




PostgreSQL 13 典型变化如下:
逻辑复制支持分区表
Btree索引优化(引入
Deduplication
技术)增量排序
(Incremental Sorting
)并行
VACUUM
索引并行
Reindexdb手册新增术语(
Glossary
)附录
本文从新特性、性能提升、数据库管理、其它亮点四方面详细介绍 PostgreSQL 13的变化。
目录
PostgreSQL 13 新特性汇总
1、新特性
2、性能提升
3、数据库管理
4、其它亮点
参考
1、新特性
1.1、PostgreSQL 13: 逻辑复制支持分区表
PostgreSQL 10 版本开始支持逻辑复制,在12版本之前逻辑复制仅支持普通表,不支持分区表,如果需要对分区表进行逻辑复制,需单独对所有分区进行逻辑复制。
PostgreSQL 13 版本的逻辑复制新增了对分区表的支持,如下:
可以显式地发布分区表,自动发布所有分区。
从分区表中添加/删除分区将自动从发布中添加/删除。
关于逻辑复制之前博客有介绍,详见PostgreSQL10:逻辑复制(Logical Replication)之一,本文仅做简单演示。
环境规划
环境规划,如下:
| 节点 | 数据库版本 | IP | 端口 |
|---|---|---|---|
| 源库 | PostgreSQL 13beta1 | 192.168.2.11 | 1922 |
| 目标库 | PostgreSQL 13beta1 | 192.168.2.13 | 1924 |
环境准备
在源库、目标库安装 PostgreSQL 13beta1软件并初始化数据库,本文略。
部署mydb数据库
在源库和目标库上均部署 mydb 数据库,如下:
--建用户CREATE ROLE pguser LOGIN ENCRYPTED PASSWORD 'pguser' nosuperuser noinherit nocreatedb nocreaterole ;--创建表空间(如果有 Standby ,也需要创建目录)mkdir -p pgdata/pg13/pg_tbs/tbs_mydb--创建数据库CREATE DATABASE mydbWITH OWNER = postgresTEMPLATE = template0ENCODING = 'UTF8'TABLESPACE = tbs_mydb;--赋权grant all on database mydb to pguser with grant option;grant all on tablespace tbs_mydb to pguser;
创建分区表
在源库和目标库上创建分区表,如下:
--创建父表CREATE TABLE tbl_log ( id serial, user_id int4, create_time timestamp(0) without time zone) PARTITION BY RANGE(create_time);--创建子表CREATE TABLE tbl_log_his PARTITION OF tbl_log FOR VALUES FROM (minvalue) TO ('2020-01-01');CREATE TABLE tbl_log_202001 PARTITION OF tbl_log FOR VALUES FROM ('2020-01-01') TO ('2020-02-01');CREATE TABLE tbl_log_202002 PARTITION OF tbl_log FOR VALUES FROM ('2020-02-01') TO ('2020-03-01');CREATE TABLE tbl_log_202003 PARTITION OF tbl_log FOR VALUES FROM ('2020-03-01') TO ('2020-04-01');CREATE TABLE tbl_log_202004 PARTITION OF tbl_log FOR VALUES FROM ('2020-04-01') TO ('2020-05-01');CREATE TABLE tbl_log_202005 PARTITION OF tbl_log FOR VALUES FROM ('2020-05-01') TO ('2020-06-01');CREATE TABLE tbl_log_202006 PARTITION OF tbl_log FOR VALUES FROM ('2020-06-01') TO ('2020-07-01');CREATE TABLE tbl_log_202007 PARTITION OF tbl_log FOR VALUES FROM ('2020-07-01') TO ('2020-08-01');--创建索引CREATE INDEX idx_tbl_log_ctime ON tbl_log USING BTREE (create_time);
部署逻辑复制
源库执行以下操作,如下:
--创建复制用户CREATE USER repuser REPLICATION LOGIN CONNECTION LIMIT 10 ENCRYPTED PASSWORD 'rep123us345er';--创建发布mydb=> CREATE PUBLICATION pub1 FOR TABLE tbl_log;CREATE PUBLICATION--给repuser用户赋权mydb=> GRANT CONNECT ON DATABASE mydb TO repuser;mydb=> GRANT USAGE ON SCHEMA pguser TO repuser;mydb=> GRANT SELECT ON ALL TABLES IN SCHEMA pguser TO repuser;
