




分享嘉宾:代野
SphereEx 解决方案专家,ShardingSphere Contributor、OCM、RHCE
整理:墨天轮
导读
而今,越来越多的国产数据库解决方案以分布式为支点,逐渐在此领域有所建树。Apache ShardingSphere 是其中的一个分布式数据库解决方案,也是目前 Apache 软件基金会中唯一的数据库中间件顶级项目。 【墨天轮数据库沙龙-中间件专场】邀请到SphereEx 解决方案专家代野,为大家带来《Apache ShardingSphere:从中间件到分布式生态演进之路》主题分享,以下为演讲实录。

代野
SphereEx 解决方案专家,ShardingSphere Contributor、OCM、RHCE
印象中间件
1、中间件的印象
中间件是什么?我搜集了大家对于中间件的常见印象标签,它们是否和你心中所想相匹配?

图1 中间件的常见标签
第一个标签是“分库分表”,一提到数据库中间件,有朋友会认为数据库中间件是做分库分表的,这也是选型阶段,长期与分布式数据库pk的方案。第二个标签是“Sharding”,即分库分表的另一种说法。在部分材料中提到分库分表方案会“对业务有入侵”,但这主要取决于业务情况。随着分布式数据库快速发展,这几年也有人把中间件的架构称为“过时架构”。除此之外,“互联网”也是数据库中间件的标签之一,Web 2.0的蓬勃发展给传统集中数据库带来扩展的能力。不仅如此,还有从产品角度对中间件定义标签:例如Cobar、Vitess、Mycat等等。
大家对于中间件有不同的印象与理解,不同的特色也是它的价值所在。在我看来,给下游数据库赋能,给上游应用程序提供更好的体验,都可以称之为数据库中间件。
2、分布式数据库分类
分布式数据库的解决方案是中间件应用最多的场景。2022年7月,国家工信信息安全发展研究中心发布了《分布式数据库发展趋势研究报告》。报告中提出,当前处在数据量增速非常大的阶段,传统数据库表现出了明显的瓶颈,很多用户会考虑向分布式数据库架构去靠拢,以解决计算以及存储瓶颈的问题。报告中把分布式数据库分为了三种路线:
-
