




Table of Contents
一. 需求
我们需要爬取豆瓣top 250的电影进行分析。
二. 解决方案
使用python的request和re模块可以爬取数据
2.1 小小的反扒
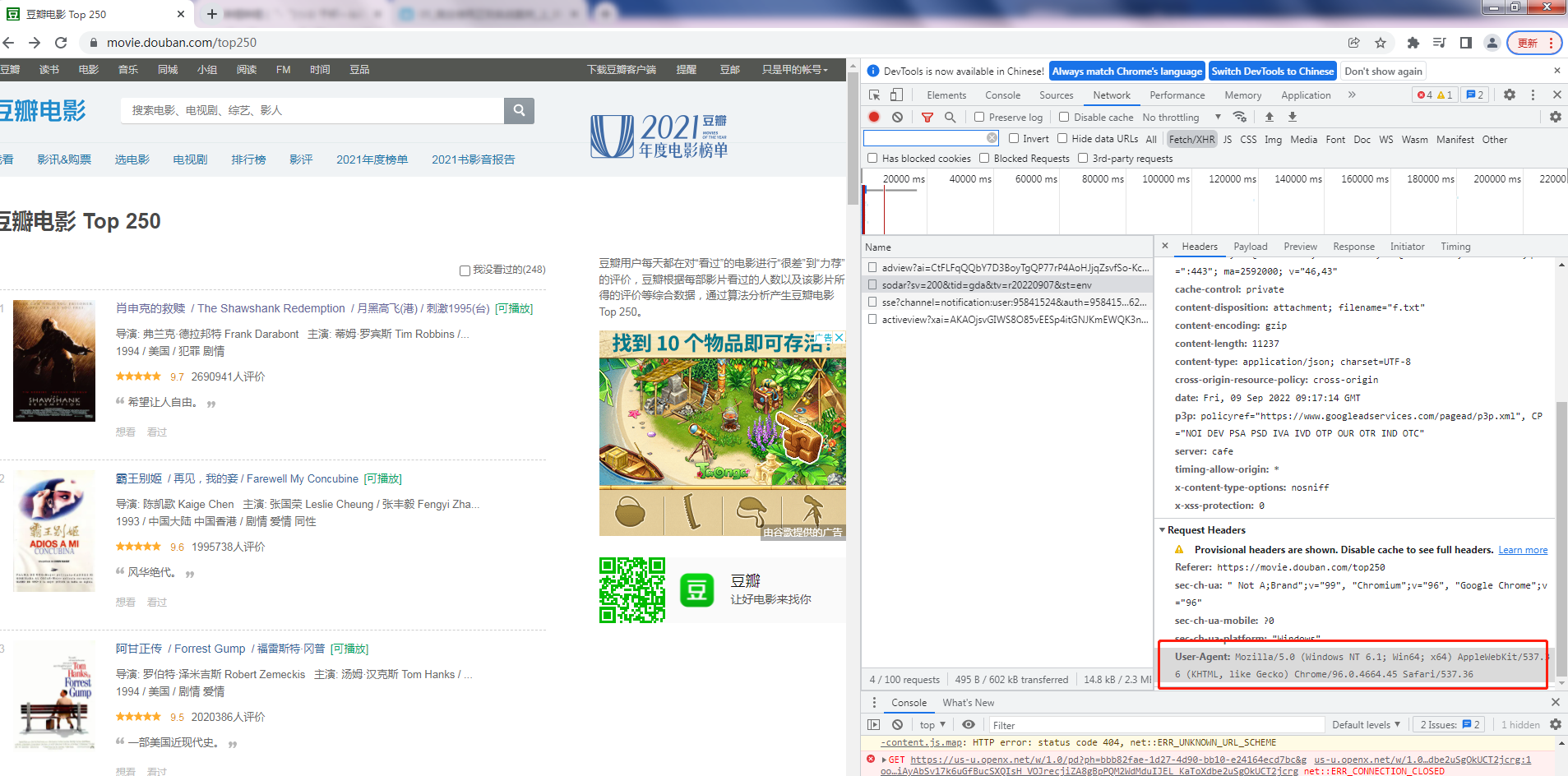
豆瓣有一个小小的反爬技巧,禁止虚拟设备的爬取数据,所以我们打开我们的浏览器,找到 User Agent,如下图所示。
2.2 查看源码
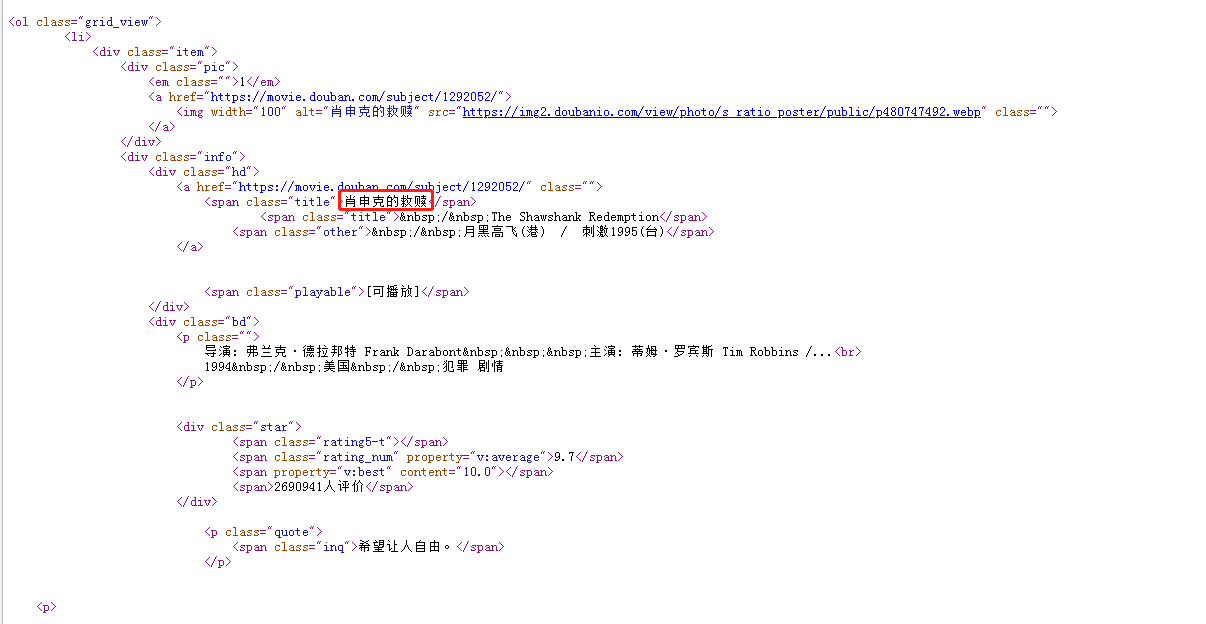
查看网页源码,然后找到《肖申克的救赎》,我们可以大概知道数据是怎么展示的。
2.3 编写代码
代码:
import requests
import re
def get_movie_data(url):
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
# 处理一个小小的反爬
resp = requests.get(url, headers=head)
resp.encoding = 'utf-8'
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" '
r'property="v:average">(?P<score>.*?)</span>.*? '
