




并发控制模型
每个事务包含多个读写操作,操作对象为数据库内部的不同数据。最简单的并发控制就是串行(serial)执行,指一个进程在另一个进程执行完(收到触发操作的回应)一个操作前不会触发下一个操作。但这明显不符合高并发的需求。因此学者们提出了一种可串行化(serializable),即可以通过并行(非串行)地执行事务内的多个操作,但是可以达到和串行执行相同的结果。
我们可以利用事务中的读写操作来为事务来建立依赖关系(依赖关系代表事务串行化成串行执行序后的事务定序,若事务 B 依赖事务 A,事务 A 应该排在事务 B 前面):
写写冲突(Write Dependency):当事务 A 修改数据 X 后,事务 B 再修改同一数据 X,事务 B 依赖事务 A。
写读冲突(Read Dependency):当事务 A 读取数据 X 后,若数据 X 对应是由事务 B 修改的,事务 A 依赖 事务 B。
读写冲突(Anti Dependency):当事务 A 读取数据 X 后,事务 B 再修改了同一数据 X,事务 B 依赖事务 A。
通过冲突来定义的可串行化,一般称为冲突可串行化(conflict serializable),可以轻易地通过以上的冲突机制来分析。当事务间的冲突关系没有成环的话,就可以保证冲突可串行化。有两种常见的实现机制, 即两阶段锁和乐观锁机制。前者是通过排它地通过加锁限制其他的事务的冲突修改,并通过死锁检测机制回滚产生循环的事务,保证无环;后者通过在提交时的检测阶段,回滚所有可能会导致成环的事务保证不会产生环。
但是实际上实现可串行化隔离级别的商业数据库少之又少,其中上述两种实现机制都有极大的性能代价,因此一般会通过允许一些容易接受的成环条件来暴露一些异常,并增加事务的性能和可扩展性。其中快照读和读已提交是比较常见的允许异常的并发控制。其中快照读隔离级别依赖维护多版本数据,并在读取时通过一个固定的读版本号读一个对应版本的数据。因此对于同一事务中的不同数据会产生因为读写冲突导致的环。比如说事务 A 读取数据版本为 1 的 X 后修改产生数据版本 2 的 Y,事务 B 取数据版本为 1 的 Y 后修改产生数据版本 2 的 X。我们可以清楚地发现事务 A 与事务 B 产生了环,这种异常也就是我们经常说的写偏斜(Write Skew)。这是快照读暴露给用户的异常。对于读已提交隔离级别,则会暴露不可重复读等异常,即事务内部两次读取结果不同。如何定义隔离级别的抽象,能给予使用者在性能上和语义易用性上的平衡感是设计事务隔离级别(Isolation)的关键之一。
OceanBase 数据库的并发控制模型
OceanBase 数据库现在支持快照读和读已提交两种隔离级别,并在分布式语义上隔离级别保证外部一致性。
多版本数据&事务表