分布式中间件+单机数据库。 这种路线是在单机数据库系统上进行改造,主要解决了计算和存储的扩展性的问题。按照两层来看,上一层分为无状态的计算节点,基于分片规则,提供SQL解析,具有请求转发和结果归并等能力。下一层为DBA所熟悉的单机数据库,提供单机数据库的存储和执行能力。这一层架构可以在逻辑层对数据进行切割,几乎是可以线性的提供计算和存储能力的扩展,达到规模化的扩展能力。
-
非对称计算节点+分布式存储。 它采用非对称节点解决扩展性问题。跨地域的数据一致性主要依赖于分布式的存储,共享存储还能够跨多个节点提供读写。上层计算的部分由无状态的一组节点来组成,当写节点出现故障,它会自动从可以读的节点中选举出一个节点作为写的节点,实现写能力的高可用。
-
原生分布式数据库。 它的各个节点提供对等的读写服务。这条路线是根据分布式一致性做底层设计,它和传统的数据库有本质性的区别。原生分布数据库可以将分布式存储、事务包括计算能力实现紧密结合。数据是由系统自动打散并存储为多个副本,通过一致性的协议保证多个副本以及事务之间实现一致性,对分布式事务和全局MVCC的支持更为彻底。
以上三种路线各自有哪些优势和不足,大家可以参考下图。
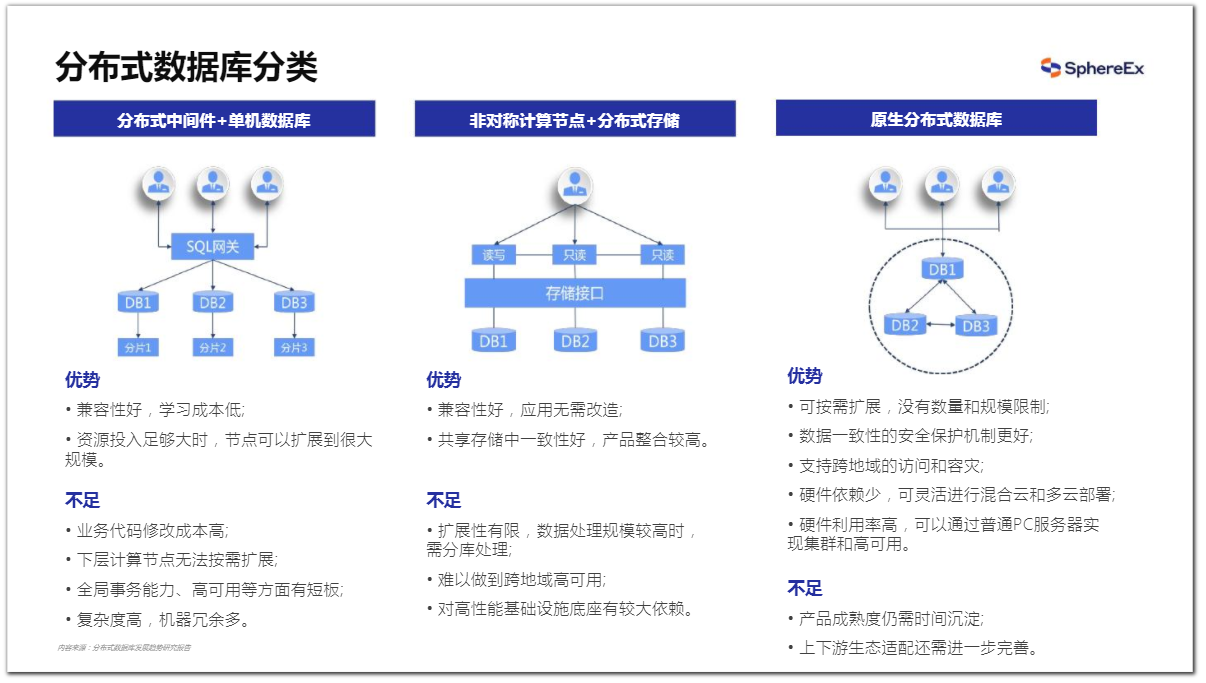
图2 《报告》对于三种路线的优劣势对比
中间件技术趋势
1、行业现状与趋势
随着各类业务的数据体量越来越大以及场景逐渐细化,数据库技术栈以及DBA路线也呈现出了多样性的发展。当前我们正处在一个数据库碎片化的趋势中,传统数据库管理、应用挑战严峻,催生数据库上层生态标准转型。架构选型困难、技术挑战众多、运维复杂度高、数据库间缺乏协作能力都是问题与挑战。

图3 数据库碎片化下的痛点与挑战
2、最优解:统一的数据平台中间件
基于以上提到的痛点,我们能否通过统一的数据平台来解决?基于数据库中间件的统一数据平台便是企业大数据时代的最优解。
在国产化进程中,业务系统对数据库有着很多的需求:基于现有单机数据库如何构建出一个分布式解决方案?如何能够实现可观察性?如何保证数据安全?如何满足不定期的由于业务变化而产生新的需求?这些需求其实在业务中来实现,只是需要不断地重构,也就是重复“造轮子”。那么将这些需求放入数据库中实现,难度更较高,尤其在协作方面,例如MySQL无法管理PG,反之PG也无法管理MySQL。
