




点击上方蓝字  关注大侠之运维
关注大侠之运维
后台回复99.99% 获取运维干货物
本文章适用于需要快速实践一套监控、告警的需求,按照文章内容操作,基本没有问题。
前提条件:服务器有doker环境,可以通外网
♦️
prometheus快速部署
文章中涉及密码或者路径需要根据自己的实际进行调整
prometheus部署,镜像拉取
docker pull prom/prometheus
配置文件准备:
mkdir -p opt/prometheusvim /opt/prometheus/conf/prometheus.yml
global:scrape_interval: 60sevaluation_interval: 60sscrape_configs:- job_name: prometheusstatic_configs:- targets: ['192.168.180.10:9001']labels:instance: prometheus- job_name: 'linux_base'file_sd_configs:- refresh_interval: 1mfiles:- config_exporter.json
vim config_exporter.json
[ {"targets" : ["192.168.180.1:9100"],"labels": {"env": "devops"}}]
服务启动:
docker run -d --name prometheus --restart=always -p 9090:9090 -v /opt/prometheus/conf:/etc/prometheus -v /etc/localtime:/etc/localtime prom/prometheus --config.file=/etc/prometheus/prometheus.yml --web.enable-lifecycle
起来后直接9090访问即可,可以查看target是否已经正常
♦️
grafana部署
快速部署两条命令解决,直接访问,关于node-exporter,可以直接找网上的模板
docker pull grafana/grafanadocker run -d -p 3000:3000 grafana/grafana
如下:
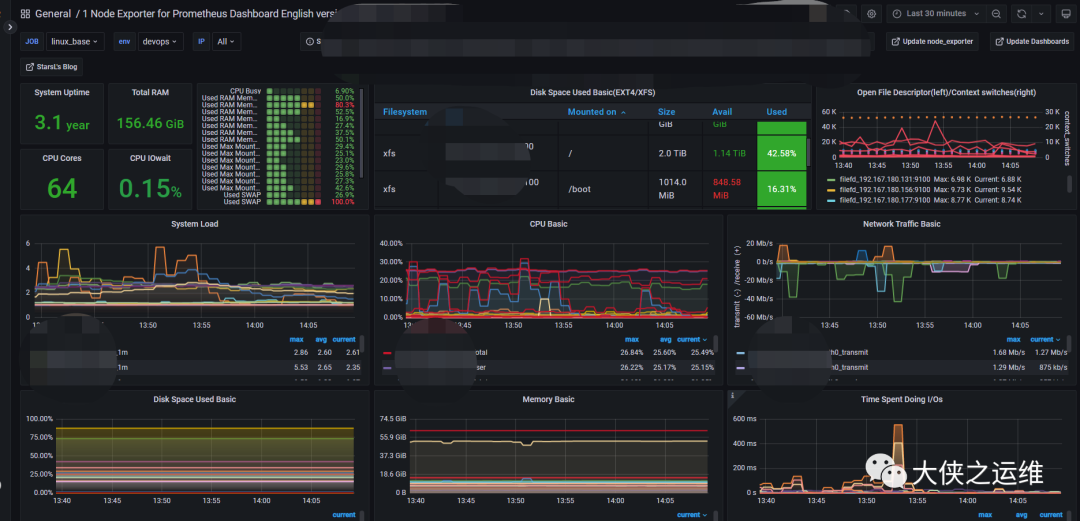
上述监控采集以及展示已经完成,我们告警没有使用alertmanager,使用夜莺+企微机器人来告警。
♦️
夜莺+企微机器人
关于这点,之前的文章中已经有介绍过了,可以到下文去看下:
夜莺V5+prometheus手把手教你使用企微机器人发送告警
效果如下:
级别状态: S1 Triggered规则标题: 磁盘使用率超过85%监控指标: [device=/dev/sda env=devops fstype=xfs instance=192.168.18.17:9100 job=linux_base mountpoint=/data]触发时间: 2022-09-23 09:50:37触发时值: 95.6621发送时间: 2022-09-23 09:50:37
告警恢复
级别状态: S1 Recovered规则标题: 磁盘使用率超过85%监控指标: [device=/dev/sda env=devops fstype=xfs instance=192.168.18.17:9100 job=linux_base mountpoint=/data]恢复时间:2022-09-23 09:54:07发送时间: 2022-09-23 09:54:07

👆点击查看更多内容👆
推荐阅读
记得星标记一下,下次更容易找到我

文章转载自大侠之运维,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