以上有个步骤是给源库上的repuser用户赋相关权限,如果不给repuser用户赋权,创建订阅后目标库无法初始化同步源库数据。
目标库创建订阅,如下:
CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.2.11 port=1922 dbname=mydb user=repuser' PUBLICATION pub1;
注意配置好源库的pg_hba.conf
和.pgpass
文件,否则创建订阅会报相关的连接不上错误。
数据验证
源库批量插入数据,如下:
INSERT INTO tbl_log(user_id,create_time)SELECT round(100000000*random()),generate_series('2019-10-01'::date, '2020-06-20'::date, '1 day');
源库查看数据,如下:
[pg13@ydtf01 ~]$ psql mydb pguser -p 1922psql (13beta1)Type "help" for help.mydb=> SELECT count(*) FROM tbl_log; count------- 264(1 row)mydb=> SELECT count(*) FROM tbl_log_202001; count------- 31(1 row)mydb=> SELECT count(*) FROM tbl_log_his; count------- 92(1 row)
目标库验证数据,如下:
[pg13@ydtf03 ~]$ psql mydb pguser -p 1924psql (13beta1)Type "help" for help.mydb=> SELECT count(*) FROM tbl_log; count------- 264(1 row)mydb=> SELECT count(*) FROM tbl_log_202001; count------- 31(1 row)mydb=> SELECT count(*) FROM tbl_log_his; count------- 92(1 row)
可见分区表的数据已从源库同步到目标库。
1.2、PostgreSQL 13: CREATE SUBSCRIPTION新增publish_via_partition_root选项支持异构分区表间的数据逻辑复制
PostgreSQL 13 版本CREATE SUBSCRIPTION
命令新增 publish_via_partition_root 选项支持异构分区表的数据同步,具体为:
分区表数据逻辑复制到普通表。
分区表数据逻辑复制到异构分区表。
第2点所说的异构分区表是指目标库和源库同一张分区表的分区策略可以不一样,比如源库分区表的分区策略是按月分区,目标库分区表的分区策略可以是按年分区。这一功能对于分区表具有重要意义,当需要从多个源库汇总数据到同一个目标库的分区表时,目标库的分区策略可以设置成和源库不一致,便于数据汇总统计。
关于 publish_via_partition_root
选项,如下:
该选项设置发布中包含的分区表中的更改(或分区上的更改)是否使用分区表父表的标识和模式发布,而不是使用各个分区的标识和模式发布。
默认使用分区进行标识和模式发布。
设置为true,可以将分区表的数据逻辑复制到普通表和异构分区表。
如果设置为true,分区上的
TRUNCATE
操作不会进行逻辑复制。
本文对分区表在上述两种场景下的逻辑复制进行验证,如下:
场景一: 分区表数据逻辑复制到普通表。
场景二: 分区表数据逻辑复制到异构分区表。
环境规划
同上
环境准备
同上
创建分区表
同上
创建发布
源库上创建发布,如下:
mydb=> CREATE PUBLICATION pub1 FOR TABLE tbl_log WITH (publish_via_partition_root=true);
创建发布时使用了 publish_via_partition_root
选项。
给repuser用户赋权,如下:
mydb=> GRANT CONNECT ON DATABASE mydb TO repuser;mydb=> GRANT USAGE ON SCHEMA pguser TO repuser;mydb=> GRANT SELECT ON ALL TABLES IN SCHEMA pguser TO repuser;
给源库上的repuser用户赋相关权限,如果不给repuser用户赋权,创建订阅后目标库无法初始化同步源库数据。
插入数据
源库批量插入数据,如下:
mydb=> INSERT INTO tbl_log(user_id,create_time)SELECT round(100000000*random()),generate_series('2019-10-01'::date, '2020-06-20'::date, '1 day');
场景一: 分区表逻辑复制到普通表
源库上的tbl_log是分区表,计划在源库上创建一张非分区表tbl_log并配置逻辑复制,验证数据是否能正常同步。
目标库上创建普通表,如下:
CREATE TABLE tbl_log ( id serial, user_id int4, create_time timestamp(0) without time zone);
创建订阅,如下:
CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.2.11 port=1922 dbname=mydb user=repuser' PUBLICATION pub1;NOTICE: created replication slot "sub1" on publisher
注意配置好源库的pg_hba.conf
和.pgpass
文件,否则创建订阅会报相关的连接不上错误。
