




与单独的PostgreSQL相比,TimescaleDB可以将查询性能显著提高1000倍或更多,将存储利用率降低90%,并提供时间序列和分析应用程序所必需的功能。这些功能中的一些甚至有利于非时间序列数据,只需加载扩展即可提高查询性能。
PostgreSQL是当今最先进、最流行的开源关系数据库。今天,我们和五年前一样相信这一点,当时我们选择PostgreSQL作为TimescaleDB的基础,因为它的寿命长、可扩展性好,并且结构坚固。
通过将TimescaleDB扩展加载到PostgreSQL数据库中,您可以有效地“增压”PostgreQL,使其在时间序列工作负载和经典事务工作负载方面都表现出色。
本文重点介绍TimescaleDB如何大规模提高PostgreSQL查询性能,提高存储效率(从而降低成本),并为开发人员提供构建现代、创新和经济高效的时间序列应用程序所需的工具,同时保持对完整Postgres功能集和生态系统的访问。
(为了展示我们的工作,本文还提供了比较PostgreSQL 14.4和TimescaleDB 2.7.2之间10亿行时间序列数据的查询性能和数据摄取的基准。对于PostgreQL,我们使用单个表和声明性分区进行了基准测试)
规模化性能更好
TimescaleDB在规模上具有数量级的更好性能,使开发人员能够在PostgreSQL和“经得起未来考验”的应用程序之上进行构建。
时间序列查询性能提高1000倍
TimescaleDB的核心概念是“超表”的概念:无缝地划分数据,同时呈现跨所有数据的单个虚拟表的抽象。
这种分区通过快速排除不相关的数据以及增强查询规划器和执行过程来实现更快的查询。通过这种方式,超级表的外观和感觉就像普通的PostgreSQL表,但支持更多功能。
例如,最近的一项查询计划器改进可以更有效地排除基于now()的相对查询的数据(例如,WHERE time>=now()-‘1 week’::interval)。更具体地说,这些相对时间谓词是在计划时间构造的,以忽略没有数据满足查询的块。此外,随着分区数量的增加,对于相同数量的分区,规划时间可以比普通PostgreSQL减少100倍或更多。
当超级表被压缩时,查询需要读取的数据量就会减少,导致性能急剧提高1000倍或更多。有关更多信息(包括对该条形图的讨论),请继续阅读下面的基准。
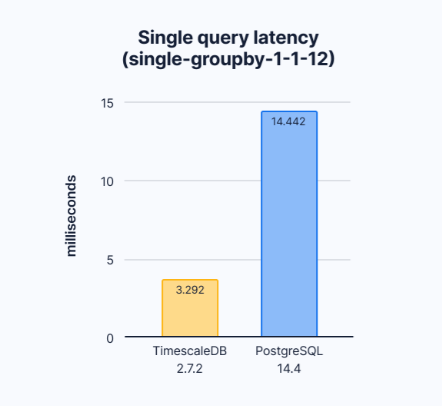
TimescaleDB和PostgreSQL 14.4之间的查询延迟比较(毫秒)。要查看完整的查询,请向下滚动。
TimescaleDB中的其他增强功能同时适用于超表和普通PostgreSQL表:例如,SkipScan,它极大地改进了对任何具有匹配B树索引的PostgreQL表的DISTINCT查询,无论您是否有时间序列数据。
将通常运行的查询减少到毫秒(即使原始查询需要几分钟或几小时)
如今,几乎每个时间序列应用程序都需要滚动聚合来更高效地查询和分析数据。原始数据可以每秒、每分钟或每小时(以及其间的大量其他排列)保存,但大多数应用程序显示的是基于时间的聚合。
此外,大多数时间序列数据应用程序都是只附加的,这意味着聚合查询会根据未更改的原始数据反复返回相同的值。存储聚合查询的结果,并在大多数时间将其用于分析报告和分析,这样效率更高。
开发人员通常会尝试使用普通PostgreSQL中的物化视图来提供帮助,但是,他们在快速变化的时间序列数据方面存在两个主要问题:
-