中间件架构则能够相对容易满足这些需求,它既开放又稳定,它不会颠覆数据库,反而是做更多的增强和连接。因此中间件相较于分布式数据库,并不是一个PK的概念,而是其在上层做增强。
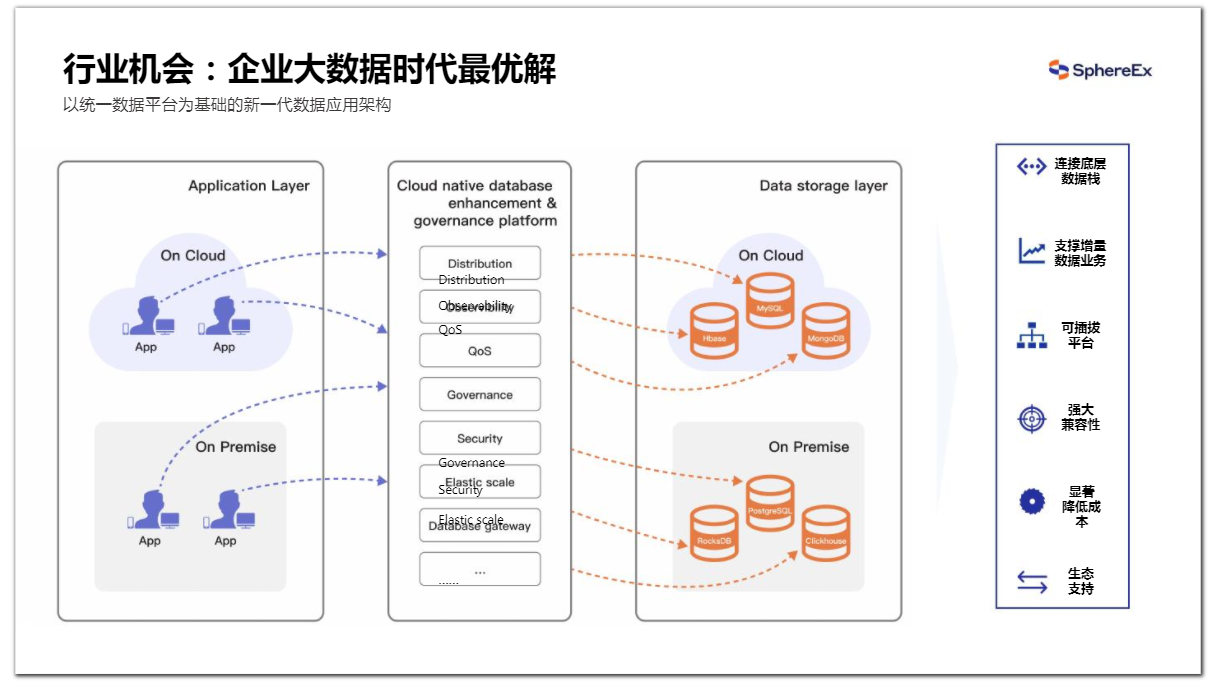
图4 中间件架构满足不同的业务需求
开源生态
1、SphereEx 及产品发展历程
墨天轮社区中间中间件流行度排行榜中,Sharding-JDBC排在第二位,在数据库中间件中位于第一。其次是 ShardingSphere、SphereEx 、Sharding-Proxy以及Sharding-Sidecar 。
ShardingSphere是开源项目的名称,其中包括Sharding-JDBC的接入端和Sharding-Proxy接入端。Sharding-Sidecar定为是云原生数据库代理,是曾经规划的接入端。SphereEx是Apache ShardingSphere核心团队创立的公司,基于ShardingSphere内核为企业提供新一代分布式数据计算增强平台。
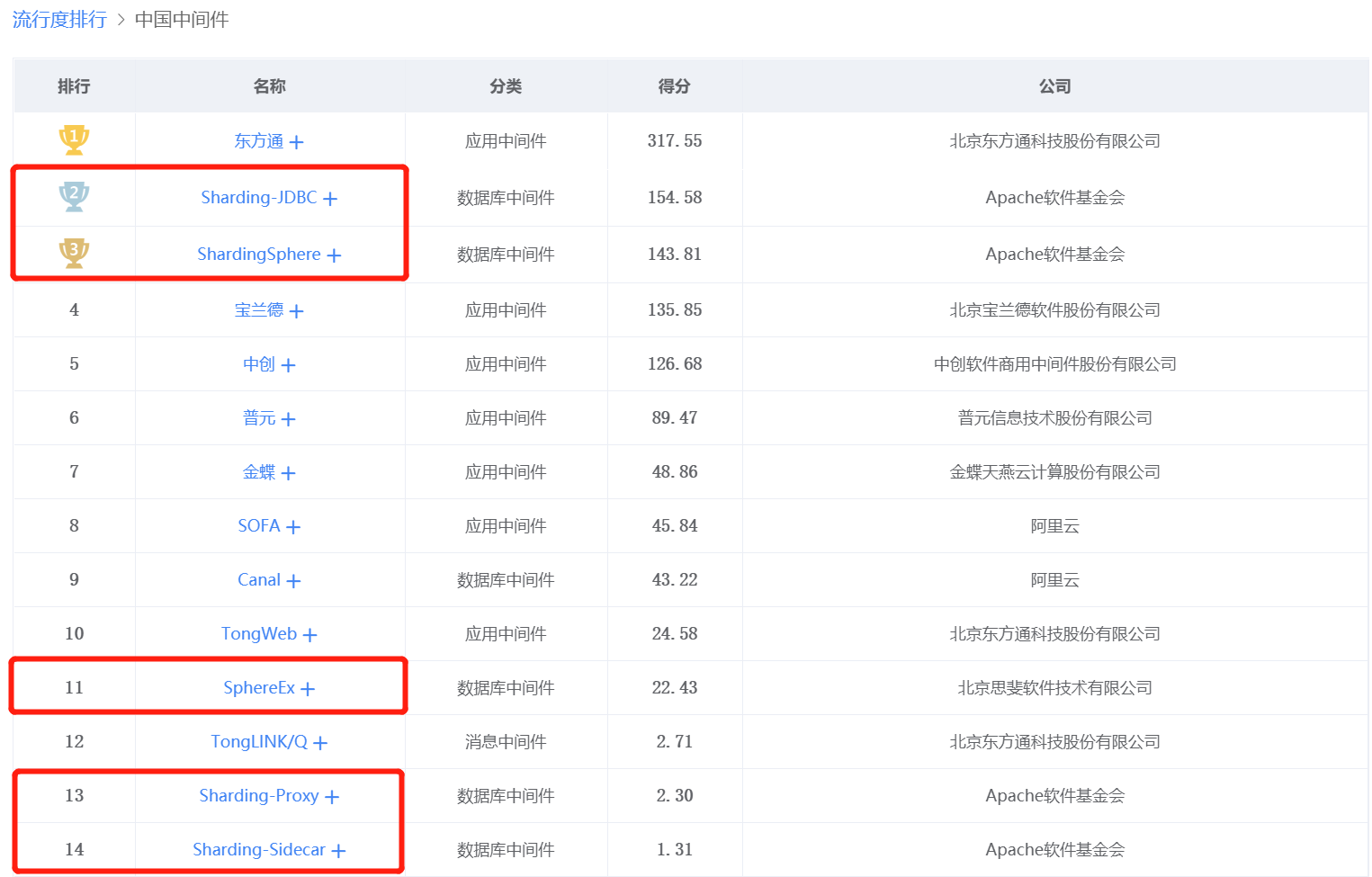
图5 SphereEx 及产品在中国中间件流行度中的排名
ShardingSphere最初的名字为Sharding-JDBC,这也是很多朋友习惯称它为Sharding-JDBC的原因。2015年在当当网上写下了ShardingSphere的第一行代码,它是为解决电商场景下分库分表的问题而诞生的一个组件。2016年Sharding-JDBC正式开源,2018年项目发生了较大的变化,在JDBC基础之上,推出了基于服务端的Proxy接入形态,项目也更名为 ShardingSphere。同年,它进入了Apache的孵化器。2020年,ShardingSphere项目毕业,成为了Apache顶级项目。2021年,SphereEx公司成立。
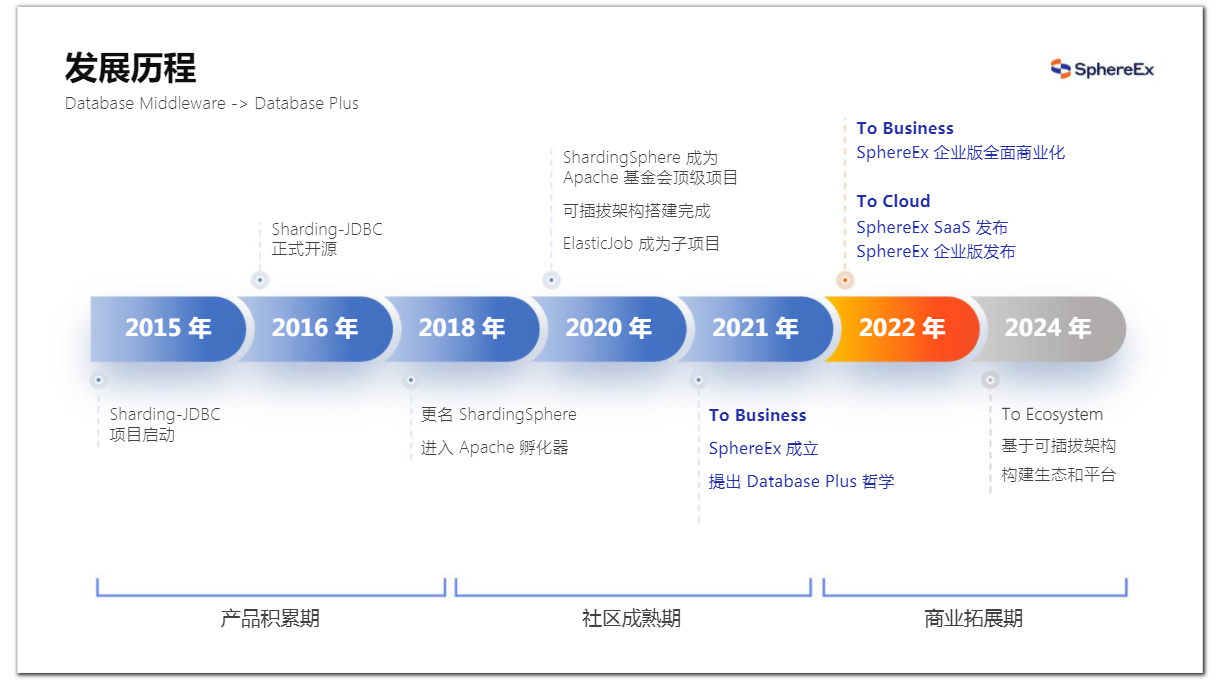
图6 ShardingSphere 发展历程
2、开源生态建设
作为Apache软件基金会的顶级项目,ShardingSphere在2021年代码提交量是整个基金会的Top 10,目前社区已经有400多位贡献者。