验证目标库数据,如下:
[pg13@ydtf03 ~]$ psql mydb pguser -p 1924psql (13beta1)Type "help" for help.mydb=> SELECT COUNT(*) FROM tbl_log; count------- 264(1 row)mydb=> \dt+ tbl_log* List of relations Schema | Name | Type | Owner | Persistence | Size | Description--------+---------+-------+--------+-------------+-------+------------- pguser | tbl_log | table | pguser | permanent | 40 kB |(1 row)
数据已从源库同步。
文档中提到对分区上的TRUNCATE
操作不会进行逻辑复制,验证下:
源库执行如下操作:
[pg13@ydtf01 ~]$ psql mydb pguser -p 1922psql (13beta1)Type "help" for help.mydb=> select count(*) from tbl_log; count------- 264(1 row)mydb=> select count(*) from tbl_log_his; count------- 92(1 row)mydb=> TRUNCATE TABLE tbl_log_his;TRUNCATE TABLE
目标库上验证数据是否已删除,如下:
[pg13@ydtf03 ~]$ psql mydb pguser -p 1924psql (13beta1)Type "help" for help.mydb=> SELECT COUNT(*) FROM tbl_log; count------- 264(1 row)mydb=> SELECT COUNT(*) FROM tbl_log_his; count------- 92(1 row)
发现目标库上数据没有变化。
场景二: 分区表逻辑复制到异构分区表
源库的tbl_log是按月分区表,计划在目标库上创建一张按年分区表tbl_log并配置逻辑复制,验证数据是否能正常同步。
目标库上删除表 tbl_log ,如下:
mydb=> DROP TABLE tbl_log_tmp ;DROP TABLE
目标库上创建按年分区表,如下:
--创建父表CREATE TABLE tbl_log ( id serial, user_id int4, create_time timestamp(0) without time zone) PARTITION BY RANGE(create_time);--创建子表CREATE TABLE tbl_log_his PARTITION OF tbl_log FOR VALUES FROM (minvalue) TO ('2020-01-01');CREATE TABLE tbl_log_2020 PARTITION OF tbl_log FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');CREATE TABLE tbl_log_2021 PARTITION OF tbl_log FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');--创建索引CREATE INDEX idx_tbl_log_ctime ON tbl_log USING BTREE (create_time);
源库数据,如下:
[pg13@ydtf01 ~]$ psql mydb pguser -p 1922psql (13beta1)Type "help" for help.mydb=> select count(*) from tbl_log; count------- 172(1 row)
观察目标库数据,如下:
[pg13@ydtf03 ~]$ psql mydb pguser -p 1924psql (13beta1)Type "help" for help.mydb=> \dt+ tbl_log* List of relations Schema | Name | Type | Owner | Persistence | Size | Description--------+--------------+-------------------+--------+-------------+---------+------------- pguser | tbl_log | partitioned table | pguser | permanent | 0 bytes | pguser | tbl_log_2020 | table | pguser | permanent | 0 bytes | pguser | tbl_log_2021 | table | pguser | permanent | 0 bytes | pguser | tbl_log_his | table | pguser | permanent | 0 bytes |(4 rows)mydb=> SELECT COUNT(*) FROM tbl_log; count------- 0(1 row)
发现目标库数据还没有同步过来。
目标库刷新订阅,如下:
ALTER SUBSCRIPTION sub1 REFRESH PUBLICATION;
再次在目标库上验证数据,发现数据已同步,如下:
