排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
聊聊时序数据库
聊聊时序数据库
白鳝的洞穴
2022-09-23
988
前阵子有朋友留言希望我写篇关于时序数据库的文章,以前我讨论的数据库大多数是RDBMS,其他数据库讨论的不多。说实在的对于时序数据库,我也只是一个小学生,我的客户使用时序数据库在一个应用系统中只是一部分很小的功能,大部分的应用系统的主要数据还是使用关系型数据库。
随着工业互联网的发展,以及物联网技术与应用的发展,时序数据库变得越来越热了。时序数据库是一种特殊的数据库管理系统,针对时间序列数据的处理进行了优化,每条记录都有时间戳。时序数据可能由物联网中的传感器、智能仪表或 RFID 产生,也可以由电网运行的各个采集点中产生,也可以从股票交易记录中产生。
时序数据的处理与关系型数据库的处理事不同的,时序数据库旨在有效地收集、存储和查询高频产生的各种时间序列数据。并在数据库的入库、批量查询、时序数据分析和过期数据自动处理等方面有着独特的方式。尽管可以使用传统的关系型数据库或者键值数据库来管理时序数据。其特点是大批量的写入带有时间戳的数据,可能高达每秒几百万甚至几千万个。同时数据被一次写入后不再修改,会被多次读取使用。这些数据要么被用于实时分析,要么被用于事后研究。一般应用软件会按照某种规则按照时间区间来装载一批数据,或者通过内建的统计函数去分析这些数据。这种应用往往不太关注单点的数据或者几个数据之间的关系。
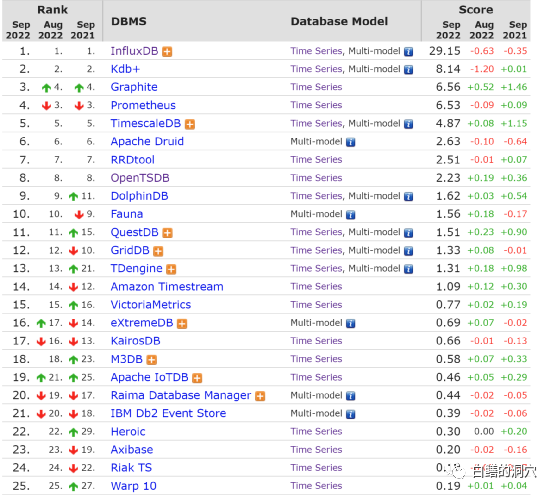
因为有一部分数据量并不是很大的时序数据库应用可以采用关系型数据库、HBASE、REDIS这样的KV数据库来存储,因此在日常应用中纯时序数据库使用的相对较少。因此时序数据库这些年发展的不温不火。从DB-ENGINES上看,纯粹的时序数据库的流行度得分并不高。
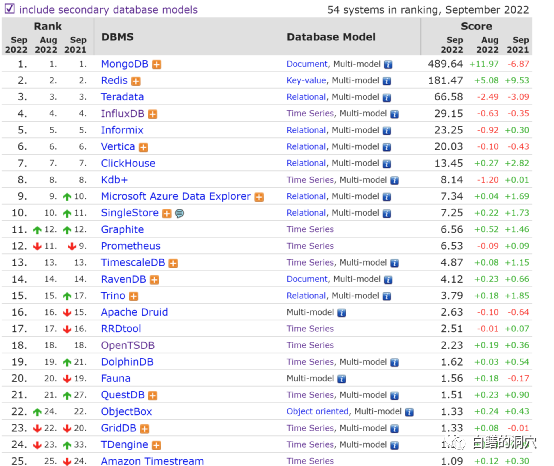
以第一模式为时序数据库类型的数据库排名看,排名最高的InfluxDB也仅仅29.15分,在数据库流行度排名中十分靠后。如果我们把主要数据库模式是其他类型,第二模式带有时序数据库模式的数据库加上,看到的是一个完全不同的情况。
在这里我们看到了一些大佬的身影,特别是现在大火的MongDB,作为文档数据库,MongoDB实际上是一种多模数据库,也支持时序数据。在国内MongoDB仅仅被作为文档数据库使用,仅仅存储一些目录与日志信息,不过MongoDB是一个十分全能的数据库产品,支持強一致性交易,甚至在时序数据库模式上也十分强大。西门子、博世等世界五百强企业用MongoDB来处理时序数据。在目前XC替代方面,实际上MongoDB是十分难以替代的,特别是你真正用了MongDB的事务、时序特性等,没有第二个数据库产品拥有MongoDB如此强大的功能。而MongoDB从商业利益上考虑将开源协议转为SSPL后,开始收割云服务厂商,而这种接近于商用协议的开源协议极容易受到美国政府出口管制措施的影响,因此对于有XC要求的企业来说,还是要十分小心的。
