





大家好,今天和大家聊聊用PG的分区代替ORACLE的可能性。
众做周知,ORACLE 作为业界数据库的旗舰级产品,各项功能都是完善的, 近些年在国内某种大潮下,国产数据库或者开源数据库开始提供一些替代
ORACLE的解决方案。 目前OLTP这块, 开源的MYSQL和PG做为了2个主力根的分支。 国产数据库大部分都是基于这2个根分支进行了研发或者魔改。
国内早期的许多项目(非互联网场景,大多数为传统行业的项目),严重依赖于ORACLE 数据库的分区,并行查询,存储过程,hint, 强力的优化器功能(上千行的复杂大SQL,几十张表的join )等等等… 使得再去O 的道路上困难重重。
作为重度依赖oracle 的项目对于 数据库选型来说 :
mysql 这种小快灵的开发部署方式(devops),以及业界默认的规则 不要写复杂的SQL(表连接不要超过3张),不要分区,短事务 等等,似乎对于老项目的改造实现起来很难。
(程序员往往就是喜欢照着翻译,上万行的PLSQL 翻译成 短小的mysql 代码 放到JAVA程序中 基本上无任何希望。。。)
PG 虽然在国外有着几十年的历史,但是与兄弟数据库mysql比起来, 国内起步较晚,国内程序员接受程度普遍不是很高。
在国外来说,PG已经成为了最受开发者欢迎的数据库之一。
言归正传,我们首先看看PG的分区历史:
PG10 之前的版本, PG使用继承的方式来实现分区表的
从PG版本10 开始, PG可以使用声明式的分区定义,支持range, list 等主流分区的方式
从PG版本11开始, PG 支持hash key 的分区
我们先从PG基础的分区的定义来了解一下(本文分享的都是声明式的分区定义方式):
Range 范围分区
postgres=# create table payment_request (
id serial ,
account_no varchar(50) not null,
pay_amount decimal (6,2),
pay_date date,
pay_status int) partition by range(pay_date);
CREATE TABLE
由于PG没有全局索引的概念,所以主键或者唯一键必须要包含分区间,否则会报错: ERROR: unique constraint on partitioned table must include all partitioning columns(这一点和mysql 的分区表是一致的,ORACLE支持更为强大的全局索引)
postgres=# alter table payment_request add constraint pk_id_paydate primary key (id,pay_date);
ALTER TABLE
表payment_request 只是一个虚拟表的概念,我们需要添加具体的范围分区:
这里值得注意的是,对于范围分区来说,如果人为的指定范围错误,那么创建分区的时候也会报错: ERROR: partition “xxxx” would overlap partition “xxxxxxxxxx”
postgres=# create table payment_request_y2022m08 partition of payment_request
postgres-# for values from ('2022-08-01') to ('2022-09-1');
CREATE TABLE
postgres=# create table peyment_request_y2022m09 partition of payment_request
postgres-# for values from ('2022-08-20') to ('2022-09-30');
ERROR: partition "peyment_request_y2022m09" would overlap partition "payment_request_y2022m08"
LINE 2: for values from ('2022-08-20') to ('2022-09-30');
正确指定范围,手动创建分区: 2022-09 和 2022-09 2 个分区, 并在2个分区内插入数据
postgres=# create table payment_request_y2022m08 partition of payment_request
postgres-# for values from ('2022-08-01') to ('2022-09-1');
CREATE TABLE
postgres=# create table payment_request_y2022m09 partition of payment_request
postgres-# for values from ('2022-09-01') to ('2022-10-01');
CREATE TABLE
postgres=# insert into payment_request (account_no,pay_amount,pay_date,pay_status) values ('10000002',3500,'2022-09-01',1);
INSERT 0 1
postgres=# insert into payment_request (account_no,pay_amount,pay_date,pay_status) values ('10000001',2500,'2022-08-01',1);
INSERT 0 1
postgres=# select * from payment_request_y2022m08;
id | account_no | pay_amount | pay_date | pay_status
----+------------+------------+------------+------------
4 | 10000001 | 2500.00 | 2022-08-01 | 1
(1 row)
postgres=# select * from payment_request_y2022m09;
id | account_no | pay_amount | pay_date | pay_status
----+------------+------------+------------+------------
3 | 10000002 | 3500.00 | 2022-09-01 | 1
(1 row)
从PG11版本开始, 数据如果要在分区之间进行移动的话 ,比如执行 update 语句, 默认是 支持 enable row movement的。 (Oracle 数据库的话,需要手动开启表级别的 enable row movement)
早期PG10的版本,跨分区之间移动数据的话,会进行 分区约束的校验 partition constraint : 会返回错误 : ERROR: new row for relation "xxx " violates partition constraint
postgres=# update payment_request set pay_date = '2022-08-15' where pay_date = '2022-09-01';
UPDATE 1
postgres=# select * from payment_request_y2022m08;
id | account_no | pay_amount | pay_date | pay_status
----+------------+------------+------------+------------
4 | 10000001 | 2500.00 | 2022-08-01 | 1
3 | 10000002 | 3500.00 | 2022-08-15 | 1
(2 rows)
postgres=# select * from payment_request_y2022m09;
id | account_no | pay_amount | pay_date | pay_status
----+------------+------------+----------+------------
(0 rows)
如何查看分区表, 相对应的子分区(分区索引)以及大小?
