




sed 全名 stream editor,一般用于文本内容替换。本文介绍日常工作中常用到的 sed 命令,更加完整的说明可以点击文末阅读原文参考 sed 手册。
01
—
模式空间(pattern space)
将文件以行为单位读取到内存(模式空间)
使用 sed 的每个脚本对该行进行操作
处理完成后输出该行
如下所示,读取 a.log 文件第一行内容,sed 中有 2 个替换脚本,第一个将 aa 替换成 @@ ,第二个将 bb 替换成 !! ,最后输出结果。
meng➜/tmp» cat a.logaa bb ccmeng➜/tmp» sed 's/aa/@@/;s/bb/!!/' a.log@@ !! cc
02
—
替换命令 s
字符串替换,将文件中 src 字符串替换成 new,支持多个替换脚本
sed ’s/src/new/‘ filenamesed -e ’s/src/new/’ -e ’s/src1/new1/‘ filename# 这里等同于下面分号隔开sed 's/src/new/;s/src1/new1/' filename
默认只会输出替换后的文本,-i 可以直接将源文件修改掉。
sed -i 's/src/new/' filename
正则替换:最常用的替换方式,需要你对正则表达式比较熟悉。
sed ’s/正则表达式/new/‘ filenamesed -r ’s/扩展正则表达式/new/ filenam# 示例:每行前面添加 #sed 's/^/#/' filename
扩展正则表达式包括 ?, +, |, ( ) 这几个字符
在扩展正则表达式中,使用圆括号匹配的内容可以当做变量来使用。比如我们可以将 aa 字符前加两个 !!
meng➜/tmp» sed -r 's/(aa)/!!\1/' a.log!!aa bb c
03
—
标志位
s/src/new/标志位
g:每次出现都替换。
数字:替换第几次出现,可以数字+g 替换第几次之后。
p:打印模式空间内容
默认每行只会替换匹配的第一个,我们可以通过 g 来替换所有
meng➜/tmp» cat b.logaa aa aa aameng➜/tmp» sed 's/aa/@@/g' b.log@@ @@ @@ @@meng➜/tmp» sed 's/aa/@@/2' b.logaa @@ aa aameng➜/tmp» sed 's/aa/@@/2g' b.logaa @@ @@ @@
p 将匹配的内容进行再次打印。加 p 后匹配的内容会被打印两次,第一次是标准输出,第二次是模式空间内容输出。这个可以结合 -n 使用,-n 表示处理完不进行标准输出。比如:在测试命令的时候,文件行数非常多,我只关心命令生效的内容。
meng➜/tmp» cat c.logaa aa aa aabb bbmeng➜/tmp» sed 's/aa/@@/p' c.log@@ aa aa aa@@ aa aa aabb bbmeng➜/tmp» sed -n 's/aa/@@/p' c.log@@ aa aa aa
04
—
寻址
sed 默认对每行进行操作,增加寻址后仅对匹配的行进行操作。
/正则表达式/s/src/new/g。
行号s/old/new/g。行号可以是具体的行,也可以是最后一行 $ 符合。
可以使用两个寻址符号,也可以混合使用行号和正则。
/正则表达式/{ s/src/new;s/src/new/ },多个替换命令。