为了支持读写不互斥,OceanBase 数据库从设计开始就选择了多版本作为存储,并让事务对于全局来说,维护两个版本号,读版本号和提交版本号,如图所示的 本地最大读时间戳 和 最大提交时间戳。其次,在内存中会为每一次更新记录一个新的版本(可以做到读写不互斥)。
如图所示,在内存中有三行数据 A、B 和 C;其中每次通过版本(ts)、值(val)和事务 id(txn)来维护更新,并将多次更新同时维护来保持多版本;其次,内存中存在一个事务表,事务表中记录了每个事务的 id、状态以及版本。事务开始和提交时会通过全局时间戳缓存服务(Global Timestamp Cache)获取时间戳作为读时间戳和作为提交时间戳参考的一部分。
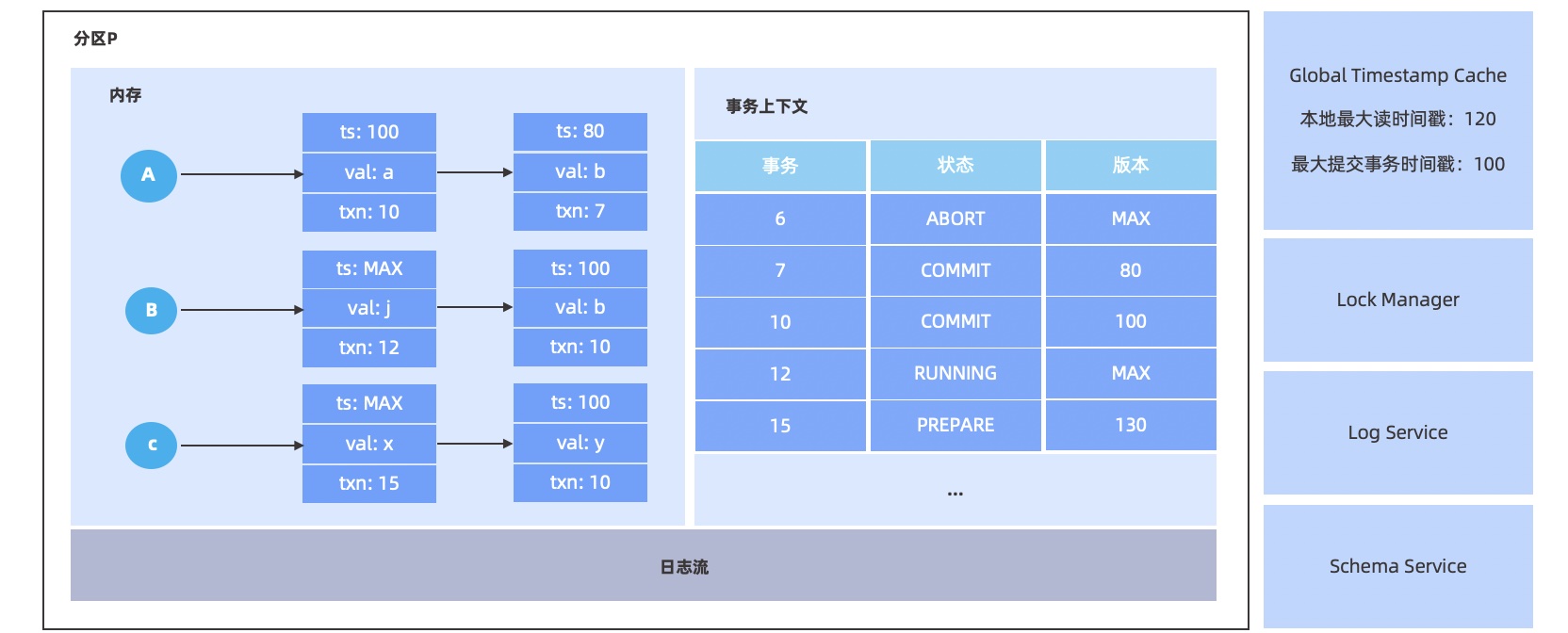
由图中可知,全局时间戳获取服务维护了最大遇到的事务的读时间戳和最大在已经提交的事务的提交时间戳,分别为 120 与 100(之后会提到这两个时间戳的作用)。在内存中,数据 A 包含 100 版本已经提交的数据 a。其对应的事务为事务 10;类似数据 B 包含未决定版本的数据 j 以及对应事务事务 12 以及数据 C 包含未决定版本的数据 x 以及对应事务事务 15。事务表中包含了对应事务以及其对应状态,如事务事务 15 正在以 130 版本进入两阶段提交状态。
提交请求处理
OceanBase 数据库 的分布式事务简单来说有三个状态,RUNNING、PREPARE 和 COMMIT。由于事务状态在分布式场景下无法原子地确认,PREPARE 是两阶段提交所增加的阶段。因此我们对于事务中维护一个 本地提交版本号(local commit version,即 prepare version),事务的 全局提交版本号(global commit version,即 commit version)是由所有分区本地提交版本号的最大值决定的。对于每个分区的保证是最后事务的 全局提交版本号 一定大于等于本地分区的 本地提交版本号 的。这个保证也是之后我们实现读写请求并发控制的关键之一。
当事务提交时,我们会走对应的两阶段提交,我们对于参与者中的每一个分区取本地 最大读时间戳 作为本地提交时间戳。这个保证是为了做单值的读写冲突(anti dependency),根据保证,可以得到我们的提交时间戳一定大于之前所有的读取,因此我们在串行执行中可以在这些之前的读取后面。如图所示,事务 12 进入提交阶段,并设置状态为 PREPARE,设置本地事务版本号为本地 最大读时间戳 120 与取 GTS 为 150 的最大值 150 作为 本地事务版本号。

在两阶段结束之前,我们的保证只有 全局提交时间戳 大于等于 本地提交时间戳,当我们收到两阶段提交的提交消息后,便能知道全局的提交时间戳,如图所示,回填状态为提交,时间戳为 160,并异步地回填到更新数据上,保证之后不需要再来查事务表。其次,会更新 最大提交事务时间戳 来提供之后的读请求优化,并在锁队列中唤醒对应的事务。