postgres=# SELECT
postgres-# nmsp_parent.nspname AS parent_schema,
postgres-# parent.relname AS parent,
postgres-# nmsp_child.nspname AS child_schema,
postgres-# child.relname AS child,
postgres-# case
postgres-# when child.relkind = 'r' then 'ordinary table'
postgres-# when child.relkind = 'i' then 'index'
postgres-# when child.relkind = 'S' then 'sequence'
postgres-# when child.relkind = 'v' then 'view'
postgres-# when child.relkind = 'm' then 'materialized view'
postgres-# when child.relkind = 'c' then 'composite type'
postgres-# when child.relkind = 't' then 'TOAST table'
postgres-# when child.relkind = 'f' then 'foreign table'
postgres-# end as child_type,
postgres-# pg_size_pretty(pg_relation_size(child.relname :: varchar)) AS child_size
postgres-# FROM pg_inherits
postgres-# JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
postgres-# JOIN pg_class child ON pg_inherits.inhrelid = child.oid
postgres-# JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
postgres-# JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
postgres-# WHERE parent.relname in ('payment_request','pk_id_paydate') order by parent.relname;
parent_schema | parent | child_schema | child | child_type | child_size
---------------+-----------------+--------------+-------------------------------+----------------+------------
public | payment_request | public | payment_request_y2022m08 | ordinary table | 5888 kB
public | payment_request | public | payment_request_y2022m09 | ordinary table | 592 kB
public | pk_id_paydate | public | payment_request_y2022m08_pkey | index | 2208 kB
public | pk_id_paydate | public | payment_request_y2022m09_pkey | index | 240 kB
(4 rows)
我们还可以利用函数 pg_partition_tree 查看表与分区之间的关系:
postgres=# select * from pg_partition_tree('payment_request');
relid | parentrelid | isleaf | level
--------------------------+-----------------+--------+-------
payment_request | | f | 0
payment_request_y2022m09 | payment_request | t | 1
payment_request_y2022m08 | payment_request | t | 1
(3 rows)
函数 pg_partition_root 可以通过子分区的名称,查找到root 表的名称:
postgres=# select * from pg_partition_root('payment_request_y2022m09');
pg_partition_root
-------------------
payment_request
(1 row)
List 分区
列表分区也是我们常见的一种分区方式,通常作用于 NDV 值很小并且是预先固定的常量值的属性类,类似于 城市, 商品类型,订单状态。
我们把之前的付款表加上一列 region 这个区域属性的列:
create table payment_request_list (
id serial ,
account_no varchar(50) not null,
pay_amount decimal (6,2),
pay_date date,
pay_status int,
region varchar(50)
) partition by list(region);
CREATE TABLE
创建4个分区: 根据区域的 东南西北
postgres=# create table payment_request_list_east partition of payment_request_list for values
in ('east');
CREATE TABLE
postgres=# create table payment_request_list_west partition of payment_request_list for values
in ('west');
CREATE TABLE
postgres=# create table payment_request_list_north partition of payment_request_list for values
in ('north');
CREATE TABLE
postgres=# create table payment_request_list_south partition of payment_request_list for values
in ('south');
CREATE TABLE
postgres=# \d+ payment_request_list;
Partitioned table "public.payment_request_list"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
------------+-----------------------+-----------+----------+--------------------------------------------------+----------+-------------+--------------+-------------
id | integer | | not null | nextval('payment_request_list_id_seq'::regclass) | plain | | |
account_no | character varying(50) | | not null | | extended | | |
pay_amount | numeric(6,2) | | | | main | | |
pay_date | date | | | | plain | | |
pay_status | integer | | | | plain | | |
region | character varying(50) | | | | extended | | |
Partition key: LIST (region)
Partitions: payment_request_list_east FOR VALUES IN ('east'),
payment_request_list_north FOR VALUES IN ('north'),
payment_request_list_south FOR VALUES IN ('south'),
payment_request_list_west FOR VALUES IN ('west')
我们尝试插入一条在 list 列表之外的记录: 会返回错误 no partition of relation “payment_request_list” found for row
postgres=# insert into payment_request_list (account_no,pay_amount,pay_date,pay_status,region) values ('1000005',1500,'2022-09-27',0,'center');
ERROR: no partition of relation "payment_request_list" found for row
DETAIL: Partition key of the failing row contains (region) = (center).
