




在我工作的地方,一直存在关于生成测试数据的讨论。
目前,我们不会替换或更改任何用于测试环境的生产数据,也不会生成测试数据。
因为生产数据是标记化的,上述的做法安全且合法。换句话说,PII和PCI数据正在被持有该占位符的令牌所替代,应用程序可以使用这个令牌通过一种特殊保护服务去访问受保护的数据。只有一部分有限的人可以处理特殊保护服务后面的数据。
在测试环境中使用生产数据比较高效,因为我们以并行和线性复制数据,或者我们可以开启写入时重定向(SSD时代的“写入时复制”)可写快照。
假设一下,我们想改变并且想达成以下目的:
- 在复制到测试数据库时,屏蔽掉一些数据
- 在保持数据参照完整性的同时,减少测试数据库中使用的数据量
- 在保持参考完整性和一些基本统计属性前提下,产生任意大小的测试数据集,而不是使用生产数据
制作数据:
假设复制生产数据到测试环境,我们把每个想隐藏的数据复本修改一下数据项,例如用sha(“secret” + original value),或者一些其它的替换令牌。
kris@localhost [kris]> select sha(concat("secret", "Kristian Köhntopp"));
+---------------------------------------------+
| sha(concat("secret", "Kristian Köhntopp")) |
+---------------------------------------------+
| 9697c8770a3def7475069f3be8b6f2a8e4c7ebf4 |
+---------------------------------------------+
1 row in set (0.00 sec)
为什么我们用一个哈希函数或者等价的公式来实现?我们当然是想保证数据的参照完整性。所以每个Kristian Köhntopp将被9697c8770a3def7475069f3be8b6f2a8e4c7ebf4代替,这是一个可以预测且稳定的值,而不是在第一次产生一个随机的数字17,第二次则产生一个随机数字25342.
关于数据库工作,表示在复制完数据完成后,我们更新数据的每一行记录,并且为每次更新创建一个binlog记录。如果被修改的列存在索引,那么包含对应列的索引也应该被更新。如果我们更改的列是主键,则该记录的物理位置也会被修改,因为InnoDB将数据聚集在主键上。
简而言之,虽然复制数据很快,但屏蔽数据的成本要高得多,而且在任何硬件上都无法以线速运行。
减少数据量
在公司历史的早期,大约 15 年前,一位同事致力于通过选择生产数据的子集来创建更小的测试数据库,同时保持参照完整性。 他失败了。
许多其他人后来尝试过,我们有项目大约每 3 到 5 年尝试一次。 他们也失败了。
每次尝试总是选择一个空数据库或生产中的所有数据。
这是为什么?
让我们来看一个简单的模型:有用户,酒店,他们的关系是n:m。
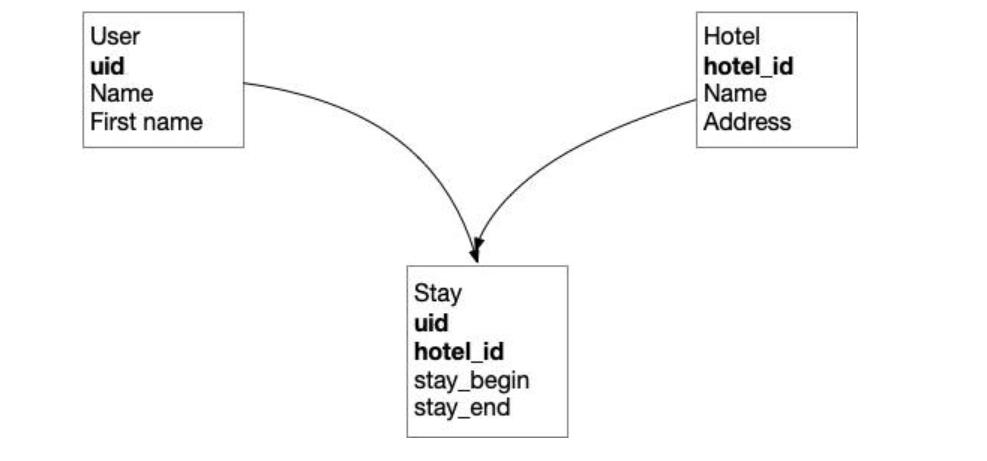
“克里斯”住在“卡萨”酒店。我们从生产环境中选择Kris进入测试数据集,酒店也选择“Casa”。 其他住在 Casa酒店的客人,他们也被导入到测试数据集中,由于这些客人也住在其他酒店,所以这些酒店也被导入。 经过3次反射,6次转换,结果我们选择了整个生产数据库进入测试集。
由于我们的生产数据是相互关联的,保持生产数据的参照完整性将意味着选择一个最终选择所有。
限制时间范围会对前述情况有所帮助:我们只选择过去一周或其他时间的数据。但这还有其他含义,例如在数据分布方面。此外,在可用性操作方面,我们的生产数据在时间上存在严重不均匀的,如上周发生了很多预订。
生成测试数据
生成垃圾数据很快,但仍然比复制慢。 这是因为从生产机器复制数据不仅要复制二进制文件,还需要预建存在的索引,对比生成垃圾数据相当于导入mysqldump。需要解析数据,更糟糕的是,需要构建所有索引。