写请求处理
在写入数据的时候,为了保证写写冲突(write dependency),修改会使用两阶段锁协议,当触发写入请求时,若发现本行的多版本有正在执行的事务,就会把这次请求放入锁管理器中等待,OceanBase 数据库在锁管理器中,实现了等待队列,通过锁或超时来唤醒这个写请求。如图所示当准备更新数据 B 时,由于存在活跃事务事务 12 正在修改数据 B,因此会将这次的写入请求放到锁队列中,等待事务事务 12 的唤醒。

快照读隔离级别为了防止读写冲突(anti dependency)和写读请求(read dependency)成环,即丢失更新(lost update),尽管写入或唤醒后加锁成功,会用读时间戳,跟本行上维护的 最大提交事务时间戳 作比较,如果读时间戳小于行上的最大提交事务时间,则会回滚掉此事务。比如说若上图写操作的读时间戳是 100,事务 12 以时间戳 160 提交,那么就会触发写操作对应事务的回滚,对应的报错(TRANSACTION_SET_VIOLATION)。
读请求处理
在读取的时候,会使用读版本号来读取对应的数据,在真正读取时会用读版本号先更新本地 最大读时间戳。依赖之前给予的保证,可以很优雅地在分布式场景下处理读请求。
接下来分开来分析,当读取到提交或回滚的事务时,可以根据 全局提交时间戳 和状态比较简单地推测出是否需要读到对应数据。如下图所示,读取请求 r1 以 90 作为读版本号进行读取,根据快照读的策略,会选择版本号为 80,数据为 b 的数据进行读取。
当读取到 RUNNING 状态的事务时,由于推高了 本地最大读时间戳,因此之后 RUNNING 状态的事务一定会以更大的 本地时间戳 来进入两阶段提交,根据保证和快照读的概念,可以安全地跳过这个数据。如下图所示,读取请求 r2 以 130 作为读版本号进行读取,会先推高 最大读事务时间戳,保证之后事务以大于 130 的 本地提交版本/全局提交版本 提交,然后跳过未进入两阶段提交的事务 12 读取到版本号为 100,数据为 b 的数据。
当读取到 PREPARE 状态的事务时,由于给予的保证,对于 本地时间戳 大于读时间戳的事务,和之前的分析一样,可以保证不用读到。但是若 本地时间戳 小于读时间戳,那么无法确认这个时间戳最后的 全局提交时间戳 和读时间戳的关系,因此解决方案是,优雅地等在这行的事务上(内部称为 lock for read,两阶段提交在 OceanBase 数据库的假设中应该会是很快完成的过程。如下图所示,读取请求 r3 以 140 作为读版本号进行读取,会先推高 最大读事务时间戳,保证之后事务以大于 140 的 本地提交版本/全局提交版本 提交,然后等待两阶段提交状态且 本地提交时间戳 为 130 的时候最后决定 全局提交时间戳 和读时间戳 140 的关系。