当然我们可以手动添加一个 list = ‘center’ 的分区 。
或者我们也可以添加一个 default 分区 ,default partition 可以收纳 分区键之前的所有值 。
(PG version 11 开始支持 default 分区,list 和 range 均可以添加 default 分区)
postgres=# create table payment_request_list_default partition of payment_request_list default;
CREATE TABLE
postgres=# insert into payment_request_list (account_no,pay_amount,pay_date,pay_status,region) values ('1000005',1500,'2022-09-27',0,'center');
INSERT 0 1
postgres=# \d+ payment_request_list
Partitioned table "public.payment_request_list"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
------------+-----------------------+-----------+----------+--------------------------------------------------+----------+-------------+--------------+-------------
id | integer | | not null | nextval('payment_request_list_id_seq'::regclass) | plain | | |
account_no | character varying(50) | | not null | | extended | | |
pay_amount | numeric(6,2) | | | | main | | |
pay_date | date | | | | plain | | |
pay_status | integer | | | | plain | | |
region | character varying(50) | | | | extended | | |
Partition key: LIST (region)
Partitions: payment_request_list_east FOR VALUES IN ('east'),
payment_request_list_north FOR VALUES IN ('north'),
payment_request_list_south FOR VALUES IN ('south'),
payment_request_list_west FOR VALUES IN ('west'),
payment_request_list_default DEFAULT
hash 哈希分区
哈希分区是PG version 11 版本开始支持的, 需要哈希的列 必须要数据分布均匀,不要有倾斜,否则失去了哈希打散数据的意义,数据热点无法分散。
我们还是以 payment_request 作为案例, ID 作为hash key , 具有唯一性,使得数据分布均匀。
postgres=# create table payment_request_hash (
id serial ,
account_no varchar(50) not null,
pay_amount decimal (6,2),
pay_date date,
pay_status int,
region varchar(50)
) partition by hash(id);
CREATE TABLE
手动创建4个分区, 利用 mode 函数 除以4取余
postgres=# create table payment_request_hash_01 partition of payment_request_hash for values with (modulus 4, remainder 0);
CREATE TABLE
postgres=# create table payment_request_hash_02 partition of payment_request_hash for values with (modulus 4, remainder 1);
CREATE TABLE
postgres=# create table payment_request_hash_03 partition of payment_request_hash for values with (modulus 4, remainder 2);
CREATE TABLE
postgres=# create table payment_request_hash_04 partition of payment_request_hash for values with (modulus 4, remainder 3);
CREATE TABLE
postgres=# \d+ payment_request_hash
Partitioned table "public.payment_request_hash"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
------------+-----------------------+-----------+----------+--------------------------------------------------+----------+-------------+--------------+-------------
id | integer | | not null | nextval('payment_request_hash_id_seq'::regclass) | plain | | |
account_no | character varying(50) | | not null | | extended | | |
pay_amount | numeric(6,2) | | | | main | | |
pay_date | date | | | | plain | | |
pay_status | integer | | | | plain | | |
region | character varying(50) | | | | extended | | |
Partition key: HASH (id)
Partitions: payment_request_hash_01 FOR VALUES WITH (modulus 4, remainder 0),
payment_request_hash_02 FOR VALUES WITH (modulus 4, remainder 1),