r'<span>(?P<num>.*?)人评价</span>', re.S)
result = obj.finditer(resp.text)
for item in result:
dic = item.groupdict()
dic['year'] = dic['year'].strip()
print(dic)
if __name__ == '__main__':
for i in range(1, 11):
page = (i - 1) * 25
if i == 1:
url = "https://movie.douban.com/top250"
get_movie_data(url)
else:
url = f"https://movie.douban.com/top250?start={page}&filter="
get_movie_data(url)
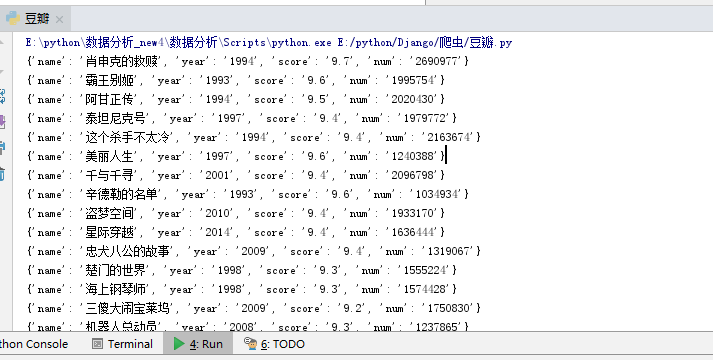
测试记录:
参考:
- https://www.bilibili.com/video/BV1wa41197X9
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
