




问题现象
由于最近在测试k8s集群,QA同学发现访问一个接口时不稳定,通信一会正常、一会后不正常、交替进行,并且报错为 503 Service Temporarily Unavailable 错误,由于使用的是ingress nginx controlller,其它业务没有此问题,报错信息如下。
报错图
环境说明
1. 问题发生在测试环境;
2. 每个deplpoyment副本数为1;
3. 配置了就绪性探针;
知识梳理
目前之所以选择 Kubernetes 作为容器编排引擎,最主要的是因为它具有强大的自愈能力,默认情况下,一台宿主机故障后,它会自动把无状态应用迁移到其它宿主机上面,或者Pod发生故障后,也会重启单独的Pod。除此之外,kubernetes 还提供了 Liveness 和 Readiness 探测机制,有了这两种机制之后,可以实现零停机部署、滚动更新、并且可在探测服务可用性等,其实 kubernetes 里面提供的两种探测机制,都是对应用程序健康状态进行检查,让 kubernetes 能够感知到应用程序是否正常工作等,如果服务不正常,流量就不应该再向其发送请求,相应的,如果应用程序服务恢复后,流量能够自动接入。
Liveness存活性探针
存活性探针主要是监控Pod是否健康,如果没有配置 livenessProbe,探针返回Success,但会判断Pod内容器是否正常启动,正常启动即为Running状态,如果配置了存活性探针,就根据探针定期进行探测,如果探测成功,则Pod状态可以判定为Running,如果探测失败,kubectl 会根据Pod的重启策略来重启容器。
这里需要注意一点,Pod 处于Running状态,并不代表能正常提供服务,只能说明 Pod 内的容器是存活的,服务是否正常,是否能提供服务,需要使用 Readiness 就绪性探针进行判断。
Readiness就绪性探针
就绪性探针是判断 Pod 是否可以接受请求和访问的依据,并且也是容器是否处于可用 Ready 状态的标志,达到 Ready 状态的 Pod 可以接受请求、调度(尤其是 HTTP 流量接口的,很有必要配置此探针)。Kubernetes 只有在 Readiness 探针检测通过后,才允许服务将流量发送到 Pod,如果探针失败,Kubernetes将停止向该容器发送流量,直到配置的 Readiness 探针通过,如果 Readiness 探针失败,还会直接从 service 的后端 endpoint 列表中把 pod 删除,至到恢复后,再加到 service 后端的 endpoint 列表中(kubectl describe svc 服务名 -n 名称空间)。
livenessProbe 探针失败, kubectl 会根据Pod的重启策略来重启容器,readinessProbe 探针失败不会重启操作,但Service 后端会从 endpoint 列表中把 pod 删除。
就绪性、存活性探针配置参数
| 探针方式 | readinessProbe/livenessProbe | 备注 |
| httpGet | httpGet: host: (默认为pod的IP) path: /index.html port: 8080 (可以指定暴露端口的名称) scheme: HTTP | 根据状态码进行判断 |
| exec | exec: command: - cat - /data/healthy | 在容器内执行某命令,命令执行成功(通过命令退出状态码为0判断)则确定Pod就绪; |
| tcpSocket | tcpSocket: host: (默认为pod的IP) port: 80 | 打开一个TCP连接到容器的指定端口,连接成功建立则确定Pod就绪 |
| 其它参数 | ||
| failureThreshold | 探测几次都失败,认为就失败了,默认是3 | |
| initialDelaySeconds | 初始化延迟探测时间,如果不定义,容器一启动就探测,我们知道容器启动,不代表容器中的主进程已经运行起来; | |
| periodSeconds | 周期间隔时长,定期探测 | |
| successThreshold | 失败后检查成功的最小连续成功次数。默认为1.活跃度必须为1。最小值为1。 | |
| timeoutSeconds | 探测超时时间,默认是1s |
问题排查
初步预判
由于是通过ingress规则注册到ingress controller中,然后通过域名进行访问,为什么会时好时坏呢,根据503 Service Temporarily Unavailable ,第一感觉是nginx controller有访问次数限制,并且通过多次测试发现时好时坏,仔细分析,并没有次数的限制,比如1分钟10次,20次,没有规律可偱,它与nginx limit策略还不是很符合,一般如果配置了limit_req策略的话,相对有规律一些,登录ingres controller,通过查看配置,发现没有limit_req 相关配置,也证明了不是 limit_req 造成 503错误,接下来,查看ingress controller日志。

nginx ingress controller 日志
发现日志中并没有转发过去,nginx只是作为反向代理,一般情况下5xx错误都是后端产生的,但这次并没有转发到后端,后端服务器也没有日志,难道 nginx 规则注册到 ingress controller控制器有问题,其它业务没有反馈。
测试对比
此时跳过nginx ingress controller,直接访问 Pod 进行测试,发现服务正常,然后编写脚本同时通过ingress访问和Pod访问测试,发现通过ingress的时好时坏,直连到Pod的通信一直是好的,说明后面Pod服务正常,此时更加确信是前端ingress controller的问题了,真的那么有信心确认是它的问题吗?👀 👀
ingress 规则是使用service名称,把转发规则注册到 ingress controller,那现在通过 service 访问是否正常呢,修改上面的脚本,同时通过 ignress controller 访问、Pod IP 直连访问、service ClusterIP 访问,此时可以发现接口正常通信时,三个接口都正常,出现503时,发现通过 Service Cluster IP 也不正常,到这里基本可以排除 nginx ingress controller了。
Pod 状态检查
之前查看过Pod的状态,存活性探针、就绪性探针都是正常的(其实是一会正常,一会异常),只是之前查看的时候正好正常而已,需要长期观察下,尤其是接口通信异常时。