mydb=> \dt+ tbl_log*List of relations Schema | Name | Type | Owner | Persistence | Size | Description--------+--------------+-------------------+--------+-------------+------------+------------- pguser | tbl_log | partitioned table | pguser | permanent | 0 bytes | pguser | tbl_log_2020 | table | pguser | permanent | 8192 bytes | pguser | tbl_log_2021 | table | pguser | permanent | 0 bytes | pguser | tbl_log_his | table | pguser | permanent | 0 bytes |(4 rows)mydb=> SELECT COUNT(*) FROM tbl_log; count------- 172(1 row)mydb=> SELECT COUNT(*) FROM tbl_log_2020; count------- 172(1 row)
总结
本文演示了分区表数据逻辑复制到普通表和异构分区表的场景,实际上普通表也可以逻辑复制到分区表,有兴趣的同学可查阅 PostgreSQL 13: 普通表数据逻辑复制到分区表。
1.3、PostgreSQL 13: 新增内置函数Gen_random_uuid()生成UUID数据
PostgreSQL 13版本前不提供生成UUID
数据的内置函数,如果需要使用UUID
数据,可通过创建外部扩展 uuid-ossp或 pgcrypto生成 UUID
数据。
PostgreSQL 13 新增gen_random_uuid()
内置函数,可生成UUID
数据。
关于gen_random_uuid()函数
gen_random_uuid()
函数生成 version 4 UUID
(基于随机数生成,使用最广泛)。
一个示例,如下:
postgres=# \df gen_random_uuidList of functions Schema | Name | Result data type | Argument data types | Type------------+-----------------+------------------+---------------------+------ pg_catalog | gen_random_uuid | uuid | | func(1 row)postgres=# SELECT gen_random_uuid();gen_random_uuid-------------------------------------- e5194f5d-0602-4a88-b388-c3bd7bfd570e
生成一张包含UUID数据的表
PostgreSQL 提供 UUID数据类型,在UUID
数据上可创建btree
索引,下面演示下。
创建测试表并生成UUID
数据,之后创建索引,如下:
mydb=> CREATE TABLE uuid_01(id_int int4, id_uuid uuid,ctime timestamp(6) without time zone);mydb=> INSERT INTO uuid_01(id_int,id_uuid,ctime) SELECT n,gen_random_uuid(),clock_timestamp() FROM generate_series(1,2000000) n;mydb=> CREATE UNIQUE INDEX idx_uuid_01_uuid ON uuid_01 USING BTREE (id_uuid);
查看UUID
数据和执行计划,如下:
mydb=> SELECT *FROM uuid_01 LIMIT 1;id_int | id_uuid| ctime--------+--------------------------------------+---------------------------- 1 | 3ba43653-e470-40d9-bfc0-55d33677ec22 | 2020-07-08 21:10:39.010639(1 row)mydb=> EXPLAIN ANALYZE SELECT *FROM uuid_01 WHERE id_uuid='3ba43653-e470-40d9-bfc0-55d33677ec22';QUERY PLAN--------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_uuid_01_uuid on uuid_01 (cost=0.43..4.45 rows=1 width=28) (actual time=0.027..0.029 rows=1 loops=1) Index Cond: (id_uuid = '3ba43653-e470-40d9-bfc0-55d33677ec22'::uuid) Planning Time: 0.162 ms Execution Time: 0.059 ms(4 rows)
2、性能提升
2.1、PostgreSQL 13: Btree索引优化(引入Deduplication技术)
PostgreSQL 13 版本的Btree索引在存储层面引入了一个重要的技术,名为Deduplication,是指索引项去重技术。
Deduplication技术的引入能够减少索引的存储空间和维护开销,同时提升查询效率。
索引的Deduplication选项默认是开启的,如果想关闭指定索引的Deduplication,设置存储参数deduplicate_items为off即可。
本文简单介绍下 Deduplication 技术,并给出示例演示。
