




Google 的 Protocol Buffers 跨语言、性能好,序列化后的消息体小利于传输,被广泛应用于RPC调用,数据存储。
本文一共分为 6 部分(TLV编码、压缩整形、字符串、嵌套类型、数组、Map),跟大家拆解 ProtoBuffer 序列化原理。
01
—
TLV 编码

T:Type ,用于标识标签或者编码格式信息。
L:Length 定义数值的长度。
V:Value表示实际的数值。
这个是个比较通用的结构类型,很多序列化工具都是基于这种类型的优化。
我们来看一个简单的 proto 定义:
message Test1 {optional int32 a = 1;}
最后一个数字是字段的序号(field_number),不能重复,每个字段有了唯一的编号,有了编号之后就可以不用存储字段名称。
正常情况下一个字段名称最少也2、3个字符,一个字符占用 2 个字节。而是用整数,再加上接下来讲的压缩整形,标识这个字段可能只需要 1 个字节就够了。
Protocol Buffers 将数据分了六种类型:
| 类型 | 含义 | 使用场景 |
| 0 | 压缩整形 | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 固定64位 | fixed64, sfixed64, double |
| 2 | 不定长 | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | 废弃 |
| 4 | End group | 废弃 |
| 5 | 固定32位 | fixed32, sfixed32, float |
6 种类型用 3 位二进制即可保存,我们用 wire_type 代表类型,对应 TLV 编码 T 的定义如下:
T = (field_number << 3) | wire_type
用低三位来存储 wire_type,剩下存放字段序号,然后 T 再用压缩整形进行序列化。
除了第二种不定长,我们可以认为其他类型都是定长的,所以定长的类型就不需要 L,直接 TV 就可以表示。
02
—
压缩整形
一个字节一共有 8 位,我们可以用低 7 位来存储数据,最高位表示是否需要更多字节来存储。
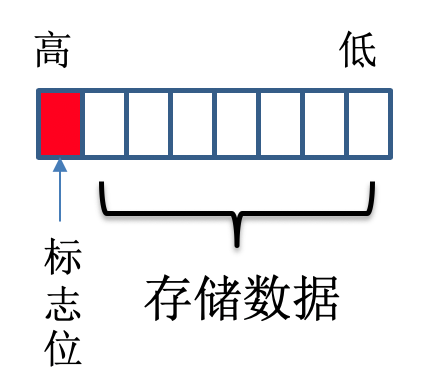
比如我们要存储一个 int 类型的 128 ,4个字节,转换后只需要两个字节存储。
接下来我们看个示例:
当我们给 a 赋值 128 的时候,输出的序列化后的字节数组:
[8, -128, 1]
8: 对应的二进制为:
0000 1000,低3位是 0 表示使用的是压缩整形,剩下的数字是 1,表示序号为 1 的字段。
-128: 转换成二进制:
1000 0000,由于采用的是压缩整形,最高位是标记为,表示下一个字节跟这个字节是一起的。
1: 转换成二进制:
0000 0001,这里标志位是 0 表示到这里已经读取到所有数据了,跟前一个字节数据拼接在一起:
000 0001 000 0000,对应的 int 类型数字是 128。
[8, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1]
(n << 1) ^ (n >> 31)
n<<1: 相当于将最低位空出来。
n>>31: 带符号移位,正数就是 32 个 0,负数就是 32 个 1。
异或:相当于把符号位移到低位,并对负数做个取反。