虽然我们可以以每秒数百MB的速度复制数据,最高可达GB/s范围,但导入数据的速度为个位数MB/s,还是达几十MB/s,很大程度上取决于 RAM 的可用性、磁盘的速度、索引的数量以及输入数据是否按主键排序。
生成良好的数据比较难,且效率也低。
你需要定义或从模式推断出的引用完整性约束列表。 在工作中,我们的模式很大,比单个数据库或服务大得多——用户服务(测试用户服务,带有测试用户数据)中的用户需要在预订服务(带有测试预订的测试预订服务)中被引用,引用 到酒店中测试房源和测试酒店商店。
这意味着要么为每个测试创建和维护一个一致的第二个环境,要么跨服务从头开始创建这个。 一个是对生产力的拖累(保持一致的环境需要大量工作),另一个是缓慢的。
但是,一致性并不是唯一的要求。 如果您想测试验证代码,一致性很好(但我的测试名称不是 utf8,它们来自 ASCII 的十六进制数字子集!)。
但是如果要谈性能,就会出现额外的要求:
- 数据大小
如果您的生产数据大小为 2 TB,但您的测试集为 200 GB,那么它的速度并不会线性提高 10 倍。 这种关系是非线性的:在给定的硬件上,生产数据可能会受到 IO 限制,因为工作集无法放入内存,而测试数据可以将 WSS 放入内存。 生产数据将产生与负载成比例的磁盘读取,测试数据将从内存运行,预热后没有读取 I/O——应用完全不同的性能模型。 对测试数据的性能测试对生产性能的预测价值为零。
- 数据分布
生产数据和生产数据访问受制于很大程度上未知和未记录的数据访问模式,并且也在不断变化。 一些用户像是鲸鱼,他们的遍历数据次数是正常标准的100倍,而其他一些用户是经常遍历的人,他们的访问数据的次数是平时的10倍。 一些用户是一次性的,在数据集中只出现一次。 这些集合之间的关系是什么,它们对数据访问有什么影响?
例如:
我丢失的数据库基准
德国计算机杂志c‘t在2006年有一个应用程序基准,描述了对DVD租赁商店的Web请求访问。参赛者应该使用他们希望的任何技术编写DVD出租商店,在所需的输出和他们将在测试中暴露的URL请求中定义。我希望作为MySQL顾问想参与其中,为此我将提供的模板放入使用MySQL的网上商店,并相应地调整商店和数据库。
我没进入前10名。
那是因为我使用了一个真实的网上商店,对用户行为有真实的假设,包括缓存和物品。
生成所使用的测试数据,并且平均分配请求:模拟DVD商店中的每张 DVD 被租用的可能性相同,并且每个用户租用的DVD数量相同。您放入存储中的任何缓存都会溢出并进入脱粒状态,或者必须有足够的内存才能将整个存储保存在缓存中。
真正的DVD出租店拥有前100名的热门影片,而且还有一条长长的尾巴。缓存有帮助。在测试中,缓存破坏了性能。
我丢失的另一个数据库基准
另一本德国计算机杂志有另一个数据库基准测试,它基本上以非常高的负载锤击被测系统。不幸的是,这里的负载分布不均,但是经常使用一些键,而从未请求过很多键。 实际上,负载生成器有大量线程,每个线程都在使用数据库中的“他们的”键——线程1到表中的 id 1,依此类推。
这锻炼了一定数量的热键,并在几个锁上等待非常快,但实际上并没有准确地模拟任何吞吐量限制。 如果您以更多类似生产的负载运行系统,它的总吞吐量将增加大约 100 倍。
TL和DR
生成用于测试的掩码或模拟数据的计算成本比复制生产数据的计算成本高 100 倍左右。 如果生产数据已经被标记化,那么与所花费的努力相比,胜利也是值得怀疑的。
生成有效的测试数据在计算上是昂贵的,尤其是在要跨服务边界维护引用完整性的微服务架构中。
有效的测试数据在测试中不一定有用,尤其是在性能测试方面。 性能测试还特别依赖于影响锁定时间的数据访问模式、工作集大小和到达率分布。
最后,实际的测试环境始终是生产环境,以我个人的专业经验,使生产中的测试安全比生产准确的测试环境更有价值。
原文标题:MySQL: Data for Testing
原文作者:KRISTIAN KÖHNTOPP
原文地址:https://blog.koehntopp.info/2022/09/26/mysql-data-for-testing.html