Deduplication介绍
PostgreSQL 13 版本前 Btree 索引会存储表的所有索引键,从而产生很多重复的索引项,13 版本引入的 deduplication 技术,可以大幅度减少重复索引项。
Deduplication 会定期的将重复的索引项合并,为每组形成一个发布列表元组,重复的索引项在此列表中仅出现一次,当表的索引键重复项很多时,能显著减少索引的存储空间。
Deduplication的优点
Deduplication技术的引入具有以下优点:
减少存储空间: 重复的索引项被合并,能显著减少索引的存储空间。
减少索引维护开销: 重建索引速度更快,vacuum索引的开销更低。
提升查询效率: 更小的索引能够减少查询的时延,并提升吞吐量。
环境准备
计划在PostgreSQL 12 和 13 版本分别创建unique索引和重复项很多的索引,比较索引的大小。
创建测试表的脚本如下:
CREATE TABLE user_info (userid int4, username character varying(32),regtime timestamp without time zone);INSERT INTO user_info (userid,username,regtime) SELECT n, 'user_info' || n, '2020-06-29 21:00:00' FROM generate_series(1,5000000) n;CREATE UNIQUE INDEX idx_user_info_usename ON user_info USING BTREE(username);CREATE INDEX idx_user_info_regtime ON user_info USING BTREE(regtime);
分别在PostgreSQL 12.2和 PostgreSQL 13 Beta1创建两个索引
idx_user_info_usename为unique索引,存储的索引项唯一。
idx_user_info_regtime为deduplicated 索引,存储的索引项都相同。
测试索引大小
PostgreSQL 12.2 查看索引大小,如下:
postgres=# \di+ idx_user_info_usename List of relations Schema | Name | Type | Owner | Table | Size | Description--------+-----------------------+-------+----------+-----------+--------+------------- public | idx_user_info_usename | index | postgres | user_info | 185 MB |(1 row)postgres=# \di+ idx_user_info_regtime List of relations Schema | Name | Type | Owner | Table | Size | Description--------+-----------------------+-------+----------+-----------+--------+------------- public | idx_user_info_regtime | index | postgres | user_info | 107 MB |(1 row)
PostgreSQL 13 Beta1 查看索引大小,如下:
postgres=# \di+ idx_user_info_usename List of relations Schema | Name | Type | Owner | Table | Persistence | Size | Description--------+-----------------------+-------+----------+-----------+-------------+--------+------------- public | idx_user_info_usename | index | postgres | user_info | permanent | 185 MB |(1 row)postgres=# \di+ idx_user_info_regtime List of relations Schema | Name | Type | Owner | Table | Persistence | Size | Description--------+-----------------------+-------+----------+-----------+-------------+-------+------------- public | idx_user_info_regtime | index | postgres | user_info | permanent | 33 MB |(1 row)
根据以上看出,创建索引后,unique索引在12版本13版本大小一致,deduplicated索引差异较大,13版本的deduplicated索引大小约为12版本的三分之一。
唯一索引是否受Deduplication影响?
手册上提到: 即使是unique索引也可以使用Deduplication技术控制重复数据的膨胀,因为索引项的TIDs指向同一行数据的不同版本。
换句话说,当表的数据被update
时,依据PostgreSQL的MVCC机制,老的tuple依然保留在原有PAGE上,并新增一条tuple,索引将同时存储新版本和老版本表数据的索引键。
目前没想到恰当的场景演示Deduplication对Unique索引影响,后续想到了再补充。
如何关闭索引的Deduplication?