物化视图在每次物化过程运行时都会重新创建整个视图,即使很少或没有数据发生更改。
-
物化视图不提供任何数据保留管理。每当您删除原始数据并更新物化视图时,聚合的数据也会被删除。
相反,TimescaleDB的连续聚合解决了这两个问题。它们会根据您配置的计划自动更新,它们可以与底层超表分开应用数据保留策略,并且它们只更新自上次物化运行以来已修改的新数据部分。
当我们将使用连续聚合与直接查询数据进行比较时,客户通常会看到查询可能需要几分钟甚至几小时的时间,而查询时间可能会降到几毫秒。当该查询为仪表板或网页提供动力时,这可能是快速和不可用的区别。
轻松跨多个节点横向扩展Postgre以实现PByte级数据集
对Postgres的一个常见批评是,一旦最大化数据库实例,就无法有效地扩展。这就是为什么我们开发了TimescaleDB Multi-node,这是一种链接多个PostgreSQL节点的方法,可以扩展PB级数据集的接收和查询性能,同时每秒插入超过100万行。
使用多节点提供分布式超表会自动在节点之间传播数据,仍然允许您像往常一样访问该数据。
降低存储成本
现代时间序列应用程序成本的首要驱动因素是存储。即使存储成本很低,时间序列数据也会很快堆积起来。时间尺度提供了两种方法来减少存储的数据量,即使用连续聚合进行压缩和下采样。
通过一流的压缩算法节省90%或更多存储
Timescale超表将数据严重地划分为许多更小的分区,称为“块”。Timescale基于每个块提供本机列压缩。
正如我们在基准测试结果中所显示的那样(正如我们在生产数据库中经常看到的那样),与普通PostgreSQL中的相同数据相比,压缩减少了90%以上的磁盘消耗。更好的是,TimescaleDB并没有改变PostgreSQL存储系统的任何内容来实现这种级别的压缩。相反,TimescaleDB利用PostgreSQL存储特性,即TOAST,将历史数据从行存储转换到列存储,这是查询单个列的长期聚合的关键组件。
为了证明压缩的有效性,这里比较了TimescaleDB和PostgreSQL中cpu表和索引的总大小。
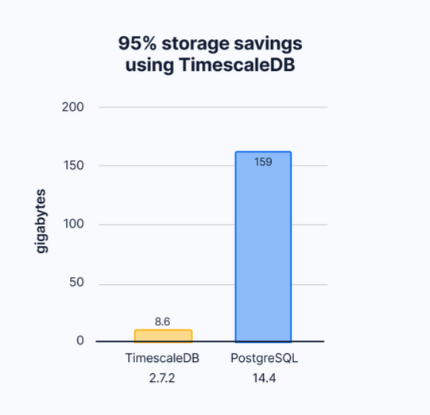
有了适当的压缩策略,一旦块中的所有数据老化超过指定的时间间隔,就会自动压缩超表块。实际上,这意味着超表可以同时将数据存储为面向行的新数据和面向列的旧数据。将数据同时存储为行存储和列存储也与时间序列应用程序的典型查询模式相匹配,以帮助再次提高整体查询性能,我们在基准测试结果中看到了这一点。
这减少了存储占用空间,并进一步提高了许多时间序列聚合查询的查询性能。压缩也是自动的:用户设置压缩范围,然后随着数据的老化自动压缩。
这也意味着用户可以使用云服务(如Timescale cloud)来节省大量成本,这些云服务提供计算和存储分离,这样就不需要更大的机器来获得更多的存储。
通过方便地删除或减少数据采样,节省更多存储空间
使用TimescaleDB,只需一个SQL命令即可实现自动数据保留:
SELECT add_retention_policy('cpu', INTERVAL '7 days');
没有进一步的设置或额外的扩展来安装或配置。每天,任何超过7天的分区都将自动删除。如果要在vanilla PostgreSQL中实现这一点,则需要使用DELETE删除记录,这是一个非常昂贵的操作,因为它需要扫描要删除的数据。即使您使用的是PostgreSQL声明性分区,您仍需要自己自动化该过程,浪费宝贵的开发人员时间,添加额外的需求,并实现需要支持的定制代码。