令人意外的事Redis这种我们经常用来做缓冲的,十分简单的内存KV数据库,也是多模的,也支持时序数据。Redis支持SortedSets数据结构,支持按权重存储数据并支持按照权重的范围查询。如果把时间戳作为权重值,key存储具体的度量维度,那么Redis就可以支持时序数据了。不过这种模式过于简单粗暴,十分消耗内存,而且并发写入性能也不好,只适合最为简单的模式。从Redis 5.0开始,Redis开始支持消息队列Stream,流式数据也是时序数据处理中的一种常见场景。而真正让Redis具有真正的流式数据库能力的是Redis TimeSeries扩展模块的引入。这是
专门面向时间序列数据提供了数据类型和访问接口,并且支持在Redis端上直接对数据进行时间范围的聚合计算(
min、max、avg、sum、range、count、first、last)。
在这个列表里我们还看到了最近比较火的ClickHose。Clickhouse是俄罗斯yandex公司于2016年开源的一个列式数据库管理系统,近些年像一匹黑马一样迅速在具有时序处理需求的OLAP场景中收割用户。其向量化引擎SIMD让一些大数据量的简单分析查询性能得到了极大的释放。只不过ClickHose简单粗暴的向量引擎限制了应用的并发,不过在OLAP场景中,高并发并不总是刚需。
大多数时序数据库的应用场景可以将时序数据库独立开来存储与访问,而应用中的较为复杂的业务数据可以放在关系型数据库里。而时序数据的读写场景相对简单,因此时序数据库在数据库领域的热度较低。
有些关系型数据库用户开始的时候都把时序数据存储在关系型数据库里,不过因为时序数据的数据量太大了。会导致关系型数据库的容量变得超大,我以前做过一个优化项目,业务数据库的库容高达上百TB,而实际上里面的关系型的业务数据只有几百GB,大多数都是写入后只读的时序数据。后来我建议他们吧时序数据独立出去了,这样数据库备份,运维就简单多了。
而把超大规模的时序数据写入关系型数据库,很可能就会到达关系型数据库的天花板,让数据库的性能无法跟上。如果把这类数据存储到纯粹的时序数据库里,那么就很容易利用其分布式特性很好的横向扩展了。时序数据库存储这些数据的时候,会占用更小的空间,也很容易实现自动的数据压缩。另外利用专用的API访问时间,对数据做复杂的汇总统计,也比SQL接口要快捷的多。因此很多企业都陆续将时序数据从传统的关系型数据库中分离出来,存储到专业的时序数据库中。
不过还有另外一种思路,那就是在关系型数据库中增加时序数据库的能力。最为典型的就是TimeScaleDB。当时序数据的量还不算太大的时候,有些用户选择了将时序数据存储到关系型数据库中。在PostgreSQL数据库中安装TimeScaleDB插件,创建时序表来存储时序数据。同事利用PG的SQL引擎来访问和处理这些时序数据。利用TimeScaleDB的历史数据自动压缩功能压缩历史数据,可以大大减少海量历史数据的存储量。我们的D-SMART中需要采集大量的数据库的监控数据,大概每2分钟采集一次,每次有上千个实例,每个实例有数百条记录。这样的话,一个纳管了2000个数据库的D-SMART,每隔两分钟,就会有100万条数据被写入TimeScaleDB,并且这些数据还需要按照时间区间,通过SQL查询出来,进行分析处理。