点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!1.1 知识点描述
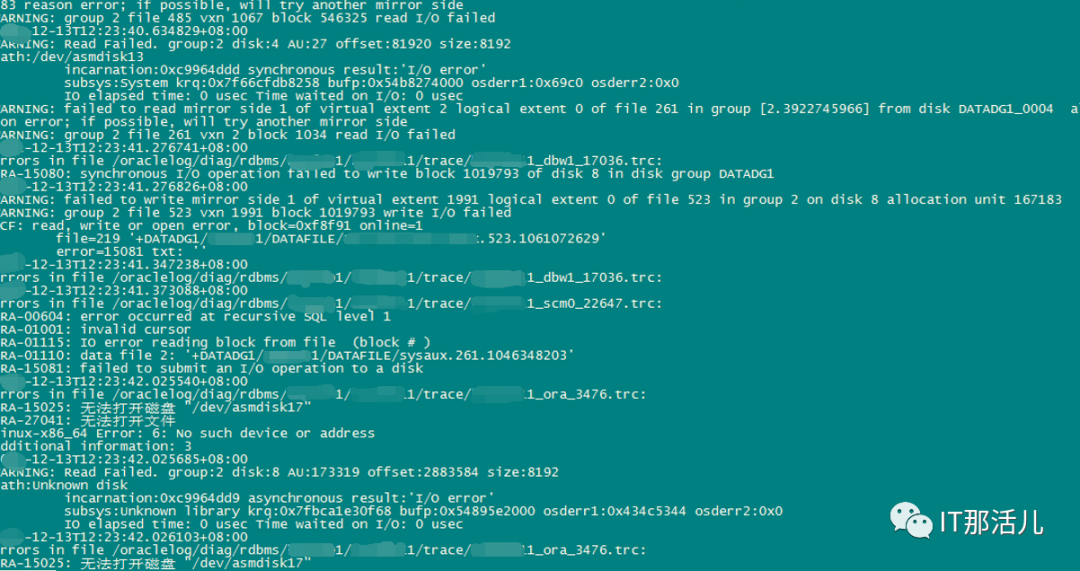
应用19.13PSU后,疑似触发数据库内存Bug 32940955以及BUG 33415279、BUG 33225584,导致数据库hang住。中午11:43收到告警,数据库节点1出现断连告警,立即登入系统进行检查,发现数据库整个hang住,两个节点实例均无法执行查询等操作。进一步检查数据库日志,发现频繁报ORA-04031错误。为了快速恢复业务,尝试进行杀会话,情况没有明显好转,12点15分经客户同意后停掉节点1的实例,随后实例2恢复正常,并重新拉起节点1实例。