还可以结合连续聚合和数据保留策略来减少数据采样,然后删除原始测量,从而节省更多的数据存储。
使用此体系结构,您可以将更高级别的汇总值保留更长的时间,即使原始数据已从数据库中删除。这允许在数据库中存储多个不同级别的粒度,并提供了更多控制存储成本的方法。
更多功能加快开发时间
TimescaleDB包含更多加快开发时间的功能。这包括一个包含100多个超函数的库,这些超函数使复杂的时间序列分析更容易使用SQL,例如计数近似、统计聚合等。TimescaleDB还包括一个内置的多用途作业调度引擎,用于设置自动化工作流。
100多个超函数库,简化复杂分析
时间刻度超函数使SQL中的数据分析变得简单。该库包括:时间加权平均值、上次观测值向前推进以及使用LTTP或ASAP算法、time_bucket()和time_bucket_gapfill()进行下采样。
例如,可以获得过去七天内每个设备每天的平均温度,并用以下SQL结转缺失读数的最后一个值。
SELECT
time_bucket_gapfill('1 day', time) AS day,
device_id,
avg(temperature) AS value,
locf(avg(temperature))
FROM metrics
WHERE time > now () - INTERVAL '1 week'
GROUP BY day, device_id
ORDER BY day;
有关TimescaleDB中大量超函数的详细信息,请访问我们的API文档。
用于工作流自动化的内置作业计划程序
TimescaleDB提供了使用用户定义的操作计划自定义存储过程的执行的能力。此功能提供了对TimescaleDB用于运行所有本机自动化作业的同一作业调度程序的访问,这些作业用于压缩、连续聚合、数据保留等。
这提供了与pg_cron等第三方调度器类似的功能,而无需维护多个PostgreSQL扩展或数据库。
我们看到用户使用用户定义的操作完成各种各样的工作,从计算复杂的SLA,到根据数据正确性发送事件电子邮件,再到轮询表。
仍然是100%PostgreSQL和SQL
值得注意的是,由于TimescaleDB打包为PostgreSQL扩展,因此它可以在不派生或破坏PostgreQL的情况下实现这些结果。
扩展PostgreSQL—Not Forking 或 Cloning
Postgres目前很流行,但这种流行主要是与“Postgres-compatible”产品有关的,这些产品可能看起来像Postgres,或者说话像Postgre,或者查询有点像Postges,但不是隐藏在幕后(有时是封闭源代码)。
TimescaleDB只是PostgreSQL。人们可以安装其他扩展,充分利用类型系统,并从极其多样化的Postgres生态系统中受益。
100%SQL
任何可以连接到PostgreSQL的产品都可以使用与通常相同的SQL查询TimescaleDB中存储的时间序列数据。虽然我们提供了用于处理数据的帮助函数,但我们不限制可以使用的SQL特性。进入数据库后,用户可以根据需要组合时间序列和业务数据。
PostgreSQL奠定了坚实的基础
PostgreSQL不是一个新数据库:它有多年的生产部署经验。高可用性、备份和恢复以及负载平衡都是解决的问题。如前所述,我们选择Postgres是因为它是可靠的,TimescaleDB继承了这种可靠性。
基准设置和结果