ShardingSphere项目在学术上表现不俗。今年上半年,在数据库三大顶会之一的ICDE发布了论文《A Holistic and Pluggable Platform for Data Sharding》。近期,我们在海外出版了《Apache ShardingSphere权威指南》。ShardingSphere也被收录至CNCF基金会中。生态建设方面,2022 年上半年,中国信通院联合Apache ShardingSphere 成立了金融用户社区,在快速发展中倾听更多金融用户的声音。

图7 开源项目概览
产品&解决方案
1、ShardingSphere设计哲学:Database Plus
首先,我将介绍一下ShardingSphere的设计哲学 —— Database Plus。它是一种分布式数据库系统的设计理念,旨在碎片化的异构数据库上层构建标准和生态,在最大限度地复用数据库原生存算能力的前提下,进一步提供面向全局的扩展和叠加计算能力,使应用和数据库间的交互面向 Database Plus 构建的标准,从而屏蔽数据库碎片化对上层业务带来的差异化影响。Database Plus具有连接、增强、可插拔三个特点:
-
连接。 我们希望通过这一层可以连接更多的数据库,比如在国产化替换过程中,能通过双引擎能力同时连接Oracle和信创库,实现数据库的双轨运行。然后通过中间层再逐步地切流,确保置换过程相对无感、无缝、低风险。
-
增强。 我们希望能够在各种数据库之上提供比如分布式的能力、加密等等这种增强的能力。
-
可插拔。 随着连接和增强能力不断的提升,中间的一层一定是越来越大。我们希望在扩展过程中能够做到可扩展、可收敛,保证中间层小而美、轻量化。
2、 ShardingSphere产品设计
根据 Database Plus 理念的指导,这部分将介绍工程化实现。
内核层中可见分布式相关的能力,功能层如数据分片、数据加密、弹性扩容、数据迁移等能力,对应的商业化产品为SphereEx-DBPlusEngine,即数据库增强引擎。下图左侧展现了可提供数据库的管理能力,通过中间件的平台层基于成熟单机产品构建出多种方案,为国产化替代做准备;协议上已实现MySQL和PG支持,此外还可与兼容MySQL和PG协议的国产数据库直接对接;语法方面,在Oracle、SQL Server可以兼容。
