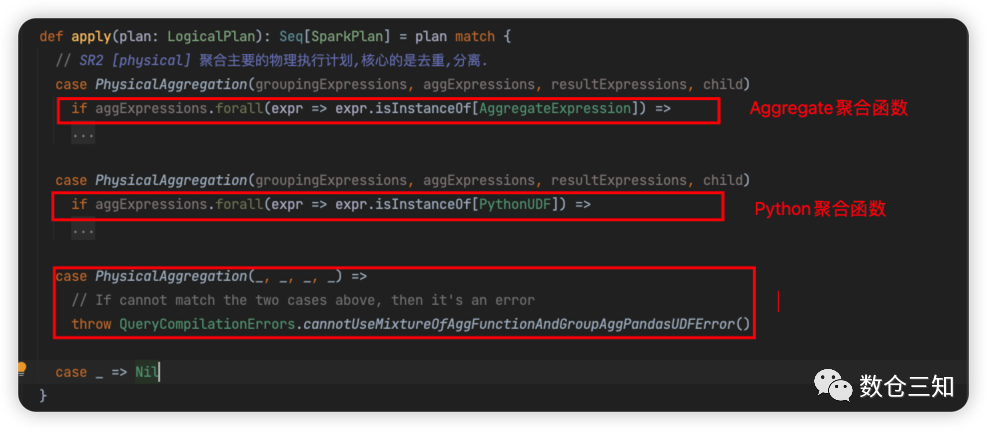
AggregateExpression
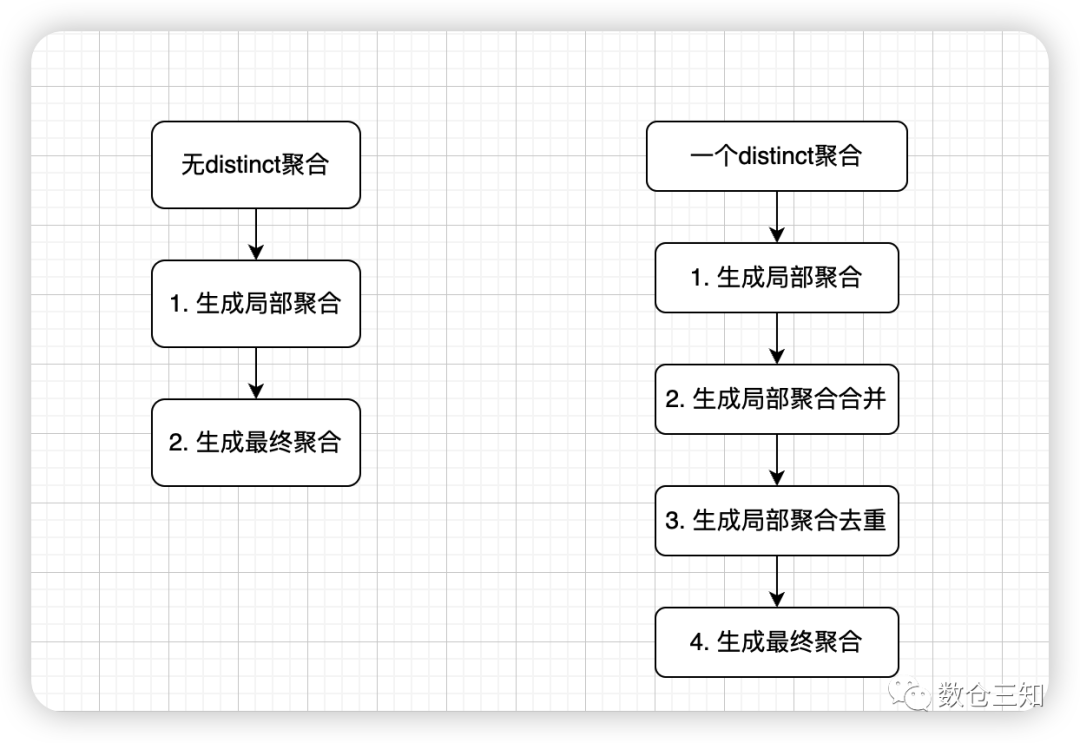
分支中分为不含distinct和含一个distinct【多个distinct可以由一个distinct组合而成】,生成方式位于AggUtils