payment_request_hash_03 FOR VALUES WITH (modulus 4, remainder 2),
payment_request_hash_04 FOR VALUES WITH (modulus 4, remainder 3)
模拟插入10000条数据: 查看数据分布的情况是很均匀的
postgres=# insert into payment_request_hash select generate_series(1,10000),'100000010',2000,'2022-09-27',1,'east';
INSERT 0 10000
postgres=# select count(1) from payment_request_hash_01;
count
-------
2489
(1 row)
postgres=# select count(1) from payment_request_hash_02;
count
-------
2527
(1 row)
postgres=# select count(1) from payment_request_hash_03;
count
-------
2530
(1 row)
postgres=# select count(1) from payment_request_hash_04;
count
-------
2454
(1 row)
组合分区
接下来再看看常用的二级分区: List + range 的形式 (一级 partition 是 List (region 列), subpartition 是 range (request_date))
PG 原生的语法并不支持直接创建二级分区表(国外商业版的 EDB postgres 支持),我们可以通过多次创建分区表的方式来间接实现2级分区的功能:
1.创建一级分区的定义 – partition by list
postgres=# create table payment_request_compose_list_range partition of payment_request_compose_list for values in ('east') partition by range(pay_date);
CREATE TABLE
2.创建二级分区的定义 – partition by range
postgres=# create table payment_request_compose_west_range partition of payment_request_compose_list for values in ('west') partition by range(pay_date);
CREATE TABLE
postgres=# create table payment_request_compose_east_range partition of payment_request_compose_list for values in ('east') partition by range(pay_date);
CREATE TABLE
3.创建具体的二级分区表
postgres=# create table payment_request_compose_west_range202208 partition of payment_request_compose_west_range for values from ('2022-08-01') to ('2022-09-01');
CREATE TABLE
postgres=# create table payment_request_compose_west_range202209 partition of payment_request_compose_west_range for values from ('2022-09-01') to ('2022-10-01');
CREATE TABLE
postgres=# create table payment_request_compose_east_range202209 partition of payment_request_compose_east_range for values from ('2022-09-01') to ('2022-10-01');
CREATE TABLE
postgres=# create table payment_request_compose_east_range202208 partition of payment_request_compose_east_range for values from ('2022-08-01') to ('2022-09-01');
CREATE TABLE
4.查询二级分区表之间的关系,我们可以利用函数 pg_partition_tree , 可以看到 level 0 是一级分区表 list 的定义, level1 是 二级分区表 range的定义 , level 2 是具体的二级分区表
postgres=# select * from pg_partition_tree('payment_request_compose_list');
relid | parentrelid | isleaf | level
------------------------------------------+------------------------------------+--------+-------
payment_request_compose_list | | f | 0
payment_request_compose_west_range | payment_request_compose_list | f | 1
payment_request_compose_east_range | payment_request_compose_list | f | 1
payment_request_compose_west_range202208 | payment_request_compose_west_range | t | 2
payment_request_compose_west_range202209 | payment_request_compose_west_range | t | 2
payment_request_compose_east_range202209 | payment_request_compose_east_range | t | 2
payment_request_compose_east_range202208 | payment_request_compose_east_range | t | 2
(7 rows)
分区的维护性
原生的PG分区的维护性和ORACLE老大哥比起来还是存在一定差异的。
a)添加,删除,truncate 分区的命令,直接作用于具体的分区表中, 由于没有ORACLE的全局索引的概念, 也就没有了全局索引 rebuild 的烦恼.