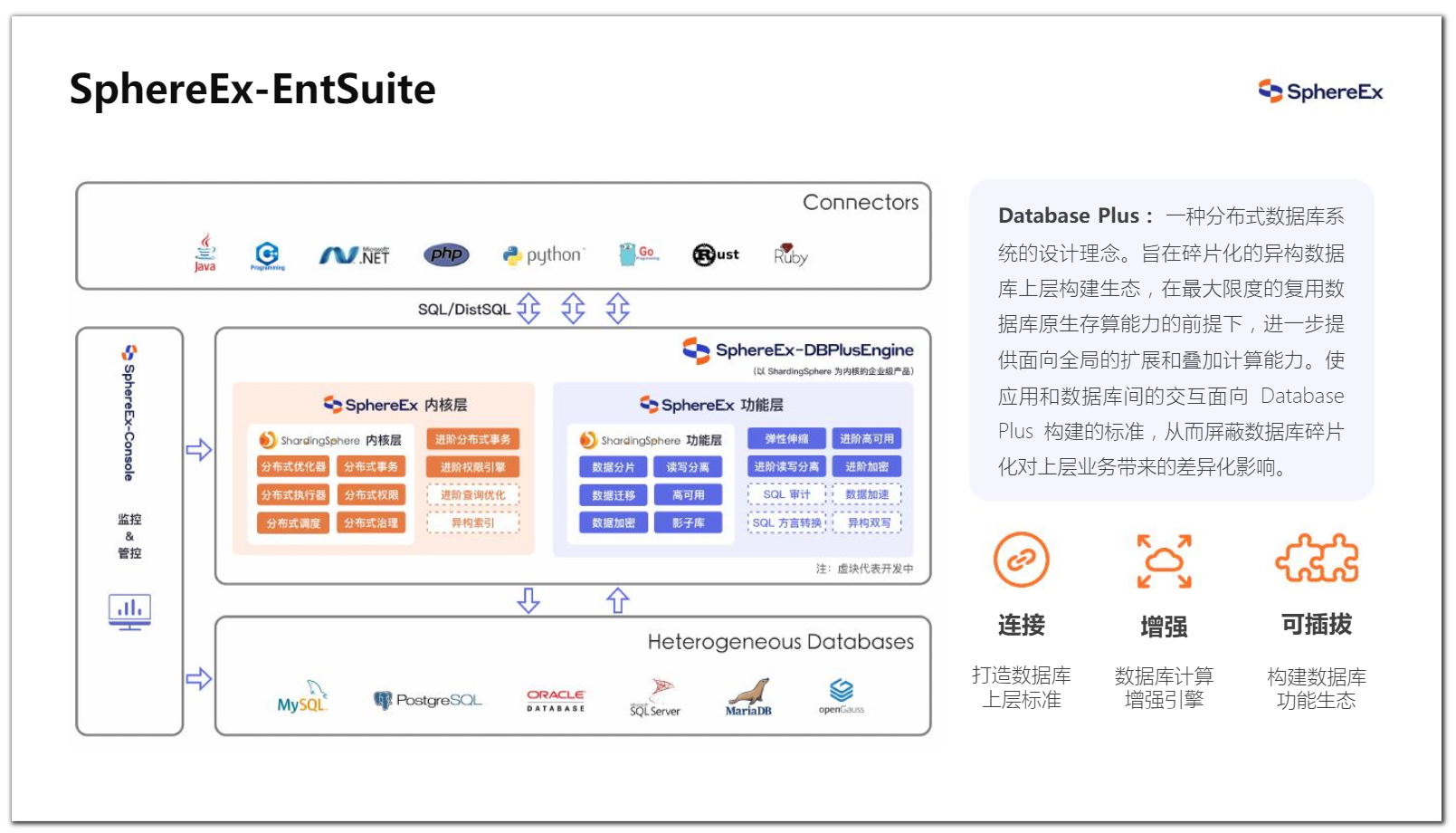
图8 DBPlusEngine 工程化面貌
为了让大家更了解产品架构设计,大家可以参考下方微内核架构设计图。从最核心的中间红色部分来看,这一层与数据库非常相似。我我们在核心部分加入了可插拔的实现扩展点,从内到外分别是微内核层、可插拔接口层,以及最外层的可插拔生态。微内核处理流程包括标准的 SQL Parser 和 SQL Binder 模块,这两个模块用于SQL具体特征的识别。
SQL Parser负责将用户发出的SQL转化为抽象语法树,并最终转化为提取必要特征的 SQL Statement。SQL Binder结合Metadata与SQL Statement,生成完整的且符合数据库表结构的抽象语法树,确定是否需要跨库执行,再根据其结果将流程分为简单下推引擎和SQL Federation引擎。当SQL可以经过逻辑表修改、执行信息补全等操作即可以全文下推至数据库存储节点时,它所使用的是左侧的简单下推引擎,以便保证SQL的最大兼容度;反之,当SQL需要跨节点和跨库子查询时,就需要走右侧的SQL Federation 引擎。
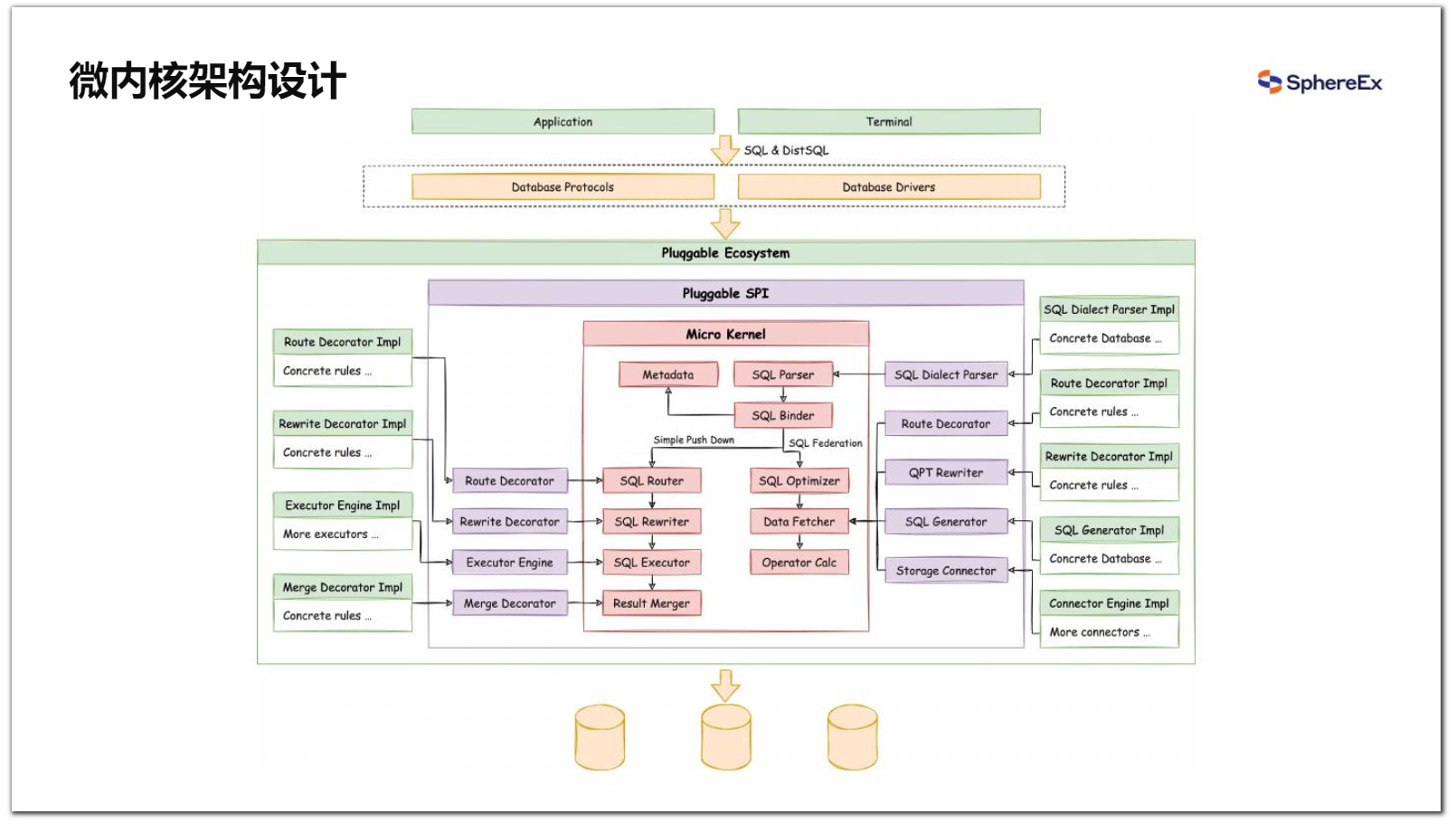
图9 ShardingSphere 微内核设计
3、 DBPlusEngine运维工具
接下来为大家介绍DBPlusEngine相关运维工具。
Boot 是快速构建 SphereEx-DBPlusEngine 集群的命令行工具,主要功能是对 SphereEx-DBPlusEngine 进行安装、启动、停止、查看运行状态、卸载等操作。
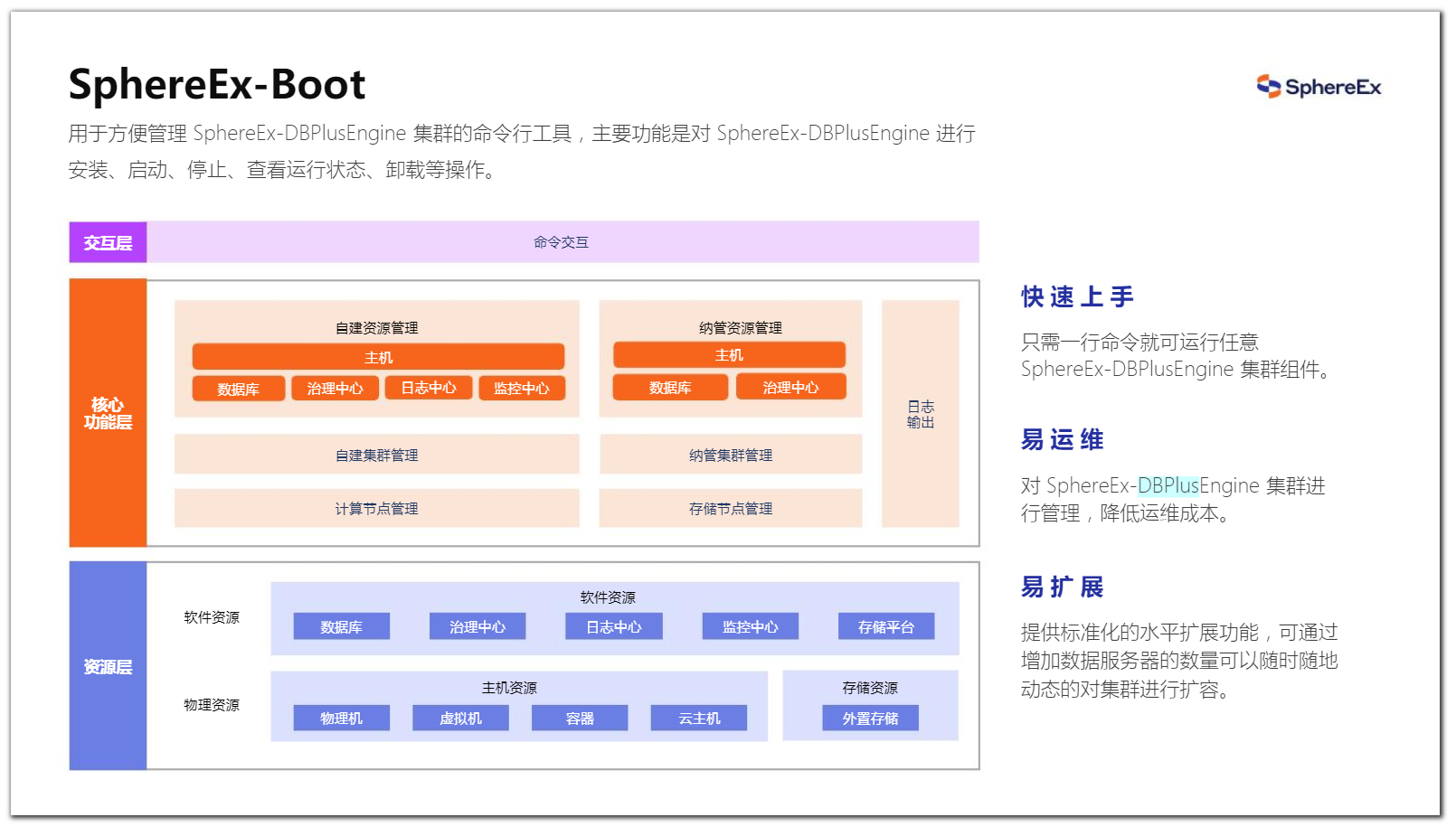
图10 DBPlusEngine运维工具:SphereEx-Boot
Console 是对 SphereEx 企业数据服务平台进行管理监控的可视化操作平台,提供更为易用的使用体验;同时,构建起以 SphereEx-DBPlusEngine 为核心的整体解决方案,包括针对资源、实例、插件等多种功能封装,为用户带来一站式的使用体验。
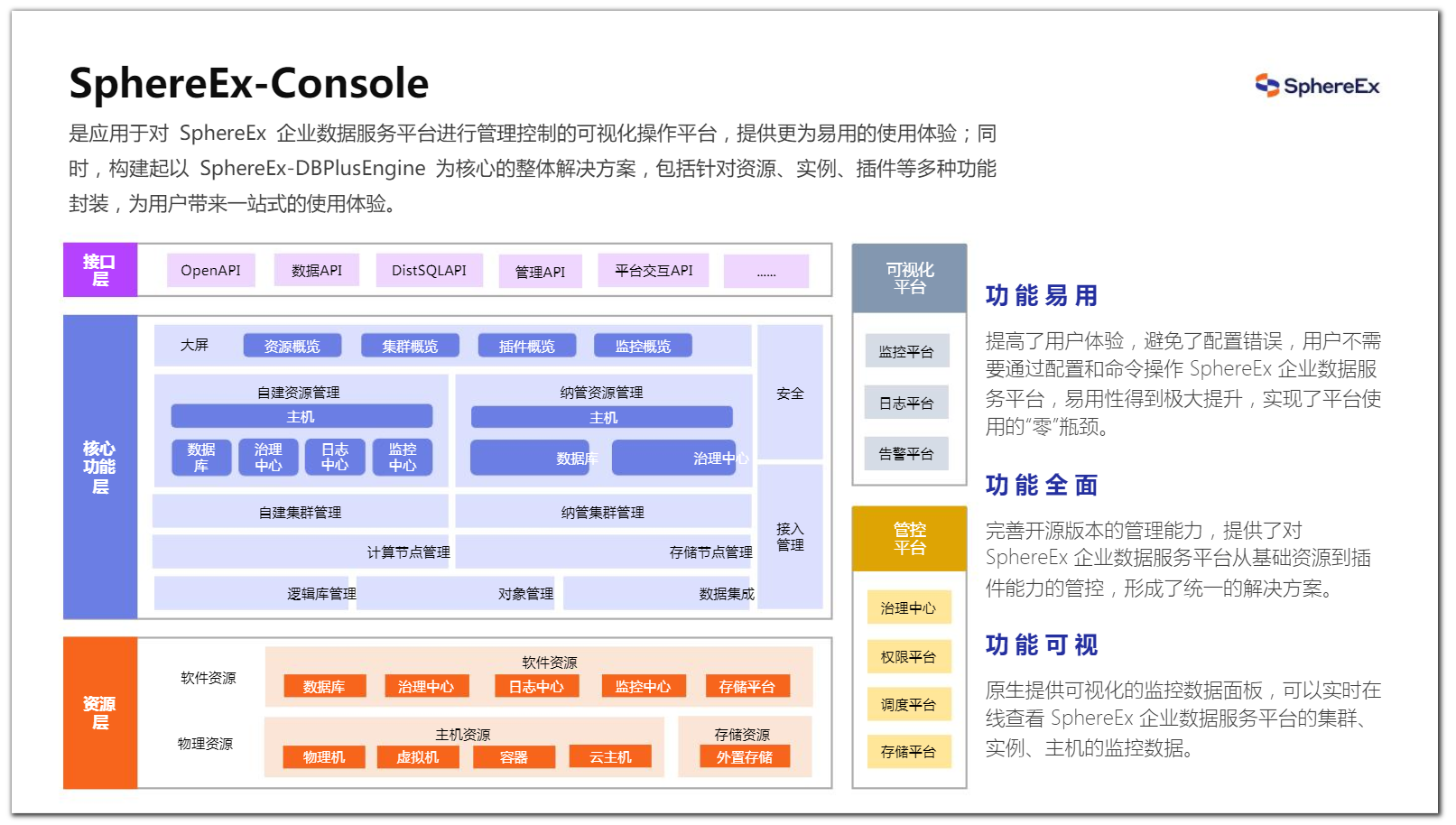