meng➜/tmp» cat d.logaa aa11 aacc aameng➜/tmp» sed '/^[a-z]/s/aa/@@/' d.log@@ aa11 aacc @@meng➜/tmp» sed '2s/aa/@@/' d.logaa aa11 @@cc aameng➜/tmp» sed '2,3s/aa/@@/' d.logaa aa11 @@cc @@meng➜/tmp» sed '/^[a-z]/,$s/aa/@@/' d.log@@ aa11 @@cc @@
/^[a-z]/,$s/ 从 /^[a-z]/ 匹配的行开始,一直到最后一行
05
—
其他
d 删除匹配的行
meng➜/tmp» sed '/11/d' d.logaa aacc aa
a 追加
# 在匹配的行后追加字符串 hellomeng➜/tmp» sed '/11/a hello' d.logaa aa11 aahellocc aa
i 插入
meng➜/tmp» sed '/11/i hello' d.logaa aahello11 aacc aa
c 更改
# 相当于直接替换掉这一行meng➜/tmp» sed '/11/c hello' d.logaa aahellocc aa
p 打印
# 打印长度为 6 的回文串meng➜/tmp» sed -rn '/(.)(.)(.)\3\2\1/p' word.logredder
06
—
多行匹配
有了 N 、P 、D 我们就可以多行内容一起处理了。
N 将下一行加入到模式空间。
D 删除模式空间中的第一个字符到第一个换行符。
P 打印模式空间中的第一个字符到第一个换行符。
meng➜/tmp» cat e.loghello# 将第二行合并到第一行,然后将换行符删掉meng➜/tmp» sed 'N;s/\n//' e.loghello
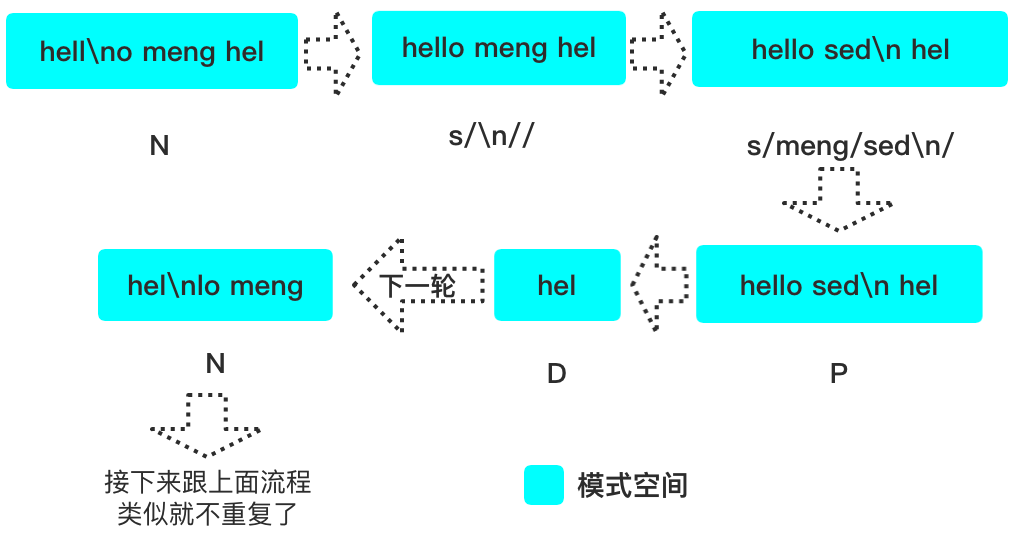
接下来看个示例,hello meng 被换行分隔成了多行,将它合并成一行,并替换成 hello sed。
meng➜/tmp» cat f.loghello meng hello meng# 处理流程见下图meng➜/tmp» sed 'N;s/\n//;s/meng/sed\n/;P;D' f.loghello sedhello sed
07
—
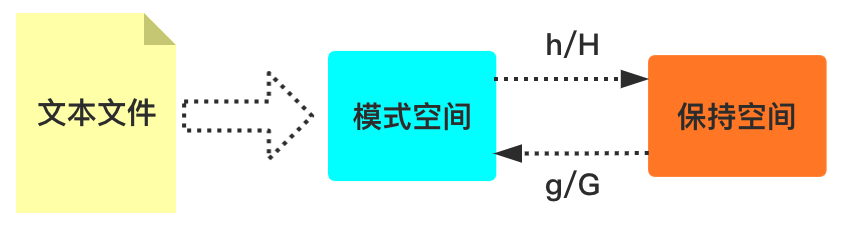
保持空间(hold space)
保持空间也是一块暂存区域,我们可以将模式空间的内容复制到保持空间,也可以将保持空间内容复制到模式空间,方便我们对多行进行操作。
h 和 H 将模式空间的内容存放到保持空间,小写是覆盖模式,大写是追加模式。
g 和 G 将保持空间的内容取出到模式空间,大小写含义同上。
x 交换模式空间和保持空间内容。
保持空间默认有一个初始字符:换行符
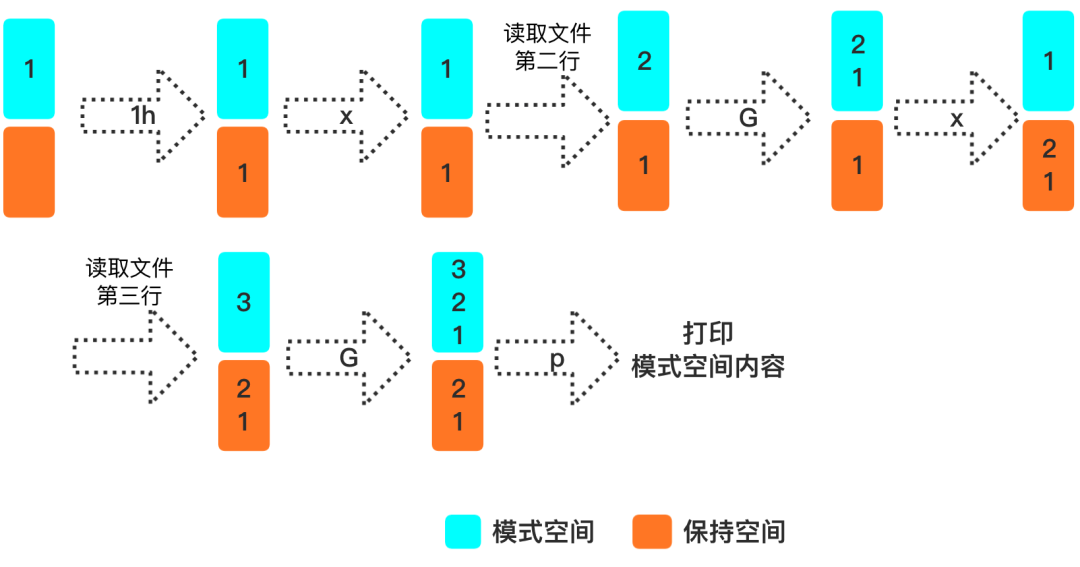
看个示例,tac 命令是将文件倒序输出,用 sed 怎么实现呢?
➜ tmp cat g.log123➜ tmp sed -n '1h;1!G;$!x;$p' g.log321
执行流程如下图
1h:只对第一行执行 h
1!G:对第一行不执行 G
$!x:对最后一行不执行 x
倒序输出的命令我们还可以精简,如下:
# 不加 1! 会多个换行,不知道为什么的同学,说明上文没认真看sed -n '1!G;h;$p' g.logsed '1!G;h;$!d' g.log
换行符改成 , 号分隔
➜ tmp sed '1h;1!H;$x;$!d;s/\n/,/g' g.log1,2,3
推荐阅读:
长按二维码关注,获得更多干货文章