问题定位及解决
为什么这里 Service Cluster IP 无法提供服务了,通过kubectl describe svc 服务名 -n 名称空间,发现Endpoints: 后面的IP时有时无,说明 Pod 一会处于 Ready 状态,一会无法正常Ready,再联想下 readiness 就绪性探针就会发现,很容易发现是健康检测时好时坏,导致探针一会正常,一会失败,进入 pod查看日志,也证实了这一点,health_check时好时坏。
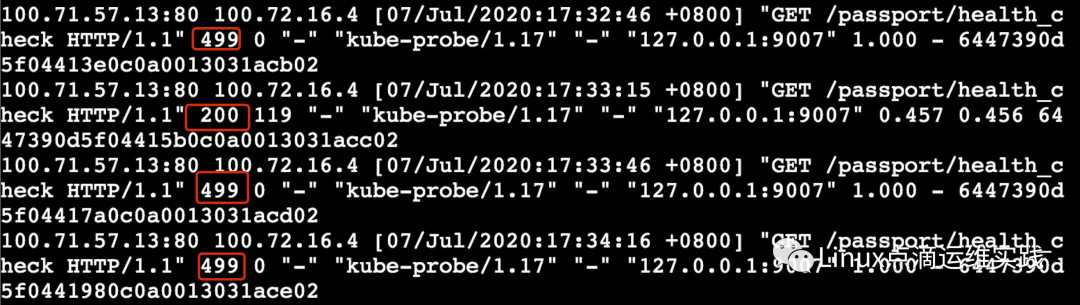
这里还发现超时时间是1秒,我们是有配置readinessProbe的,配置如下
readinessProbe:
failureThreshold: 1
httpGet:
port: 80
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 1
这里超时时间为1秒,与上面错误日志中health_check时1秒超时相互应,问题到这里基本上找到根了,和ingress controller 没有关系。进一步排查为什么health_check失败呢?
通过time curl可以很容易的发现,是经常出现超过3秒的情况,使用strace 跟踪了下,如下图
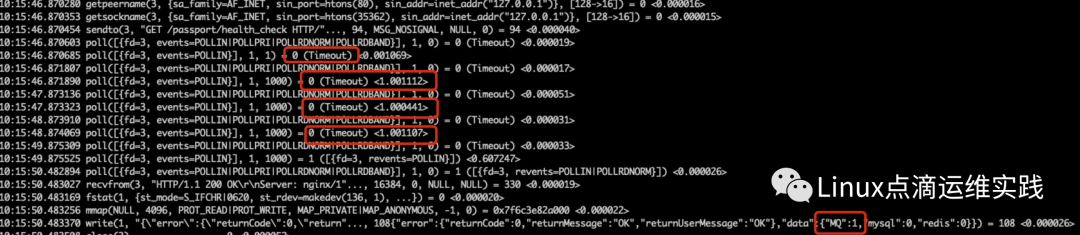
发现确实是非常的卡,由于是php项目,php项目中有慢查询日志,查询慢查询日志中应该有记录才对,通过查看日志发现

发现checkMQ()时出错,最终发现是访问 (这里域名进行了替换)
[root@passport ~]# curl http://k8s.vip:8080/mqagent/healthcheck
fail[root@passport ~]#
[root@passport ~]#
这个接口会耗时很大,reponse 有时非常快,有时很慢有3秒、1秒的情况,正常接口应该很快就有响应。
[root@passport ~]# curl http://k8s.vip:8080/mqagent/healthcheck
success[root@passport ~]#
[root@passport ~]#
最后,去MQ机器去排查问题,发现一个配置错误,导致响应很慢,至此,问题解决。
总结
本次问题点就是当 Pod 的 readinessProbe 探针失败时,Service 后端会从 endpoint 列表中把 pod 删除,由于是测试环境,后端只有一台 Pod,所以问题非常容易复现。
在处理问题时,需要结合 kubernetes 实现原理一步步排查,大部分可以很快解决。现在知道了结果,感觉排查很简单,其实往往解决一个问题后,都有类似的感觉,走了不少弯路,只有日积月累后,才能更好的解决问题,共勉。

您的关注是我写作的动力

往期分享
专辑分享
kubeadm使用外部etcd部署kubernetes v1.17.3 高可用集群
第一篇 使用 Prometheus 监控 Kubernetes 集群理论篇