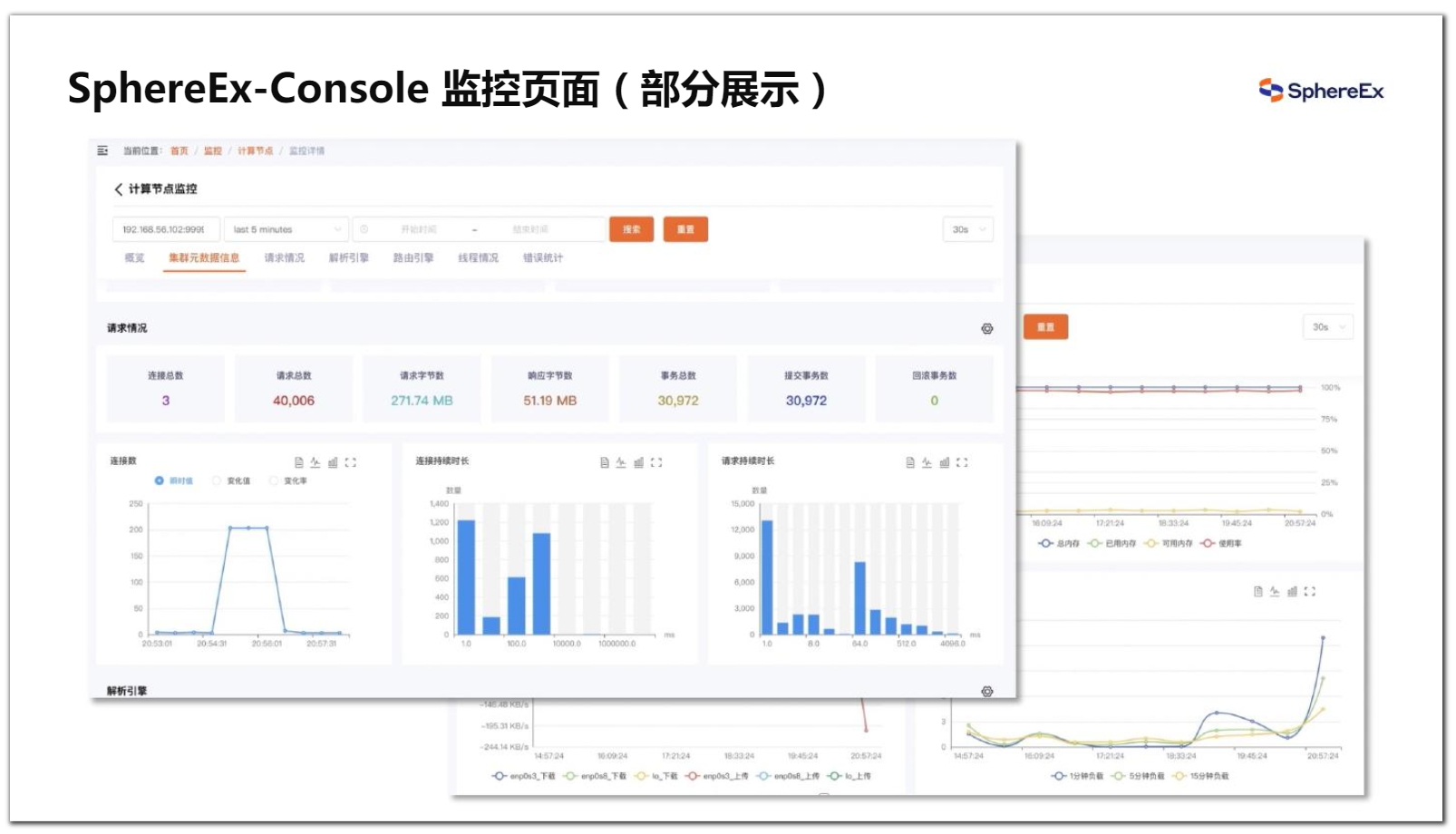
图11、12 DBPlusEngine运维工具:SphereEx-Console及部分监控页面
4、 DBPlusEngine 物理部署架构
DBPlusEngine物理部署架构有两种形态。如图,我们可以把最下面的Proxy当成数据库来使用,它对DBA友好,可以使用客户端直接访问,Proxy也可以对接多种开发语言的程序,比如Java、PHP等。
另外一种形态是Driver,它和Proxy内核是一样的,只不过外壳不一样。它比较适合于性能极致的场景,因为它靠近应用侧,到数据库少了网络一跳。同时也不需要单独再去采购服务器,就可以实现分布式的能力。这一部分就是对多种接入端选择的说明。我们当然可以混合使用这两种接入端,取各自优点,中间使用注册中心做元数据同步。
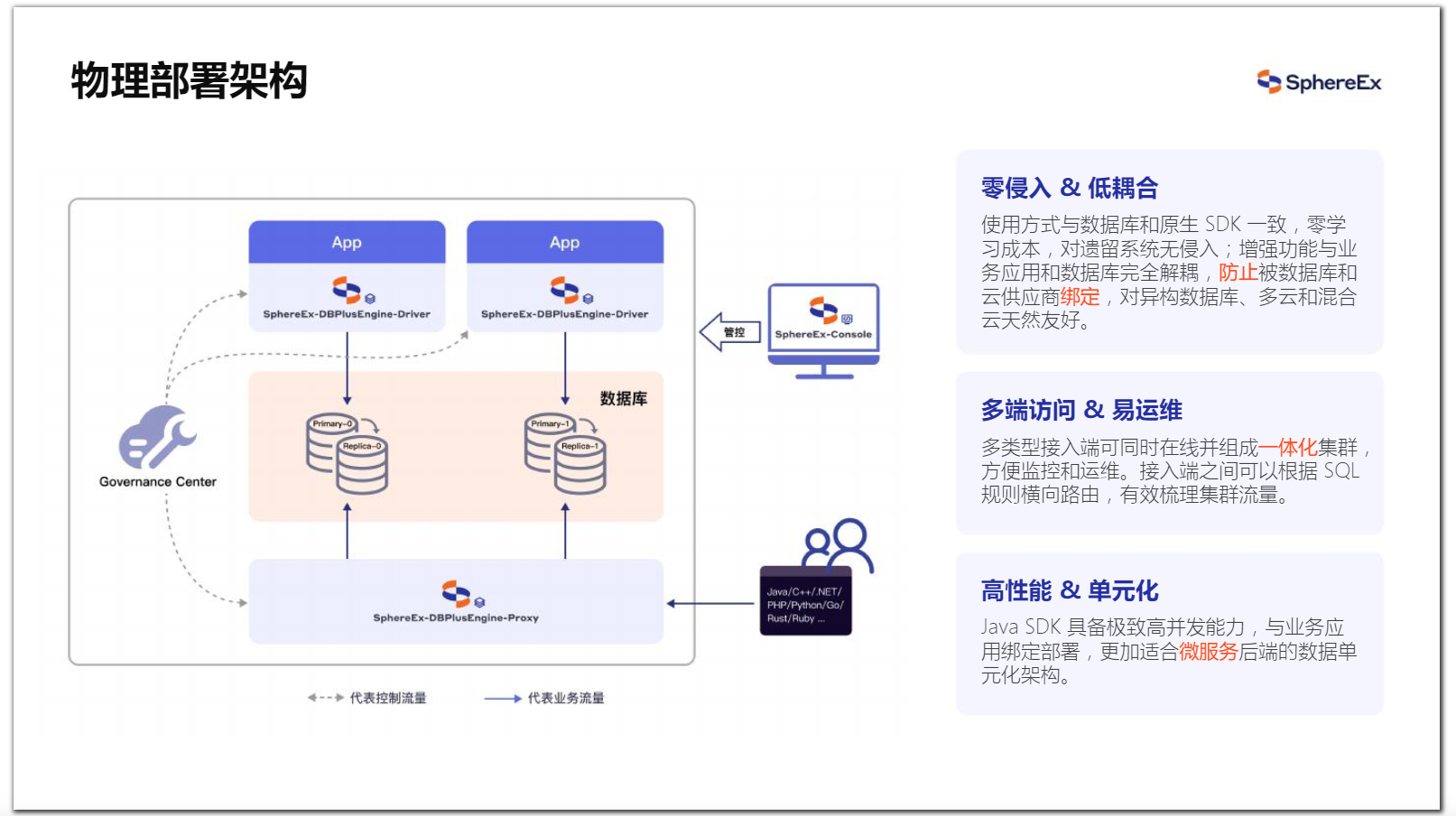
图13 ShardingSphere 物理部署架构
5、 ShardingSphere 性能优势与适用场景
下图展示了 ShardingSphere的极致性能优势。Sysbench点查场景中,数据库单点性能是4.8w的 QPS,通过中间件扩展后,底层使用5个数据库节点做了分片,整体吞吐量提升了4~5倍,呈线性增长。读写场景优势更明显。
我们今年联合openGauss社区进行了TPC-C测试,一共是16台鲲鹏设备,其中8台部署了openGauss,通过7个JDBC测出了1000万tpmC,现在我们也在做更进一步的优化提升。
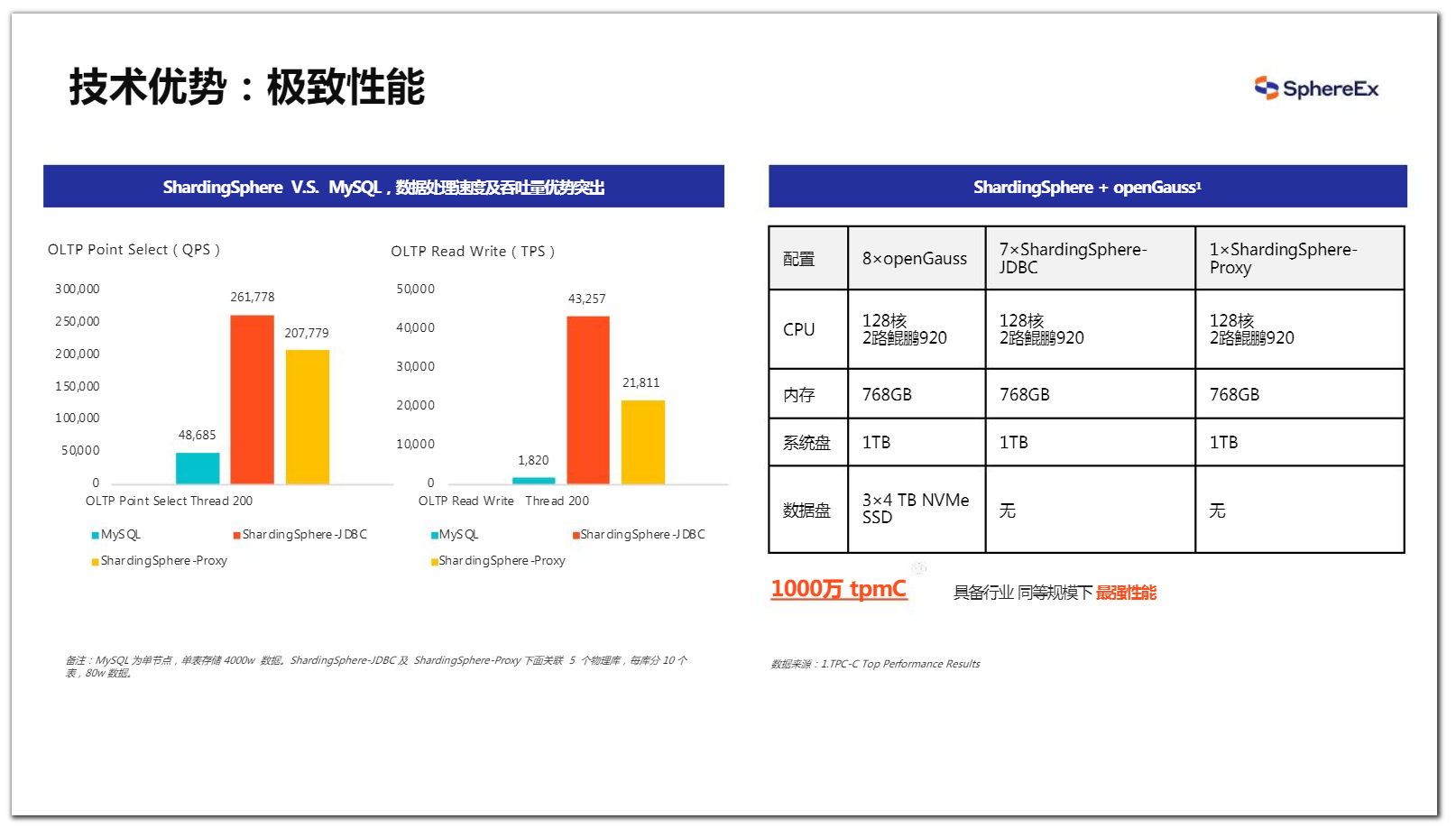
图14 ShardingSphere 极致性能体现
6、 ShardingSphere 适用场景
-
海量存储数据分片。数据库容量达到单体瓶颈场景下,通过横向水平扩展,可以有效解决单体数据存储容量问题,并可实现平滑数据迁移。
-
异构数据计算。面临数据库碎片化现状,打通异构数据库计算壁垒,提供联邦查询计算能力。降低异构数据库使用成本,提升计算效率。
-
数据安全。面临日益严重数据安全问题,通过多维度的数据加密能力,解决数据存储安全问题;并通过完善的数据行为的审计能力。
-