可通过存储参数deduplicate_items控制索引是否启用Deduplication,这个参数默认为开启。
关闭索引的Deduplication,如下:
postgres=# ALTER INDEX idx_user_info_regtime SET (deduplicate_items=off);
2.2、PostgreSQL 13: 支持增量排序(Incremental Sorting)
PostgreSQL 13 版本的一个重要特性是支持增量排序(Incremental Sorting),加速数据排序,例如以下SQL:
SELECT * FROM t ORDER BY a,b LIMIT 10;
如果在字段a上建立了索引,由于索引是排序的,查询结果集的a字段是已排序的,这种场景下,PostgreSQL 13 的增量排序可以发挥重要作用,大幅加速查询,因为ORDER BY a,b
中的字段a
是已排序好的,只需要在此基础上对字段b
进行批量排序即可。
测试准备
计划在PostgreSQL 13 演示增量排序,创建测试表,并插入测试数据,如下:
CREATE TABLE t_is(a int4,b int4,ctime timestamp(6) without time zone);INSERT INTO t_is(a,b,ctime) SELECT n,round(random()*100000000), clock_timestamp() FROM generate_series(1,1000000) n;INSERT INTO t_is(a,b,ctime) SELECT n,round(random()*100000000), clock_timestamp() FROM generate_series(1,1000000) n;CREATE INDEX idx_t_is_a ON t_is USING BTREE(a);
查看测试数据,如下:
postgres=# SELECT * FROM t_is ORDER BY a,b LIMIT 10;a | b | ctime---+----------+---------------------------- 1 | 60379526 | 2020-07-21 16:28:42.034869 1 | 73197294 | 2020-07-21 16:28:45.496297 2 | 943408 | 2020-07-21 16:28:45.496346 2 | 27584454 | 2020-07-21 16:28:42.036121 3 | 31616182 | 2020-07-21 16:28:45.496348 3 | 88997913 | 2020-07-21 16:28:42.036134 4 | 21557231 | 2020-07-21 16:28:45.49635 4 | 23206459 | 2020-07-21 16:28:42.036136 5 | 13268559 | 2020-07-21 16:28:45.496351 5 | 33672766 | 2020-07-21 16:28:42.036137(10 rows)
PostgreSQL 13 测试
当开启enable_incrementalsort
时,执行以下SQL,如下:
postgres=# SHOW enable_incrementalsort ;enable_incrementalsort------------------------ on(1 row)postgres=# EXPLAIN ANALYZE SELECT * FROM t_is ORDER BY a,b LIMIT 10;QUERY PLAN----------------------------------------------------------------------------------------------------------------------------------------- Limit (cost=0.51..1.16 rows=10 width=16) (actual time=0.042..0.044 rows=10 loops=1) -> Incremental Sort (cost=0.51..130115.72 rows=2000000 width=16) (actual time=0.041..0.042 rows=10 loops=1) Sort Key: a, b Presorted Key: a Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB -> Index Scan using idx_t_is_a on t_is (cost=0.43..58848.31 rows=2000000 width=16) (actual time=0.021..0.027 rows=11 loops=1) Planning Time: 0.106 ms Execution Time: 0.064 ms(8 rows)
执行计划中重点关注Presorted Key: a
和 Incremental Sort
两行,SQL执行时间为 0.064ms。
当关闭enable_incrementalsort
时,执行SQL,
执行计划中没有Incremental Sort
相关信息,SQL执行时间上升为 160.027ms,性能相比开启增量排序时差了好几个数量级。
总结
本文演示了 PostgreSQL 13 版本的增量排序,在本文的测试场景中,开启增量排序比不开启增量排序的SQL执行性能上升了好几个数量级,但并不能说明绝大多数开启了增量排序的SQL性能要比不开启性能高出好几个数量级,个人推测与排序的字段组合及排序字段数据分布也有关系,本文不做进一步的分析,有兴趣的朋友可构造测试案例进一步测试。
3、数据库管理
3.1、PostgreSQL 13: EXPLAIN、Auto_explain、autovacuum、pg_stat_statements跟踪WAL使用信息
PostgreSQL 13版本的EXPLAIN
、auto_explain
、autovacuum
、pg_stat_statements
可以跟踪WAL使用信息。
EXPLAIN跟踪WAL使用信息
13版本的EXPLAIN
命令新增WAL选项,启用后可以跟踪WAL使用信息,此选项的说明如下:
WAL Include information on WAL record generation. Specifically, include the number of records, number of full page images (fpi) and amount of WAL bytes generated. In text format, only non-zero values are printed. This parameter may only be used when ANALYZE is also enabled. It defaults to FALSE.