12:23左右,节点1再次出现严重性能问题,内存资源不足,alert日志出现IO ERROR:无法打开磁盘,导致无法进行IO读写,节点1发生实例重启,重启后,性能问题未解决。再次经客户同意后,在12点33分对节点1实例进行停止,随后节点2恢复正常,在12:45尝试手动拉起节点1实例,所有节点均恢复正常状态。在13:26手动拉起节点1监听,至此所有节点均恢复正常访问。
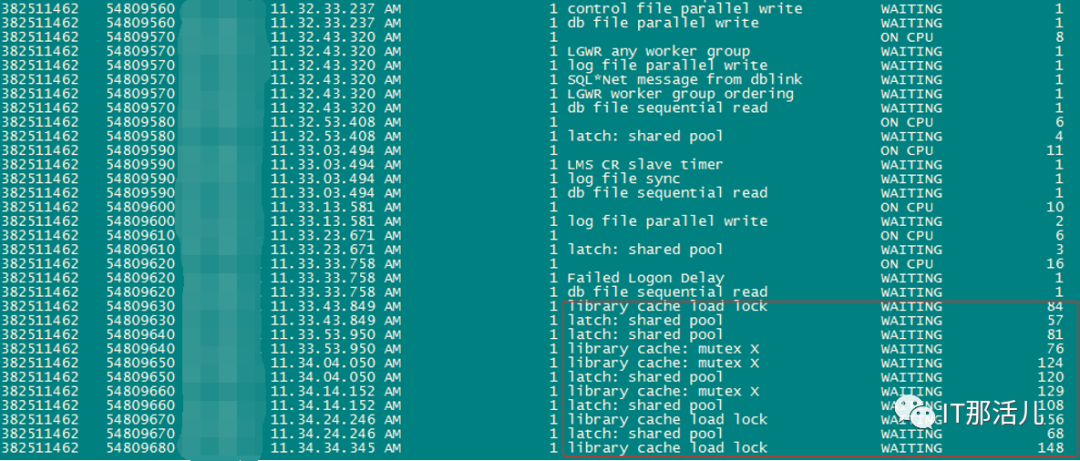
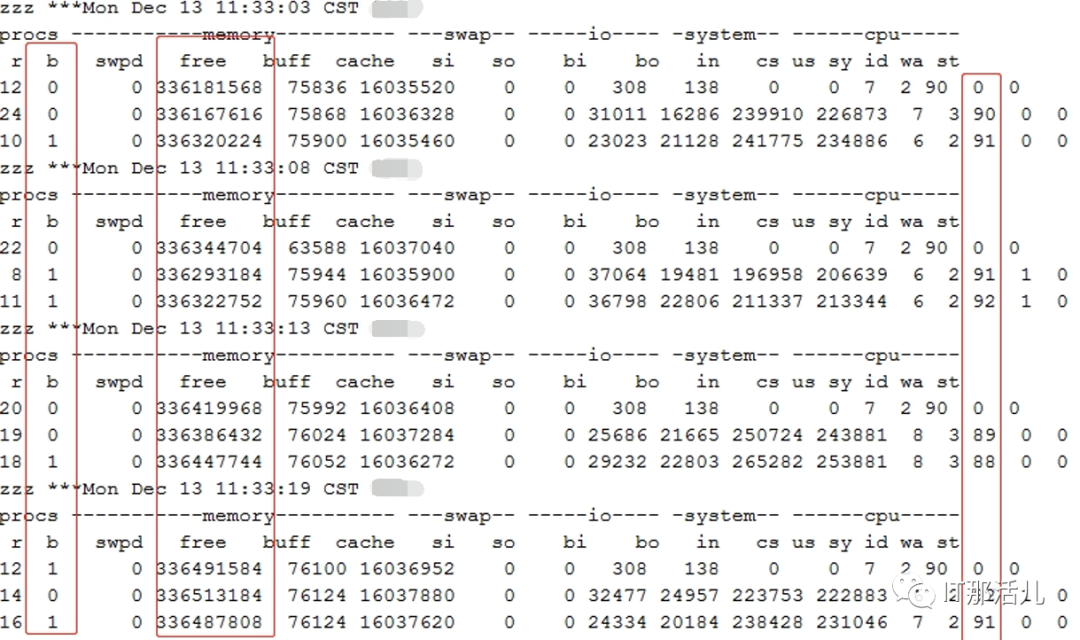
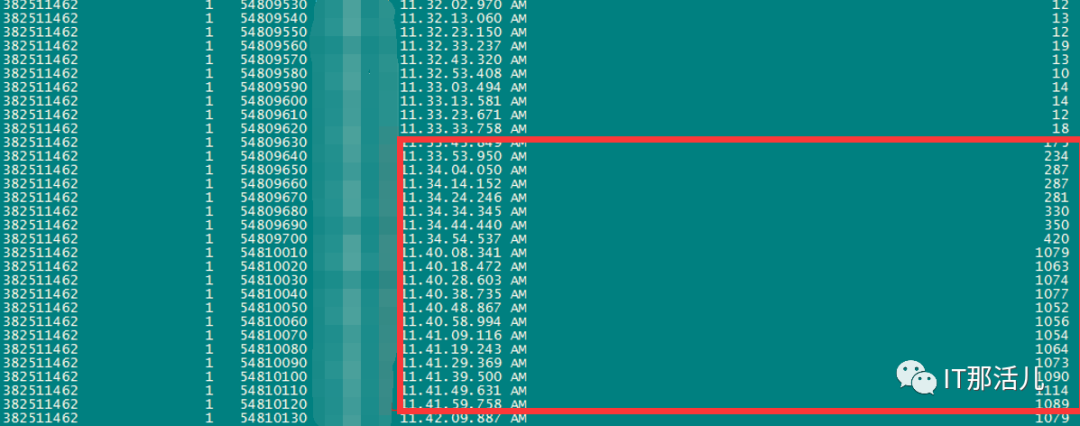
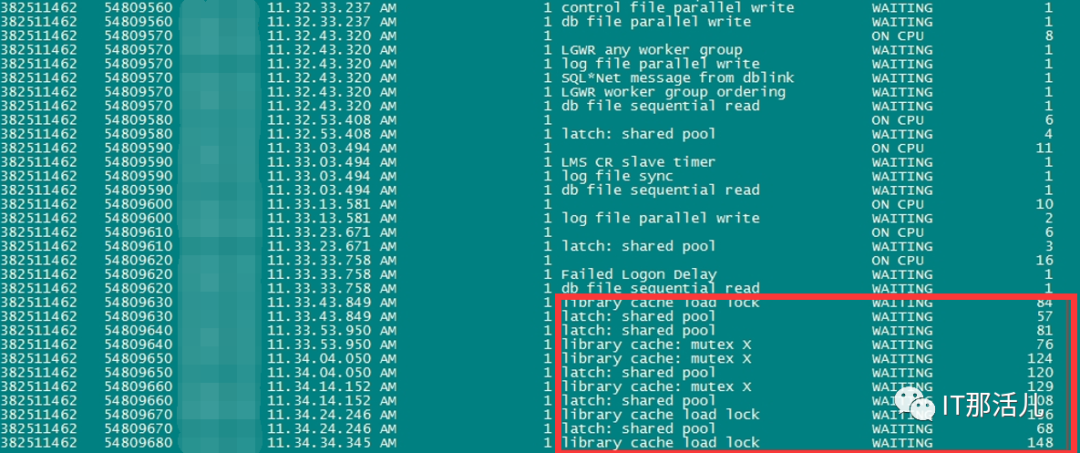