大规模高并发。互联网化的核心场景下,数据库响应变慢等问题。提供弹性扩展能力,实时提升数据库响应和计算能力。

图15 ShardingSphere 适用场景
6、 ShardingSphere 解决方案
基于 SphereEx-DBPlusEngine 的可插拔架构底座,将分布式数据库的核心能力中,与企业业务贴近的垂直功能排列组合,在数据库替换,海量数据存储,高并发访问与数据安全存储等场景,提供对应的解决方案。
- 分布式数据库解决方案: 为解决原有方案的技术瓶颈,降低更换架构带来的复杂性风险,在不更换原有架构前提下,实现数据库同步,管理多个异构数据库集群,线性提升数据存储容量及并发吞吐。为用户提供基于数据分片,分布式事务、弹性伸缩的分布式数据库解决方案,兼具单机交易型数据库稳定性和分布式数据库的扩展能力。
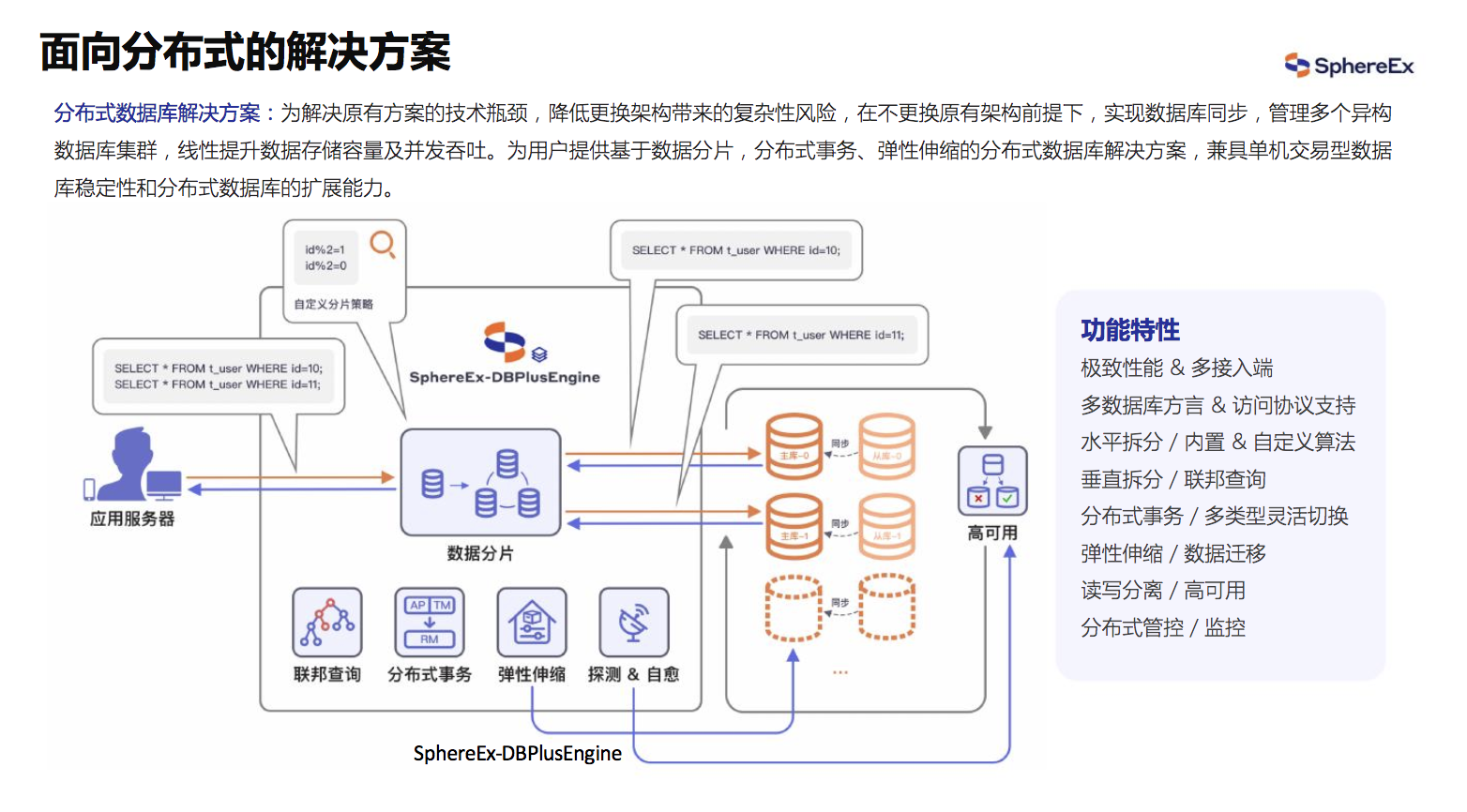
图16 分布式数据库解决方案
- 数据安全解决方案: 为了防止数据泄露,保护数据安全,提供基于产品的数据加密和数据脱敏功能。在不改动原有代码的前提下,为企业提供跨平台、异构环境的数据安全解决方案。
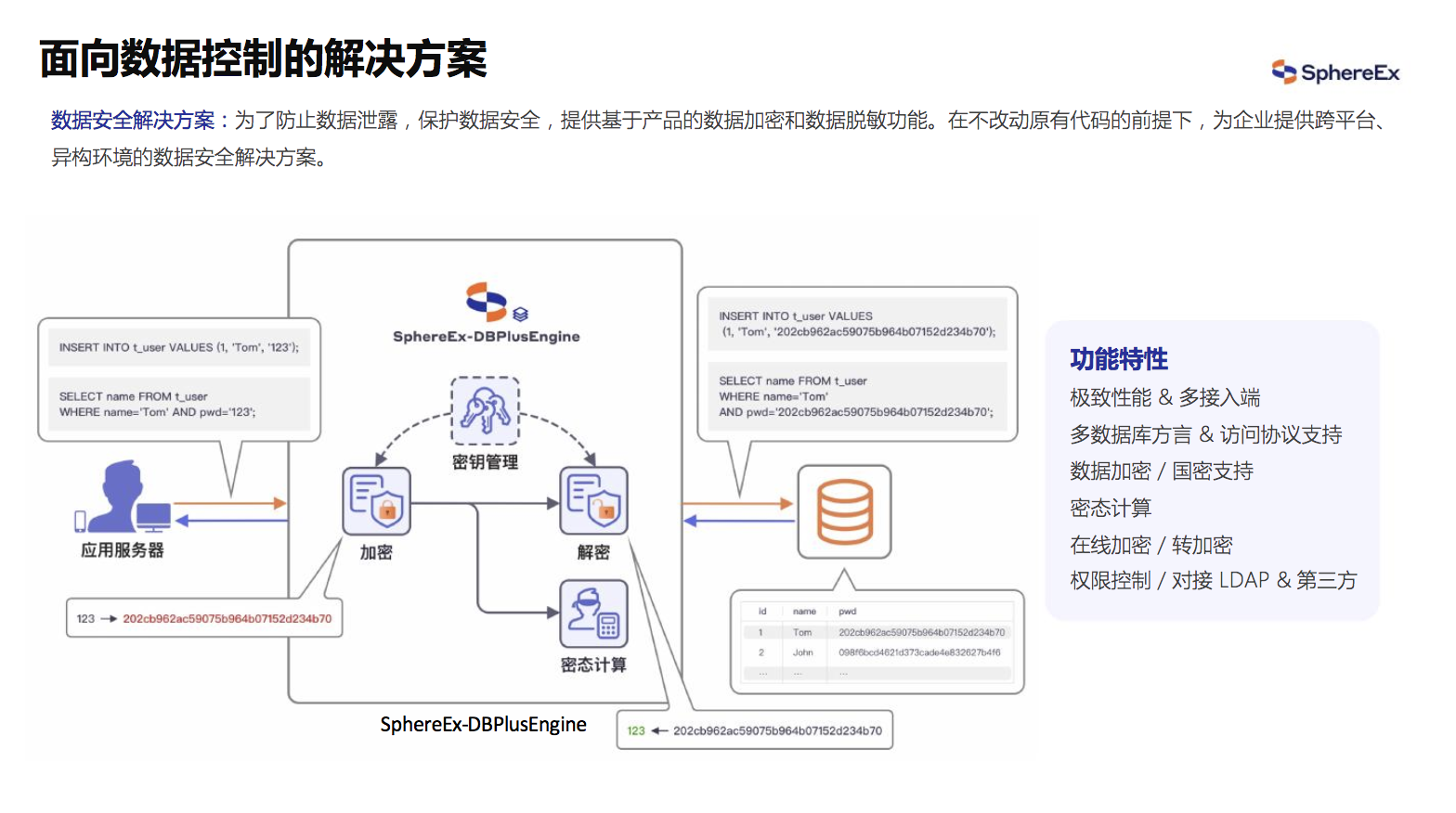
图17 面向数据控制的解决方案:数据安全
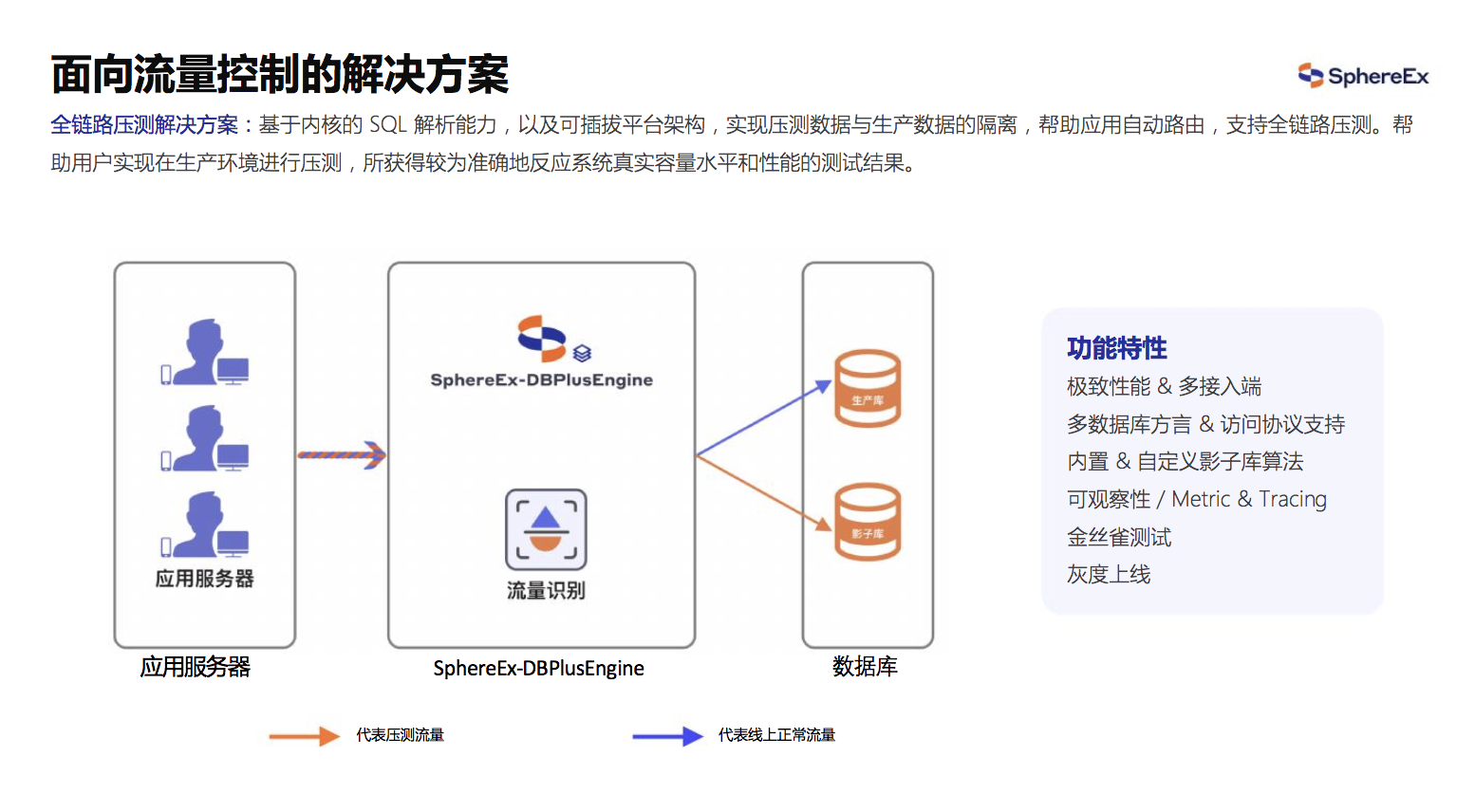
图18 全链路压测解决方案
- 全链路压测解决方案: 基于内核的 SQL 解析能力,以及可插拔平台架构,实现压测数据与生产数据的隔离,帮助应用自动路由,支持全链路压测。帮助用户实现在生产环境进行压测,所获得较为准确地反映系统真实容量水平和性能的测试结果。
ShardingSphere 最佳实践
下面我们通过两个案例来了解ShardingSphere 的最佳实践:数据分片和异构双写。
1、案例一:千亿数据量级金融场景(分片场景)
这是目前已知最大规模使用ShardingSphere的案例。该场景中,ShardingSphere支撑了6400分片、超过 1000亿条交易记录。在早期业务规划阶段,已经考虑了它数据量比较大、并发比较高的情况,因此在业务代码中实现了数据分片逻辑。但随着业务不断迭代,研发人员需要不断的在分片的逻辑上耗费较多的精力。