跟踪WAL信息的前提条件是启用ANALYZE
选项,WAL信息包括以下三部分:
WAL record: WAL记录条目数。
(Fpi): Full page images。
WAL bytes: WAL日志大小,单位为字节。
Auto_explain跟踪WAL使用信息
同理,auto_explain
外部模块新增了是否跟踪WAL使用信息的选项,通过参数auto_explain.log_wal
控制
Autovacuum跟踪WAL使用信息
autovacuum
同样支持是否跟踪WAL信息,下面演示下:
设置log_autovacuum_min_duration参数为0
pg_stat_statements跟踪WAL使用信息
pg_stat_statements
视图同样新增wal_records、wal_fpi、wal_bytes三个字段,可以跟踪WAL的使用信息,如下:
wal_records: Total number of WAL records generated by the statement
wal_fpi: Total number of WAL full page images generated by the statement
wal_bytes: Total amount of WAL bytes generated by the statement
总结
WAL日志膨胀是PostgreSQL数据库运维过程中的常见问题,13版本的这一新特性使得对WAL的膨胀分析带来帮助。
3.2、PostgreSQL 13: 新增log_min_duration_sample参数控制日志记录的慢SQL百分比
PostgreSQL 新增log_min_duration_sample参数用来控制日志记录的慢SQL百分比。PostgreSQL 12 已提供了log_statement_sample_rate 参数控制日志记录的慢SQL百分比,之前写了篇博客可参考: PostgreSQL 12: 新增 log_statement_sample_rate 参数控制数据库日志中慢SQL百分比。
但 PostgreSQL 13版本这个参数的定义与12版本有差异,使得对慢查询的抽样记录策略有变化,先来看看手册中这几个参数的说明。
13版本与12版本慢查询抽样策略差异
PostgreSQL 12日志中慢查询抽样策略,如下:

PostgreSQL 13日志中慢查询抽样策略,如下:

通过上图说明应该很容易理解12版本与13版本在抽样策略的差异。
3.3、PostgreSQL 13: Reindexdb命令新增-j选项,支持全库并行索引重建
reindexdb
命令用于重建一个或多个库中表的索引,可以是schema
级索引重建,也可以是database
级索引重建。
reindexdb
是REINDEX INDEX
命令的的封装,两者在本质上没有区别。
13版本前reindexdb
不支持并行选项,13版本此命令新增-j选项,支持全库并行索引重建。
3.4、PostgreSQL 13: 新增ignore_invalid_pages参数
PostgreSQL 13 新增ignore_invalid_pages
参数用于控制数据库恢复过程中遇到坏块时是否绕过这个坏块继续进行数据库恢复,此参数默认值为off
。
早在 PostgreSQL 13 版本前 Developer Options已提供了zero_damaged_pages
参数,用于控制PostgreSQL数据库运行过程中遇到坏块数据时是否绕过这个坏块。
关于zero_damaged_pages
PostgreSQL当检测到受损的页面首部时会报错,并中止当前事务。将参数zero_damaged_pages
设置为on
,数据库将报WARNING