本节详细介绍了我们如何根据vanilla PostgreSQL测试TimescaleDB。请随意下载时间序列基准套件并自行运行。如果您想快速开始使用TimescaleDB,可以使用Timescale Cloud,它允许您注册30天免费试用。
基准配置
对于这个基准测试,所有测试都在AWS us-east-1中相同的m5.2xlarge EC2实例上运行,配置和软件版本如下。
-
版本:TimescaleDB 2.7.2版、社区版和PostgreSQL 14.4
-
一台运行TSBS的远程客户端计算机,一台数据库服务器,两者位于同一云数据中心
-
TSBS客户端实例:EC2 m5.4xlarge,带16 vCPU和64 GB内存
-
数据库服务器实例:EC2 m5.2xlarge,带8 vCPU和32 GB内存
-
操作系统:服务器和客户机都运行Ubuntu 20.04
-
磁盘大小:1 TB EBS GP2存储
-
TSBS配置:Dev-ops配置文件,一个月内每10秒记录4000个设备的指标。
我们还故意选择使用EBS(弹性块存储)卷,而不是附加的SSD。虽然SSD的基准性能肯定会有所提高,但使用EBS的基准性能说明了许多自托管用户的期望,同时通过使用弹性存储节省了一些开支。
数据库配置
我们在EC2数据库实例上只运行了一个PostgreSQL集群。TimescaleDB扩展通过shared_preadload_librarys加载,但未安装到PostgreSQL专用数据库中。
为了为PostgreSQL集群设置合理的默认值,我们在PostgreSQL.conf中运行了timescaledb-tune和setsynchronous_commit=off。这是一种常见的性能配置,用于写入繁重的工作负载,同时仍保持事务性和日志完整性。所有配置更改都同样适用于PostgreSQL和TimescaleDB基准。
数据集
如前所述,对于这个基准测试,我们使用时间序列基准测试套件,为4000台设备生成数据,每10秒记录一个月的指标。这产生了超过10亿行的数据。因为TimescaleDB是PostgreSQL扩展,所以我们可以使用相同的数据文件和摄取过程,确保每个数据库中的数据相同。
TimescaleDB设置
TimescaleDB使用一种称为hypertables的抽象,它将大表拆分为更小的块,从而提高了性能并大大简化了对大量时间序列数据的管理。
我们还启用了TimescaleDB上的本机压缩。除了最近的数据块外,我们压缩了所有数据,使其保持未压缩状态。通常建议使用此配置,其中未压缩的原始数据将保存最近的时间段,而较旧的数据将被压缩,从而提高查询效率。我们用于启用压缩的参数如下:我们按tags_id列进行分段,并按时间降序和usage_user列进行排序。
所有的基准测试结果都是在一个PostgreSQL表和一个空的TimescaleDB超表上执行的,该超表是用四个小时的块创建的。
(对于那些认为我们还需要将TimescaleDB与PostgreSQL Declarative Partitioning进行比较的人:请阅读到最后,我们也会讨论这一点。)
查询延迟深度下降
对于这个基准测试,我们插入了10亿行数据,然后对各自的数据库分别运行一组查询100次。这两个数据库的数据、索引和查询完全相同。唯一的区别是TimescaleDB查询使用time_bucket()函数执行任意间隔桶,而PostgreSQL查询使用PostgreSQL13中引入的新date_bin()功能。