添加
postgres=# create table payment_request_y2022m10 partition of payment_request for
postgres-# values from ('2022-10-01') to ('2022-11-01');
CREATE TABLE
删除:
postgres=# drop table payment_request_y2022m10;
DROP TABLE
truncate:
postgres=# truncate table payment_request_y2022m10;
TRUNCATE TABLE
b)PG的交换分区命令(原生的PG不支持ORACLE的 exchange partition的命令): ATTACH 和 DETACH 分区
我们用 ATTACH,DETACH 模拟一下 类似exchange partition 的功能:
我们归档一下表 payment_request 的 8月份的分区 :
1)detach partition & create new partition
postgres=# alter table payment_request detach partition payment_request_y2022m08;
ALTER TABLE
postgres=# create table payment_request_y2022m08_arch partition of payment_request
postgres-# for values from ('2022-08-01') to ('2022-09-1');
CREATE TABLE
2)detach partition & attach partition
postgres=# create table payment_request_y2022m08 (LIKE payment_request INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
CREATE TABLE
postgres=# alter table payment_request detach partition payment_request_y2022m08_arch;
ALTER TABLE
postgres=# alter table payment_request attach partition payment_request_y2022m08 for values from ('2022-08-01') to ('2022-09-01');
ALTER TABLE
c)如何split 拆分分区, 原生的PG是没有split 的 语法的(国外的EDB的企业版有支持), 我们只能用如下的步骤来代替:
我们把一个月的分区,一分为二的步骤如下: 当然生产环境的话,如果这个分区不是冷数据(静态的数据)的话,是需要应用系统有 outage 的,来确保的完整性
1)Detach the partition
postgres=# alter table payment_request detach partition payment_request_y2022m09;
ALTER TABLE
2)create new partition
postgres=# create table payment_request_y2022m09_half1 partition of payment_request for values from ('2022-09-01') to ('2022-09-15');
CREATE TABLE
postgres=# create table payment_request_y2022m09_half2 partition of payment_request for values from ('2022-09-15') to ('2022-10-01');
CREATE TABLE
3)load the data into new partition
postgres=# insert into payment_request_y2022m09_half1 select * from payment_request_y2022m09 where pay_date <= '2022-09-15';
INSERT 0 0
postgres=# insert into payment_request_y2022m09_half2 select * from payment_request_y2022m09 where pay_date > '2022-09-15';
INSERT 0 9991
PG 分区的好处大致是:
1)数据的维护,特别针对数据的删除delete操作,避免产生大量的日志文件(WAL),避免大量死元祖的产生(表膨胀),避免频繁触发数据库 auto vacuum/vacuum的 backgroud 进程
2)性能上的优化:大家常说的 partition purning (分区消除),大表转化为小表的思想
3)并行查询
4)避免单表大小32TB的限制
分区的限制和缺陷:
1)分区键对于业务系统(业务代码)的侵入性,或者说 只有在特定的业务下选择业务分区键,才能最有效发挥分区的优势
2)PG目前无interval 类型的自动扩展分区,需要自行编写脚本来维护和监控。
3) 不支持全局索引,应用端之前如果有依赖全局唯一索引做校验的话保证数据的完整性的话,需要做代码改动
4)对于非分区表到分区表的转换, 由于目前PG不支持类似ORACLE基于MV LOG的在线重定义, 需要编写触发器同步数据的方案或者干脆选择系统维护窗口来实现CTAS
最后, 总结一下 ORACLE 分区表和PG分区表的功能对照表 (来自于 AWS 的官方,个人简单的翻译了一下)
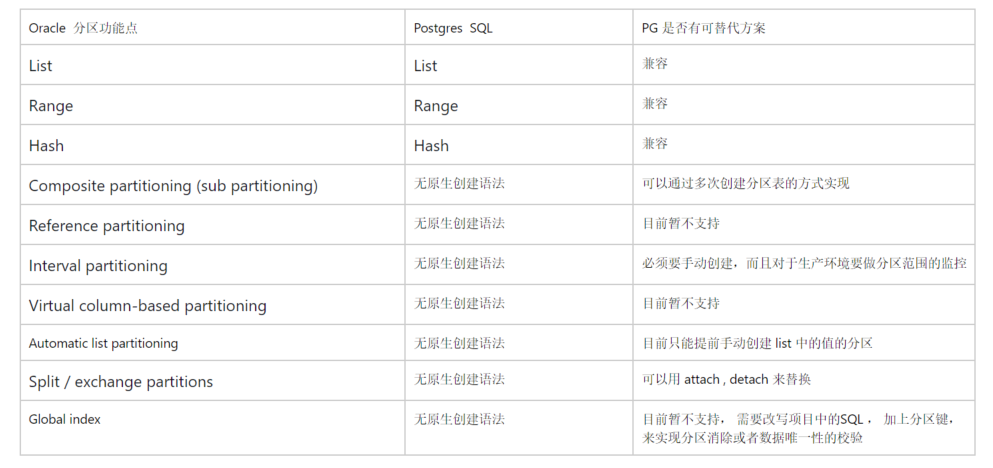
Have a fun! 😃