错误,并将内存中的页面抹为零。然而该操作会带来数据丢失,也就是说受损页上的所有数据全都丢失。不过,这样做确实能绕过错误并从未损坏的页面中获取表中未受损的行。当出现软件或硬件故障导致数据损坏时,该选项可用于恢复数据。通常情况下只有当放弃从受损的页面中恢复数据时,才应当使用该选项。本选项默认是关闭的,且只有超级用户才能修改。
关于ignore_invalid_pages
如果设置为off
,当在恢复过程中发现WAL记录引用了无效页面时,PostgreSQL引发严重错误,中止恢复。
如果设置为on
,当在恢复过程中发现WAL记录引用了无效页面时,PostgreSQL忽略这个严重错误(但仍然告警),并继续进行恢复,这种行为可能会导致崩溃、数据丢失、隐藏损坏或其他严重问题。当遇到这种情况时,应首先尽量尝试恢复已损坏的数据文件。
两个参数的异同
zero_damaged_pages
和ignore_invalid_pages
参数共同之处为以下:
都属于Developer Options参数,这种类型的参数是用来处理PostgreSQL源代码的,在postgresql.conf文件中已剔除,并且在某些情况下可以用于恢复严重受损的数据库,生产库原则上不应该使用这些参数,除非是紧急情况。
都是用于控制数据库遇到坏块场景时的处理方式。
两个参数的不同点为以下:
ignore_invalid_pages
参数用于数据库恢复过程中遇到坏块的场景,zero_damaged_pages
参数用于当数据库运行过程中遇到数据坏块的场景。只有当数据库处于
recovery mode
或standby mode
时,ignore_invalid_pages
参数才有效。
4、其它亮点
4.1、PostgreSQL 13: 日期格式新增对FF1-FF6的支持
2016 SQL标准
定义了FF1-FF6
时间格式,PostgreSQL 13 版本的日期格式中新增了对FF1-FF6
格式的支持,手册说明如下。
FF1-FF6
表示时间数据类型秒后的第一位到第六位,手册说明如下:
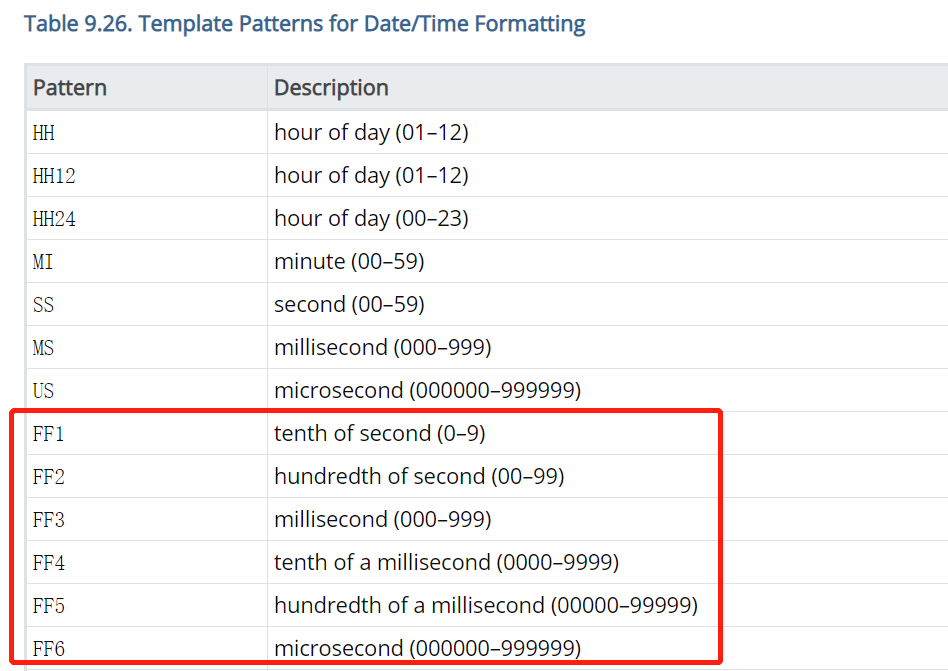
FF1: 秒的1/10
FF2: 秒的1/100
FF3: 秒的1/1000,毫秒
FF4: 毫秒的1/10
FF5: 毫秒的1/100
FF6: 毫秒的1/1000,微妙
下面通过示例说明。
举例说明
PostgreSQL 13 执行以下SQL,如下:
postgres=# SELECT now(), to_char(now(),'HH24:MI:SS.FF1'), to_char(now(),'HH24:MI:SS.FF2'), to_char(now(),'HH24:MI:SS.FF3'), to_char(now(),'HH24:MI:SS.FF4'), to_char(now(),'HH24:MI:SS.FF5'), to_char(now(),'HH24:MI:SS.FF6');now | to_char | to_char | to_char | to_char | to_char | to_char-------------------------------+------------+-------------+--------------+---------------+----------------+----------------- 2020-07-18 20:58:08.646871+08 | 20:58:08.6 | 20:58:08.64 | 20:58:08.646 | 20:58:08.6468 | 20:58:08.64687 | 20:58:08.646871(1 row)
从以上看出FF1-FF6
分别返回了秒后的第一位到第六位。
参考
PostgreSQL 13 Beta 1 Released!
E.1. Release 13