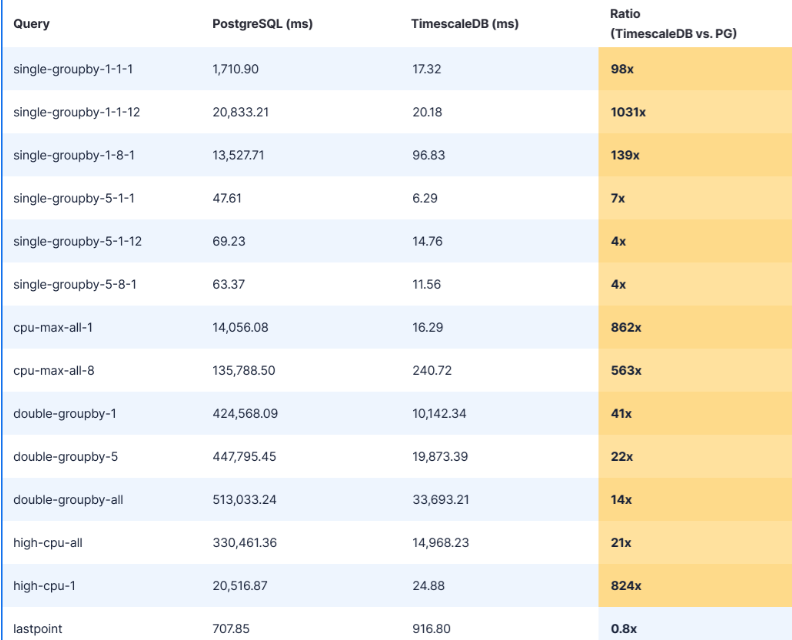
针对不同查询,PostgreSQL和TimescaleDB之间的查询延迟比较
结果清晰,重复性好。对于跨越一个月的十亿行数据(具有四小时的分区),TimescaleDB始终优于普通PostgreSQL数据库,一次运行100个查询。
Timescale的一致查询性能有两个主要原因。
压缩=更小的存储+更少的工作
在PostgreSQL(和许多其他数据库)中,表数据存储在8Kb的页面中(有时称为块)。如果一个查询必须读取1000页才能满足它,那么它会读取~8Mb的数据。如果必须从磁盘检索其中的一些数据,那么查询通常会比在内存中找到所有数据(PostgreSQL中称为共享缓冲区的保留空间,如果您想了解PostgreQL缓存,我们有一个博客)慢。
使用TimescaleDB压缩,返回相同结果的查询必须读取更少的数据页(这是因为实际的压缩,也因为它可以返回单列而不是整行)。对于我们所有的基准测试查询,这也转化为基准测试期间的更高并发性。
换句话说,压缩通常对获取历史数据的影响最大,因为TimescaleDB可以查询单个列而不是整行。由于每个查询的I/O更少,TimescaleDB可以处理更多的查询,标准偏差比普通PostgreSQL更低。
让我们看两个例子,通过上面的两个查询,cpu-max-all-1和single-groupby-1-1-12,了解这两个数据库之间的关系。
单组-1-1-12
我们从基准测试中选择一个查询,并在两个数据库上运行它。回想一下,每个数据库在未压缩数据上都有完全相同的数据和索引。TimescaleDB的优点是能够以有利于典型应用程序查询的方式对压缩数据进行分段和排序。
EXPLAIN (ANALYZE,BUFFERS)
SELECT time_bucket('1 minute', time) AS minute,
max(usage_user) as max_usage_user
FROM cpu
WHERE tags_id IN (
SELECT id FROM tags WHERE hostname IN ('host_249')
)
AND time >= '2022-08-03 06:16:22.646325 +0000'
AND time < '2022-08-03 18:16:22.646325 +0000'
GROUP BY minute ORDER BY minute;
当我们对这个查询运行EXPLAIN并要求返回BUFFERS时,我们开始得到发生了什么的提示。
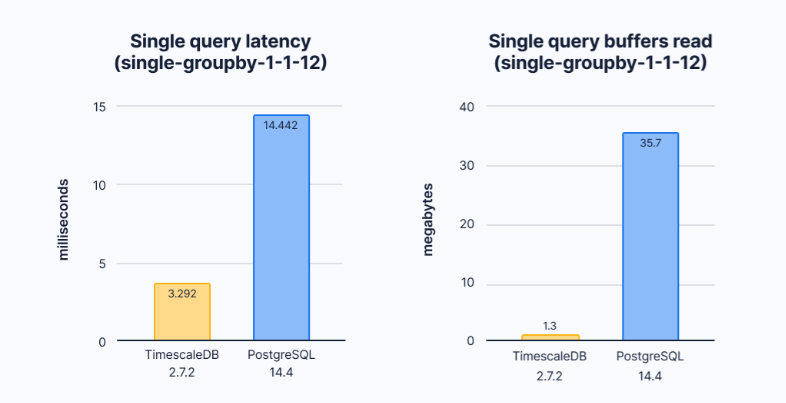
查询延迟与为满足TimescaleDB和PostgreSQL中的查询而必须读取的数据量。
当我查看这些结果时,有两件事会很快跳出来。首先,执行时间明显低于上述基准测试结果。单独来看,这些查询执行得很快,但PostgreSQL必须读取大约27倍的数据才能满足查询。当16个工作人员跨时间范围请求数据时,PostgreSQL必须执行更多的I/O操作,这会消耗资源。TimescaleDB可以简单地处理相同工作负载的更高并发性。我们也可以在完整的基准测试输出中看到这一点。
cpu-max-all-1型
与普通PostgreSQL相比,我们可以清楚地看到压缩对TimescaleDB处理更高并发负载能力的影响。
EXPLAIN (ANALYZE, buffers)
SELECT