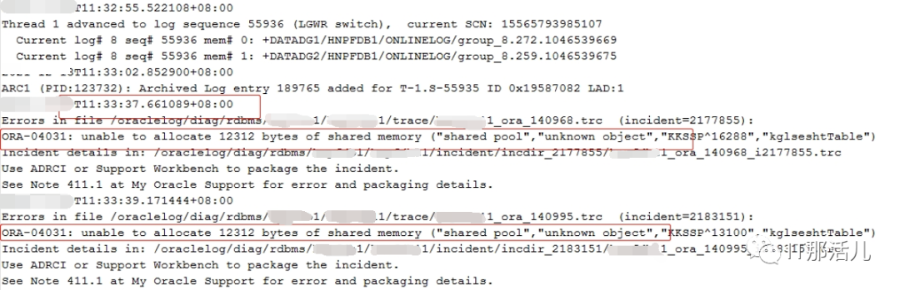
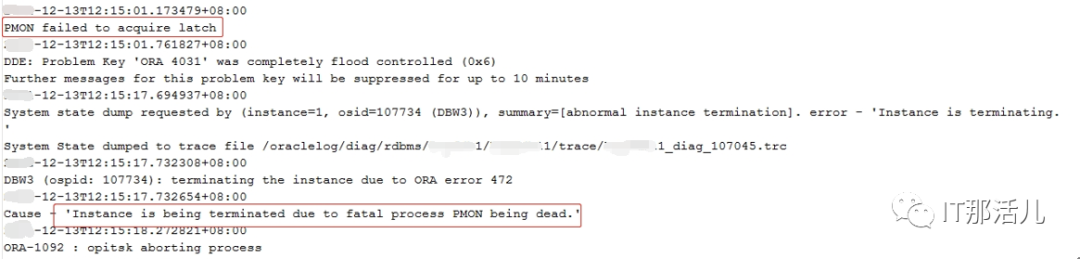
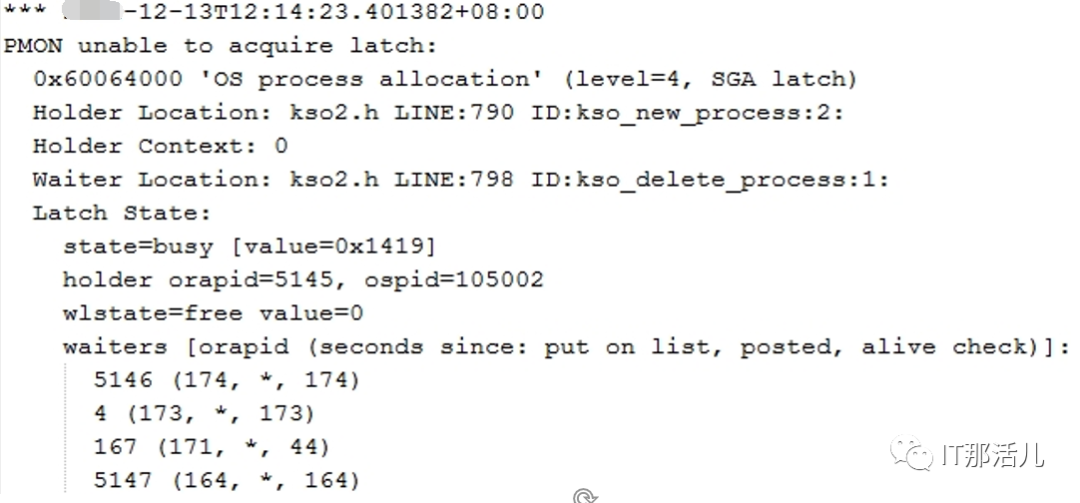
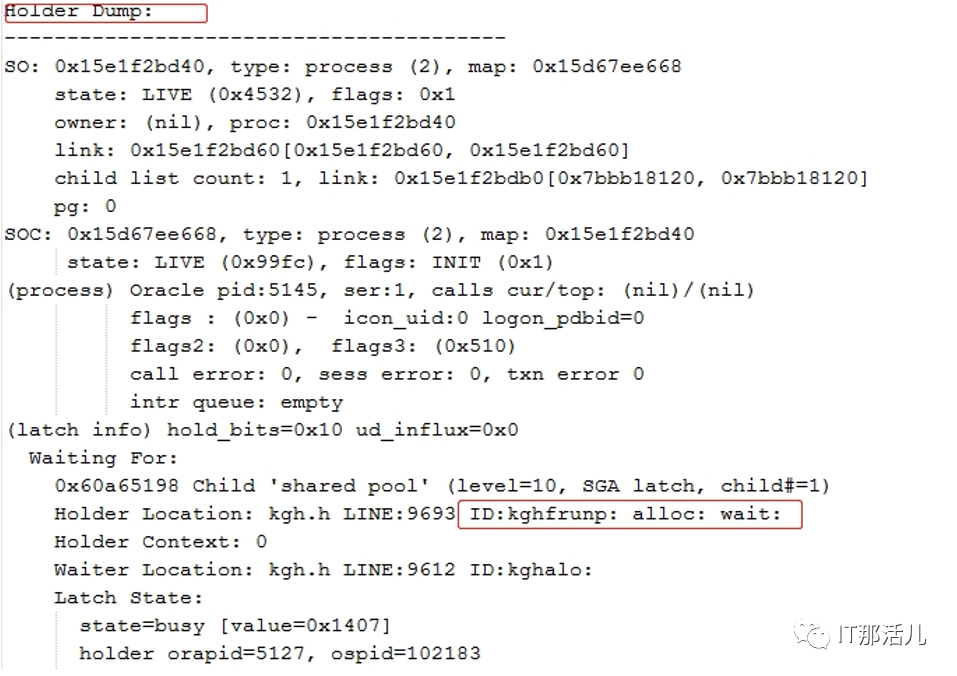
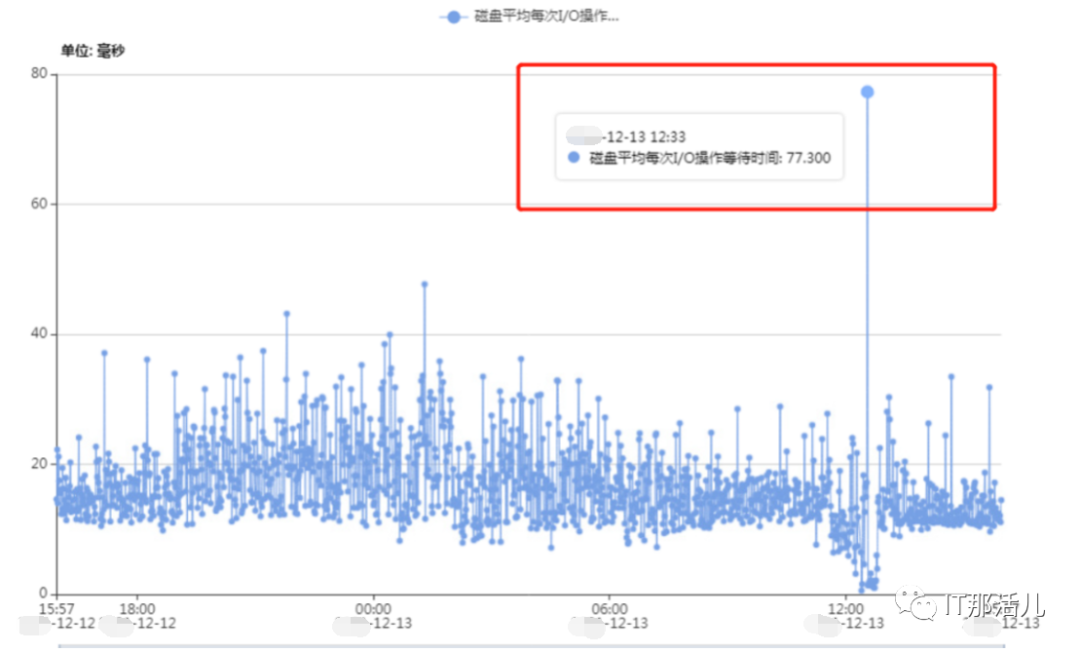
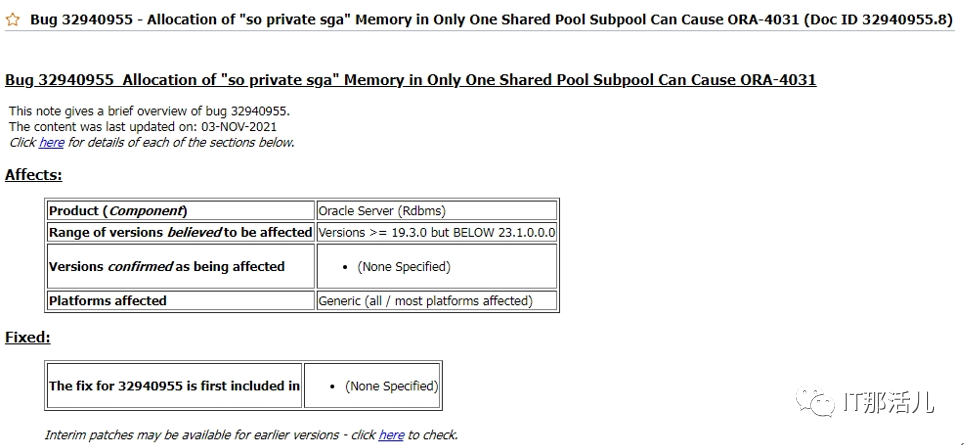
事后回溯分析,发现节点1 在11:33左右突然出现大量library cache相关等待事件:11:33左右开始连到数据库的应用会话数明显突增:查看等待事件发现主要是latch: shared pool等待事件:查看DB ALERT日志发现大量ORA-4031报错。继续查看db alert日志发现11:43:33开始pmon进程获取latch一直失败,12:15:17由于pmon进程挂死导致实例宕掉。查看pmon trace日志发现pmon一直在等待内存分配。检查12:23 alert日志出现IO ERROR:无法打开磁盘。12点33分左右,有严重的IO性能问题,经分析为内存资源耗尽导致IO性能严重下降。查询资料文档发现,应用19.13PSU后,疑似触发数据库内存Bug 32940955以及BUG 33415279、BUG 33225584。1)打patch 32940955,让"so private sga"分布到各个Sub Pool里去。2)打patch 33415279,避免"pga accounting"的内存泄漏。3)patch 33225584,解决了共享池内存释放的调用kghfrunp时超过1秒的 'latch: shared pool' 等待的问题。4)需设置如下2个隐含参数
- "_dlm_stats_collect"=0 :关闭DLM Statistics Collection功能以减少KJSC rnb slots内存组件对shared pool空间的占用。
- "_shared_pool_reserved_pct"=15 : 建议设置10%~15%之间,增大reserve pool的size,对于超过4.4KB的内存请求是有益处的。