




复制的基础
MySQL复制基础是SQL语句的逻辑复制。其中复制中对于执行的SQL语句进行验证,但对整个结构(表,数据库)等不会进行验证。
从目前自身提供的几种HA核心架构,可以知晓单台节点负载和性能,会影响Relay Log回放速度,如超过负载,延迟无可避免。
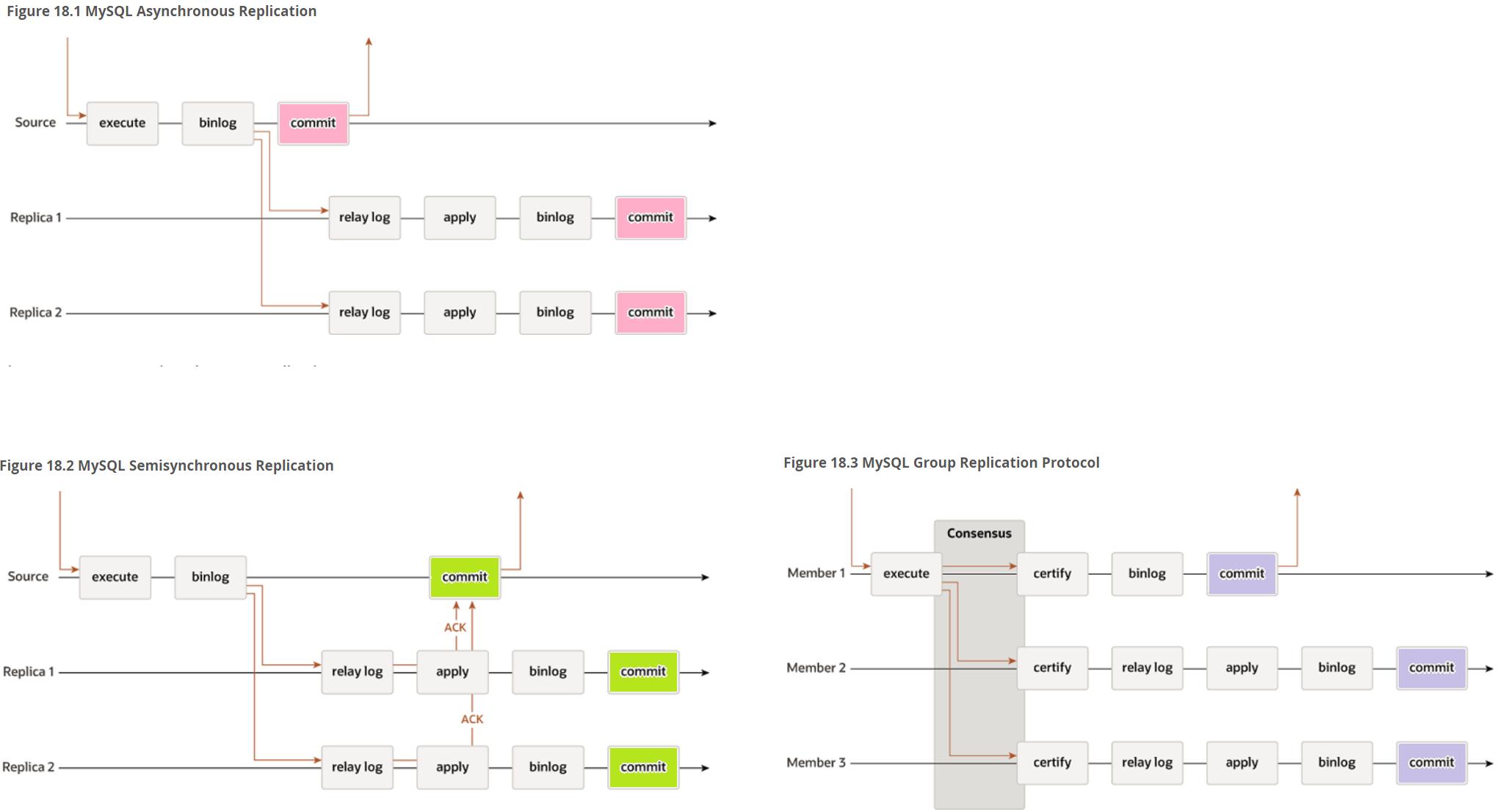
在这种情况下,当主从切换的时候,会存在数据不一致的情况,更严重的数据混乱情况。对于企业核心系统,数据不一致是非常致命的。
发生不一致情况
主从数据不一致可能是由多种因素造成的,常见的数据不一致,从目前了解的一些案例总结如下:
1.从库被写入数据
1、 这里分多种情况,常用的架构里因为前段应用访问的vip,因网络心跳问题,在主从节点上vip跳动,导致分别在两边都写入。通称脑裂现象。
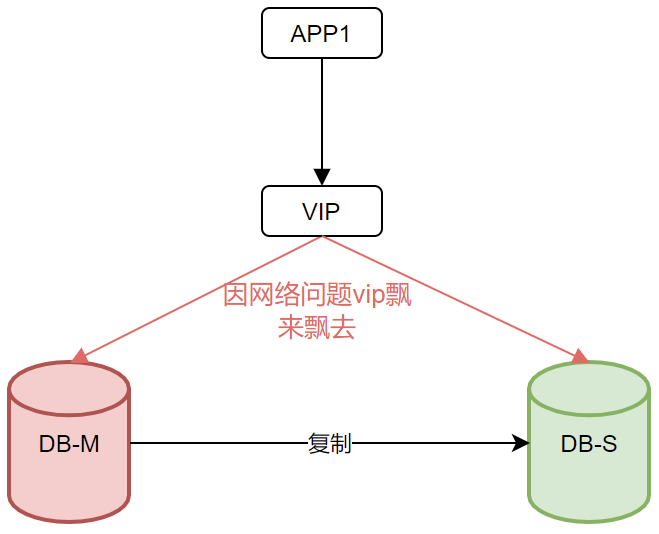
2、 双主情况下,为了保证负载,业务特性,双节点都在写,但因为复制进程断开或延迟存在,导致两个节点都写入同样的数据。复制破坏被迫停止,业务持续当中,这种情况破坏性越来越扩大。
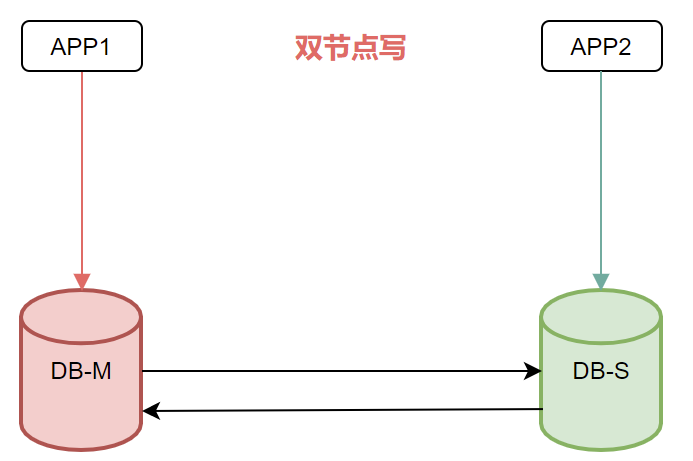
3、 从库人为做了操作:误链接从节点进行操作.
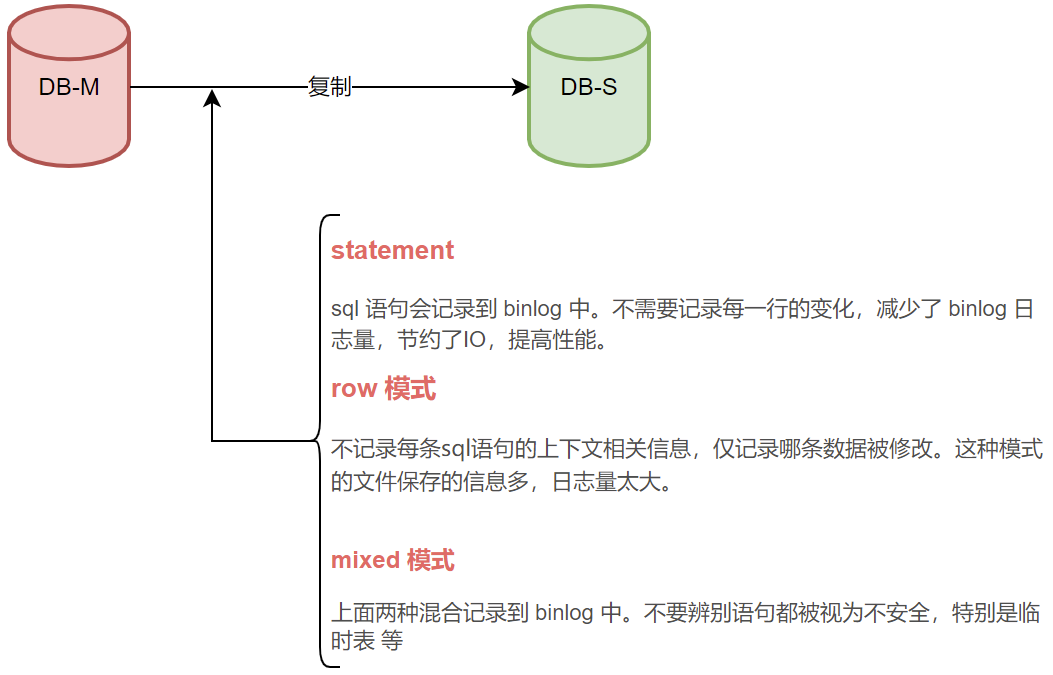
2.binlog非row格式
binlog三种模式,不管statement模式 还是mixed模式都有可能会用sql语句方式,把不应该操作的数据进行更改。最终数据不一致。
3.存储过程 或 触发器
存储过程或 触发器 因为本地调用的特有特性,有可能导致数据不一样结果。特别是时间和自增字段。
auto increment ,datetime ,timestamp
4.sql_mode不一致
因为模式不同,对数据的处理不一样。典型的STRICT_TRANS_TABLES严谨模式,进行数据的严格校验,错误数据不能插入。当模式不一样下数据会被截断,最终就会存在不一致问题。
mysql> CREATE TABLE `t1` (
`id` int NOT NULL,
`name` varchar(10) ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
Query OK, 0 rows affected (0.01 sec)