从这些年的使用来看,TimeScaleDB是可以轻松应对这样的场景的,每个SQL查询也都是几十毫秒就可以完成。我们最初是使用PG的普通表存储这些监控数据的,换成TimeScaleDB后,写入性能与查询性能都有了多倍的提升。最令我们喜欢的是历史数据的自动压缩功能,作为运维自动化系统,7天前的监控数据被访问的比例很低,因此我们设置了7天数据自动压缩,大大节约了存储资源。
使用TimeScaleDB最大的好处是保留了我们团队在SQL上的所有研发经验,只要不乱写SQL,大部分SQL不需要特殊的优化改写,就可以达到性能要求。实现这种开发自由来自于TimeScaleDB优秀的设计,因为时间问题,我们在这里就展开讨论了。如果是千万到数亿级别的时序数据处理,使用TimeScaleDB是没有任何压力的。
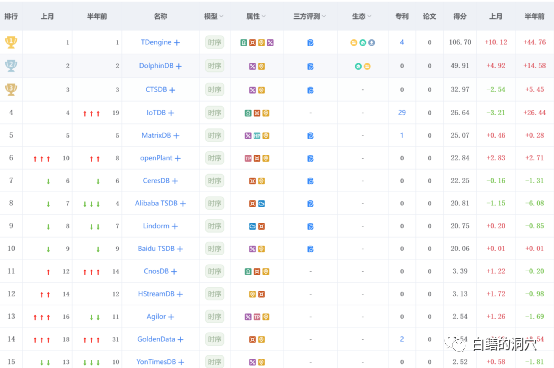
国产的时序数据库产品也很多,在墨天轮上目前有32种国产时序数据库,已经和DB-ENGINES上35种纯时序数据库的列表差不多长了。其中排名靠前的涛思数据的TDengine和智叟科技的DolphinDB。在DB-ENGINES的时序数据库排行中,这两种时序数据库也比较靠前。也有一些国产时序数据库基于openTSDB,或者与之兼容。
时序数据库与时序应用的发展呈现出三种模式,大家也都在争论哪种模式更好。
第一种模式是放弃关系型数据库,转向时序数据库或者用带有时序数据库模式的多模数据库替代关系型数据库。利用原生分布式架构,带有向量处理能力的数据库引擎来支撑特别大数据量写入,大数据量输出需求的场景。这些人认为NOSQL才是时序数据处理的最终解决方案。
第二种模式正好相反,他们从NOSQL的时序数据库转向了具有时序数据处理能力的关系型数据库,充分利用SQL的能力来解决应用的问题。最典型的就是我今天介绍的D-SMART里使用的TimeScaleDB。对于更大数据量的需求,可以使用CrateDB、TDengine这样的分布式数据库。
第三种模式是使用HBASE这样的KV数据库来存储时序数据,而不专门使用时序数据库。对于仅仅把海量时序数据找个地方存起来,满足大并发写入,大吞吐量输出的场景要求就行了,大量的数据处理都是应用程序自己来干,那么这样的用法也没啥问题。
实际上也无需争论,因为不同的应用场景就会选择不同的模式。到底你选择什么样的时序数据库方案,往往取决于下面几个因素:1)你的时序数据的量级是什么样的,每秒几万,几十万,还是几百万,几千万;2)你的时序数据如何被使用,每次读取的批次是多少;3)你需要数据库的内置功能来处理和分析时序数据,还是有自己的数据分析应用模块;4)你如何处理过期的数据;5)你的历史数据的访问模式;6)你的查询并发QPS是多少;……。
我想你把这几个问题考虑清楚了,再根据目前主流的时序数据库或者带有时序功能的多模数据库的特征去找寻,那么就不难做出相对靠谱的选择了。
内存时序
大数据
mongodb
关系型数据库
数据库
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