基于这样的情况,我们采用了下图右侧中的架构模式,业务通过ShardingSphere-JDBC来完成数据Sharding,基于客户端的模式可以最大化地发挥性能,代理端Proxy为DBA提供维护入口。通过改造,系统的扩展性得到了极大地改善,更重要的是业务人员也可以更专注于业务研发。
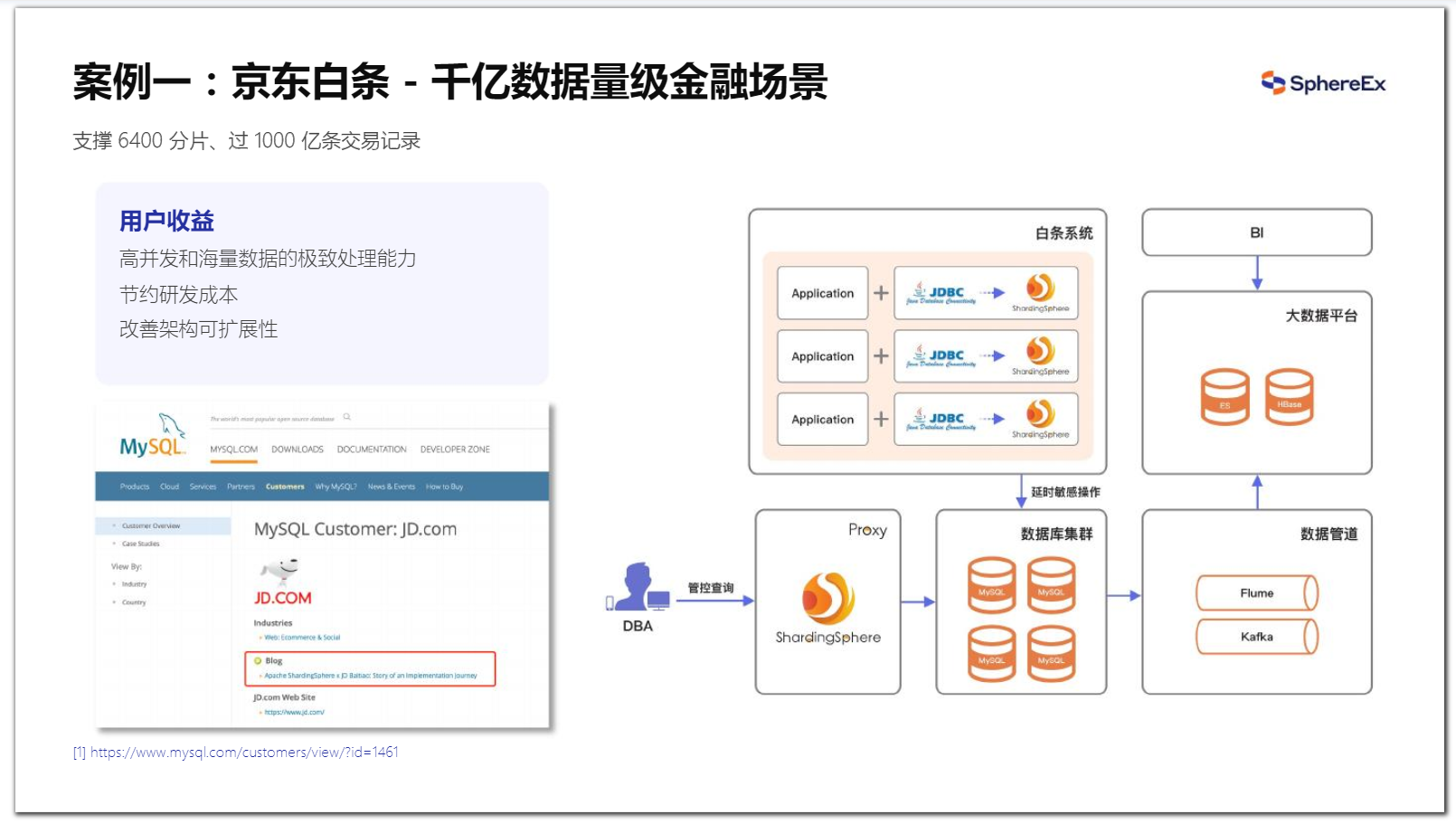
图19 ShardingSphere 在京东白条中的实践(信创场景)
2、案例二:异构数据双写场景
在某国企信息系统替“O”改造中,客户的核心诉求是系统稳定,相比上线时间的deadline,切换过程的平滑、稳定和完善的回退机制是客户最为关注的。基于这样的要求,我们的解决方案如下:一是双轨运行,应用请求会通过Driver组件向异构库分发,从应用到数据库全流程打通,确保可回退;第二是要实现逐步的切流,即在正式切换前的一段时间,Oracle只做写备份,国产DB把所有的读流量都承担过来,各项指标满足要求后再考虑下线Oracle。
实施中,首先需要对异构库做一次存量数据迁移,当两端存量数据同步完成之后,开始启用DBPlusEngine的这一层的双写能力,以XA的方式去保证两端数据的一致性,整个流程均为在线完成。
中间层具备底层数据库节点角色的捕获能力,以此来确定信创库HA的状态。极端情况下,当信创库出现集群级别异常,XA会自动退化为local事务,当故障处理完毕后,重新追齐数据,再人工启用双写。ShardingSphere 通过自身强有力的异构数据双写能力,助力国产基础软件走好信创落地“最后一公里”。
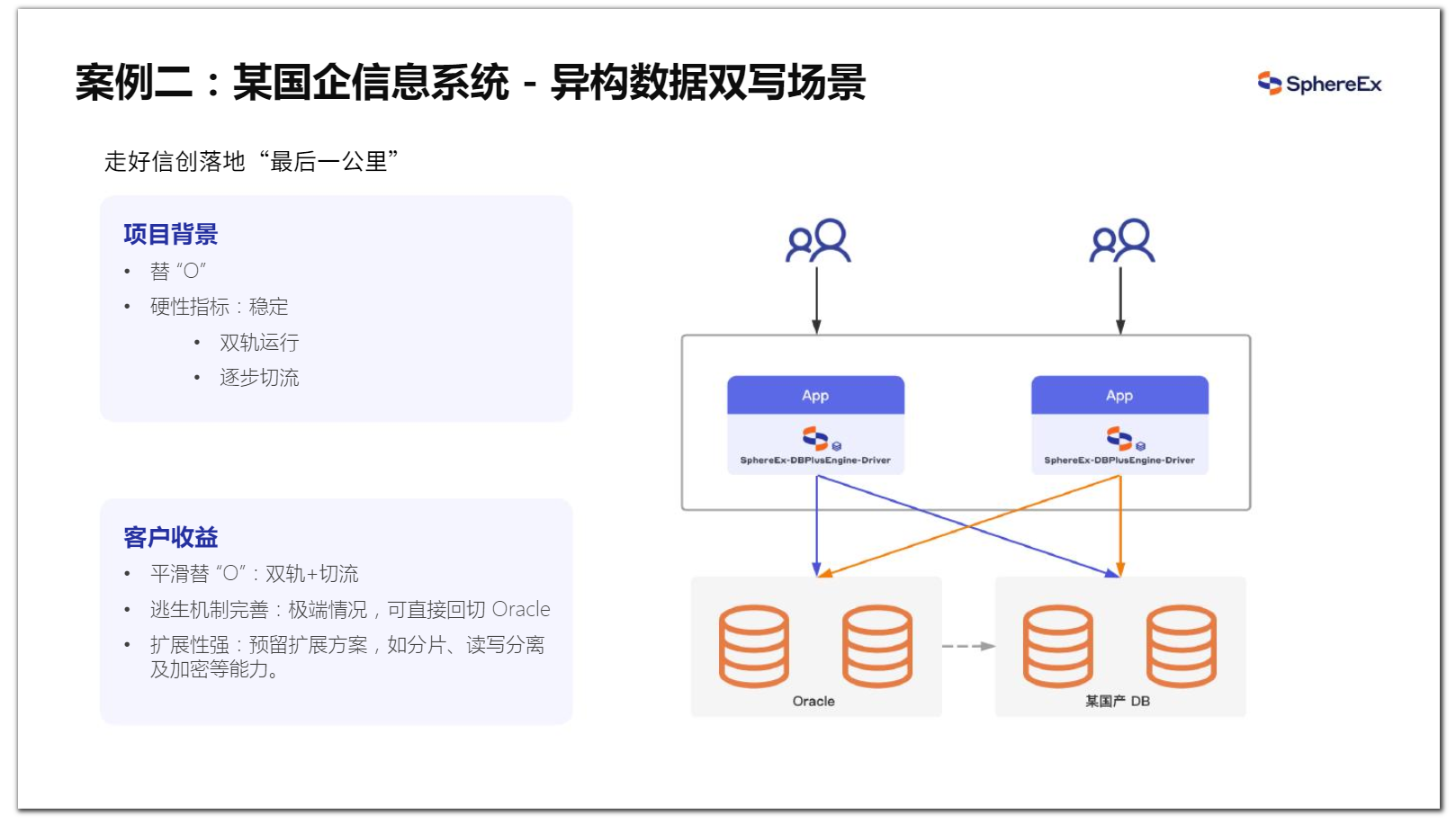
图20 DBPlusEngine 在某国企信息系统中的实践
随着应用场景的多样化,ShardingSphere 正在被推向更广的应用平台以及更深的技术场景,在实践中持续验证并优化自身的能力,同各路合作伙伴一起打造标准化的数据生态服务体系。

图21 ShardingSphere 部分生态合作伙伴
更多精彩内容,欢迎大家观看现场视频回放与会议资料
视频回放:https://www.modb.pro/video/7305
会议资料:https://www.modb.pro/doc/77274