mysql> show variables like '%sql_mode%';
+---------------+-----------------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+-----------------------------------------------------------------------------------------------------------------------+
| sql_mode | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION |
+---------------+-----------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
mysql> set sql_mode="";
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t1(id,name) values(1,"hello beijing nice to meet you");
Query OK, 1 row affected, 1 warning (0.00 sec)
mysql> select * from t1;
+----+------------+
| id | name |
+----+------------+
| 1 | hello beij |
+----+------------+
1 row in set (0.00 sec)
5.复制跳过
slave_skip_error, sql_slave_skip_counter和gtid_next方式,跳过事务,就说明对应事务,没有在从库执行,这些复制跳过方式运行当中需要谨慎操作。
1、sql_slave_skip_counter :传统position模式下,跳过当前时间来自于master的之后N个事件,这对于恢复由某条SQL语句引起的从库复制有效。

2、gtid_next跳过方式;
在碰到一些gtid事务冲突的时候,手动处理跳过事务,gtid信息和事务编号一定要精准。
Gtid_next可以接受以下任何值:
| 字段 | 说明 |
|---|---|
| AUTOMATIC | 使用下一个自动生成的全局事务ID。 |
| ANONYMOUS | 事务没有全局标识符,仅通过文件和位置进行标识。 |
| UUID | NUMBER格式的全局事务ID。 |

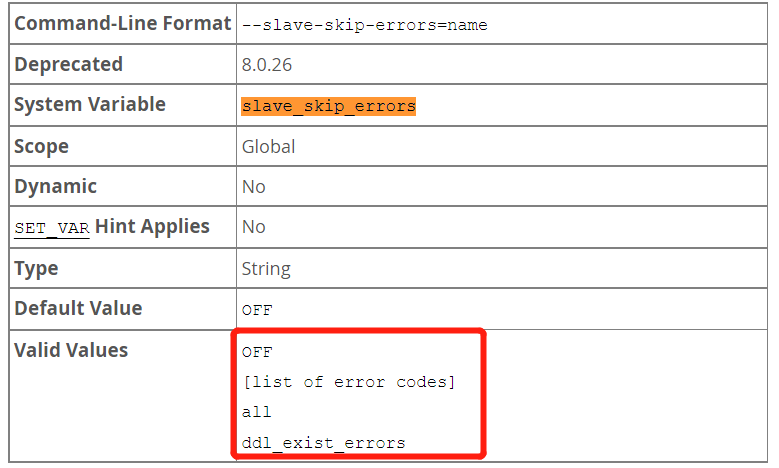
3、slave_skip_error 应对复制SQL thread线程回放语句进行跳过。
复制SQL线程在语句返回选项值中列出的任何错误时,跳过,继续复制。这是保证复制不断,但丢失数据一致性。
slave_skip_errors选项有四个可用值,分别为:off、all、ErorCode、ddl_exist_errors。
如下配置:
主从库同步错误:
1062 Error ‘Duplicate entry ‘1438019’ for key ‘PRIMARY’’ on query;
1032 Error Can’t find record in ‘table’;
1053 Error:复制过程中主服务器宕机
[mysqld]
slave_skip_errors=1062,1053,1032
备注:
因NDB集群之间复制时不以相同的方式工作(epoch序列号,一旦丢失或打乱了顺序,会立即停止复制应用程序线程)。从NDB 8.0.28开始,提供忽略跳过的epoch事务,可以通过同时指定NDB-application-allow-skip-epoch和——slave-skip-errors;
6.双1设置
MySQL日志体系中存在服务器日志和引擎层日志,写入底层文件,控制参数为sync_binlog,innodb_flush_log_at_trx_commit。其中innodb_flush_log_at_trx_commit是将事务日志从innodb log buffer写入到redo log中,sync_binlog是将二进制日志文件刷新到磁盘上binlog。
不是双1的情况下,mysqld服务崩溃或者服务器主机crash的情况下,很有可能出现binlog或者relaylog文件出现损坏,导致主从不一致。
7.半同步机制
在开启半同步复制下,不合理的参数设置,会导致数据不一致的风险。
主要核心参数rpl_semi_sync_master_wait_point有两个值after_commit是MySQL5.6半同步参数,after_sync是MySQL5.7参数,用以解决MySQL5.6半同步缺陷的选项。
区别于是在从库接收ack确认以后主库在引擎层做提交(after_sync),而after commit是先在引擎层做提交后等待ACK确认。因此,在写入数据后并且在从库确认之前,其他的客户端可以看到在这一事务。