类中planAggregateWithoutDistinct
和planAggregateWithOneDistinct
方法,方法执行流程分别是:
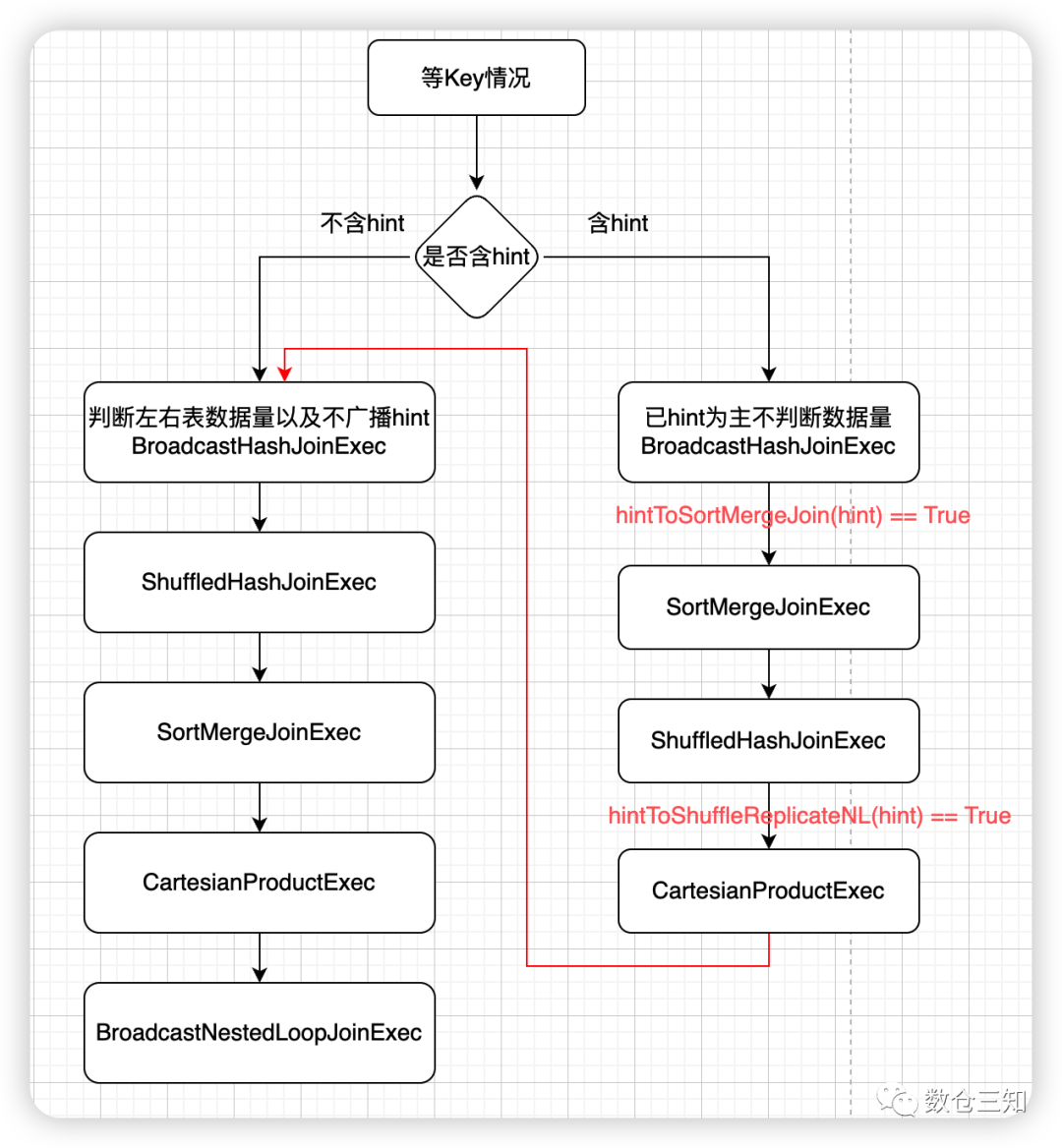
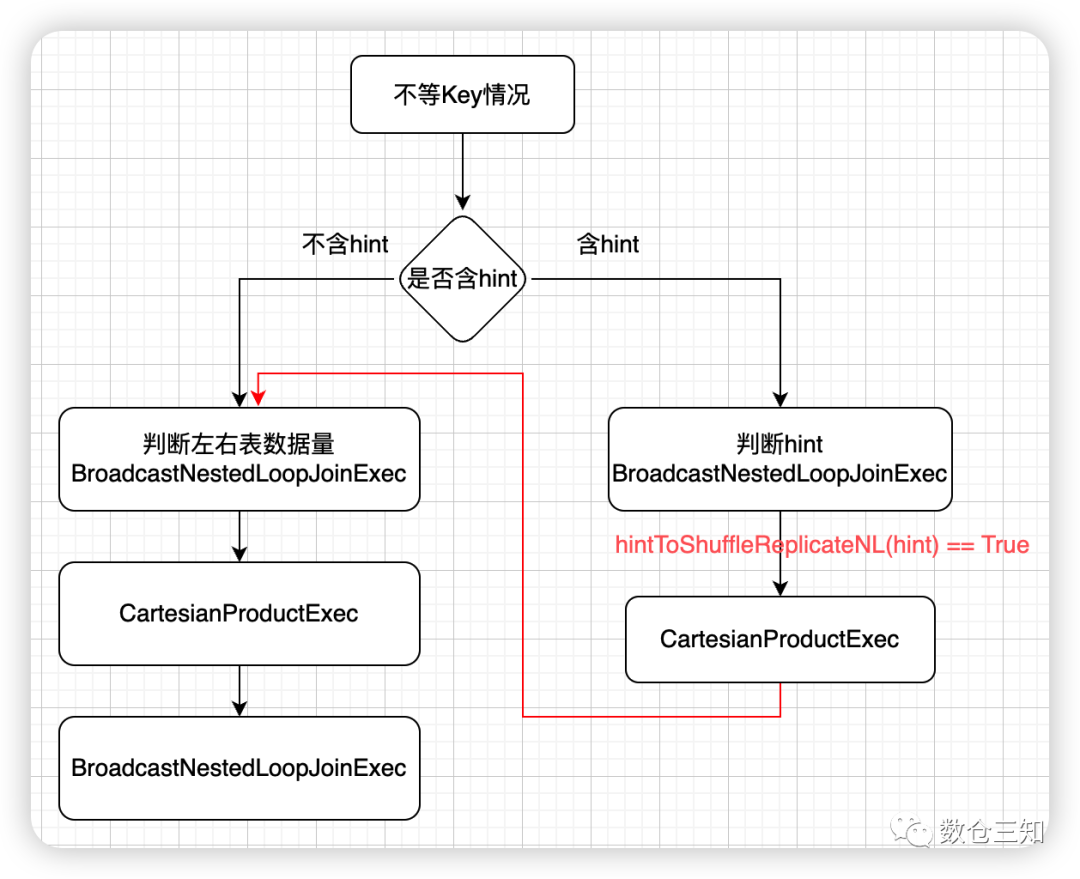