03
—
字符串
message Test2 {optional string b = 1;}
给 b 赋值 "java" 输出的字节数组如下:
[10, 4, 106, 97, 118, 97]
第一个字节标记类型和序号,大家可以自己推算。第二个字节是长度,也是用压缩整形序列化,后面 4 个字节对应 “java” 这 4 个字符的 ASCII 码。
04
—
嵌套类型
如下 Test3 中包含 Test1 数据
message Test3 {optional Test1 c = 1;}
Test1 中的 a 赋值 128,将 Test3 序列化输出如下:
[10, 3, 8, -128, 1]
10:0000 1010 对应的是 c 字符的位置和序号
3:接下来内容大小,3 个字节
8, -128, 1:对应的是 Test1 的数据
05
—
数组
repeated 是表示字段可以重复。
message Test4 {repeated int32 d = 1;}
这里给 d 添加 2 个值 “1” 和 “128”,输出如下:
[8, 1, 8, -128, 1]
8, 1:这里表示 1
8, -128, 1:这里表示 128
这里跟基本类型序列化一样,只不过数组中每一个元素序列化的时候都有一个相同的 T (Type,示例中的 8)。
这里在序列化的时候,ProtoBuffer 并不保证数组的元素一定是连续存储,有可能中间序列化的有别的元素。
对于基本类型来说数组可以压缩,省略掉每个元素都要标记 T 。配置了压缩之后,数组就是连续存储。
message Test4 {repeated int32 d = 1 [packed=true];}
同样的 “1” 和 “128” 输出如下:
[10, 3, 1, -128, 1]
10:field_number=1 ,wire_type=2,不定长。
3:长度,接下来 3 个字节存放数据。
1:0000 0001,高位是 0 说明是一个完整的数据,就是我们第一数据 1。
-128,1:对应的是第二个数据 128
06
—
Map
Map 的序列化方式跟数组是差不多的,我们可以认为一个 key-value 是一个 item,其实就相当于一个 item 数组。
定义如下结构
message Test5 {map<string,Test1> e = 1;}
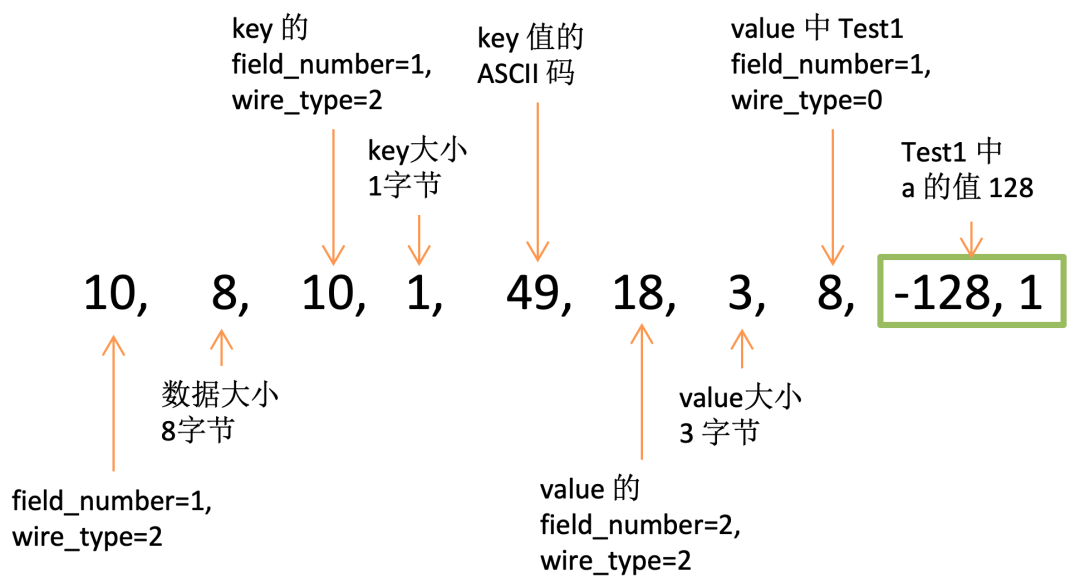
在 e 中添加 2 个元素: ("1", Test1(a=128)),("128", Test1(a=128)),序列化后的结果如下:
[10, 8, 10, 1, 49, 18, 3, 8, -128, 1, 10, 10, 10, 3, 49, 50, 56, 18, 3, 8, -128, 1]
上面的数据可以拆分成 2 组,带大家分析下第一组数据,剩下一组可以自己分析。
10, 8, 10, 1, 49, 18, 3, 8, -128, 1,10, 10, 10, 3, 49, 50, 56, 18, 3, 8, -128, 1
参考文档
https://developers.google.com/protocol-buffers/docs/encoding
https://developers.google.com/protocol-buffers/docs/proto
长按二维码关注,获得更多干货文章