time_bucket('3600 seconds', time) AS hour,
max(usage_user) AS max_usage_user,
max(usage_system) AS max_usage_system,
max(usage_idle) AS max_usage_idle,
max(usage_nice) AS max_usage_nice,
max(usage_iowait) AS max_usage_iowait,
max(usage_irq) AS max_usage_irq,
max(usage_softirq) AS max_usage_softirq,
max(usage_steal) AS max_usage_steal,
max(usage_guest) AS max_usage_guest,
max(usage_guest_nice) AS max_usage_guest_nice
FROM cpu
WHERE
tags_id IN (
SELECT id FROM tags WHERE hostname IN ('host_249')
)
AND time >= '2022-08-08 18:16:22.646325 +0000'
AND time < '2022-08-09 02:16:22.646325 +0000'
GROUP BY HOUR
ORDER BY HOUR;
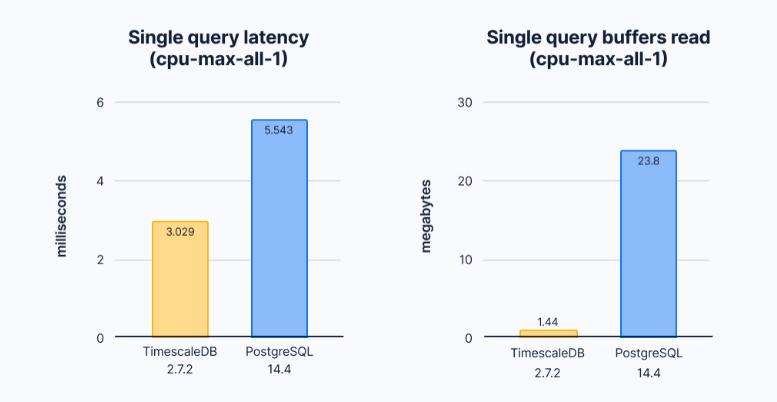
在TimescaleDB和PostgreSQL中,查询延迟与为满足查询而必须读取的数据量
通过压缩,TimescaleDB检索相同数据的工作量大大减少,从而实现更快的查询和更高的查询并发性。
按时间排序的查询工作得更好
TimescaleDB超表需要一个时间列来划分数据。由于时间是每一行和块的基本(和已知)部分,TimescaleDB可以智能地改进计划和执行查询的方式,以利用数据的时间成分。
例如,让我们查询过去10分钟内每分钟的最大CPU使用量。
EXPLAIN (ANALYZE,BUFFERS)
SELECT time_bucket('1 minute', time) AS minute,
max(usage_user)
FROM cpu
WHERE time > '2022-08-14 07:12:17.568901 +0000'
GROUP BY minute
ORDER BY minute DESC
LIMIT 10;
因为TimescaleDB知道该查询正在按时聚合,并且结果是按时间列排序的(每个块在索引中已经按时间列进行排序),所以它可以使用ChunkAppend自定义执行节点。相比之下,PostgreSQL计划五个工作线程扫描所有分区,然后对结果进行排序,最后对时间列执行GroupAggregate。
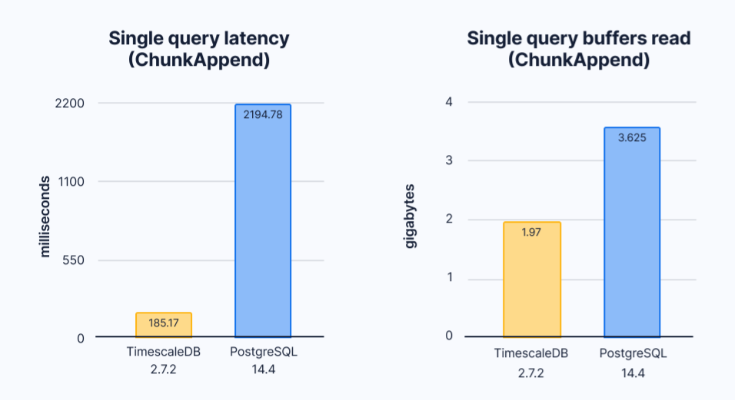
在TimescaleDB和PostgreSQL中,查询延迟与为满足查询而必须读取的数据量
TimescaleDB扫描的数据更少,不需要花费时间重新排序它知道已经在块中排序的数据。对于具有已知顺序和约束的时间序列数据,TimescaleDB比普通PostgreSQL更适合大多数查询。
摄入性能
有趣的是,TimescaleDB和PostgreSQL的接收性能几乎相同,这对于五年前PostgreSQL9.6的结果来说是一个巨大的改进。然而,TimscaleDB仍然以平均每秒3000到4000行的速度完成了任务,比单个PostgreSQL表高出了3000到4000个行。