2.4 JoinSelection
join生成策略,分为3中case:
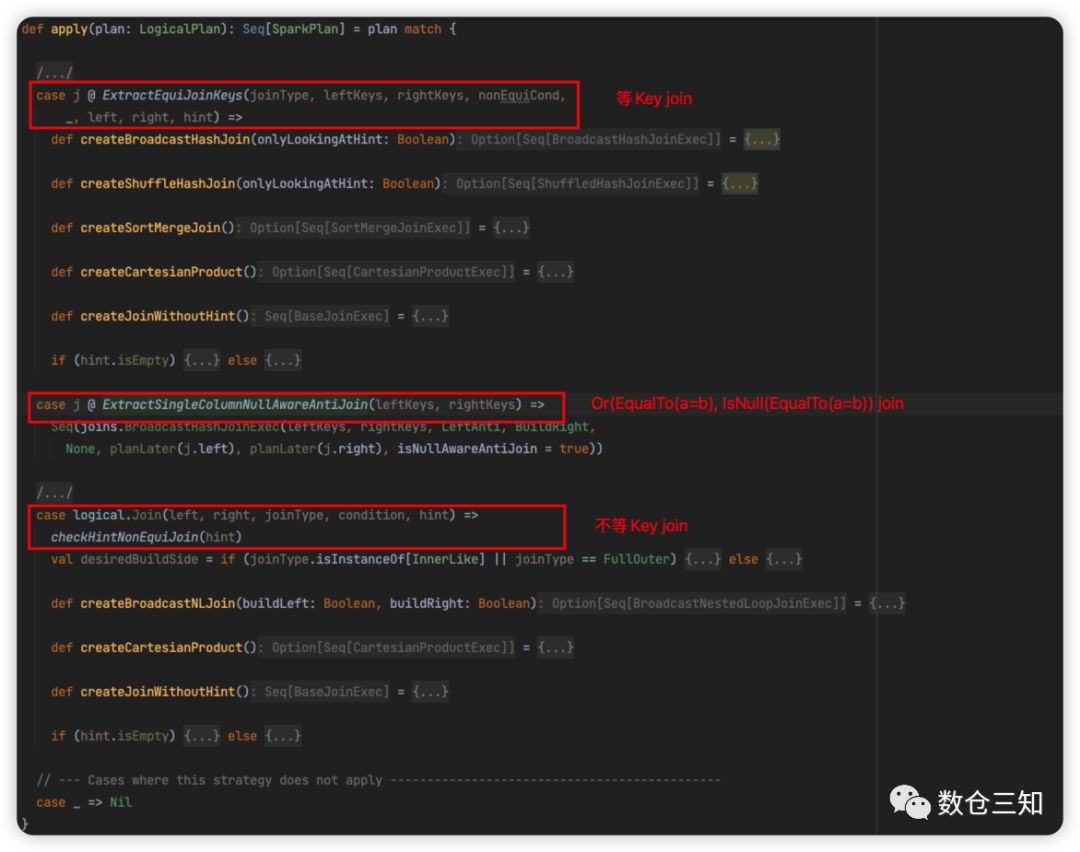
等key join生成流程
不等key join物理执行计划生成流程
其他生成策略不累述。
3 预告
下一篇将以具体的SQL为例,详细描述Aggregate物理执行计划生成过程。