mysqld服务崩溃或者服务器主机crash的情况下,要不丢失,要不回滚,可能会导致主从不一致。
8.ignore/do/rewrite等replication等规则**
过滤复制源数据,常见的问题出现在不同schema下跨schema操作。
如:复制数据库如db1,但在db2中进行 db1.table的更改,这样从库就不会回放这条SQL语句。
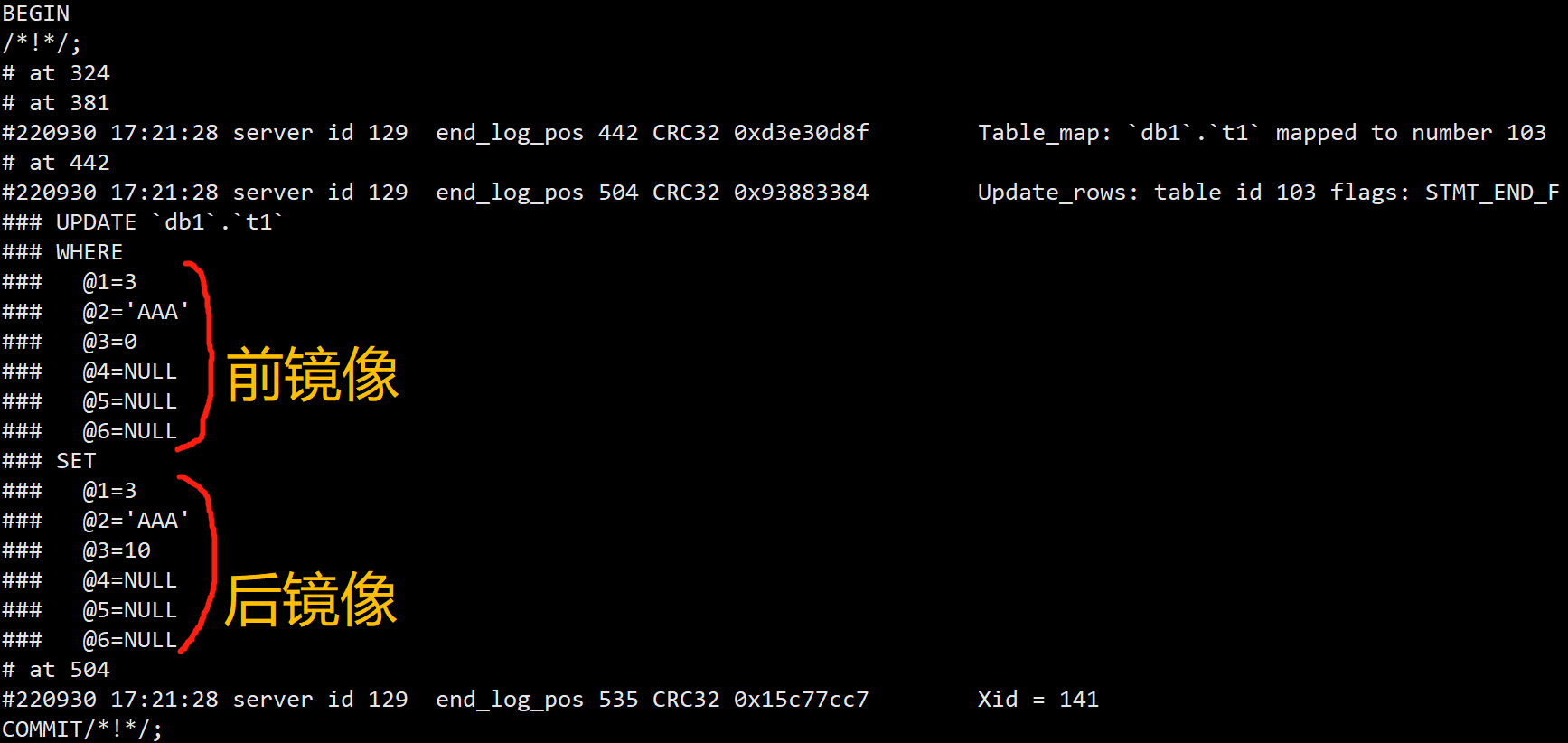
9.binlog_row_image记录内容
binlog_row_image参数可以设置三个值: FULL、MINIMAL、NOBLOB。不同的设置binlog记录数据不一样。
前镜像:数据库表中修改前的内容
后镜像:数据库表中修改后的内容
| 值 | 说明 |
|---|---|
| full | 表无论有没有主键约束或者唯一约束binlog都会记录所有前后镜像; |
| minimal | 如果表有主键或唯一索引,前镜像只保留主键列,后镜像只保留修改列;如果表没有主键或唯一索引,前镜像全保留,后镜像只保留修改列; |
| noblob | text/blob列;如表有主键或唯一索引,前后镜像忽略text/blob列。如果表没有主键或唯一索引,前后镜像全保留;如果表没有主键或唯一索引,修改列不是text/blob列,前镜像全保留,后镜像忽略text/blob列。 |
10.sql_log_bin参数
sql_log_bin是一个动态变量,开启参数之后更改操作不写入binlog。对于数据更改,就不能使用这个参数。不写入binlog就无法同步到从节点。
如下述操作 就不会记录binlog,数据将不同步:
mysql> SET @@SESSION.SQL_LOG_BIN= 0;
Query OK, 0 rows affected (0.00 sec)
mysql> update t1 set age=10 where id =4;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SET @@SESSION.SQL_LOG_BIN= 1;
11.表结构不一致
为了一些特许需求,有时主从结构不一致,比如从库设置主键,唯一键,多余的字段,字段类型 或 默认值等。
数据本身不一致,可能会导致未知的问题。
12.外键约束
foreign_key_checks 参数导致,从库SQL回放的时候,没有验证外键值。