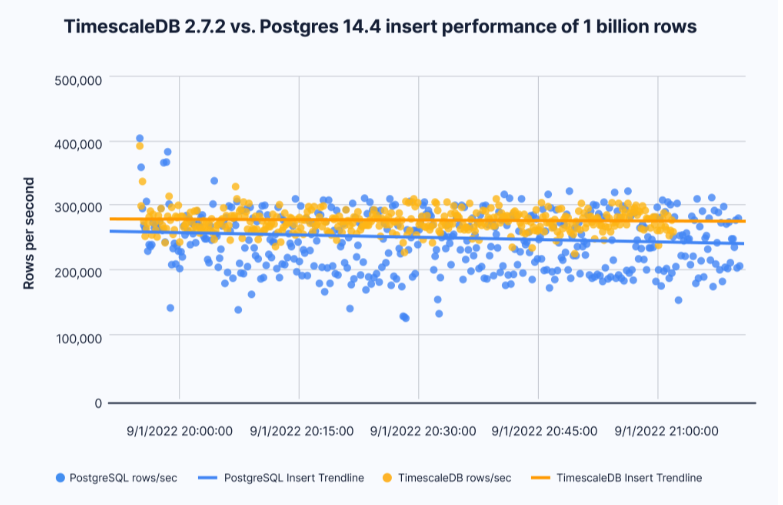
插入TimescaleDB 2.7.2和PostgreSQL 14.4之间的性能比较
这表明,虽然PostgreSQL已经取得了巨大的改进,但时间刻度超表也继续表现出色。除了速率之外,TimescaleDB和PostgreSQL的接收性能的其他特征几乎相同。修改一次要插入的行数的批大小对每个数据库的影响都是一样的:较小的批大小或几百行会严重影响接收性能,而10000到15000行的批大小似乎最适合此数据集。
声明性分区
在上面的基准测试中,我们针对单个PostgreSQL表测试了TimescaleDB,因为这是大多数人最终使用的默认选项。PostgreSQL还支持本机声明式分区,这种分区在过去几年中也逐渐成熟。
为了完整性,我们还针对本机声明性分区测试了TimescaleDB。如下图所示,对于某些查询,TimescaleDB的速度仍然是1000倍,性能仍在全面提高。TimescaleDB和声明性分区的吞咽性能相似。
事实上,如果有什么区别的话,这些测试的结论是,虽然声明性分区已经成熟,但使用单个表和声明性分区之间的差距已经缩小。
使用声明性分区的TimescaleDB和PostgreSQL之间的查询延迟比较
使用声明性分区也比较困难。需要手动预创建分区,确保没有数据间隙,确保没有在分区范围之外插入数据,并随着时间的推移创建更多分区。
相比之下,使用TimescaleDB,不需要任何这些。相反,使用单个create_hypertable命令将标准表转换为超表,其余部分由TimescaleDB负责。
结论
TimescaleDB利用扩展框架的强大功能为时间序列和分析应用程序增强PostgreSQL。TimescaleDB具有压缩和连续聚合等附加功能,不仅提供了在PostgreSQL中使用时间序列数据的最高效方式,而且提供了最佳的开发人员体验。
与传统的PostgreSQL相比,TimescaleDB实现了1000倍的时间序列查询速度,压缩了90%的数据,并提供了对高级时间序列分析工具的访问,以及专门为简化数据管理而设计的操作功能。TimescaleDB还通过安装扩展为其他类型的查询提供了好处,这些查询具有SkipScan等功能。
简而言之,TimescaleDB扩展了PostgreSQL,使开发人员能够继续使用他们喜爱的数据库来处理时间序列,在规模上表现更好,花费更少,并流式处理数据分析和操作。
如果您希望扩展数据库的可伸缩性,请尝试我们的托管服务Timescale Cloud。您将获得您所熟悉并喜爱的PostgreSQL,它具有时间序列的额外功能(连续聚合、压缩、自动保留策略、超函数)。此外,该平台还具有自动备份、高可用性、自动升级、自动缩放的灵活调整大小等功能。您可以免费使用30天。
原文标题:PostgreSQL + TimescaleDB: 1,000x Faster Queries, 90 % Data Compression, and Much More
原文作者:Ryan Booz
原文链接:https://www.timescale.com/blog/postgresql-timescaledb-1000x-faster-queries-90-data-compression-and-much-more/
