




Hive是一个基于Hadoop分布式系统上的数据仓库,最早是由Facebook公司开发的,Hive极大的推进了Hadoop
ecosystem在数据仓库方面上的发展。
Facebook的分析人员中很多工程师比较擅长而SQL而不善于开发MapReduce程序,为此开发出Hive,并对比较熟悉SQL的工程师提供了一套新的SQL-like方言——Hive
QL。
Hive SQL方言特别和MySQL方言很像,并提供了Hive QL的编程接口。Hive QL语句最终被Hive解析器引擎解析为MarReduce程序,作为job提交给Job
Tracker运行。这对MapReduce框架是一个很有力的支持。
Hive是一个数据仓库,它提供了数据仓库的部分功能:数据ETL(抽取、转换、加载)工具,数据存储管理,大数据集的查询和分析能力。
由于Hive是Hadoop上的数据仓库,因此Hive也具有高延迟、批处理的的特性,即使处理很小的数据也会有比较高的延迟。故此,Hive的性能就和居于传统数据库的数据仓库的性能不能比较了。
Hive不提供数据排序和查询的cache功能,不提供索引功能,不提供在线事物,也不提供实时的查询功能,更不提供实时的记录更性的功能,但是,Hive能很好地处理在不变的超大数据集上的批量的分析处理功能。Hive是基于hadoop平台的,故有很好的扩展性(可以自适应机器和数据量的动态变化),高延展性(自定义函数),良好的容错性,低约束的数据输入格式。
下面我们来看一下Hive的架构和执行流程以及编译流程: 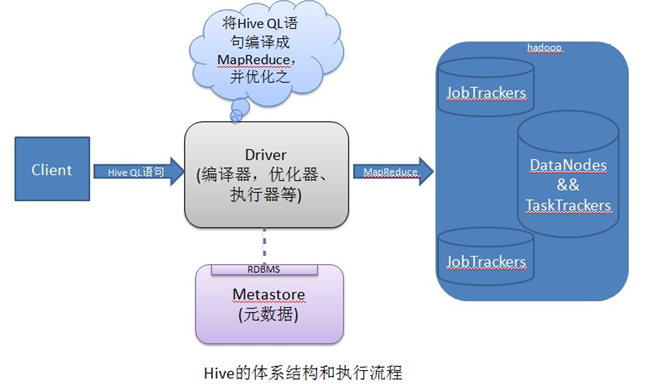
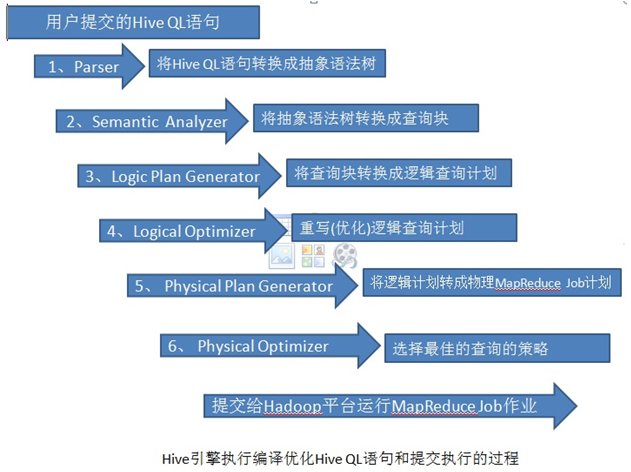
用户提交的Hive QL语句最终被编译为MapReduce程序作为Job提交给Hadoop执行。
Hive的数据类型
Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,TIMESTAMP(V0.8.0+)和BINARY(V0.8.0+)。
Hive的集合类型有:STRUCT,MAP和ARRAY。
Hive主要有四种数据模型(即表):(内部)表、外部表、分区表和桶表。
表的元数据保存传统的数据库的表中,当前hive只支持Derby和MySQL数据库。
内部表:
Hive中的表和传统数据库中的表在概念上是类似的,Hive的每个表都有自己的存储目录,除了外部表外,所有的表数据都存放在配置在hive-site.xml文件的${hive.metastore.warehouse.dir}/table_name目录下。
Java代码
CREATE TABLE IF NOT EXISTS STUDENTS(USER_NO INT,NAME STRING,SEX STRING,
GRADE STRING COMMOT '班级')COMMONT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS TEXTFILE; 外部表:
外部表指向已经存在在Hadoop HDFS上的数据,除了在删除外部表时只删除元数据而不会删除表数据外,其他和内部表很像。
Java代码
CREATE EXTERNAL TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级')COMMONT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE
LOCATION '/usr/test/data/students.txt';
分区表:
分区表的每一个分区都对应数据库中相应分区列的一个索引,但是其组织方式和传统的关系型数据库不同。在Hive中,分区表的每一个分区都对应表下的一个目录,所有的分区的数据都存储在对应的目录中。
比如说,分区表partitinTable有包含nation(国家)、ds(日期)和city(城市)3个分区,其中nation
= china,ds = 20130506,city = Shanghai则对应HDFS上的目录为:
/datawarehouse/partitinTable/nation=china/city=Shanghai/ds=20130506/。
Java代码
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE; 分区中定义的变量名不能和表中的列相同。
桶区表:
桶表就是对指定列进行哈希(hash)计算,然后会根据hash值进行切分数据,将具有不同hash值的数据写到每个桶对应的文件中。
Java代码
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级',score SMALLINT COMMOT '总分')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
CLUSTERED BY(user_no) SORTED BY(score) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE;内部表和外部表的主要区别:
1)、内部表创建要2步:表创建和数据加载,这两个过程可以同步执行。在数据加载的过程中,数据数据会移动到数据仓库的目录中;外部表的创建只需要一个步骤,表创建数据加载同时完成,表数据不会移动。
2)、删除内部表时,会将表数据和表的元数据一同删除;而删除外部表时,仅删除表的元数据而不会删除表数据。