13.备份一致性丢失
因备份是参数(如:逻辑备份mysqldump参数 single-transaction和master-data )和 开源备份软件xtrabackup 导致最终一致性丢失。这样搭建出来的复制节点,本身就存在问题。
14.版本不一致
特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面不支持该功能。
15.自身bug
mysql本身的bug引起的主从不同步。
比如:碰到的现象是Slave_IO_Running,Slave_SQL_Running进程Yes状态,但实际复制进程穷住。
应对不一致
虽然目前国内MySQL使用已经非常普遍,但还是会碰到数据不一致问题。这些不一致问题,如上述描述中的一条件 或 多种组合。对于发生不一致问题,要及时发现,要及时修复,要初期避免。
避免不一致:
- 多节点写入, 业务要合理设计,不应该存在冲突;
- slave_skip_error参数绝对不可用,如特殊情况应急可以;
- innodb_flush_log_at_trx_commit,sync_binlog 双1数据安全性保障;
- 设置从库为只读模式,不可操作;
- 增强半同步避免数据丢失采取after_sync模式;
- binlog强烈建议设置为row格式;binlog_row_image 为FULL模式;
- 复制存在延迟时,把从库提升为主库,有可能存在数据不一致情况;
- 过滤复制源数据,不得跨schema操作;
- 存储过程&触发器使用不要依赖一些特性的字段,尽量不使用;
- sql_mode必须采取严谨模式;
- 主从表结构必须一致;
- 备份恢复搭建从库,一致性要保证;
发现不一致
发现问题,需要做好监控,还需定期进行主从一致性检验。
不一致的修复
1、将从库重新搭建
恢复时间比较慢,而且有时候从库也是承担一部分的查询操作的,不能贸然重建。但发生数据不一致,不要觉得麻烦,就选择手动修复,建议还是重新搭建
2、使用percona-toolkit工具辅助
PT工具包中包含pt-table-checksum和pt-table-sync两个工具,主要用于检测主从是否一致以及修复数据不一致情况。修复速度快,不需要停止主从辅助
3、手动修复不一致的表或数据
执行期间需要暂时停止从库复制,按照不一致的提示信息,手动修复。
除了上诉这些,做好日常备份。当所有手段无用的,通过备份恢复,修复不一致数据。
